基于迁移学习的全岩光片有机显微组分识别与定量
——以皖泾地1井下三叠统殷坑组烃源岩为例
2022-02-06曾烃详刘岩文志刚樊云鹏冯兴强季长军史旭凯高变变武远哲
曾烃详, 刘岩*, 文志刚, 樊云鹏, 冯兴强, 季长军, 史旭凯, 高变变, 武远哲
(1.油气地球化学与环境湖北省重点实验室/长江大学资源与环境学院, 武汉 430100;2.中国地质科学院地质力学研究所, 北京 100081)
有机岩石学是在孢粉学和煤岩学基础上发展起来的一门边缘学科,主要研究地质体中沉积有机质的成因、产状、组成、结构和演化等内容[1-2]。为了客观评价烃源岩,其常用手段是应用光学显微镜交替使用反射光和荧光观察研究全岩样品,对观察到的组分进行识别、判断及统计等分析,结果可用于评价烃源岩的有机质类型、丰度和成熟度等,还能进一步获取生烃母质、烃类生成和运移等信息[3],而在煤岩学方面,显微组分不仅关系到煤层气的生成、赋存、储集因素,还有利于煤岩的高效利用,因此,实现显微组分的自动识别与定量具有重要意义[4-6]。随着深度学习在图像识别领域发展,前人运用机器学习技术研究煤岩显微组分,取得了良好的成果[7-9]。目前,已有不少学者尝试采用深度学习技术、卷积神经网络对煤岩显微组分图像进行分析与识别,Wang等[10]对比经典的深度学习分割模型,认为DeepLab V3+网络在中国烟煤显微组分的识别具有更高的分割效率和精度。Lei等[11]通过改进U-net网络,采用ResNet50主干网络,引入了注意力机制,实现对煤岩显微组分的精确识别。虽然烃源岩的显微组分识别方法与煤岩相似,但在客观上,沉积岩中的显微组分远比煤岩中复杂,煤岩的显微组分和烃源岩中的组分有着明显区别,主要体现在组分的类型、组成、形态及富集程度上,且不同丰度、类型及成熟度的烃源岩在显微组分构成上也存在差异。此外,根据中国石油天然气行业标准《全岩光片显微组分鉴定及统计方法》[12],对显微组分定量计算是判断烃源岩类型指数的重要指标之一。谢小敏等[13-14]利用Leica QWin_V3图像处理软件,通过对图片中的特殊区域进行选取,实现对全岩有机显微组分进行客观、快速的统计定量分析,并在近年来应用了综合矿物分析仪(TESCAN integrated mineral analyzer, TIMA)技术分析了Alum页岩的有机质和黄铁矿粒度分布特征,为石油地质研究者在快捷定量描述有机岩提供了新的思路。
现阶段,全岩样品或干酪根的有机显微组分识别大多仍然采用人工观测识别的方式,然后通过计数器或使用软件对显微组分进行统计定量,这类方式存在自动化程度低、结果易受主观因素影响、人工工作量大等问题。针对这些问题,现以皖泾地1井下三叠统殷坑组烃源岩为研究样品,设计了一个基于迁移学习的镜下全岩光片显微组分识别与定量实验,实现对全岩显微组分的自动分类识别,再利用OpenCV图像处理库对组分分类结果进行定量统计,以期改进全岩光片显微组分的识别方式,提高显微组分定量统计的效率。
1 分析框架
U-net网络在医学图像语义分割应用上有着出色的表现,显微组分的识别需求也同样类似于医学图像语义分割,不仅需要识别物体类别,也需要精准分割定位。由于烃源岩的多样性和复杂性,很难使用一种全面且统一的显微组分分类方案来描述烃源岩特征[15],因此,烃源岩显微组分的语义分割模型应当针对研究区显微组分的整体特点来构建相应的训练数据集,以使模型能够对同类型烃源岩的组分识别有更好的泛化能力。在构建数据集的初期,往往缺乏足够的训练数据,而迁移学习是一种有效的模型改进方式,能够在小样本的情况下获得比较好的训练结果,从而提升模型的训练精度和鲁棒性能[16-17]。本次实验首先在细胞分割数据集下完成U-net预训练网络的训练,然后将研究区不同深度的全岩光片显微组分图像作为训练数据迁移到预训练网络模型中微调模型的权值,获得新的分类模型,进而实现对显微组分图像中不同组分的识别与分类,最后通过OpenCV图像处理库进行定量处理,实验总体框架如图1所示。
2 实验样品
近年来,中国地质科学院地质力学研究所在皖南地区实施的皖泾地1井在下三叠统殷坑组钻遇良好的油气显示,引起了研究人员的重视。皖泾地1井殷坑组主要有灰岩和泥岩、泥灰岩不等厚互层, 总有机碳(total organic carbon, TOC)含量介于0.031%~1.7%,研究区显微组分特征如图2所示,有机显微组分主要以壳质组为主,多发育富氢强荧光的壳屑体,壳屑体在紫外光激发下发黄色、橙色荧光,反射光下呈红褐色。发育少量镜质体和惰屑体,荧光下均呈黑色。不同深度的样品,黄铁矿的数量差异较大,且形态复杂,有无规则、块状分布的黄铁矿、成团聚集的草莓状黄铁矿以及零散分布的近圆形的草莓状黄铁矿。

图1 实验总体框架示意图Fig.1 Schematic diagram of the overall framework of the experiment
3 实验预处理
3.1 图像采集
本次研究采用的数据集分为研究区数据集与预训练数据集两部分。在构建研究区数据集的过程中,为了提高模型对皖泾地1井殷坑组样品的适应能力,挑选不同深度、TOC的样品来进行实验,实验样品信息如表1所示。将样品沿垂直层理切割至合适大小,用环氧树脂粘结固化,再经粗磨、细磨、抛光处理形成块光片,将光片置于光学显微镜下,配制50倍油浸物镜拍摄,交替切换反射光与荧光光源采集图像。在采集研究区数据集图像的过程中,注意保持拍摄像机的曝光值、感光度、白平衡等摄影参数一致,收集高质量的训练样本图片。将采集到的图像各分为训练集、验证集、测试集。训练集用于匹配一系列参数来建立一个分类器,用于模型拟合数据样本;验证集用于调整模型的超参数和用于对模型的能力进行初步评估;测试集则用于检验最终选择最优的模型的性能[18]。研究区数据集包含反射光及荧光图像共490张,其中训练集样本272张,验证集68张,5个测试集样品各30张图像作为测试集样本,所有样本图像分辨率均为2 752像素×2 208像素。预训练数据集采用生物医学成像国际研讨会(International Symposium on Biomedical Imaging, ISBI)医学细胞分割数据集[19],该数据集包含训练图像及标注图像各30张,分辨率为512像素×512像素。
3.2 图像的人工标注
由经验丰富的有机岩石学学者使用LabelMe图像标注工具[20]对图像的各种显微组分进行组分的鉴定及标注。根据研究区样品的整体特点,标注分别为镜质体、惰屑体、壳屑体、草莓状黄铁矿,对部分特征难以分辨及实验中不关注的组分划分为矿物背景,如图3所示。值得注意的是,不同深度的样品,黄铁矿的数量和形态差异较大,故本次实验统一选取颗粒状明显的圆形草莓状黄铁矿进行标注。

表1 实验样品信息Table 1 Experimental samples information
3.3 图像数据增强
训练集和验证集图像的质量及数量都会对语义分割模型的性能和泛化能力产生巨大的影响[21-22]。为了防止模型过拟合,增强模型的训练精度和泛化能力,对研究区训练样本图像进行了更改亮度、翻转、旋转、小范围局部变形等图像数据增强处理(图4),对应的标注图像也随着形状及位置的改变而改变,对部分过度增强或信息缺失的图像进行剔除。增强后,训练集扩充至4 563幅,验证集扩充至1 141幅。

图3 人工标注示意图Fig.3 Schematic diagram of manual annotation
4 实验设计
4.1 模型构建

图4 数据增强处理示例Fig.4 Examples of data enhancement processing
U-net是一个优秀的语义分割模型,其包含编解码两个模块,整体呈“U”形,通过跳跃连接的方式将特征图进行维度拼接,能够保留更多的位置和特征信息,在小样本数据集上分割性能优于其他网络结构,且适合处理小尺寸物体的语义分割任务[23]。U-net左半部分为主干特提取网络,右半部分则是对提取的特征进行上采样。视觉几何组(visual geometry group, VGG)网络[24]结构清晰,特征提取能力强,在迁移学习中的泛化性能好。如王培珍[25]在ImageNet数据集基础上,使用VGG16网络完成预训练网络训练,结合煤岩壳质组样本对模型进行迁移学习,实现对壳质组组分高精度的识别。本次实验采用VGG16网络的作为U-net模型的主干特征提取网络,该网络结构及参数如图5所示。
实验采用的服务器硬件配置为: CPU 12th Gen Intel(R) Core(TM) i5-12600K 3.69 GHz; GPU Nvidia GeForce GTX 3060; Ram 32.0 GB; 软件环境为Windows 10 1909,使用Python语言开发,将Tensorflow作为本次深度学习框架,版本为2.4.1。在训练过程中,采用Adam优化器进行优化,采用Dice_loss损失函数完成网络参数优化,模型训练参数如表2所示。

图5 特征提取网络结构及参数Fig.5 Feature extraction network structure and parameters

表2 模型训练参数Table 2 Model training parameters
Dice系数是一种集合相似度度量函数,一般用于计算两个样本的相似度[26]。Dice_loss损失函数计算公式为
(1)
式(1)中:X为预测值像素点集;Y为真实值像素点集。
将研究区数据集迁移到以细胞分割数据集完成的预训练网络模型中进行训练,模型的损失值曲线如图6所示。随着训练次数的增加,模型的损失值在不断减小,在经过100个批处理后,loss值基本稳定,模型训练结束。
4.2 评价指标
如表3所示,混淆矩阵指在表中分别统计分类模型的分类情况,用于计算各种分类评价指标。
像素准确率(pixel accuracy, PA)、平均交并比(mean intersection over union, MIoU)、类别平均像素准确率(mean pixel accuracy, MPA)是语义分割模型中中常用的评价指标,其中PA表示预测类别正确的像素数占总像素数的比例,表达式为

表3 混淆矩阵
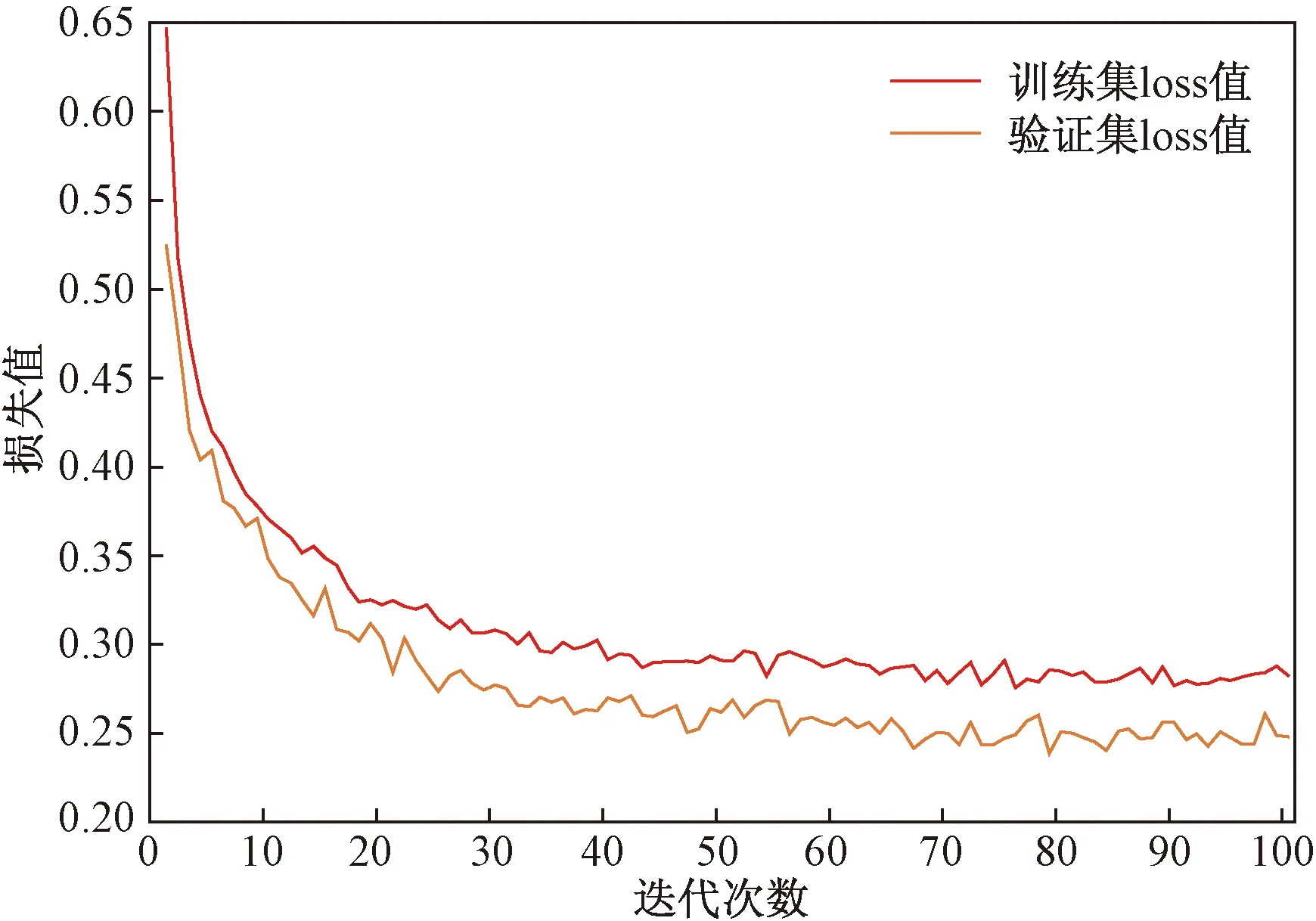
图6 模型损失值曲线Fig.6 Loss curves of the model
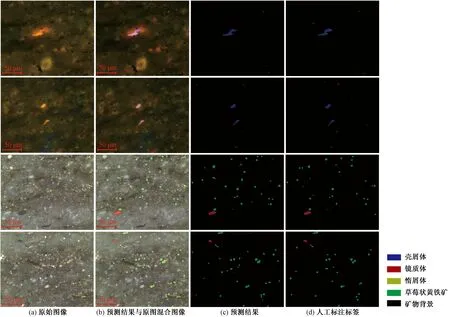
图7 分类结果比较Fig.7 Comparison of classification results

(2)
MIoU表示每一类预测的结果和真实值的交集与并集的比值,求和再平均的结果,表达式为
(3)
MPA表示对每一个类被正确分类像素数的比例累加求平均,表达式为
(4)
式中:C为总的分类数;M为样品总数;pmii表示第m个样本中属于TP的像素数;pmij、pmji分别表示第m个样本中属于FN和FP的像素。
4.3 实验结果
将5个样品,共150张测试集照片输入实验模型中进行自动识别与分类,模型各评价指标如表4、表5所示,部分分类结果对比如图7所示。可以看到,测试集在本次模型中的PA、MIoU和MPA分别为99.74%、74.81%和84.65%,表明实验模型有着较好的分割性能。从混淆矩阵的分类识别概率表可以看出,整体分类识别率为84.32%,其中镜质体和惰屑体识别率较高,分别有89%和87.7%。因为在反射光中,这两种组分边缘界限清晰,与周围的矿物背景有很好的区分,且整体光照明亮,成像效果好,因此识别率高。壳屑体识别率为79.2%,稍低于镜质体和惰屑体,一方面,壳屑体在较多透明矿物的环境下,荧光会产生不同程度的光晕;另一方面,荧光下,光源较暗,摄像机成像受一定影响,二者均会影响识别结果。草莓状黄铁矿识别率较低,仅有65.8%,主要因为在研究区的样品中,草莓状黄铁矿多聚集成团,容易出现粘连现象,且块矿类似,会干扰草莓状黄铁矿的识别。此外,被错误划分或漏分的组分都大多划分到矿物背景,说明模型对显微组分具有良好的特征提取能力。

表4 模型的分类性能评价Table 4 Classification performance evaluation of the model
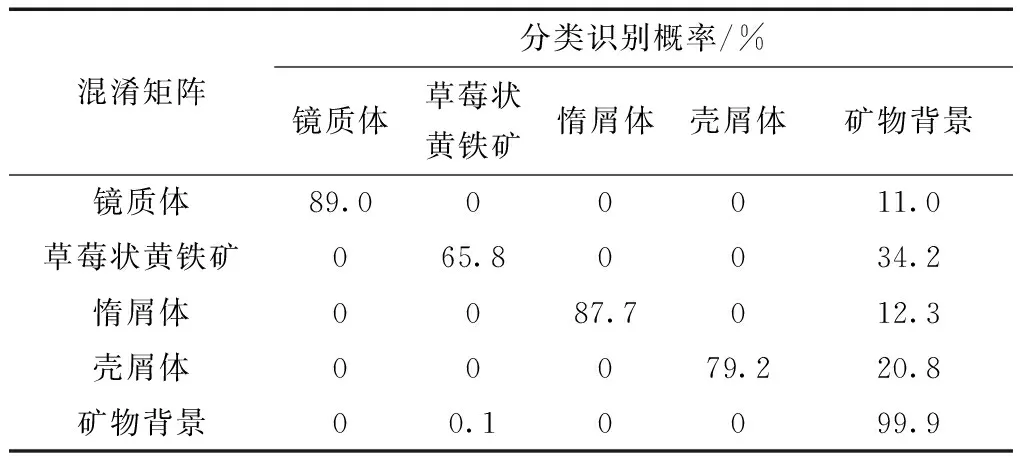
表5 各显微组分分类识别混淆矩阵Table 5 Confusion matrix of maceral groups
4.4 定量统计
OpenCV作为功能强大的开源计算机视觉和机器学习软件库,实现了很多图像处理和计算机视觉等方面的算法,能有效提升开发效率[27]。首先,对每一类组分的分类结果进行二值化处理,调用OpenCV中的findContours( )函数建立目标轮廓,然后调用contourArea( )函数对每一类组分遍历统计轮廓的面积并调用putText()和rectangle()将每个组分所占像素直观地显示在图片上,最后在后台统计各组分像素与总视域图像像素的比值作为显微组分的百分比,定量统计流程如图8所示。通过该方法统计5个测试样品的分类结果,与人工数点统计定量的结果相比,结果如图9所示,可以看出,本次通过OpenCV统计的有机显微组分体积百分比与人工数点统计的结果相近。150张测试集图像从模型分类识别到定量仅需数分钟,相较于传统人工识别与定量,显著地提高了工作效率。
5 结论
以皖泾地1井下三叠统殷坑组烃源岩的显微组分图像为训练数据,构建了一个基于迁移学习的U-net语义分割模型,开展了显微组分自动识别与定量的实验,得出以下结论。
(1)以VGG16网络为主干特征提取网络,构建基于迁移学习的U-net语义分割模型,该模型对研究区数据集的整体分类识别准确率可达84.32%,可以满足对研究区烃源岩显微组分进行客观、快速地识别与分类的需求。
(2)OpenCV图像处理库能对模型的分类结果的进行定量统计,统计结果与人工数点统计结果较为接近。
(3)本方法可以在短时间内对大量与研究区类型相近的烃源岩显微组分图片进行识别和定量,减轻了人工工作量,显著提高了全岩光片的鉴定及统计效率。

图8 定量统计流程示意图Fig.8 Schematic diagram of quantitative statistical process
