基于混合深度学习的多模态场景指令分类方法
2022-01-28吴桂玲
吴 桂 玲
(信阳农林学院信息工程学院 河南 信阳 464000)
0 引 言
人工智能技术的发展使得智能机器人的研究得以实现,人们对于家庭服务机器人(Domestic Service Robots,DSR)的需求也逐渐增加。解决DSR与人互动的大多数方法都是基于句法和语义语法的[1],由于创建语法的困难,区分性分类器(例如条件随机场和支持向量机)以及生成性分类器(例如有限状态行列式和隐马尔可夫模型)已开始用于此问题[2]。随着可用数据和计算能力的增加,深度学习算法开始在自然语言处理(NLP)领域中达到新的水平。Li等[3]将递归神经网络(Recurrent Neural Network,RNN)树应用于动作识别;Fok等[4]提出了长短期记忆网络(Long Short-Term Memory,LSTM)和RNN进行运动动作和性能分析的人工智能方法。
由于机器人执行复杂任务的能力与其环境模型的丰富性有着内在的联系,传感器技术、机器感知和自然语言理解的进步提供了丰富的数据,可以输入到这些模型中[5]。DSR推断用户的意图不仅依赖于语言输入,还依赖于其他本体感觉和语境知识[6]。为了使提供各种支持功能的DSR标准化,研究者正在做出更大的努力,机器人领域开始更加关注语言和现实世界信息之间的映射,Chao等[7]提出了通过面部信息、上下文文本和对象识别增强TED-LIUM语料库,为机器人多模态自然语言理解方法打下了基础。然而,大多数用于DSR的口语理解(Spoken Language Understanding,SLU)方法仍然是基于规则的[8]。Kawahara[9]提出了类人对话机器人ERICA的语音对话系统,利用视觉和上下文信息启动语音识别的模型。Gallé等[10]提出的人机对话中多模态对话填充语的上下文感知选择方法采用贝叶斯模型对填充时间进行采样,收集对话期间的上下文信息。
利用视觉和上下文信息等多模态内容能够帮助DSR更好地理解和执行指令,最近的研究已经使用基于多模态相似性的集成来处理多模态语言理解,王红等[11]提出了LSTM进行语义关系抽取。Hatori等[12]提出了一种机器人系统,该系统包括人类自然语言指令以拾取和放置日常物品。Liyanage等[13]提出一种基于规则和机器学习的语义分析方法。Mi等[14]提出了基于CNN(Convolutional Neural Networks)的对象提供能力识别方法,用于多模态人机交互。
本文在现有机器自然语言理解方法的基础上,结合深度学习和多模态信息,提出一种基于混合深度学习的多模态自然语言理解方法,该方法结合周边场景和指令,通过两种深度学习预测周边所有目标-源对,得到每个目标-目的地对的区域范围可能性,最后通过GAN(Generative Adversarial Network)对数据进行增强和分类,提高指令中目标对象预测的准确率。实验结果表明,本文方法能够提高家庭服务机器人对指令理解的准确性。
1 基础理论
1.1 Bi-LSTM


图1 LSTM模型结构
1.2 生成式对抗网络和卷积神经网络
生成式对抗网络(GAN)是一种通过对抗过程估计生成模型的网络框架,具有强大的图片生成能力,初始在图像方面得到广泛应用,目前越来越多的研究者将其应用到自然语言理解分类方面。
GAN的基本框架由两个网络构成:生成网络G和判别网络D,生成网络G利用真实数据样本x训练生成新的数据样本G(z),判别网络D是一个二分类器,判断样本是来自于原始数据x还是由生成网络产生G(z)。GAN的目标函数表示为:
Ez,P(z)[log(1-D(G(z)))]
(1)
式中:z是潜在表征;x是真实样本;P表示概率分布;E表示期望。
卷积神经网络(CNN)作为深度学习算法之一,包含卷积计算且具有深度结构的前馈神经网络。CNN由卷积层、池化层和全连接层构成,卷积层用来提取对象特征,池化层连接在卷积层后面,其对象是特征的局部区域,使特征具有一定的空间不变性。
本文选用在ImageNet中取得成功的VGG19网络结构为基础网络结构,VGG19网络结构主要的贡献是采用了一个非常小的3×3的卷积核。
2 混合深度学习的多模态自然语言理解方法
本文提出一种混合深度学习的多模态自然语言理解方法,帮助DSR更好地理解和执行指令。该方法可以根据给定的指令语句和场景预测所有目标和源对,然后将预测数据进行GAN训练,提高分类准确性。混合深度学习多模态自然语言理解指令获取框架如图2所示。

图2 混合深度学习多模态自然语言理解指令获取框架
本文方法的输入:指令句子和场景作为一个图像;输出:目标-源对的可能区域,其中目标指的是用户希望机器人获取的日常物品(如瓶子或水果),源指的是目标的来源(如桌子或架子)。图3给出了本文方法的具体流程,图4给出了GAN扩展框架。

图3 本文方法的模型结构

图4 GAN扩展框架
如图3所示,对于每个候选目标i={1,2,…,N}和候选源i′={1,2,…,M},假设它们各自的裁剪图像和位置是可用的。因此,给定目标候选者,输入的集合为x(i)={xins(i),xv(i),xrel(i)},其中:xins(i)表示语言特征;xv(i)表示视觉特征;xrel(i)表示关系特征。在下文中,出于可读性考虑,省略索引i,将x(i)写为x。
输入xrel表示目标候选者与环境的关系特征(例如其他对象、场景中的位置、相对于源的位置)。根据数据集,xrel可能会有所不同。
视觉输入xv对应于目标对象的裁剪图像,CNN用于处理xv。并行地将xins进行词嵌入,然后由Bi-LSTM网络进行编码。在对视觉、关系和语言输入进行编码后需要一个通用的潜在表示形式来比较从CNN和Bi-LSTM中提取的特征,为此,使用了两个多层感知器(MLP)。之后,基于语言和视觉MLP的输出,使用第三个MLP预测目标对象的来源。
在自然语言处理中词嵌入是一种有效的特征学习,常用的词嵌入方法有Word2vec等。得到字嵌入后,字嵌入特征作为双向LSTM的输入。在本文中,使用子词嵌入模型BERT[15]模型来初始化嵌入向量,而不是基于词的嵌入模型。BERT模型是一种基于双向变换器的语言编码模型,具有更大的灵活性和鲁棒性。BERT接受了35亿单词的预训练,因此对稀有单词的数据稀疏性很强。另外,BERT没有使用基于单词的标记化,而是使用子单词标记化,子单词标记化对单词拼写错误更为稳健。经过BERT模型处理以后的词特征是多层Bi-LSTM的输入。
本文方法使用多层Bi-LSTM来编码语言特征,可以更好地捕获句子的上下文信息。同时,使用19层网络VGG19对场景视觉特征进行编码。这些网络连接到两个人工神经网络中的多层感知器(Multi-Layer Perceptron,MLP)网络,即MLP-I和MLP-V,两者的输出用于预测目标的可能性。两个MLP的输出OI表示视觉特征,OV表示语言特征。源的预测由OI和OV通过一个MLP-U预测得到。
GAN扩展处理之前的输出可以表示为:
Y={ytarg,ysrc}
(2)
式中:ytarg表示目标预测;ysrc表示源预测。此时的损失函数J定义如下:
J=λ1Jtarg+λ2Jsrc
(3)
式中:λ1和λ2表示加权参数;Jtarg和Jsrc分别是目标和源的交叉熵损失函数。Jtarg和Jsrc可表示为:
(4)
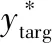
为了提高DSR对指令任务中目标对象预测的准确率,使用GAN对数据进行扩展和分类,GAN框架包含两个对抗网络,一个生成器G和一个鉴别器D。生成器G通过模仿给定的数据分布来创建人工数据,鉴别器D预测输入数据是真实的还是伪造的。凭借其对抗目标,训练了G生成更现实的数据,同时增强了D的辨别能力。
如图4所示,GAN的输入有三个:语言特征OI、非语言特征OV和一个服从正态分布随机抽样的多维输入z。则GAN的输入集合可以表示为:
xGAN={z,xreal=(OI,OV),xfake=G(z,OV)}
(5)
为了对真实数据xreal和伪数据xfake进行分类,从源标志S∈{fake,real},用x=xreal或x=xfake交替输入鉴别器D,D的输出可表示为D(x)=PD(S=real|x),G和D的损失函数分别为JG和JD,定义如下:
(6)
在训练过程中,D和G的训练是交替进行的。首先训练D的参数,然后训练G的参数。在训练G的参数时,D的参数是固定的。由G生成的人工数据可以用来增强和改进D中的分类器网络,因此,D不仅可以区分xreal和xfake,而且网络还可以通过预测候选目标的可能性来执行分类任务。因此,除了PD(S),D还有第二个输出PD(ytarg),这是目标的可能性。通过GAN进行扩展以后,本文算法的损失函数修改为:
JD=JG+λJ
(7)
式中:λ是加权系数;J是式(3)中定义的交叉熵损失函数。
3 实验与结果分析
在实验部分,对本文方法中参数进行设置,使用24层预训练的BERT模型进行子单词标记,嵌入向量的大小为1 024。使用VGG19预训练模型作为CNN,在MLP-1和MLP-V中,为每层应用了批处理标准化和ReLU激活函数,在MLP-S中,除了使用ReLU激活功能外,最后一层还使用了Softmax函数。GAN中发生器G和鉴别器D均由具有四层ReLU激活函数的层组成,并将批量归一化应用于这些层。G的输出层是tanh激活函数,而Softmax函数应用于D的输出层,方法权重λ1=1、λ2=0.7。具体参数由多次实验调整得出,参数设置如表1所示。

表1 本文方法参数设置
为了评估本文方法在真实情况下的性能,将本文方法应用于PFN-PIC数据集[12],其中训练集中有89 861个句子和25 517个边界框,而验证集中有898个句子和352个边界框。图5给出了在不同正负样本率γ条件下,本文方法使用BERT模型和未使用BERT模型的指令目标分类准确率。

图5 本文方法的目标分类准确率
可以看出使用了基于双向变换器的语言编码BERT模型,使得对指令的解析更加准确,这是因为BERT接受了35亿单词的预训练,因此对稀有单词的数据稀疏性很强。另外,该模型是基于子单词,对错误拼写具有更好的鲁棒性。
为了验证本文方法的有效性,将本文方法与现有其他方法进行比较,其他方法包括:CNN+LSTM深度学习方法[12]、基于规则和机器学习的语义分析方法[13],以及基于CNN的多模态融合的人机交互指令分析方法[14]。表2给出了在不同正负样本率γ条件下,所有方法的准确率比较。
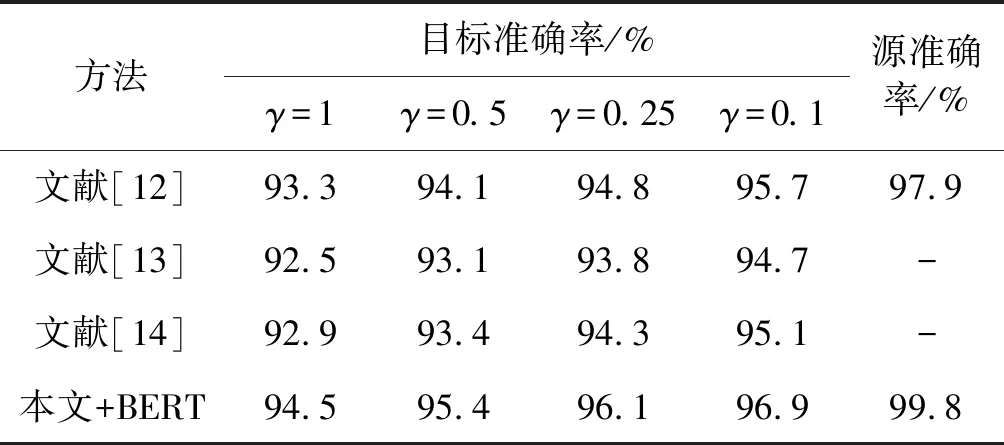
表2 不同方法下指令理解的目标和源准确率
可以看出本文方法对于自然语言获取任务中目标对象预测的准确率在不同γ下都具有最高的准确率,文献[12]方法次之。这是因为文献[13]使用了机器学习方法,文献[14]使用了CNN框架,从单一的方法对指令进行解析,文献[12]使用了CNN+LSTM的方法,从指令和场景进行分析,但是本文方法采用了CNN+Bi-LSTM+GAN混合深度学习方法,将语言特征和非语言特征分别进行编码和预测,并进行GAN数据扩展,进一步提高抓取任务中目标对象预测的准确率。另外,本文可以给出99.8%的源预测准确率;除了本文方法和文献[12]中方法能够给出源预测,其他两种方法只能够对目标进行预测。
为了验证本文方法的实际效果,采集实际图片对方法进行验证,对图6中待拿取物品进行预测,框中物品为目标物品。

(a)电脑桌上酸奶 (b)电脑桌上红色笔帽的笔
本文方法能够对图6中项目提供正确的预测,这些预测图片是实际采集的图片,说明本文方法对于真实的拿取场景中物品预测的准确性和有效性。
为了对本文模型时间性能进行实验,对PFN-PIC数据集部分实验数据进行指令理解和分类,得到的时间性能如表3所示。

表3 时间性能比较
可以看出本文模型用时最长,这是因为本文采用了CNN+Bi-LSTM+GAN混合深度学习模型,训练和学习时间都比其他三种方法长,但是本文混合深度学习模型对于预测的准确性最高,未来一部分工作集中在缩短本文模型时长方面。
4 结 语
为提高DSR自然语言指令分类精度,提出一种混合深度学习的多模态自然语言指令分类方法,该方法从指令、场景和关系特征多模态入手,使用Bi-LSTM对语言指令进行编码,使用CNN对视觉特征和关系特征进行编码,经过MLP处理,得到目标-源对的预测,为了提高DSR对NLP指令分类的准确性,使用GAN对数据进行扩展和分类。实验结果表明,本文方法提高了获取任务中目标对象预测的准确率且性能优于现有其他方法,随着正负样本率增加,本文方法对指令分类的准确率增加,验证了本文方法的可行性与有效性。未来将使用注意力机制来扩展本文方法。
