高速铁路周界快速识别算法研究
2022-02-01朱力强许力之王耀东
朱力强,许力之,周 鑫,王耀东
(1.北京交通大学 机械与电子控制工程学院,北京 100044 2.北京交通大学 载运工具先进制造与测控技术教育部重点实验室,北京 100044)
基于视频图像的智能分析技术能有效检测出侵入铁路周界内的异物,是铁路安全防灾系统的重要一环[1]。判断异物是否侵限需要获取精确的铁路周界即轨道区域的边界及位置。传统的处理算法大多针对监控区域固定的相机采集的图像进行处理,并需要手动标记报警区域。随着我国高速铁路的快速发展,铁路沿线的监控相机数目激增,对所有相机内的场景进行标注需要耗费大量的时间和人力成本。同时大量布置在铁路沿线的可变焦的云台相机,随时可能因不同的需求而改变拍摄角度、焦距等,导致监控场景改变,使得报警区域需要手动的重新标定。故把能学习特征后自动识别目标的深度学习算法应用到周界识别中,实现不同场景内周界区域的划分,将大幅度提升检测系统的工作效率和精确度。在实际工程应用中,需要将算法移植进沿线不同配置的数据处理平台,即要求设计的检测算法具备良好的识别精准度,同时算法的计算量要足够小。
周界识别可归为分割问题,目前分割算法主要有传统算法和基于深度学习两种。传统算法基于阈值、区域和目标纹理等信息划分出不同目标区域,如Achanta等[2]基于简单线性迭代聚类的超像素算法,该方法将图像由RGB颜色空间转换到CIE-Lab颜色空间,并和X、Y坐标组成5维特征向量,然后通过K-means算法进行局部聚类获取目标边界。文献[3-4]提出一种多尺度组合聚合(MCG)算法,在多尺度融合的基础上,引入随机森林回归器提升区域组合以及目标生成的方式。房泽平等[5]提出基于特征颜色和SNCC的交通标志识别与跟踪方案,基于图像的YCbCr颜色空间进行阈值分割,并设计标准的匹配模板来定位和识别交通标志。Verbeek等[6]提出一种基于马尔科夫随机场的区域分类算法,并结合基于方面的空间模型,提高了区域级分类的精度。文献[7-9]基于K-means聚类算法,设定基于场景的颜色聚类规则,对所有碎片化区域中的连通域进行分析后进行组合与聚类。以上传统分割算法计算耗时较长,在不同的场景运用需要进行调整,且无法获得目标的语义信息。
深度学习算法可根据任务分为目标检测和语义分割两大类,目标检测网络有基于单阶段检测和基于两阶段检测两种,两阶段检测算法如R-CNN系列[10-13],首先生成大量的候选区域,再对各候选区域进行分类。单阶段检测算法如YOLO系列则略过了生成候选区域阶段[14-18],但在图像的不同尺度特征图的每一个像素位置预设了大量不同尺度的先验框,最后直接预测产生物体的类别和位置。然而无论是单阶段还是两阶段的目标检测算法,依赖的锚框均不能精确地适配周界区域,无法直接应用于周界识别。语义分割网络如FCN等[19-22]对图像中所有像素进行分类,所以网络需要的尺寸较大,其中包含的上采样的结构导致计算量比目标识别网络大。以上问题使得分割网络依赖于高性能GPU显卡,为获取区域的精准度需要较长的计算时间不利于将算法移植进在铁路沿线的端侧数据处理平台层。
因此,结合目标检测算法和语义分割算法的优点,提出一种基于特征点识别的目标检测网络算法,实现铁路周界区域的实时识别。该算法在保证网络精确识别周界的前提下,压缩网络参数进一步优化模型,提升网络速度。
1 基于特征点的周界识别网络
提出算法方案不同于传统目标检测算法需要依赖检测目标锚框,而是直接对铁轨、护栏的特征点进行识别。算法整体方案见图 1,首先对图像中的铁轨、护栏等边界上的特征点进行标注,然后设计深度神经网络实现对特征点的识别,最后利用识别的特征点集进行曲线拟合从而获取精确的周界区域。

图1 基于特征点的周界识别方案
1.1 数据标注方式
传统的目标检测标注方式见图2(a),该标注方案同时包含轨道区域和轨道周围的无关区域。当物体侵入该部分区域时,无论物体在轨道内还是轨道外,视频监控系统都会进行报警,导致容易出现大量误报为入侵的情况。语义分割网络虽然能精准的识别出铁路周界区域,但是网络尺寸大,计算量高,不适用于铁路沿线数据处理设备。因此,需要在传统目标检测基于边界框的方案上进行改进,通过小计算量的网络模型,划分出更为精准的报警区域。

图2 周界不同的标注方式
提出基于特征点的周界识别算法,通过识别铁轨和护栏的特征点后再拟合出精确的周界。该方案的标注方式见图2(b),首先将护栏按照左右两侧的不同特征分别标记为主护栏Fm和侧护栏Fs,然后周界内四条铁轨分别标记为四类R1、R2、R3、R4,最后将周界内区域划分成两部分:护栏区域和轨道区域。其中两侧的护栏区域由最外侧两条铁轨R1、R4和护栏Fm、Fs分别连接而成,轨道区域由最外侧两条铁轨R1和R4连接而成。
手动标记的特征点并不能包含周界上的所有特征点,因此需要将标注的数据概率化生成热图。首先将六类特征点(左右侧护栏、四条轨道)分开单独进行处理,再将手动标注的特征点在该类热图上的位置值设为1,通过图3所示高斯核,将特征点位置附近的区域都置为0~1之间的数代表真值,最后将每类特征点的真值图转为热图。图4为数据集中单幅图像的热图,六张图片分别代表R1、R2、R3、R4、Fm、Fs六类特征点的热图。

图3 高斯核热图

图4 热图数据集
1.2 特征点提取网络LDNet
为了兼顾准确率和模型大小,选用VGG16网络模型作为基础网络。卷积神经网络中不同尺度的特征图提取的是网络不同的图像信息,因此需要针对周界特征点的识别任务改进VGG16网络模型。改进的网络模型为LDNet,其结构见图5。

图5 多尺度信息融合网络结构LDNet
网络结构的改进步骤如下:
Step1全连接层改进
使用卷积层替代VGG16中的全连接层,网络最后直接生成热图与真值比对进行损失计算。使用卷积层替换后三层全连接层后,网络参数减小了2~5个数量级,有效地减小了原网络模型的规模。
Step2多尺度信息融合
浅层网络输出的特征图包含丰富的几何细节信息,如点和线的位置信息,但语义信息表征能力较弱;深层网络输出特征图中含有更多的语义信息,但缺乏对空间几何细节信息的感知能力。网络模型实现精确的铁路周界特征点识别,既需要铁路周界特征点在图像上的空间细节信息,也需要通过丰富的语义信息识别不同的周界线。因此需要融合计算的多尺度特征信息提升模型特征点识别能力。在全连接层改进后的VGG16网络基础上,加入池化层和卷积层Conv7增大模型的感受野。
模型中同一尺度的特征由相同序列不同的卷积核计算得到,图5中Conv6下两个蓝色的特征图(尺寸为:19×19×1 024)是Conv6-1和Conv6-2计算所得,其他序列类推。
选用Conv2-2、Conv3-3、Conv4-3、Conv6-2、Conv7五个卷积层的输出(分辨率分别为:150×150、75×75、38×38、19×19、10×10)分别代表了五个不同尺度的信息进行融合。信息融合方式为首先对低分辨率的特征进行Squeeze层压缩,然后对压缩后的特征反卷积到与高分辨率特征同一尺度,最后再与高分辨率特征进行像素级点乘。在训练过程中,每一尺度的信息经过Squeeze层压缩后的特征,都会与热图标签计算损失进行反向传播,即图5中四个绿色的Squeeze层与最后两个蓝色的预测层,总共计算6个尺度信息的损失。以图5网络模型最后一层Conv7输出的1 024个通道的10×10尺度特征为例。首先将该特征图输入到Squeeze7层通过1×1卷积核压缩成6个通道做检测(与标签计算损失);再将6个通道信息输入到反卷积层Deconv7,得到19×19×1的特征信息;最后与模型Conv6-2输出的19×19×1 024特征的每个通道信息进行点乘。后续计算以此类推,直至与模型Conv2-2输出的150×150×128特征相乘后,通过Conf_layer和Loc_layer分别计算得到置信度预测结果(150×150×6)和位置偏差预测结果(150×150×2)。其中置信度预测结果的像素点值表示为该点属于六类特征点的概率值,置信度预测结果每个像素点值代表该点与真值的位置偏差,两个通道分别预测X、Y两个方向上的位置偏差。
以上搭建的网络模型称为LDNet,由图5可以看出,LDNet可分为三大模块,包括由VGG16改进的基础特征提取模块(白色网络层);多尺度特征融合模块的Squeeze层和Deconv层(绿色网络层和黄色网络层);以及最终用于周界特征点预测的Conf_layer和Loc_layer(蓝色网络层)。LDNet网络每层配置如表1所示,其中Conv1代表Conv1-1、Conv1-2,其他层以此类推。

表1 LDNet网络配置
1.3 网络损失函数
网络损失Λdet分为置信度损失Λconf和位置损失Λloc,计算式为
Λdet=Λconf+λlocΛloc
( 1 )
式中:λloc为位置损失权重,取1。
使用Focal Loss计算置信度损失
( 2 )
( 3 )
( 4 )
式中:Lk为每k个尺度的Focal Loss;N为图像中关键点的数量;训练过程中,γ设为2,β设为4。
训练过程中,LDNet中共有五个尺度的信息参与了置信度损失的计算,即图5中绿色网络层输出的特征和Conf_layer蓝色网络层输出的特征。因此总置信度损失计算式为
( 5 )
式中:n代表一共有n个尺度的信息;Λi是根据式( 2 )计算的当前尺度的置信度损失;αi为当前尺度置信度损失的权重因子,对150×150的尺度置信度损失取2,其他尺度取1。
网络位置损失基于L1 loss,L1 loss计算式为两数差值的绝对值,具体如下
( 6 )

1.4 网络训练与数据后处理
选用Adam优化器,可大幅度提升网络的学习收敛速度,并容易获得更优的模型参数。网络训练超参数设置如下:学习率基于迭代次数进行阶梯状变化,初始学习率设置为0.000 1,在迭代8 000、10 000、12 000次后学习率依次减小10倍。设置每次输入的数据Batch size为2,Batch Normalization的权重衰减系数设置为0.000 1,动量参数为0.9。训练经过30 000次后完全收敛,收敛后网络输出的热图见图6,每个尺度的热图从左至右依次代表R1、R2、R3、R4、Fm、Fs。

图6 网络输出不同尺度热图
使用Conf_layer输出150×150的热图用于拟合周界曲线。见图7(a),首先将热图的每一行搜索一个概率最大值标记在原始图像上。然后对于每一个概率大于0.4的行最大值,加上Loc_layer预测的位置偏置值变换至原图像的真实坐标位置。最终将每一类筛选出的值做多项式拟合并连接,得到四条边界线fm、fs、r1、r2。其中r1、r2两条线组合形成轨道区域,fm和fs根据边界线的起始点位置排序决定分别与哪一条铁轨组合形成对应的护栏区域,当fm起始点在r1左侧时,fm和r1组合而成的区域作为主护栏区域。最终排序后四条边界线组合成的周界区域,见图7(b),其中包括轨道区域(红色区域)、护栏区域(蓝色区域和绿色区域)。
由图7可以看出,LDNet能在多场景、白天黑夜、雾天雨天等多张状况有效识别周界上的特征点,并对特征点拟合合成精准的周界。

图7 算法最终输出结果
2 基于特征相似度的LDNet网络裁剪
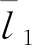
( 7 )
对于LDNet识别铁路周界的特征点过程,虽然各通道特征图的l1范数值能有效代表对应的卷积核是否有用,但不能判断该卷积核是否为冗余的卷积核(即其他卷积和与其贡献相近),同样不能代表当该卷积核与模型最终输出结果的相关程度。由于LDNet每一尺度反卷积生成的特征的六个通道均包含了需要识别的六类特征点的信息,故利用LDNet网络结构中的反卷积层输出的特征信息能有效判断卷积核是否冗余,LDNet各尺度反卷积结果见图8。

图8 LDNet各尺度反卷积结果
将LDNet中每个卷积核输出的特征图与其尺度相同的反卷积结果进行比较,当卷积核与反卷积输出的特征越相似,说明该卷积和对最终输出的影响越大,该卷积核对最终结果是否精确越重要。将图8的这四种尺度反卷积特征图作为模板,然后把模型每个卷积核与对应相同尺度的模板的差值计算l1范数。l1范数越大,说明该卷积核与模板匹配度越小,对结果的贡献度也越小。在实施裁剪过程中,通过计算卷积核在训练集中结果的l1均值后进行排序,l1均值越大,则该卷积核序列越靠后,对应的通道则为可以裁剪的通道。特别的,LDNet中Conv1-1和Conv1-2输出的为300×300特征图,Conv7输出为10×10特征图,按特征图l1范数准则裁剪,则最终裁剪准则如下
( 8 )
式中:size为当前卷积核输出的特征图尺寸;Sxi为第i张图片xi输入网络后生成的对应尺度的特征图模板。
为了对比本文裁剪准则(基于特征相似度)与其余两种裁剪准则(基于特征图l1范数,基于卷积核l1范数),把数据集中每个场景的50个图像用于计算卷积核与输出的相似度-‖Fxi-Sxi‖,并按升序进行排序可视化。图9为三种裁剪准则排序结果,基于特征相似度和基于特征图l1范数变化趋势相近,这二者与基于卷积核l1范数变化趋势差异较大。虽然前两种裁剪准则的曲线走势大致相同,但对卷积和的排序结果有区别的。以第20个卷积核的特征相似度和特征图l1范数作为基准线为例,前20个卷积核对应的特征图l1范数有一部分是低于基准线的,而基于特征相似度的没有这种情况,后续将通过实验讨论这三种裁剪方式对检测结果的影响。

图9 特征相似度、特征图l1范数与核l1范数准则排序结果
3 分析与讨论
为了验证算法的可行性,从铁路视频监控系统收集了多场景多状况的图像数据,包含白天、夜晚、直道、弯道、公铁跨桥、无护栏等多种铁路场景图像数据3 816张,并以6∶2∶2的比例划分成训练集(2 288张)、验证集(764张)和测试集(764张)。由于监控系统中采用的相机不同,采集的原图尺寸大小有1 920×1 080和1 280×720两种,为了保证输入图像尺寸统一和减少深度学习算法的计算量,统一将图像缩放至300×300。使用LDNet进行计算,并进行裁剪实验,将裁剪前后网络性能与其他算法作对比,实验平台为采用统一配置,Intel i7处理器,16 GB内存,不使用GPU 显卡。
3.1 性能评价指标
基于提出的周界识别算法方案,本章基于运行速度和对样本是否分类正确的判断进行评价。按分类是否正确将最终的预测值分为四类:真正例TP、真负例TN、假真例FP、假负例FN。
语义分割的性能评价指标采用mPA、mIoU,根据置信度阈值判断像素点是否分类正确,计算式为
( 9 )
(10)
(11)
式中:PA为像素精确率,mPA为所有类别的平均像素精确率;mIoU为所有类别的平均交并比;k为除去背景的k个类别目标;pij为属于第i类但被预测为第j类的像素点的总数目,即pii为TP,pij为FN,pji为FP。
3.2 裁剪准则有效性验证
在应用中,通常根据实际任务所需的处理速度和内存大小来确定对模型的压缩比。一次性将模型裁剪成所需的大小容易裁去一些潜在有用的卷积核,破坏了模型的结构,导致很大的精度损失以及大幅度识别准确度降低。因此采用多次裁剪的策略,选取每次最合适的裁剪比例,逐步的将原始模型压缩到目标结构。通过对LDNet不同裁剪次数形成相同的最终裁剪结果实验出最佳裁剪策略。不同裁剪策略结果如表2所示,不同裁剪策略性能结果如表3所示。

表2 不同裁剪策略相关参数对比

表3 不同裁剪策略的性能比较 %
由表3可知,裁剪策略1采用少量多次的方式最佳,故后续将统一采用四次裁剪次数。为了比较本文所提出的裁剪方法与特征图l1范数、卷积核l1范数的性能差异,基于铁路数据集训练,将这三种准则在LDNet上分别进行四次裁剪实验,实验的性能对比和裁剪压缩率如表4所示。
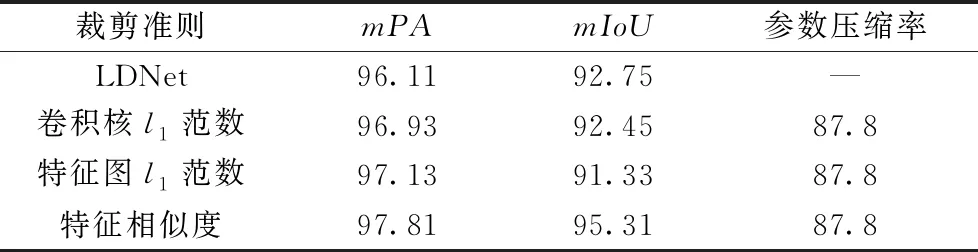
表4 不同裁剪准则的性能比较 %
由表4可以看出,在对LDNet进行四次裁剪到相同参数压缩率后,基于特征相似度的裁剪准则的结果在mPA和mIoU指标上均优于其余两种裁剪准则,且最终识别精度优于原始模型。故本文提出的裁剪准则得到的模型识别精度更好,能更有效的识别出模型中无用和冗余的卷积核。
为了探索更优的模型压缩后的结构,对LDNet按表2策略1所示的裁剪压缩比基础上增加裁剪次数,直至裁剪后模型精度不能恢复为止。裁剪次数增加过程中模型的性能变化见图10。

图10 网络识别精度变化曲线
由图10可知,使用特征相似度的裁剪准则在小裁剪比例的基础上,对LDNet裁剪8次后精度损失较大,且进行微调也无法恢复原有精度,故以第7次裁剪后得到的模型结构作为最终裁剪结果,在保证精度的情况下尽可能减少网络参数量。
3.3 LDNet有效性验证
使用图10中7次裁剪后得到的LDNet进行计算,并与FCN、MCG算法以及裁剪前原始结构作对比。其中可视化区域分别为主护栏区域、侧护栏区域、轨道区域。不同算法的性能比较如表5所示。
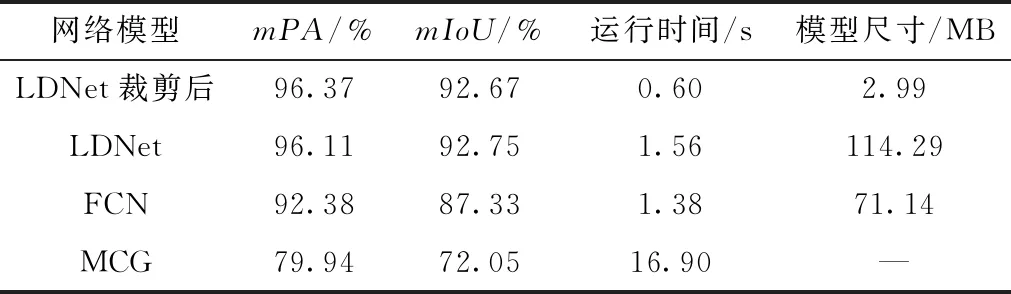
表5 使用所提算法裁剪前后模型与不同算法性能参数比较
由表5可知,LDNet裁剪后模型尺寸压缩至仅2.99 MB,压缩了原始LDNet尺寸的97.4%。裁剪后的LDNet在mPA上达到最高为96.37%,相比原始LDNet增加0.26%,而mIoU仅下降0.08%,几乎保持不变。LDNet裁剪后计算耗时降低61.5%,相比其他算法运行时间大幅度缩短。综上可得将LDNet用提出裁剪准则进行7次裁剪最终可以实现2.99 MB的参数占用空间,且精度几乎无损失。最终识别精度上优于其他的算法,不同算法对铁路周界的识别结果见图11。

图11 不同算法识别结果
由表5和图11可知,FCN识别结果中,护栏区域存在漏识别,也有部分非周界区域识别成铁轨区域;MCG算法计算过程中需要对大量的区域进行迭代聚合,所以计算速度和效率远低于算法,并且MCG识别结果中铁轨和护栏聚合区域均存在缺少的情况。本文提出的识别模型LDNet对周界各个区域的识别精度更高,误识别也更少,裁剪后单张图片计算耗时最短,能够满足铁路视频监控系统实时性要求和低内存占用要求,不再依赖GPU的加速,容易搭载在铁路沿线不同配置的处理平台上,实现自动快速的识别出铁路周界中的护栏和铁轨区域。
4 结论
提出一种基于多尺度信息融合的铁路周界识别深度神经网络模型LDNet,实现各种线路场景的周界自动快速精确识别。该算法抛弃了目标检测网络依赖的锚框,直接识别周界线特征点,使用目标检测网络实现了分割式的结果;对于实际运用中的配置问题,设计了基于特征相似度的裁剪准则,选用网络裁剪的方式压缩网络,进一步的对模型优化。通过对比实验,裁剪后的LDNet单张图像处理耗时0.60 s,识别mPA达到96.37%,模型尺寸仅2.99 MB,均优于FCN和MCG算法,能满足在精度要求的前提下达到实时性识别铁路周界的要求。
