基于集成学习的PET/CT混合成像肺癌检测
2022-02-04沈琳琳左长京
张 瑞,程 超,沈琳琳,左长京*
(1.深圳信息职业技术学院软件学院,深圳 518172;2.海军军医大学长海医院核医学科,上海 200433;3.深圳大学计算机与软件学院,深圳 518060)
肺癌是发病率和死亡率增长最快,对人群健康和生命威胁最大的恶性肿瘤之一。早期确诊对提高肺癌患者的生存率具有重要意义[1]。影像学技术对于肺癌的确诊起着关键作用[2],它可以发现肺部早癌细胞,保证对癌症的早期诊断和治疗。正电子发射断层扫描/计算机断层扫描(PET/CT混合成像)是用于检测肺癌的重要三维扫描成像技术[3]。随着影像扫描应用的日益广泛以及人工智能大数据时代的到来,利用PET/CT图像进行基于肺癌的计算机辅助诊断系统的研究越来越多[4-9]。Punithavathy等[10]提出了一种基于模糊C均值(FCM)聚类的方法自动检测PET/CT图像中的肺癌。文献[11]提出一种基于人工神经网络模型的肺癌CT图像分割算法。Wang[12]比较了四种经典机器学习方法和深度学习方法在PET/CT图像中肺癌分类中的应用。Ding[13]提出了一个新的基于深度卷积神经网络的肺结节检测方法。Xie等[14]提出了一种融合3种类型信息(Fuse-TSD)的肺结节分类方法。文献[15]通过基因数据与PET/CT影像数据相结合,提出了一种基于超体素的3D区域增长的肺结节分割方法以及一种多级加权的深度森林模型用于肺腺癌亚型分类。文献[16]提出了一种基于Mask R-CNN[17-18]的肺癌诊断方法。该方法仅针对PET数据进行了多尺度深度学习模型构建。文献[19]提出了一种基于集成学习的对PET/CT图像进行肺癌检测的方法,但该研究的数据量较少。文献[20]利用了集成学习的思想对PET/CT数据对初代CNN进行建模融合,实现了肺部肿瘤分类模型。
利用深度学习技术对PET/CT混合成像进行肺癌诊断的研究具有重要意义。基于多模态图像的肺癌智能检测的研究中的一个研究难点就是如何有效利用PET及CT图像特征减少检测中出现的过多假阳性结果。本研究提出一个新的方法解决该难点。
1 实验方法
1.1 方法流程
本研究利用多尺度多模态的集成掩模区域卷积神经网络(mask region-based convolutional neural network,Mask R-CNN)来解决伪阳性过多问题。首先建立5个Mask R-CNN模型用于肺癌候选区的抽取。5个模型基于PET与CT两种模态数据生成:3个模型用3种不同尺度的PET图像训练获得,2个模型用不同尺度CT图像训练生成。之后采用集成学习中的加权投票策略对5个Mask R-CNN模型进行融合。方法框架流程如图1所示。

图1 基于多尺度Mask R-CNN的肺肿瘤检测方法框架Fig.1 Framework of multi-scale Mask R-CNN based lung tumor detection approach
1.2 数据来源
研究使用的图片均来自上海长海医院核医学部(图片均已做脱敏处理)。利用西门子biograph64高清PET/CT扫描系统获得PET/CT图像进行实验。共采集80个病患的PET/CT数据。患者男女人数分别为48和32;年龄为20~80;体重范围为35~80 kg,身高范围为150~180cm。本次研究的病患诊断的金标准为组织病理学检查。本研究每个训练数据集包含来自62例肺癌患者的轴向横断面。其中PET数据训练集为594张轴向横断面,CT数据训练集为648张轴向横断面。测试数据包括270张轴位横断面,其中135个为PET横断面,135个为CT横断面:肺癌患者7例,PET横断面58张,CT横断面58张;正常人11例,PET横断面77张,CT横断面77张。图片数据详情信息见表1。
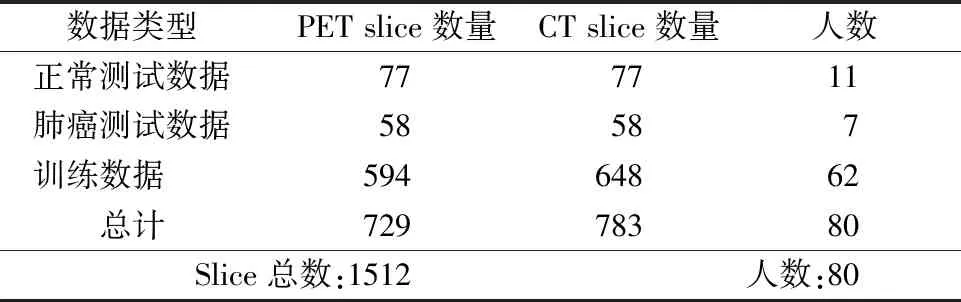
表1 训练数据及测试数据Tab 1 Training and test datas
1.3 评价指标和评价方法
F-score、Precision和Recall是人工智能癌症检测研究中最有效权威的评价指标。在本研究中,我们也使用这3个参数作为评价指标。F-score、Precision和Recall的计算方法如下:
(1)
(2)
(3)
其中TP表示真阳数,FP表示假阳数,FN表示假阴数[21]。Precision代表模型检测出的阳性中正确阳性所占比例,Recall代表模型检测出的阳性在所有正确阳性中所占比例。F-score是用来衡量二分类模型精确度的一种指标,它同时兼顾了分类模型的精确率和召回率,是最具有综合性评价的指标。
1.4 预处理和模型训练
利用PET/CT混合成像生成5个训练数据集:训练数据集1:分辨率为512×512的PET图像数据;训练数据集2:分辨率为768×768的PET图像数据;训练数据集3:分辨率为1024×1024的PET图像数据;训练数据集4:分辨率为768×768的CT图像数据;训练数据集5:分辨率为1280×1280的CT图像数据。
PET和CT图像的原始分辨率分别为168×168和512×512。PET和CT全身扫描分别由274个横断面组成,其中第40~120层的轴位横断面与肺区的位置相对应,故取第40~120层PET和CT横断面进行实验。在来自两名有资格且经验丰富的读影医生指导下,使用“Labelme”软件对所有训练图像进行标记。原始PET/CT图像和分割出肺癌的mask图像都包含在训练集中,如图2所示,左上图和左下图分别为PET和CT原图;右上图和右下图分别为肺癌在PET扫描和CT扫描中的mask图;中上图是肺癌mask图与PET原图的叠加图,中下图为肺癌mask图与CT原图的叠加图。

图2 PET和CT训练数据示例Fig.2 Examples of training image
为了适应不同分辨率和不同形态的肺癌大小,我们在每个模型中设置了5个anchors的比例参数:分辨率为512×512的PET图片设置为4,8,16,32和64;分辨率为768×768的PET图设置为8,16,32,64和128;分辨率为1024×1024的PET图设置为16,32,64,128和256;分别率为768×768的CT图像设置为16,32,64,128和512;分别率为1280×1280的CT图像设置为32,64,128,512和1024。对于3个PET模型,batch size设置为8;每个epoch的步数=50;epoch数量=300,学习率=0.000 1。对于两个CT模型,batch size=2;每个epoch的步数=200;epoch数量=300,学习率=0.000 1。
记录为Model-PET512、Model-PET768和Model-PET1024的3个PET模型可以得到不同PET图像尺度下的肺癌特征,为肺癌检测提供更深入的特征和信息。记录为Model-CT768和Model-CT1280的两个CT模型可以从另一种模态的成像方式提取肺癌的特征。之后通过集成学习将5个Mask R-CNN单模型进行组合以减少假阳性结果。
1.5 基于集成学习的多尺度和多模态Mask R-CNN单模型融合
上步骤中的PET与CT训练图像被用来训练生成PET与CT的Mask R-CNN模型。3个PET Mask R-CNN模型和两个CT Mask R-CNN模型用于肺癌候补区的检出。在这一步中,集成学习模型被用来将上一步骤的多尺度和多模态Mask R-CNN模型进行集合。集成学习模型包括两个部分:(1)癌症候选区配准;(2)单模型集成。
(1)癌症候选区配准
图3显示了5个单模型中的癌症候选区配准过程。图3(a)是测试图像在Model-PET512、Model-PET768、Model-PET1024、Model-CT768和 Model-CT1280的测试结果,每个圆形代表检测出来的阳性结果,即癌症候选区(Mask)。在图3(b)中,从 Model-PET512中的第一个癌症候选区开始,该癌症候选区被命名为Mask1,将其标签标记为1并先后与其他四个单模型中的癌症候选区Mask进行比较配准:如果Mask1与Model-PET768中某个癌症候选区的重叠率大于0.5,则将两个癌症候选区认定为同一个区域,将Model-PET768中的癌症候选区也标记为1。同理这种匹配过程用于Model-PET512与其他3个模型的癌症候选区配准。当Model-PET512中的所有的癌症候选区都被配准标号后,再从Model-PET768中还未被匹配的癌症候选区开始进行与后续3个模型进行配准操作,如图3(c)所示。以此类推5个模型中的所有癌症候选区都可以进行该配准操作,如图3(d)和(e)所示,即所有模型中的癌症候选区都被标号。图3(f)为最后的配准结果。
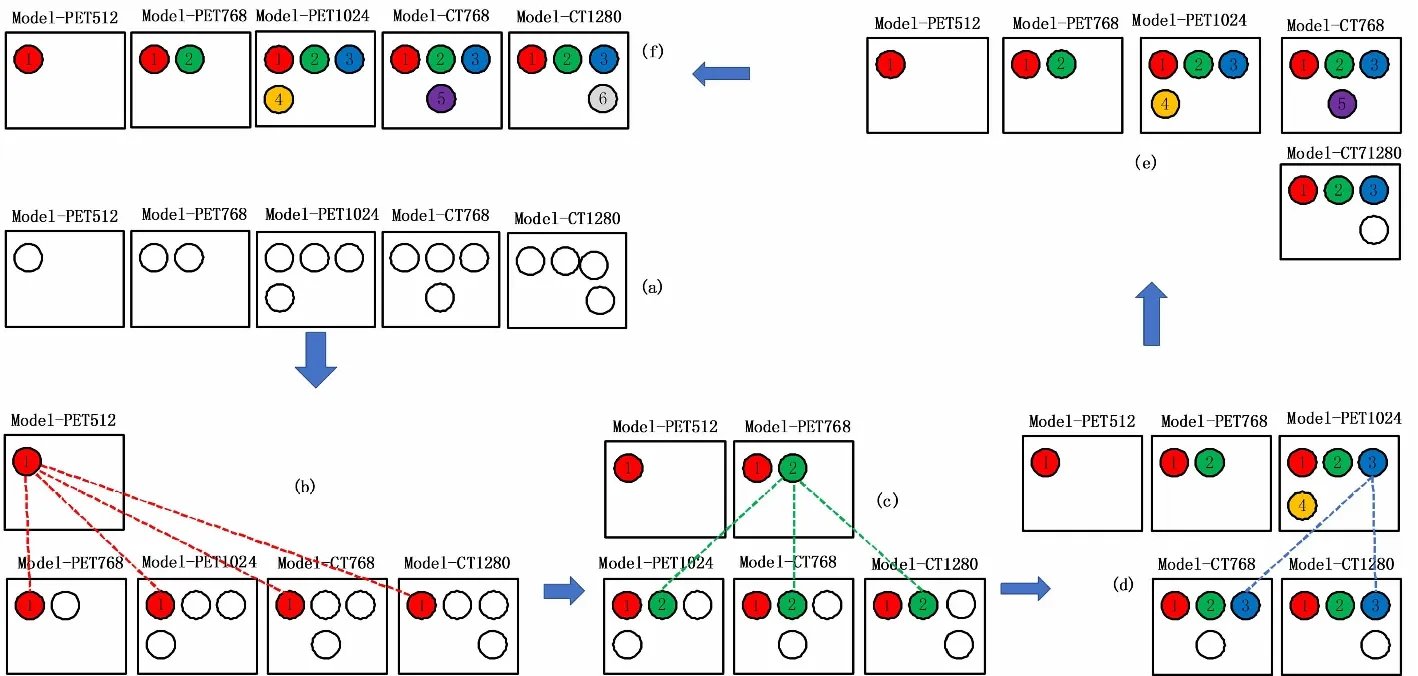
图3 对于5个单模型的匹配过程Fig.3 Matching and labeling operation
(2) 单模型加权集成
使用集成学习中的加权投票过程将5个单模型集成。每一个癌症候选区的置信度值被提取出来用做权值来进行投票。对于具有同一个标号的癌症候选区,即被认定为同一Mask,将其置信度值进行加和再重新赋值给这个癌症候选区。如果最终的置信度值小于某个固定的值,则该癌症候选区被认定为假阳,否则认定为真阳。
具有相同标签“i”的癌症候选区被视为同一肿瘤候选区,其表示为Maski;Ci表示其置信度。例如,Ci-PET512表示Model-PET512中Maski的置信度。Ci-PET512,Ci-PET768,Ci-PET1024,Ci-CT768,Ci-CT1280的值都在[0,1]的范围内,其中0表示在模型中找不到匹配的癌症候选区。具体集成投票操作伪代码如表2所示:

表2 集成投票伪码Tab.2 Pseudo code of voting
2 结果分析
2.1 集成模型与单模型结果对比分析
对集成模型和5个单模型结果及性能进行了分析。图4显示了5个单模型和集成模型的Precision、Recall和F-score的对比直方图。Model-PET512、Model-PET768、Model-PET1024、Model-CT768和Model-CT1280的Precision分别为0.87,0.83,0.72,0.69和0.75,说明每个单模型都有较多假阳性结果产生。集成模型的Precision为0.90,比性能最好的单模型Model-PET512高0.03。显然,最精确的结果是由集成模型产生。Model-PET512、Model-PET768、Model-PET1024、Model-CT768和Model-CT1280的Recall分别为0.86,0.94,0.94,0.82和0.75,最优单模型Model-PET768的值也低于集成模型0.06,说明集成模型对真阳结果的识别能力较好。最具代表性的综合性评价指标F-score在Model-PET512、Model-PET768、Model-PET1024、Model-CT768和Model-CT1280的值分别为0.86,0.88,0.82,0.75和0.75,集成模型中的F-score值为0.95,高于所有单模型。说明集成模型提取了最全面的特征,同时在减少伪阳性的误诊方面更加有效和精确。
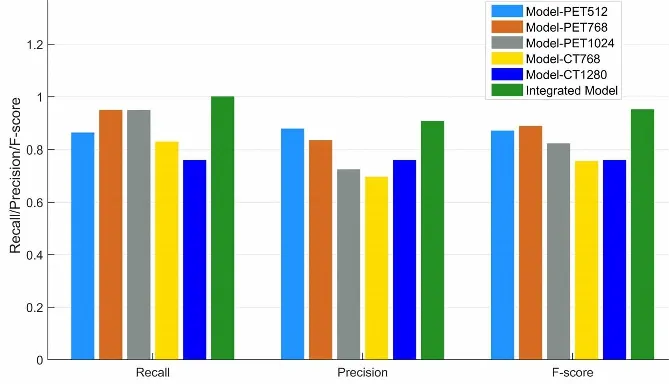
图4 集成模型和单模型precision,recall和F-score对比直方图Fig.4 Comparative histograms of precision,recall and F-score between single model and integrated model
图5显示了单模型Model-PET512、Model-PET768、Model-PET1024、Model-CT768、Model-CT1280和集成模型的P-R曲线。从图4可以看出,与5个单模型相比集成模型性能最好。说明集成模型可以融合五种单模型的优点。虽然每个单模型都会产生许多假阳性结果,但5个单模型的假阳性结果在空间位置上呈现交错分布,见图6。这五张图片来自同一个病人的同一个位置。左上图为Model-PET512试验结果,中上图为Model-PET768试验结果,右上图为Model-PET1024试验结果,左下图为Model-CT768实验结果,右下为Model-CT1280实验结果。经过测试后,Model-PET512出现假阳性结果,但由于在其他四个单模型中未提取出该假阳性结果,因此集成模型中该候选肺癌的加权投票值为0.983。由于该值较低,该候选癌症在集成学习中会被认定是假阳性结果,因此假阳性结果可以顺利排除。将这五种模型集成起来,从空间分布和加权置信度两个角度对每个癌症候选区进行分析和识别可以有效减少假阳性结果的发生,因此集成模型对肺癌检测的有效性更为显著。

图5 单模型与集成模型P-R曲线Fig.5 P-R curves for single model and integrated model

图6 假阳性的交错分布示例Fig.6 Staggered spatial distribution for false positives
2.2 加权投票和简单投票分析
本节比较了集成学习中的2种投票策略:简单投票和加权投票。简单投票使用1作为权重,5票被视为阳性结果的标准。加权投票和简单投票的Precision、Recall和F-score的数值如图7所示。简单投票和加权投票的precision值都为0.90;加权投票的recall为1,比简单投票高0.26。加权投票的F-score值为0.95,比简单投票高0.09。与简单投票相比,加权投票策略将Mask R-CNN产生的置信度作为分析和识别癌症的重要指标,有效的减少了假阳性结果,加权投票方法的性能优于简单投票方法。
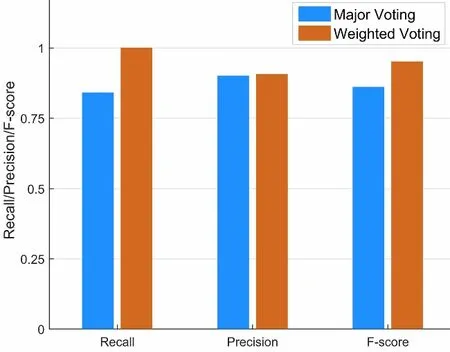
图7 简单投票和加权投票的对比直方图Fig.7 Comparative histograms of precision,recall and F-score between major voting and weighted voting
2.3 集成模型规模对比分析
集成模型由于兼具了不同单模型所提取出来的特征,因此具有比单模型更优的肺癌检测结果。将该集成模型与由3个最优单模型(Model-PET512、Model-PET768、Model-CT768)集成的Integrated Model-3[19]进行对比可以看出,本次实验的5个单模型集成效果更优。将单模型Model-CT512和Model-CT1024相继累加集成到本实验的集成模型上,分别生成模型Integrated Model-6和Integrated Model-7,通过其对应的PR曲线对比图和F-score对比图的图8可以看出,模型Integrated Model-6和Integrated Model-7效果没有更优。本文提出的方法F-score值为0.95,其他集成模型的F-score值:Integrated Model-3为0.94:Integrated Model-6为0.93:Integrated Model-7为0.92。说明数量过多的单模型进行集成不会使模型的精度提升,5个单模型进行集成的集成模型已经达到了最优的结果。
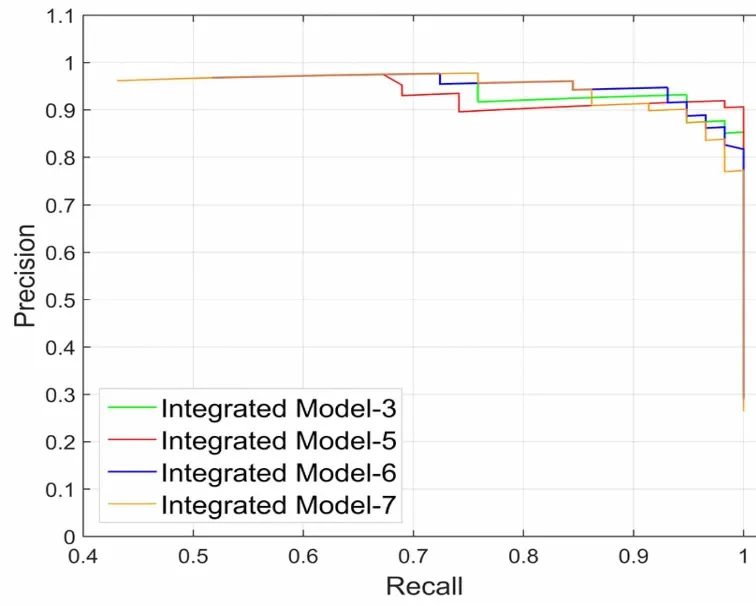
图8 集成模型规模对比图Fig.8 Comparative P-R curves and histograms of different Integrated Models
3 讨论
本研究提出了一种对PET/CT混合成像进行人工智能肺癌检测的基于多模态多尺度的Mask R-CNN集成学习新方法。集成学习是一种有效的将多个学习个体模型进行融合,使其可以执行深层次学习任务的框架思想,是目前多尺度多维度的深度学习热点研究方向之一。本研究结合不同尺度的CT特征和PET特征提取候选癌症区域,并利用集成学习将5个模型融合从而减少伪阳性结果数量。本研究使用的训练数据和测试数据总和达到了1512个PET/CT横截面,对比文献[19],本研究实验中的病患人数增加了26例,增幅为48%,训练数据数量增加了712个横断面,增幅为89%;测试数据量增加了110个横断面,增幅为69%;研究总数据量增加了552个横断面,总数据量增幅为59%。同时在集成方法上,本次研究采用了5个模型共同集成,比单模型所提取出来的特征更加详实,实验结果也证明本次实验所得到的训练模型相比文献[19]的三模型集成的准确率更高更稳定。文献[20]采用初代深度学习模型CNN LeNet-5进行建模,该深度学习模型主要用于图像的分类问题。方法需要首先对PET/CT图像进行事先的病灶手动分割,以分割出的病灶图块作为实验的输入。因此该文献方法实现了对肺癌病灶的分类,并不具有对整张PET/CT图像进行肺癌检测功能;同时方法采用少数服从多数的投票对3个分割图构成的模型进行集成。对比该方法,我们使用了最新的深度学习模型Mask-R CNN,并且以整张图片作为检测对象的输入实现了肺癌的检测,同时我们增加了更多尺度的PET、CT图像模型特征进行集成;并采用了加权投票的方式进行多模型的融合,将每个mask的置信度作为投票权值,对已经进行了空间位置配准的癌症候选区进行置信度的加和集成。本研究对加权投票和少数服从多数的简单投票也进行了对比实验,实验结果表明,本文的方法的Precision、Recall及F-score高于简单投票的对应结果,本研究方法实现了肺癌的检测并且可以完成更准确的肺癌分类。
4 结论
本研究提出了一种对PET/CT混合成像进行人工智能肺癌检测的基于多模态多尺度的Mask R-CNN集成学习新方法。该方法结合不同尺度的PET特征和CT特征提取候选癌症区域,并利用集成学习将5个模型融合从而减少伪阳性结果数量。实验结果表明,相比于单模型及简单投票集成,本文的集成模型可以提高肺癌的检测性能,并有效地减少假阳性结果。因此,本文方法可以为医生提供有效的辅助诊断信息。
