灾害大数据驱动的县域重大洪涝过程灾害风险评估*
2022-02-05刘蓓蓓郭桂祯
林 森,刘蓓蓓,闫 雪,孙 宁,郭桂祯
(应急管理部国家减灾中心,北京100124)
根据应急管理部发布数据,2021年我国重大洪涝灾害共造成5 901万人次受灾,因灾死亡失踪590人,倒塌房屋15万间,直接经济损失2 459亿元。其中,华北、西北地区洪涝灾害历史罕见,特别是7月份河南遭遇特大暴雨洪涝灾害,造成近1 500万人受灾,直接经济损失1 200亿元[1]。随着全球气候变化、极端气候事件频发和社会经济的快速发展,暴雨多、强度大、损失重已成为洪涝灾害的趋势[2-3]。减少洪涝灾害损失,减轻洪涝灾害风险是我国洪涝灾害风险管理中的必要任务。
风险评估是风险管理的重要基础。根据洪涝灾害风险评估的时间段,可分为针对区域历史灾害的风险分析和针对实时重大洪涝过程的风险预测两大类。前者可用于风险区划和洪水风险图编制,帮助政府制定长期规划,主要方法是通过指标体系对区域风险进行评估,一般选择致灾因子、承灾体、孕灾环境、防灾减灾能力等灾害系统相关指标[4-5],经过层次分析法、熵权法等方法确定指标权重,进行加权求得一个综合风险指数,在此基础上进行风险等级划分,此类方法主观性较强[6-7],结果以定性评价为主,另外还有模型模拟[8-9]、信息扩散[10-11]等方法。针对实时重大洪涝过程的灾害风险评估研究相对较少,其目的是对即将发生的洪涝过程预测承灾体期望损失和灾害风险分布,为灾害预警和应急响应提供依据。目前,国际上单灾种风险评估模型以半定量化和定量化模型居多,如美国的自然灾害风险评估模型(HAZUS)[12]、世界银行的概率风险评估模型(CAPRA)[13]等,这些模型大多基于致灾因子危险性(H) 、承灾体脆弱性(V)、承灾体暴露度(E)三要素[14]。对洪涝灾害而言,一般是将不同强度暴雨概率、承灾体脆弱性函数、承灾体分布三者进行耦合,构建定量化风险评估模型[15-16],用于评估单次洪涝过程可能造成的人口、房屋、农作物、经济等期望损失[17]。基于H-V-E框架的洪涝风险评估模型核心是计算不同暴雨概率和开展尺度适宜的脆弱性函数研究[18-21],该方法在应用中可能存在三个方面的困难:①尺度太小会导致样本量小,难以获取较好的回归函数,影响脆弱性函数表现[22],而尺度太大会导致脆弱性代表性不足;②建模复杂,需要分步骤开展危险性和脆弱性研究,而且不同强度危险性分级会造成计算结果离散化,不能形成连续度量;③难以考虑到灾害系统中其他指标,如孕灾环境指标、防灾减灾能力指标等[23]。
大数据背景下,数据驱动的机器学习算法应用逐渐增多,很多算法被用于建立灾害风险评估模型,其优势是能够利用大样本数据进行建模[24-25],建模过程淡化了传统灾害风险理论中危险性、脆弱性等概念,简化了模型搭建步骤,同时,还可以考虑更多的相关指标。例如,刘芳利用降雨量、孕灾环境等13个指标建立了人工神经网络(ANN)模型,用于对浙江的台风-暴雨灾害风险进行动态预评估[26];OPELLA等基于卷积神经网络(CNN)和支持向量机(SVM)算法建立了考虑10个指标的洪涝灾害风险评估模型[27];LI等利用13个指标对比了逻辑回归、朴素贝叶斯等模型在洪涝风险评估中的表现[28]。虽然上述方法在一定程度上提高了评估效率,但是仍存在明显缺点,主要是不易说明各模型参数的作用,类似于“黑箱”操作,无法解释不同指标在灾害风险评估中所起的作用[29]。集成学习方法正好能解决上述缺点,该类算法是将多个弱学习器组合建立一个强学习器,能够提高单一模型的泛化能力和稳健性。集成学习不但能提高预测准确率,更重要的是利用其原理可以有效评估指标对最终评估结果的贡献值[30-32]。其中,XGBoost模型被认为是集成学习算法中性能最好的方法之一。
我国目前已形成覆盖国家-省-市-县-乡-村六级的灾情报送网络体系,建成了长时间序列、高精细度的灾害事件案例库,为数据驱动的模型构建提供了保障。本文选取我国南方地区洪涝灾害案例作为训练样本,在县域层级收集可能影响重大洪涝过程灾害风险的23项指标,基于XGBoost算法建立重大洪涝过程灾害风险评估模型,对南方地区重大洪涝过程中人口、农作物、房屋、经济等损失风险以及综合风险进行评估,并验证指标量和样本量增加对于提升模型性能的意义。
1 数据与方法
1.1 研究范围
江淮地区、长江中下游地区、华南地区、西南地区等南方地区历来是我国洪涝灾害影响最大和损失最重的区域[33]。一般进入主汛期,南方地区会遭受多次大范围降雨过程,基本上每年都会有重大洪涝灾害发生。本文在县级行政单元的尺度上,收集了2012—2021年南方地区650个有灾情上报的重大洪涝过程案例,除去无法匹配降雨过程的,有625个案例用于模型研究,其中,621个案例用于模型训练,4个案例用于模型测试。训练案例共有12 640个县级样本,涉及江苏、浙江、安徽、福建、江西、湖北、湖南、广东、广西、重庆、四川、贵州、云南等13省(自治区、直辖市)1 120个县;测试案例是2021年7月洪涝过程,涉及安徽、湖北、湖南、重庆4省(直辖市)97个县(图1)。

图1 县级训练样本和测试案例分布(审图号:GS(2019)1823号,底图无修改,下同)
1.2 评估指标与等级划分
1.2.1 评估指标选取
洪涝灾害是由致灾因子、孕灾环境、承灾体、灾情损失构成的复杂系统,灾情损失是由致灾因子、孕灾环境、承灾体三个子系统相互作用的产物[34]。历史灾情能够反映区域灾害风险的大小,数据驱动的风险评估模型是通过探索历史灾情大数据与致灾因子、孕灾环境、承灾体等灾害系统指标的相关关系来建立。本文对上述625个洪涝过程分别匹配了4个维度23项指标(图2),数据来源如表1所示。
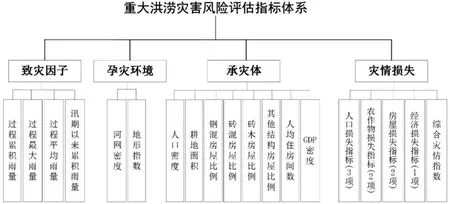
图2 重大洪涝过程灾害风险评估指标体系

表1 指标数据来源
(1)致灾因子指标。主要是重大洪涝过程的降水数据统计,包括洪涝过程的县域累积雨量、最大雨量、平均雨量以及汛期以来累积降雨量。其中,最大雨量是指洪涝过程的单日最大降雨量;汛期以来累积降雨量统计的是从当年5月1日起到当前过程发生时的累积降雨,考虑的是当年的累积雨量对当前过程的影响。
(2)孕灾环境指标。主要考虑河网和地形影响,包括河网密度和地形指数。其中,河网密度指县域内河道总长度占县域面积的比例,地形指数是水文模拟参数之一,可以表征区域径流面积、坡度等信息。
(3)承灾体指标。主要提供县域承灾体信息,包括人口密度、耕地面积、房屋结构及人均住房间数、GDP密度等指标。
(4)灾情损失指标。主要考虑国家自然灾害统计制度中涉及的指标,包括人口损失、农作物损失、房屋损失和经济损失。其中,人口损失指标用以评估人口损失风险,具体还包括受灾人口、死亡失踪人口、紧急转移安置人口等3项指标;农作物损失指标用以评估农作物损失风险,具体还包括农作物受灾面积、农作物绝收面积等2项指标;房屋损失指标用以评估房屋损失风险,具体还包括倒塌和严重损坏房屋、一般损坏房屋等2项指标;经济损失指标用以评估直接经济损失风险,含1项指标。
另外,综合灾情指数是基于灾情损失各类指标计算的一个指数,用以评估洪涝过程的灾害损失综合风险。综合灾情指数计算有多种方法[35-37],本文采用文献[35]的灾情绝对指数计算方法,对各项指标归一化后,采用加权平均计算,各指标项选取及相应的权重如图3所示。
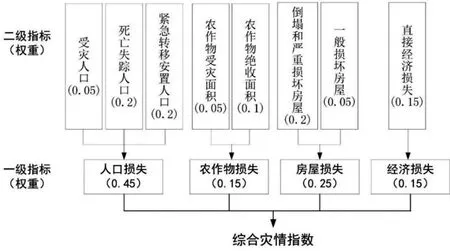
图3 综合灾情指数计算所用的指标及权重
1.2.2 灾情损失与风险等级划分
灾情损失与风险等级划分标准统一是评估模型的基础。本文将县域洪涝灾情损失划分为3级:轻灾、中灾、重灾,相对应的县域洪涝过程灾害风险评估结果等级划分为3级:有一定风险、中风险、高风险。这里认为凡是能预测到有损失可能性的都是有一定风险的,代替传统的低风险等级。实验中将对受灾人口、紧急转移安置人口、农作物受灾面积、倒塌和严重损坏房屋、直接经济损失以及综合风险等6项指标分别建模和评估,这些指标常用于实际风险管理工作。考虑到重大洪涝过程风险评估有实际业务倾向,每个指标的灾情损失或风险等级划分阈值的确定主要参考相关灾害管理办法和历史经验(表2)。
1.3 XGBoost算法
XGBoost是集成学习中Boosting家族中的算法[38],目标是将多个弱分类器提升为一个强分类器,用于数据集的分类或回归。XGBoost核心是对算法的损失函数加上了正则化部分,并且损失函数对每一步的误差部分做二阶泰勒展开,更加准确。XGBoost的损失函数形式为:
(1)
式中:L表示损失函数,t表示迭代次数,i表示第i个样本,m表示样本数量,f(x)和h(x)分别表示强学习器和弱学习器,J是叶子节点个数,ωtj是第j个叶子结点的最优值,λ和γ是正则化系数。XGBoost算法流程总结如下:
模型输入:训练集D={(x1,y1),(x2,y2),…,(xN,yN)},xi∈X⊆Rn,yi∈Y⊆R;损失函数L;最大迭代次数T。
模型过程如下:
(1)计算第i个样本当前轮损失函数L基于ft-1(xi)的一阶导数gti和二阶导数hti,然后计算所有样本的一阶导数和Gt以及二阶导数和Ht。
(2)尝试分裂决策树,默认分数score=0,G和H分别为当前需要分裂节点的一阶导数和以及二阶导数和,对指标序号k=1,2…K,有
①GL=0,HL=0。
②按指标k将样本从小到大排列,依次取出第i个样本,计算该样本放入左子树后,左右子树的一阶导数和以及二阶导数和:
GL=GL+gti,GR=G-GL;
(2)
HL=HL+hti,HR=H-HL。
(3)
③更新最大分数:
score=
(4)
(3)基于最大分数对应的指标分裂决策树。
(4)如果最大得分为0,则当前决策树建立完成,更新当前轮强学习器ft(x),进入下轮迭代;如果最大得分不为0,则转到步骤(2),继续分裂决策树。
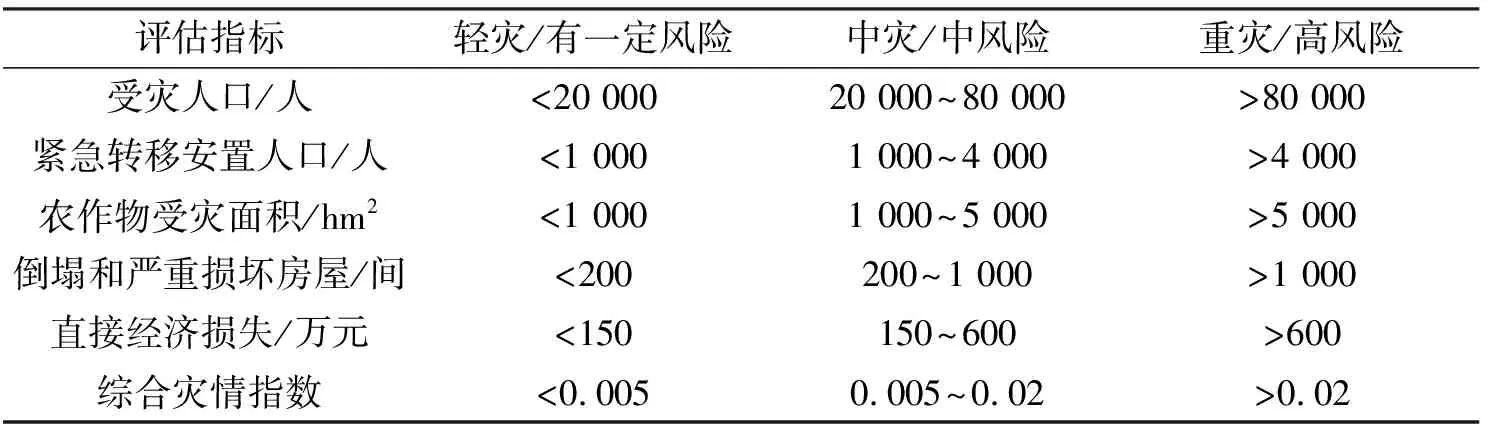
表2 县域灾情损失和风险等级划分阈值
1.4 模型建立与性能评估
本文基于XGBoost算法分别建立洪涝过程中受灾人口风险、紧急转移安置人口风险、农作物受灾面积风险、倒塌和严重损坏房屋风险、直接经济损失风险、灾害综合风险等6个风险评估模型。所有模型以致灾因子、孕灾环境、承灾体三类指标为输入向量,以不同损失风险等级为输出向量,具体模型建立流程如图4所示。

图4 基于XGBoost的洪涝灾害风险评估模型建立流程
其中,模型调参采用10折交叉检验优化参数,对XGBoost模型主要3个参数进行格网搜索,分别是弱分类器个数、决策树最大深度和学习率,6个模型最优参数及训练集准确率如表3所示。
为评估模型精度,选取准确率(ACC)、查准率(P)、召回率(R)、F值(F)等4个评价指标:
(5)
(6)
(7)
(8)
式中:TP表示真阳性(True Positive),即本身是正样本,预测也是正样本;TN表示真阴性(True Negative),即本身是负样本,预测也是负样本;FP表示假阳性(False Positive),即本身是正样本,预测是负样本;FN表示假阴性(False Negative),即本身是负样本,预测是正样本。上述评价指标中,准确率表示所有预测正确的样本占总样本的比例;查准率表示预测为正的样本中是真正的正样本的比例;召回率表示实际样本中的正例被预测正确的比例;F值是平衡查准率和召回率的指标,是二者的调和平均值。
2 结果与讨论
2.1 案例验证
本文以2021年7月中旬的南方降雨过程作为案例,验证基于XGBoost算法建立的重大洪涝过程灾害评估模型的应用效果。这次洪涝过程造成安徽、湖北、湖南、重庆等地97个县发生灾害,共造成90余万人受灾,直接经济损失近10亿元。
利用建立的模型分别对受灾人口、紧急转移安置人口、农作物受灾面积、倒塌和严重损坏房屋、直接经济损失、灾害综合风险进行评估,然后与县级实际灾情损失等级对比,结果如表4所示。
可以看出,模型整体上性能较优,除直接经济损失风险评估外,其他风险评估结果的准确率、查准率、召回率和F值都在80%以上,特别是紧急转移安置人口、倒塌和严重损坏房屋两项的准确率非常高,达到97%和98%,这可能因为在测试集中样本不平衡导致,这两项指标涉及到应急响应启动条件,该案例中均未达到启动条件;综合风险评估结果准确率为84%,考虑到防止过拟合的参数设定,该模型精度达到了预期效果,通过实际灾情(图5a)与风险评估结果(图5b)的空间对比,可以看出,模型评估在安徽、湖北、湖南、重庆都能够较好地预测洪涝过程的灾害风险;直接经济损失风险评估结果准确率相对较低,只有63%,可能的原因是直接经济损失在实际统计中较为复杂,包含了很多统计子项,不同地区、不同时间的直接经济损失统计标准可能存在较大差异。

表3 模型最优参数
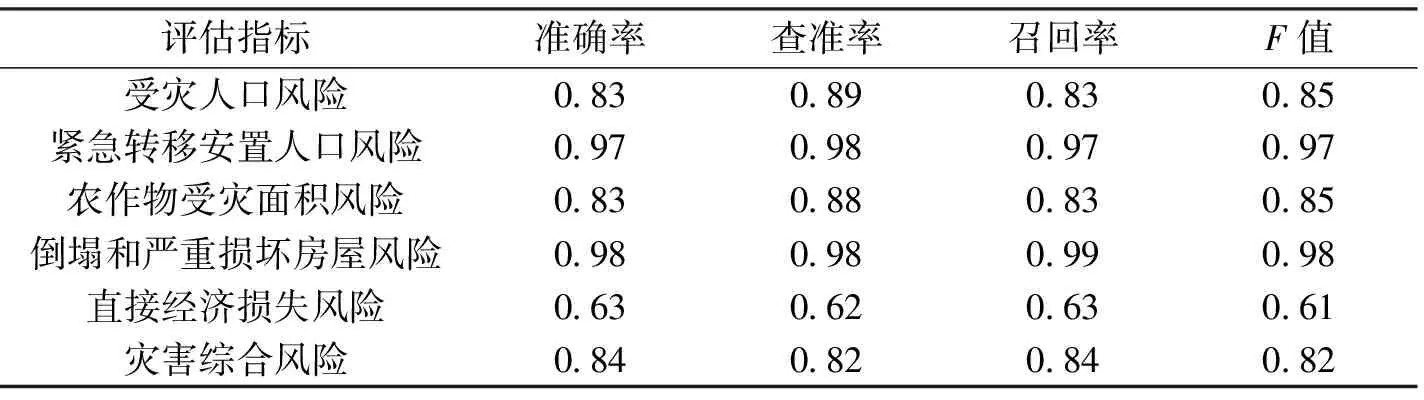
表4 验证集不同风险等级评估结果
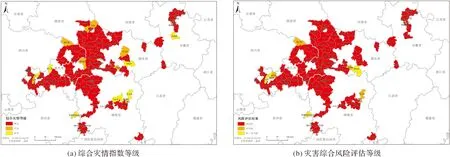
图5 测试集案例中实际综合灾情指数与模型评估的灾害综合风险对比

图6 不同风险评估类型的指标重要性
2.2 指标重要性
要理解影响评估结果的各种因素,有必要对各评估指标的具体贡献进行计算。XGBoost算法计算指标重要性的原理是一个输入指标在决策树分枝时是被选取为分枝特征次数越多,则该特征越重要。本文分别对6类风险评估目标进行了指标重要性计算,结果如图6所示。其中,影响受灾人口风险评估最重要的指标是过程累积降雨、人口密度、地形指数,表明致灾因子、承灾体、孕灾环境都对评估结果有所贡献;影响紧急转移安置人口风险评估最重要的指标是过程累积降雨、地形指数、河网密度,这与实际灾害应对过程相符,一般雨量大、地势险、离水近的人口在灾害应急中容易被转移;农作物受灾面积风险与地形指数、过程累积降雨、耕地面积、砖木房屋比例、人口密度有较大关系,特别是地形指数影响突出,说明农作物的受灾与孕灾环境有很强的关联;倒塌和严重损害房屋风险明显受过程累积降雨、人均住房间数、房屋结构比例、河网密度等因素影响,承灾体指标重要性突出;直接经济损失风险影响因素主要是过程累积降雨、河网密度,可见直接经济损失大小与致灾因子、孕灾环境密不可分;灾害综合风险的主要影响因素是GDP密度,可能的原因是GDP本身就是综合性指标,GDP既能反映区域的承灾体综合暴露度,也在一定程度上反映了区域的承灾体脆弱性,即一般情况下可以认为GDP高的地区比GDP低的地区综合防灾减灾能力要更强。总体来说,不同指标对不同风险评估结果的贡献并不完全相同,也没有一个指标的贡献率可以达到忽略不计的程度,各指标贡献率都在5%~12%之间。
2.3 指标量和样本量对评估结果的影响
为考察指标数量对评估模型精度的影响,本文对不同维度的输入指标进行了组合,比较了仅用致灾因子、致灾因子和孕灾环境组合、致灾因子和承灾体组合以及采用全部指标在洪涝灾害风险评估结果中的准确率(表5)。通过对比发现,指标量的变化对受灾人口风险、紧急转移安置人口风险、倒塌和严重损坏房屋风险3个模型评估结果影响较小。然而,指标量对农作物受灾面积风险、直接经济损失风险和灾害综合风险3个模型评估准确率有较大影响,如果模型输入只有致灾因子,准确率最低,比全指标偏低10%~15%;在致灾因子基础上,无论加入孕灾环境和承灾体指标,对准确率都有较大提升,而且承灾体指标比孕灾环境指标提升多,因为承灾体指标子项更多;而将所有指标一同作为输入,准确率最高,说明指标量对评估结果有很大影响。

表5 不同指标量的风险评估准确率
一般对某个区域进行灾害风险评估,往往仅选用该区域内相关灾害案例进行分析[19,21],这样可能导致区域样本量较少。为考察样本数量对评估模型精度的影响,本文对验证集中的安徽、湖北、湖南和重庆4个省(直辖市)案例进行对比。首先,提取各自省份(直辖市)2012—2021年的县域灾害数据样本;然后利用各省(直辖市)样本分别进行训练,建立各省(直辖市)基于单省份样本的综合风险评估模型;最后比较基于单省份样本量的模型和基于全样本量的模型在洪涝灾害综合风险评估结果中的准确率(表6)。可以看出,全样本评估对湖南评估结果准确率提升了13%,其他省份也有5%~10%的提升,这说明样本量的增加对各省评估准确率都有较大增益。

表6 不同样本量的灾害综合风险评估准确率
3 结论
本文基于我国南方地区625个重大洪涝过程案例的将近30万条指标,利用XGBoost算法建立了重大洪涝过程灾害评估模型,并以2021年7月中旬南方地区洪涝过程数据对模型进行了验证。结果表明该模型可用于重大洪涝灾害事件发生前对受灾人口风险、紧急转移安置人口风险、农作物受灾面积风险、倒塌和严重损害房屋风险、直接经济损失风险和灾害综合风险评估,对灾害风险管理业务有重要意义。研究主要结论如下:
(1)基于XGBoost算法建立的重大洪涝过程灾害风险评估模型适用性较好。通过测试案例验证,受灾人口风险、转移安置人口风险、农作物受灾面积风险、倒塌和严重损害房屋风险、灾害综合风险等5个模型在风险评估中的准确率、查准率、召回率和F值等性能指标均在80%以上,说明模型有较好的泛化性能,能够用于实际灾害风险评估工作中。
(2)模型可以通过计算重要性评价指标对风险评估结果的贡献度。除过程累积降雨指标对大部分评估目标都有影响外,不同风险评估目标的影响因素不同,如受灾人口、倒塌和严重损坏房屋受承灾体因素影响较大,紧急转移安置人口、农作物受灾面积、直接经济损失主要受孕灾环境影响,而灾害综合风险主要影响因素是GDP密度。指标重要性增加了风险评估模型的可解释性,提升了指标与评估结果之间关系的理解,有助于改进对机器学习算法“黑箱”模式的认识。
(3)指标量和样本量对于数据驱动的评估模型有重要作用。集成学习算法在灾害风险评估中淡化了危险性、脆弱性等灾害机理,纯粹利用灾害系统相关数据进行学习,建模较为简单,这也要求评估指标和样本数量要要有足够积累。一方面,致灾因子指标、孕灾环境指标、承灾体指标都对灾害风险评估结果有重要影响,利用全指标量比仅用致灾因子指标可以提高10%~15%的评估准确率;另一方面,样本数量增加1~2个数量级能够提高5%~13%的评估准确率。这表明灾害大数据对于提升灾害风险评估模型性能有很大帮助。
(4)模型仍存在一定的不确定性。由于选择的训练案例源自全国各地上报灾情,灾情本身是人为统计,存在着时间差异和地区差异,这可能也是模型在直接经济损失风险评估中没有其他风险评估结果准确性高的原因之一。另外,样本本身偏向于重大洪涝灾害过程,对于一般灾害的评估效果尚待验证。
本文利用灾害大数据建立了县域洪涝过程灾害风险评估模型。随着社会经济的快速发展,区域的承灾体和孕灾环境会发生很多变化,在今后的研究中,需要不断引入最新数据,更新和累积大数据,提升模型的可靠性。总结下一步工作,重点有三个方向:一是继续完善指标体系和样本分布,利用第一次全国自然灾害综合风险普查数据对指标进行更新,进一步完善模型;二是收集北方地区重大灾害过程案例,并验证模型在北方地区是否具有通用性;三是模型的推广应用,比如用于确定针对历史灾情分析时各指标权重,或用于缺乏资料地区的洪涝灾害风险评估等。
