基于改进SOLOv2 的复杂场景下智能机器人巡检识别算法
2022-02-03吴忧,袁雪
吴 忧,袁 雪
(北京交通大学 电子信息工程学院,北京 100044)
伴随着国家的快速发展,工业所需的电站等电路基础设施越来越多,出于对安全的考虑,对电站的设备进行定期巡视检查显得尤为重要.通过巡检可以采集电站设备图像,监视设备信息以及故障报警,实现对电站设备的远程监控,及时排除安全隐患,减少设备故障,延长设备使用周期,避免停工停产维修带来的巨大损失.
过去的巡检方式主要是人工巡检,但工作效率和人员安全等方面存在着诸多问题,开始逐步采用巡检机器人和视觉技术相结合的方式解决上述问题.文献[1]利用图像复原、图像滤波及图像分割等传统视觉技术对变电站指针式仪表进行识别和后处理,能有效解决水雾和抖动等外界干扰因素造成的模糊问题.文献[2]使用基于粒子群优化SVM[3]算法建立煤矿设备匹配模型,实现巡检机器人对煤矿设备的精确识别与分类.文献[4]通过中值滤波方法除去图像噪声,利用颜色图像区域搜索紧急性目标区域定位,采用脉冲耦合神经网络对仪表图像中的数字实行分割和二值化处理,经过样本匹配算法实现变电站仪表识别.文献[5]采用模板匹配算法识别仪表读数,基于Hough 变换和线状特征判断指示灯、开关等设备部件的状态信息.文献[6]基于概率潜在语义分析(Probabilistic Latent Semantic Analysis,PLSA)的颜色属性训练算法确定开关柜状态指示灯的轮廓,采用HSV 判断指示灯的亮暗.
传统的视觉算法在实际应用过程中存在准确率低、速度慢的问题,为了满足工程应用的准确率和实时性,深度学习算法逐渐替代传统视觉算法用于巡检任务,其中包括目标检测、语义分割、实例分割等算法.目标检测算法,例如两阶段检测器R-CNN 系列[7-9]和单阶段检测器YOLO 系列[10-13],致力于预测图像中存在的感兴趣的目标的类别和边界框;语义分割算法,例如FCN 系列[14-15]和DeepLab 系列[16-20],从像素级理解图像内容,为图像中的每一个像素分配一个类别,但是对同一类别的不同对象无法区分;而实例分割算法与语义分割算法较为类似,但不同的是实例分割可以区分同一类别的不同对象,从而得到每一个对象的精确轮廓,主要包括两阶段实例分割Mask R-CNN[21]、TensorMask[22]和单阶段实例分 割YOLACT[23]、Blendmask[24]、Polarmask[25]、SOLO 系列[26-27]等.现有的部分研究已经将深度学习算法应用于巡检任务过程中,文献[28]通过传统的视觉算法提取图像中设备仪表状态信息,运用深度学习算法实时检测工作人员是否佩戴安全帽.文献[29]采用AlexNet[30]卷积神经网络对少量仪表设备进行识别和分类.文献[31]基于SSD[32]目标检测算法实现巡检图像中目标设备的识别及定位.文献[33]针对仪表所处的复杂环境提出基于YOLOv3[12]网络改进的仪表设备检测方法,对目标检测方法中的传统计算机视觉算法和深度学习算法进行研究分析.文献[34]提出一种改进的YOLOv4[13]网络结构满足指针式仪表实时识别定位,利用新颖的指针式仪表读数方法解决仪表读数误差大、泛化性差等一系列问题.文献[35]基于改进型YOLOv3 的配电设备检测算法,同时利用Mask-RCNN 算法对图像进行分割,与YOLOv3 算法相结合实现配电设备识别.
上述方法存在着三大问题:1)设备部件可识别种类较少、难以满足复杂场景多种类部件识别任务的实际需求.目前现有的智能巡检技术主要是针对于指针式仪表的识别,对于指示灯、开关等也有少量的研究,而且形态较为单一,无明显复杂变化.对于复杂场景下的多种类设备部件识别问题,现有技术无法完全满足需求;2)部分部件状态无法识别的问题.对于部分设备部件,例如开关,状态信息需要像素级的信息进行判断.在单一进行识别的过程中,现有技术可以较为粗略地获取其相关信息,但是在多类别、多数量识别任务过程中,现有的方法已无法解决这一类设备部件的识别问题;3)小目标部件识别效果较差.由于电站的设备部件愈变复杂、形状各异、类别多样,大、小部件之间的识别效果相差较大.小部件由于其像素信息较少导致模型在训练的过程中,对于小目标的训练不够拟合,使得小目标识别效果较差.同时设备部件的图像信息易受到尺寸变化、环境光照变化等影响,因此基于复杂场景下的多种类设备部件识别任务对算法的要求较高,目前的传统视觉算法、目标检测算法和语义分割算法在功能性上各自存在欠缺.
针对以上问题,本文作者提出基于改进SOLOv2[27]的智能机器人巡检识别算法,实现复杂场景下多种类部件识别——该算法不仅满足复杂场景下多种类部件识别的实际需求,而且有效解决了部分部件状态无法识别的问题,极大地改善了巡检机器人的使用场景;提高小目标检测精度——基于原始SOLOv2 算法进行创新性改进,改善了SOLOv2 在小目标上识别精度较低的问题,同时整体的精度也有一定的提升.
1 机器人巡检识别算法
本文提出一种基于改进SOLOv2 的智能机器人巡检识别算法.机器人按照巡检路线定点采集设备图像,将预处理后的设备图像送入识别网络中,定位到关注设备部件后,通过特定的状态信息读取算法对各个设备部件进行后处理,获取设备部件的状态信息从而达到实时监测的目的.机器人巡检识别的具体步骤如下:
1)巡检机器人根据固定路线巡逻,采集待检测点图像;2)图像预处理后传输至服务器端,同时客户端显示预处理后的图像;3)预处理后的图像进入识别网络,定位到图像中的关注设备部件,同时部件定位结果图显示在客户端;4)对定位到的关注设备部件进行状态信息读取,获取每个部件的状态信息,同时将部件状态信息同步显示在客户端,与预处理图像和部件定位结果图对应.总体流程图见图1,涉及的部件类别见图2.

图1 本文设计算法总体流程Fig.1 The overall flow of the algorithm designed in this paper

图2 本文处理的部件类别Fig.2 Component categories addressed in this article
为了巡检时获取较大的视野区域和广泛的场景信息,利用鱼眼相机进行图像采集,但是形成的图像会有一定程度的变形、扭曲,对后续的识别以及后处理会有较大的影响.为了消除一定程度形变的影响,需要对图像进行鱼眼矫正,使图像无明显形变、呈现清晰,矫正过程见图3 所示.

图3 图像预处理Fig.3 Image preprocessing
矫正原理如下:相机坐标系存在一点P(x,y,z),根据相机模型成像原理,未发生畸变时,点P的投影入射角为θ,像点为P0(a,b),极坐标形式为(γ,φ);实际上由于畸变的存在,实际的像点为P'(x',y'),光线出射角θd≠θ.
鱼眼相机的成像过程是根据入射角θ求解出射角θd,而鱼眼相机的畸变矫正过程则是根据畸变后的像点位置P'(x',y')求解实际入射角θ,其中相机焦距等各参数已知.根据成像过程可知

式中k1,k2,k3,k4是畸变参数,由相机标定结果提供.
使用牛顿迭代法求解θ:

循环迭代直到f(θ)≈0,或达到迭代上限次数从而求得θ.未畸变像点P0到相平面中心的距离:

由相似三角形原理可知
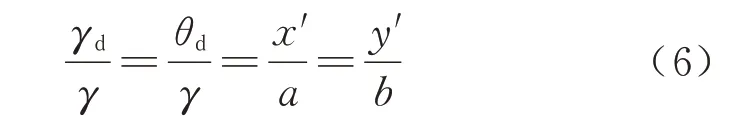
可以求得P0的坐标为

利用相机内参将P0(a,b)转换到像素坐标系即可得到未畸变的像素坐标.
2 部件识别算法
2.1 部件定位算法
实例分割SOLO[26-27]系列算法颠覆之前“自上而下”的先检测后分割的方式和“自下而上”的基于语义分割的方式,通过目标的位置和尺寸来区分,其核心思想是将实例分割问题转化为两个同时发生的子问题:类别预测和实例掩码生成,具体方法是将输入图像划分为S×S网格,目标中心落入的网格负责预测该目标的语义类别和分割该目标的实例.SOLO 系列算法属于单阶段实例分割算法,相比于两阶段实例分割算法具有更快的速度和更高的精度,目前已经有相关工作[36-38]基于SOLOv2 进行研究与探索,研究表明SOLOv2 在实例分割视觉任务中具有出色的性能.因此,本文以SOLOv2 算法为基础,实现机器人对设备部件的识别.
2.1.1 算法原理
SOLOv2 网络选 择ResNet[39]残差神 经网络 作为特征提取网络,通过FPN[40]特征金字塔输出不同大小的特征图作为预测头的输入,预测头将输入特征图划分为S×S网格,如果目标的中心落入网格单元,则该网格负责:1)预测语义类别;2)分割该对象实例,即为语义类别预测分支和实例掩码预测分支.特征提取网络结构、预测头网络结构分别如图4、图5 所示.
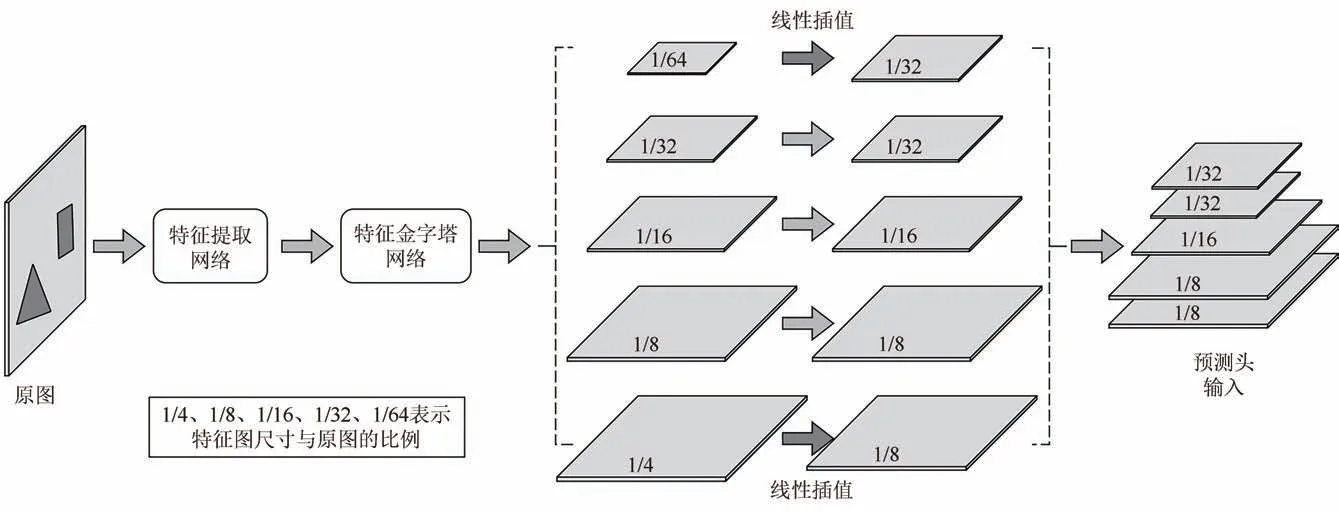
图4 特征提取网络结构Fig.4 Feature extraction network structure

图5 预测头网络结构Fig.5 Prediction head network structure
1)语义类别预测分支
对于每个网格,SOLOv2 预测C维输出来预测实例类别,其中C是类别的数量,输出空间为S×S×C维.
2)实例掩码预测分支
在语义类别预测的同时,目标区域落入的网格为正样本网格,每个正样本网格生成相应的实例掩码,最多生成S2个实例掩码,输出空间为HI×WI×S2维,第k个通道负责在网格(i,j)处分割实例,其中k=i*S+j(i和j从0 开始).因此语义类别分支和类别不明的实例掩码分支之间建立起一一对应的关系.
SOLOv2 通过动态卷积的方式,只对实例所在的网格进行语义类别预测和实例掩码预测,得到网格对应的语义类别和实例掩码,使用Matrix NMS[27]非极大抑制获得最终实例分割结果.
2.1.2 算法改进
本文的研究目标形状各异,种类繁多,目标之间差异性较强,SOLOv2 原始算法对形状大小不同的部件识别效果差异较大,尤其是较小部件的识别精度远远低于较大部件的识别精度.如图6 所示,无法定位到部分较小设备部件,从而无法完全掌握巡检现场的设备部件状态,如遇故障无法立即发现并解决,可能会造成严重的安全事故以及经济损失.

图6 小目标漏检Fig.6 Missing detection of small objects
SOLOv2 利用ResNet 残差网络提取图像特征,经过特征金字塔得到尺寸不同的各级特征图,每一级特征图分别进入预测头进行实例掩码和语义类别的预测.在特征金字塔网络各个尺寸的特征图输出中,小尺寸特征图具备较大的感受野以及丰富的语义信息,但分辨率较低,目标位置较为粗略,小目标信息严重缺失;而大尺寸特征图具备较高的分辨率、目标位置精确,但感受野较小,缺乏语义信息.为了减少计算量,不占用较大的内存,提高处理速度,特征金字塔网络往往舍弃大尺寸特征图或者对大尺寸特征图下采样之后进行特征融合,造成网络对于小目标的识别效果不好.因此,本文通过增加特征金字塔网络中较大尺寸层级特征图的输出,如图7 所示,增加小目标的正样本数量,提高小目标的识别精度.

图7 改进SOLOv2 后特征金字塔结构Fig.7 Feature pyramid structure of improved SOLOv2
SOLOv2 的预测头将输入特征图划分成S×S网格,不同层级的特征图对应的网格数S2并不相同,对应关系如表1 所示.SOLOv2 网络在计算预测值与真实值之间的损失的过程中,首先根据真实标签中实例所在区域的外接矩形框的面积所在区间,对真实标签中的实例进行网格数和层级的归属划分,与对应层级上的预测值进行对比,实现特征图中预测值与真实值在层级和网格数上的统一,通过相应的损失函数得到对应的损失,经过反向传播计算梯度从而更新网络参数.由此可知,增加特征金字塔网络的输出之后,面积区间的划分标准直接影响到增加的层级特征图的网格划分.SOLOv2 特征图尺寸和网格数、面积区间的对应关系如表1 所示.

表1 特征图尺寸和网格数、面积区间的对应关系Tab.1 Correspondence between feature map size,grid number,and area interval
2.2 部件状态信息读取算法
根据设备部件状态信息读取方式,将设备部件分为按钮类,开关类、文字类、消防类和仪表类,每个类别均有对应的状态信息读取算法,如图8 所示.

图8 状态信息读取算法Fig.8 Algorithm for reading status information
其中按钮类主要是将定位所得按钮图像进行HSV 颜色空间分离,即H--色调空间、S--饱和度空间和V--亮度空间,如图9 所示,亮暗两种状态下的按钮在V 空间下的像素值有较大的差别,通过反复实验,设定一组较好的阈值实现按钮的亮暗状态判断.

图9 按钮状态信息结果Fig.9 The state information result of button
文字类 主要是基于DBNet[41]和CRNN[42]的 文字检测和文字识别算法实现文字识别功能.通过大量的数据进行训练,使得文字检测和文字识别的模型泛化性较高,鲁棒性较强,运用于设备部件文字识别的准确率较高,如图10 所示.

图10 文字类部件状态信息结果Fig.10 The state information result of text component
对于实际场景下的消防类设备,主要的需求是判断关注的消防设备是否齐全,以达到在火灾发生时能及时通过消防设备进行灭火等一系列操作的目的.特定场景下,若定位到所有消防设备,则表示消防设备齐全.
设备中的开关类和仪表类部件是选择实例分割算法的关键所在,通过实例分割算法获取设备部件的具体轮廓区域,可以使其状态信息的判断更加精准.如图11 所示,旋钮处于不同形态时,所在区域的最小矩形框与水平线的夹角有所不同,因此可以根据包围旋钮轮廓的最小矩形框与水平方向之间的角度来获取旋钮的状态信息.通过观察以及实验,获取旋钮处于各个状态下的角度区间范围,设定阈值,实现旋钮精准状态获取,扳手阀门与旋钮较为类似.
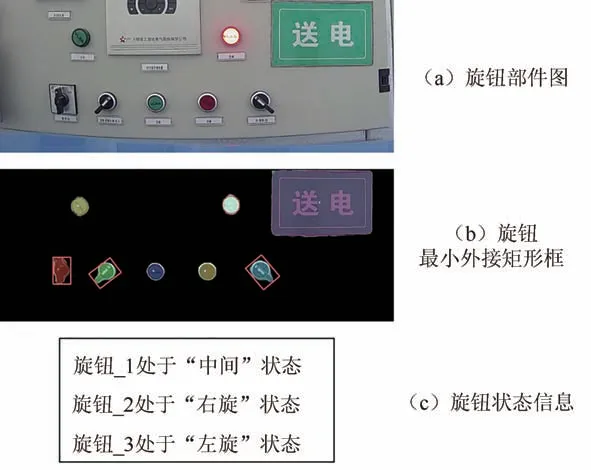
图11 旋钮状态信息结果Fig.11 The state information result of knob
设备中的仪表类也是众多论文中的重点研究对象,如图12 所示.本文对于仪表的状态信息获取是基于阈值分割实现的,对仪表进行像素阈值分割得到指针,通过霍夫直线原理得到指针的角度,利用指针的角度以及仪表盘的刻度精度进行计算得到较为精确的仪表读数.

图12 仪表类部件状态信息结果Fig.12 The state information result of meter component
3 实验结果分析
本文使用的数据集来自于山西某煤矿下的配电室以及水泵房等场景,包含各种设备部件的图像,通过亮度调整、旋转、翻转、平移等图像增强操作,并对数量相对较少的部件进行图像合成[43],图像的场景更具丰富性和多样性.数据集共计1 200 张图像,训练集、验证集和测试集按照8∶1∶1 的比例分配.图13为该数据集中部分图像,可见设备部件种类和数量繁多,形态复杂.

图13 数据集中部分图像Fig.13 Some images in the dataset
3.1 部件定位算法的比较
基于复杂场景下的多种类部件识别任务,分别采用传统视觉算法、目标检测算法、语义分割算法和实例分割算法进行实验,实验结果如表2 所示.分析实验结果得出,传统视觉算法无法实现多种类部件识别任务,只能对单一部件进行识别;目标检测算法无法获取目标轮廓的像素级信息,对于部分部件(例如开关类)状态无法识别;语义分割算法对于同一类别的不同实例无法区分,无法实现设备部件定位.因此,选取实例分割算法作为部件定位算法,具有较好的兼容性.

表2 设备部件定位算法对比Tab.2 Comparison of Equipment Parts Location Algorithms
3.2 实验参数设置
本文通过增加特征金字塔网络的大尺寸层级特征图的输出来提高小目标的识别效果,同时需要根据真实标签中检测框面积所在区间对真实标签分配合适的网格数,因此增加的层级特征图的尺寸(size)、检测框面积划分区间(scale range)和对应的网格数(grid)成为本实验三个关键的变量.上述三个变量具有强相关性,且检测框面积划分区间和网格数视增加的层级特征图尺寸而定,检测框面积划分区间和网格数之间互为影响.
1)增加的层级特征图的尺寸(size):设置增加的层级特征图的尺寸为网络输入图像的1/4、1/8.
2)检测框面积划分区间(scale range)和网格数(grid):增加大尺寸层级特征图的输出图后,设置[1/4 或1/8,1/8,1/8,1/16,1/32,1/32]六个层级的检测框面积划分区间和网格数组合如表3 所示.

表3 网格数、面积划分区间的组合Tab.3 Combination of grid number and area division interval
3.3 增加不同尺寸的层级特征图的比较
在特征金字塔网络的输出中分别增加网络输入图像尺寸的1/4 和1/8 的层级特征图输出,在测试集上的检测结果如表4 所示.由表4 可知,当检测框面积划分区间(scale range)=((1,32),(16,64),(32,128),(64,256),(128,512),(256,2 048))和网格数(grid)=52 固定时,特征金字塔增加网络输入图像尺寸的1/4 的层级特征图输出时表现的效果更好,不仅小目标的检测效果有较大的提高,而且整体的精度 也有一定的提升,同时检测速率基本保持一致.

表4 增加不同尺寸的层级特征图输出的对比Tab.4 Comparison of the output of feature maps of different sizes
3.4 不同组合检测框面积划分范围和网格数的比较
在特征金字塔网络增加1/4 尺寸层级特征图的前提下,对比多组检测框面积划分区间和网格数的参数组合,在测试集上的检测结果如表5 所示.由表5 可知,当检测框面积划分区间(scale range)=((1,32),(16,64),(32,128),(64,256),(128,512),(256,2048))和网格数(grid)=52 时,此时三个变量的组合在本实验中表现效果最好.

表5 检测框面积划分区间与网格数的不同组合的对比Tab.5 Comparison of Equipment Parts Location Algorithms
3.5 实例分割算法的比较
选择目前较为主流的实例分割算法Mask RCNN 与本文的所选用的实例分割算法SOLOv2 作比较,其中Mask R-CNN 属于“先检测后分割”的两阶段实例分割算法.在本文数据集上分别使用Mask R-CNN 和SOLOv2 两种实例分割算法进行训练,得到的模型在测试集上的检测结果如表6 所示.由此可知,本文使用的实例分割算法SOLOv2相比于Mask R-CNN 具有明显的优势,改进后的SOLOv2 算法相比于原始SOLOv2 算法在小目标检测精度上有较大的提升,整体的精度也提升了1.7%,速度上无明显降低.
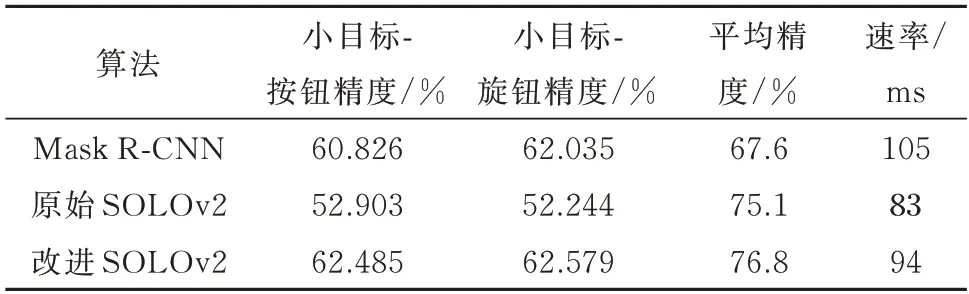
表6 实例分割算法对比Tab.6 Instance segmentation algorithm comparison
3.6 算法验证
为了进一步验证算法改进的有效性,在公开数据 集Cityscapes[44]上进行 相关实 验.Cityscapes 是 关于城市街道场景的语义理解图像数据集,主要包含来自50 个不同城市的街道场景,拥有5 000 张在城市环境中驾驶场景的高质量像素级注释图像,其中包含训练集图像2 975 张、验证集图像500 张和测试集图像1 525 张,图像分辨率为1 023×2 048.Cityscapes 数据集共有34 个类别像素标注,其中8 个实例级 分割类 别,即person、rider、car、truck、bus、train、motorcycle 和bicycle,属于小 目标类 别的是person 和rider.
改进SOLOv2 与基线方法在Cityscapes 数据集上的检测结果如表7 所示,从表中可以看出,改进后的SOLOv2 算法相比于原始SOLOv2 算法提升了0.6%,属于小目标类别的person 和rider 的检测精度也有相应的提升,速度上略有下降,其原因可能是添加高层语义特征图后,网络参数量变大,计算复杂度增加,导致推理速度有所下降.

表7 改进算法有效性验证Tab.7 Improved algorithm validation verification
本实验所用计算机配置GPU:NVIDIA Ge-Force GTX 1080、CPU:Intel i5-6800K、操作系统:Ubuntu 18.04.以PyTorch 作为SOLOv2 算法实现的基础框架.模型训练过程为多尺度训练,批次大小为2,初始学习率设置为0.001 25,每次训练共36 轮.
4 结论
本文首先介绍了智能机器人巡检识别算法的现状以及存在的问题,在此基础上提出了基于改进SOLOv2 的智能机器人巡检识别算法,将更加快速、高效的算法运用于智能机器人巡检过程,同时对原始SOLOv2 算法进行创新性改进,实现了以下几个功能:
1)通过实例分割算法实现了复杂场景下多类别设备部件巡检的需求,有效地解决了识别单一场景的局限性,同时解决了以往算法对部分部件状态无法识别的问题.
2)通过对原始SOLOv2 算法的创新性改进,提升了小设备部件的识别精度,同时整体的精度也有一定的提升,确保设备部件的识别达到实际场景需求.
随着数据库的逐渐丰富,小目标的识别精度将会逐渐提升,整体将会呈现一个较好的效果.对于光照太强、曝光较严重的图像,本文提出的算法暂时无法达到较好的检测效果,需要进一步的研究.
