基于常规临床检验指标构建子痫前期风险预测模型
2022-02-02王浩乌永嘎郭玉婷梁雨朝李海成周健夏书琴左永春
王浩,乌永嘎,郭玉婷,梁雨朝,李海成,周健,夏书琴,左永春
(1.内蒙古大学生命科学学院,呼和浩特 010070;2.内蒙古智汇大数据研究院,呼和浩特 010000;3.内蒙古医科大学&内蒙古临床医学院,呼和浩特 010110;4.内蒙古自治区人民医院妇产科,呼和浩特 010017)
子痫前期(preeclampsia,PE)是指发生于妊娠20周后,以高血压、蛋白尿为主要临床特征的常见妊娠并发症,在发展中国家发病率高达10%,是造成孕产妇及胎儿患病率和死亡率增高的主要原因之一[1]。目前有很多针对PE的筛查项目,但PE早期预测效果不佳,亟待开发快速有效的早期诊断模型。
近年来,研究人员利用机器学习算法针对临床检验指标对妊娠期疾病开展了一系列研究。Betts等[2]用梯度提升树构建用于预测产后并发症的风险模型,表明常规健康数据在确定女性因常见产后并发症入院的风险方面发挥了重要作用。张心远等[3]通过收集PE和健康妊娠孕妇的凝血、血常规等临床检验数据,利用LightGBM预测PE,取得了较好的结果。Rasmussen等[4]利用游离RNA(cfRNA)特征预测PE的发病概率,敏感性达75.00%。Wu等[5]开发了妊娠期糖尿病分层预测模型,为孕妇16孕周前筛查妊娠期糖尿病提供了一种简单有效的方法。
本研究基于多项临床检验指标,建立了一种特征筛选策略Tuning Relief F (TURF)与机器学习方法K-nearest neighbor (KNN)相结合的PE预警模型,实现了对PE的准确预测。
1 对象与方法
1.1研究对象 选择2019年1月至2021年12月于内蒙古自治区人民医院妇产科就诊的346例健康孕妇为对照组(HE组),年龄23~40(30.4±4.9)岁,单胎妊娠,临床资料完整,初次入院孕周 37~40(39.4±1.0)周;另选取同期就诊的PE孕妇 342例为实验组(PE组),年龄 22~44(31.7±5.3)岁,初次入院孕周 23~37(35.7±4.3)周。
PE患者符合第9版《妇产科学》中关于PE的诊断标准,妊娠20周后,患者静坐休息5 min后测量血压,2次测量至少间隔4 h,血压高于140 mmHg/90 mmHg,合并有尿蛋白≥ 0.3 g/24 h或随机蛋白尿(尿蛋白+),或者患者合并出现腹痛、肺水肿、肝肾功能异常、血小板下降等症状;单胎妊娠;临床资料完整。排除患有慢性高血压、心脏病、自身免疫病、肾脏疾病、合并其他妊娠期疾病等。
收集年龄、收缩压、舒张压、BMI、初次入院孕周、初次入院实验室资料(血常规、尿常规、生化全项、凝血功能)等,排除含有缺失值的指标,最终纳入87个特征指标用于分析。
本研究经内蒙古自治区人民医院伦理委员会批准(批准文号:202201004L)。所有参与者签署知情同意书。
1.2数据预处理 收集所有研究对象(688例样本共87项指标)的血常规、尿常规、生化全项和凝血四项检测数据。对过滤后样本的临床检测数据集进行标准化,然后按照3∶1的比例将688份样本数据拆分为包含516份样本的训练集和172份样本的测试集,见表1。

表1 临床检验数据集组成
1.3特征选择策略 对高维数据的计算分析及其解释对于理解模型决策至关重要。LASSO和TURF将特征选择过程从单轮推进到多轮过程,对所有特征评分[6]。通过使用TURF和LASSO 2种特征选择策略对87个临床检验指标进行评分并根据分值从大到小排序。基于增量特征选择策略(incremental feature selection, IFS),使用4种机器学习分类器拟合TURF训练集数据。
1.4机器学习模型 K近邻(K-nearest neighbor,KNN)[7]、支持向量机(support vector machine,SVM)[8]、随机森林(random forest classifier,RFC)和XGBoost 4种机器学习算法被用来构建PE预测模型,并比较预测性能,选择最优模型。基于python包xgboost(1.5.2)构建XGBoost模型,基于python包scikit-learn(1.0)构建SVM、RFC和KNN模型。
1.5五折交叉验证 五折交叉验证即对数据进行5次划分,每次选取4份样本为训练集建立模型,1份样本为测试集评估预测效果,每次记录模型分别在训练集和测试集上的预测结果和预测误差,如此重复5次,最后将5次的预测误差取平均值,得到1个综合的预测误差估计值。五折交叉验证法的实现以及各个预测模型的模拟计算与预测分析均通过python编程实现。
1.6模型评估 基于五折交叉验证策略,用准确率、召回率、F1 measure和精确度4个经典指标评估模型的预测性能[9-10]。准确率=(TP+TN)/(TP+TN+FP+FN),召回率=TP/(TP+FN),F1 measure=2×(准确率×召回率)/(准确率+召回率),精确度=TP/(TP+FP)。TP、TN、FP和FN分别代表真阳性、真阴性、假阳性和假阴性。用ROC曲线定量评估模型的整体性能,通过计算ROC曲线下面积(AUCROC)客观评价预测器的性能。
1.7SHAP解释方法 SHAP是在合作博弈论启发下构建的加性可解释模型,其核心是计算出每个特征的SHAP值,能够反映特征对整个模型预测能力的贡献程度。

2 结果
2.1基线资料 与HE组比较,PE组年龄、收缩压、舒张压和BMI均升高,初次入院孕周降低(P均<0.05),见表2。

表2 HE组和PE组一般资料比较
2.2构建PE预测模型
2.2.1基于特征选择策略构建预测PE最优模型 基于增量特征选择策略,评估机器学习算法在不同数量特征集下的预测性能结果见图1A。SVM随特征数量的变化,预测性能波动剧烈,另外3种机器学习模型随特征数量的变化则呈现出逐渐平稳的趋势。
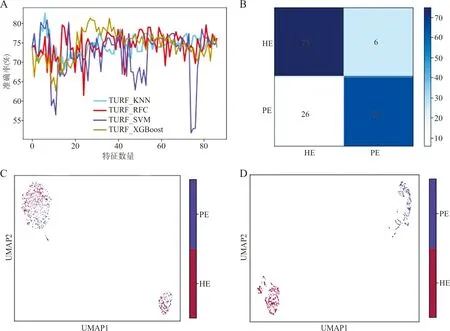
注:A,基于增量特征选择策略,评估机器学习算法在不同数量特征集下的预测性能;B,基于7个特征,KNN在测试数据集的混淆矩阵;C和D,UMAP显示原始特征集和TURF最优特征指标之间HE组和PE组的聚类情况(C,原始特征集,D,TURF特征集)。图1 模型的预测表现
4个基本分类器基于TURF和LASSO预测PE性能的训练集结果见表3。基于TURF,XGBoost在使用28个特征指标时表现最优,准确率为88.15%。KNN和SVM同样有优异表现,基于TURF特征策略,在仅使用7个和8个特征指标的情况下,准确率分别达到了82.55%和84.68%。基于LASSO选择的7个最优特征子集,4种机器学习模型也同样达到了较优异的预测结果,KNN、SVM、RFC和XGBoost的准确率分别为75.58%、75.58%、75.00%和75.00%。TURF特征策略更适合用于进一步分析和建模。

表3 4个基本分类器基于TURF和LASSO预测PE的性能(训练集)
2.2.2基于测试集验证PE预测模型 用完全独立于训练过程的测试集验证4种模型的可靠性和稳定性,见表4。SVM在使用8个特征指标时,准确率、精确度、召回率和F1 measure分别为80.81%、84.52%、78.02%和80.14%。RFC在使用15个特征指标时,准确率、精确度、召回率和F1 measure分别为79.53%、65.07%、85.11%和75.57%。XGBoost在使用28个特征指标时,准确率、精确度、召回率和F1 measure分别为81.28%、85.22%、74.48%和80.42%。
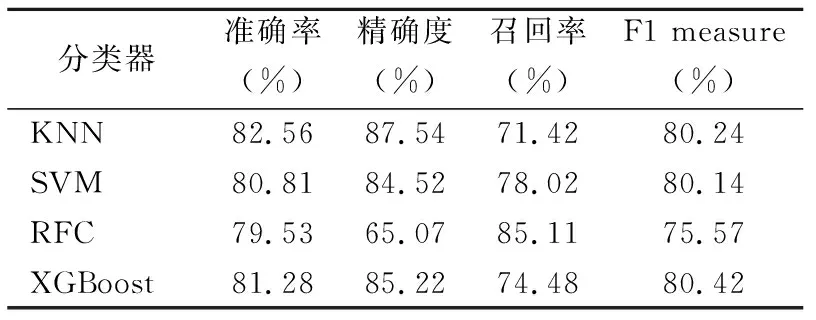
表4 4个基本分类器基于TURF识别PE的性能(测试集)
当K=14时,KNN算法在仅使用7个特征指标时表现最为优异,准确率、精确度、召回率和F1 measure分别达到了82.56%、87.54%、71.42%、80.24%。进一步通过模型在独立数据集的ACC表现来评判其鲁棒性,SVM、RFC和XGBoost均出现了不同程度的过拟合现象,然而KNN表现优异,准确率和精确度均优于其他模型且展现出优异的鲁棒性。
ROC曲线显示,基于TURF特征子集,KNN预测模型的AUCROC达0.90,可以将PE与HE区分开来。基于TRUF特征策略的KNN算法被选择搭建基于临床检验数据预测PE的机器学习模型。
KNN预测PE和HE表现的混淆矩阵见图1B,6个健康妊娠样本被预测为PE患者,26个PE患者被预测为HE,总体预测性能优异。分别以全部特征指标和7个特征指标为输入变量,使用均匀流形近似和投影(uniform manifold approximation and projection, UMAP)对所有样本进行聚类分析,见图1C和1D。当使用所有特征指标进行降维聚类时,PE和HE夹杂在一起,冗余信息使样本几乎无法区别;当使用7个最优特征指标时,PE和HE完美地分开;表明采用的特征选择策略有效过滤掉了冗余信息,筛选出了关键的特征指标。最终,尿蛋白、尿电导率、血尿酸、碱性磷酸酶、乳酸脱氢酶、平均红细胞血红蛋白浓度和淀粉酶被确定为最具有诊断PE能力的7个指标。
2.3PE预测模型的特征解释 用SHAP解释7个特征指标见图2。图2A显示尿蛋白值越高对模型预测性能的提升越大,乳酸脱氢酶升高同样与模型预测性能呈正相关;反之,淀粉酶值越低会改善模型的预测性能;而碱性磷酸酶、尿电导率、血尿酸和平均红细胞血红蛋白浓度似乎没有显著影响模型的决策能力。用7个特征指标SHAP值的平均绝对值来观察如何影响模型,见图2B。结果表明尿蛋白对于模型做出决策有绝对的影响力,淀粉酶会影响模型对HE做出决策,乳酸脱氢酶会影响模型对PE患者做出决策,碱性磷酸酶、尿电导率、血尿酸和平均红细胞血红蛋白浓度没有显著影响模型做出决策。

注:A,样本特征SHAP值;B,样本特征SHAP值平均绝对值的柱状图。图2 SHAP值解释预测模型特征
2.4预测模型揭示在常规临床检验数据中的PE关键指标 比较7个特征指标的表达水平,HE组和PE组差异有统计学意义(表5)。

表5 7个特征指标在HE组和PE组中的表达水平
2.5网络服务web平台搭建 为方便用户使用,搭建网络服务器来实现PE的预测功能,见图3,免费访问网址为http://bioinfor.imu.edu.cn/ipreeclampsia。

注:A,PE预测平台主页;B,用户通过点击“SERVER”进入到预测功能模块;C,用户可以直接在表格中键入数据或者点击“Upload File”上传需要预测的数据文件,点击“Submit”将获得预测结果并通过“Disease Diagnosis”获取到所有样本数以及对应标签,最终通过“Download”可以将预测结果下载至本地电脑。图3 基于常规临床检验指标的PE预测模块
3 讨论
PE除了产生不良妊娠和分娩结局外,还可能通过胎盘功能障碍、妊娠期缺氧缺血环境、异常炎症水平和表观遗传变化等途径增加子代对疾病的易感性,如免疫病、代谢综合征、神经发育和精神障碍[11]。目前有大量关于PE风险预测的研究,但研究质量参差不齐、预测步骤繁琐且精确度不高,后期缺乏有效的临床验证,最终这些预测方案并没有落地于临床实践[12]。本研究结果表明,基于血常规、尿常规、生化全项和凝血四项结果的基础临床检验数据可以实现对PE患者的有效预测。使用TURF策略去冗余后得到的7个特征指标作为KNN输入特征构建的PE预测模型取得了优异性能,准确率达到了82.56%。此外,通过模型解释探究了7个特征指标如何影响模型做出决策,例如,尿蛋白和乳酸脱氢酶值的升高会提升模型预测效果。通过比较7个特征指标在PE患者和健康孕妇中的表达水平,进一步证实了其可以作为PE预测的关键指标,然而血小板减少、血清转氨酶升高、血肌酐升高指标并未成为最优特征,可能与PE临床表现多样性有关。
Poon等[13]根据PE表型的异质性和预测的复杂性提出了PE筛查的最佳方法是在母体风险因素的基础上,加入各项生物学指标,包括平均动脉压(MAP)、子宫动脉多普勒参数和不同的血清学指标建立预测分析模型。PE确诊的金标准是在女性妊娠20周后出现高血压伴随尿蛋白显著增加[14],与本研究结论一致。此外,碱性磷酸酶和乳酸脱氢酶在PE患者中发生变化,且通过机器学习模型发现其可能会增加PE患病风险,并有可能成为PE的风险标志物[15-16]。平均红细胞血红蛋白浓度在PE中明显低于HE组,可以用于预测PE[17]。PE与血尿酸水平有关,血尿酸浓度的变化可能是由于PE初始阶段的代谢改变,血尿酸促进炎症和氧化应激功能障碍,是PE的可靠预测因子[18-19]。淀粉酶和尿电导率在PE中的作用很少受到关注。本研究有效地整合了上述指标,有助于建立良好的预测模型。此外,本研究根据得到的预测模型提供了PE预测web服务器。
本研究也存在一些不足之处:(1)数据均来源于内蒙古自治区,可能存在选择偏倚,需要外部验证进一步评估模型的性能;(2)研究中部分指标的缺失率偏大,如孕前BMI是孕产妇产检的重要指标,但在本研究中由于该指标缺失率偏大而未纳入模型中,重要指标的缺失可能会对模型的效能产生一些影响。
