基于并行局部特征金字塔的弱势道路使用者检测
2022-01-28高广鹏
高广鹏 赵 峰
(桂林电子科技大学计算机与信息安全学院 广西 桂林 541004)
0 引 言
目标检测作为自动驾驶领域的关键技术之一,首要任务是能够正确检测出道路使用者。2018全球道路安全现状报告统计[1]中指出,在全球范围内,每年的VRU死亡人数占道路交通死亡总人数的26%。在现实道路中,复杂的背景环境,VRU的相互遮挡和尺度变化等均会对VRU的检测造成影响,其中尺度变化对检测性能影响最大,因此需要检测器能够正确检测不同尺度的VRU。根据特征提取方式将VRU检测方法分为传统方法和深度学习方法。
Dalal等[2]使用方向梯度直方图(Histogram of Oriented Gradients,HOG)提取行人边缘梯度和强度特征,然后使用支持向量机(Support Vector Machine,SVM)判定候选区内是否存在行人。然而HOG只保留了行人的梯度特征,丢失了大量的表观信息。Dollar等[3]结合颜色通道、梯度幅值和梯度直方图等10种特征描述行人,然后利用积分图方法减少特征的计算时间,最终取得了很高的精度。为了解决行人遮挡问题,Felzenswalb等[4]提出多尺度可变形组件(Deformable Parts Model,DPM)对行人的不同部位进行独立建模。Yan等[5]通过剪枝、构建查找表策略解决了DPM计算复杂、速度慢的缺点。骑车人检测使用了类似的算法。Li等[6]使用HOG提取骑车人的局部特征,图像金字塔采样法提取不同尺度空间的全局特征检测骑车人。Chen等[7]利用外观和边缘特征对夜间环境中的自行车和摩托车进行检测。Yang等[8]提出两级多模态检测方案检测不同姿态的骑车人。Tian等[9]通过级联多视角检测器检测不同视角下的骑车人。
传统VRU检测算法需要研究者们根据VRU特征手动设计相对应的特征算子,不利于检测复杂场景中的VRU检测,而神经网络具有学习抽象特征的能力使其在检测领域得到了广泛的应用。VRU检测一般通过改造主流的检测算法来实现。基于区域的检测算法[11-16]首先在原始图像上生成感兴趣区域(Region Of Interest,ROI),然后利用神经网络对ROI进行特征提取和分类。文献[13]使用区域建议网络(Region Proposal Network,RPN)将区域检测算法的多个阶段统一到一个卷积网络中,实现了端到端的检测,加快了检测速度。He等[14]使用自上而下的特征融合网络(Feature Pyramid Network,FPN)将高层的语义信息融合到每一个特征层中提升了小目标的准确度。基于区域的检测算法虽然精度很高,但是很难达到实时检测。基于回归的检测算法[17-21]丢弃了RPN过程,大幅提升了算法的检测速度。YOLOV1[17]在原图的每一个单元格上回归输出最后的预测位置和目标所属类别。YOLOV2[18]通过优化网络的训练过程,设置默认框的方法解决了YOLOV1精度低的问题。YOLOV3[19]通过修改基础网络和使用特征融合提升YOLOV2的小目标检测精度。SSD[20]结合了区域检测算法和YOLO算法的优点,使用多层特征图检测不同尺度物体。文献[25]使用两步回归方式解决了基于回归的检测算法中正负样本数不平衡的问题。
当前针对行人和骑车人的检测是使用两个单独的检测器分别检测,然而行人和骑车人作为重要的道路交通参与者,具有不同的行驶速度,受到的事故伤害程度也不尽相同。因此,需要一个检测器将两者统一到一个检测框架中。然而,对于当前研究缺少相应的数据集,通过建立VRU数据集和使用改进策略提升模型对不同尺度VRU的检测能力。本文主要进行以下工作:从现有的多个数据集中抽取行人和骑车人样本建立VRU数据集;研究分析FPN特征融合方式会为底层目标检测引入高层的噪声,并提出并行的局部特征金字塔结构。该结构在增强底层特征的同时,减少高层噪声对底层特征的干扰。研究发现SSD的默认框不能涵盖目标的多个尺度,造成检测率低。本文通过利用每个特征层的下采样步长重新计算默认框的尺度,使默认框能够匹配更多尺度的VRU,再使用两阶段回归方法平衡正负样本数。与基础网络相比,该网络的mAP提升了7%,检测速度满足实时性要求。
1 相关工作
SSD是一个卷积神经网络检测模型,特征图从下而上依次减小,结构如图1所示。

图1 SSD网络结构
模型前端为特征提取网络,由基础卷积层和辅助卷积层组成。后端为检测网络,由特征提取网络中的C4_3、C7、C8_2、C9_2、C10_2、C11_2特征层组成。模型对检测网络中不同特征层做不同尺度的特征映射来预测不同尺度的目标。用于检测的每个特征层都与一组默认框绑定,生成一系列固定尺度的预测集合,集合中的每一个元素包括预测框的4个偏移量和分类类别的得分。若检测网络中某一个特征层的大小为w×h,那么在该层会有k×w×h×(c+4)个输出,k表示特征图中每个单元格绑定的默认框个数,c表示分类类别。SSD利用式(1)为每层特征图生成相对应尺度的默认框。
(1)
式中:最小尺度smin预设为0.2;最大尺度smax预设为0.9;m为6;sk表示第k层的特征图的尺度。
2 网络模型
并行局部特征金字塔网络结构如图2所示。首先通过基础网络层提取图像的VRU特征,对提取的特征在第一阶段检测层中进行回归和分类,根据回归的结果粗调默认框。然后通过并行局部特征金字塔结构加强已经提取的VRU特征作为第二阶段检测层的输入,最后使用第二阶段检测层的结果精调已经粗调过的默认框作为最终的检测结果。

图2 并行局部特征金字塔网络结构
2.1 网络结构
1)基础网络层。与SSD大致相同,将VGG16的池化层pool5、全接连层fc6、fc7分别转换为3×3卷积层、3×3卷积层C6和1×1卷积层C7,并删除最后的dropout层和分类层。不同的地方在于,SSD使用6层特征层进行最后的预测,但由于SSD网络最后一层的特征图太小,包含的VRU特征信息较少,因此本网络只用SSD的前五个特征层。
2)特征融合层。文献[14,26]通过FPN结构将高层的语义信息结合到每一个特征尺度中来加强底层特征,提升了模型的检测能力。这些模型使用的FPN结构都是从最顶层开始融合逐层特征,然而并不是所有的顶层信息都对底层的小尺度VRU检测有帮助。首先,小尺度VRU和大尺度VRU在视觉上具有不同的纹理结构,而由于遮挡、光线等外在环境的影响,所展现出的视觉效果更是不同,因此直接利用所有高层的语义信息去加强不同尺度的VRU特征是非常粗鲁的。其次,对于小尺度VRU的检测需要更多的纹理信息,高层特征层中已经几乎不包含纹理信息,使用全部高层信息加强底层特征时会为小尺度VRU引入额外的高层噪声,影响小尺度VRU检测。因此本文使用并行局部特征金字塔结构,即多个并列的PFFM模块如图3所示。
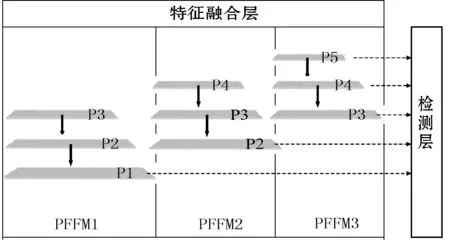
图3 特征融合
对于当前输出层,只融合相邻上两层间的特征,这样的特征融合方式不仅避免为底层特征融合过多的高层抽象信息又能使用高层信息加强底层特征。对于PFFM3中的p5和p4层,由于已经是最顶层的两层特征,所以对于p5层没有融合其他层特征,p4层只融合p5层的特征信息。
STM模块是基础网络层和特征融合层间信息的转换模块。图4由基本的1×1、3×3卷积、ReLU激活函数构成。
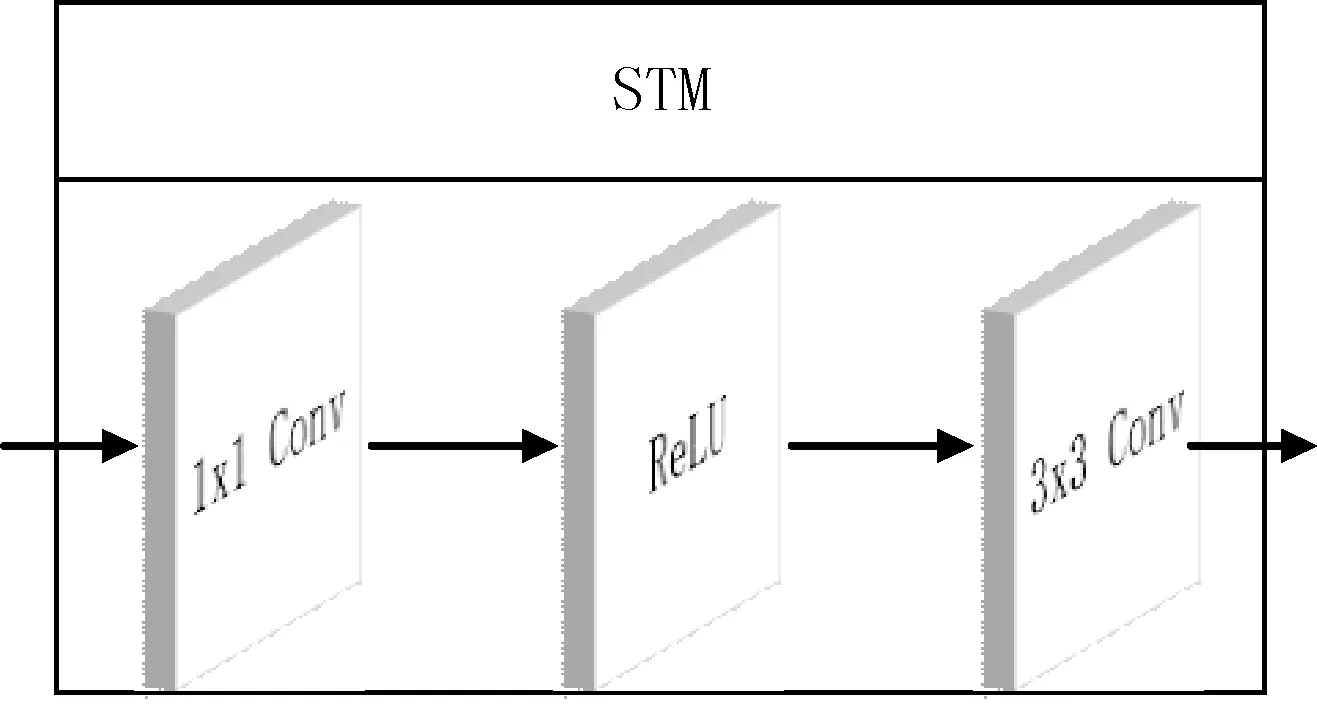
图4 STM模块
为使相邻层的特征能够融合,PFFM模块在相邻的特征层间使用1×1卷积帮助交换通道间信息和使用上采样层将高层小分辨率的特征图扩展到与底层特征图的大小相同,方便相邻特征层之间的信息相加融合,结构如图5所示。
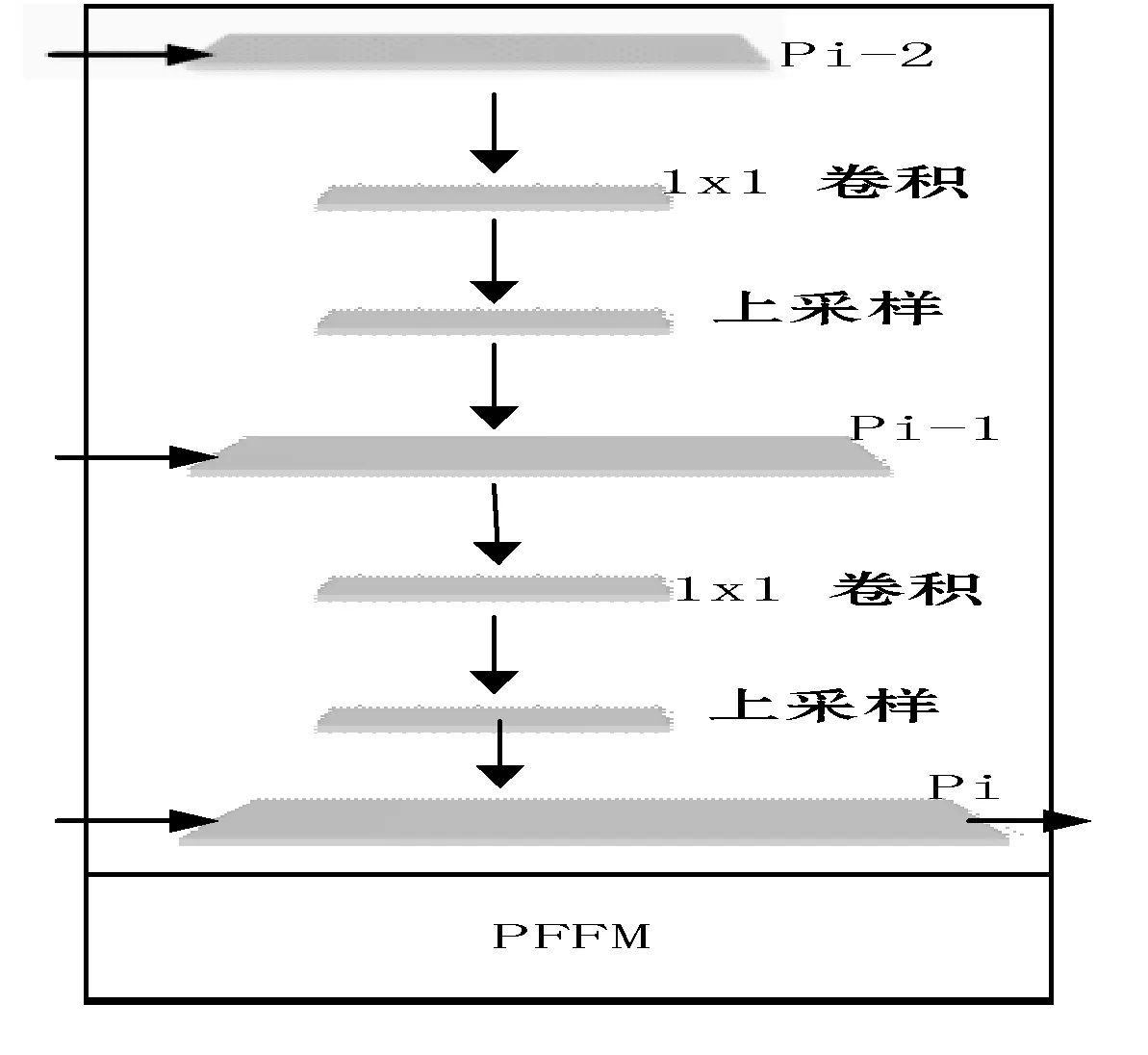
图5 PFFM模块
2.2 默认框的设计策略
模型通过在不同特征层上设置不同尺度的默认框来有效地处理不同尺度的目标。根据文献[27]每层特征图对应着不同的理论感受野,然而在理论感受野的范围内只有一部分值影响最后结果,即有效感受野。因此默认框的设置应与有效感受野匹配。文献[28]根据有效感受野和4倍等间隔原则为人脸检测设计默认框,保证不同尺度的默认框在图像上具有相同的平铺密度和足够大的有效感受野包含周围环境信息,比如头发、肩膀等辅助人脸检测。
1)默认框的尺度。SSD默认框的最小尺度为60,不能匹配小尺度的VRU。受文献[28]的启发,现实环境中,VRU周围有大量的背景干扰物,对VRU的检测起不了辅助作用,因此为了减少背景对VRU检测的影响,在下采样步长和默认框的尺度间建立线性映射关系寻找合适VRU的有效感受野:
sscale=k×sstep
(2)
式中:sstep表示步长;sscale为默认框的尺度;k为常数。
2)默认框的宽高比。在同一水平面中,行人和骑车人展现出不同的姿态。根据行人和骑车人在不同角度下巨大的姿态差异分别设定不同的宽高比如图6所示。对于行人,在0度角时,视角与行人前进方向垂直,宽高比接近1∶2。在90度角时,视角与行人前进方向平行,行人偏细长,宽高比近似为1∶3。同理,对骑车人,根据0、45、90度角分别设置为1∶1、1∶2、1∶3的宽高比。因此数据集的默认框的宽高比分别为1∶1、1∶2、1∶3,如表1所示。

图6 行人和骑车人不同角度对应的不同姿态

表1 默认框的设置
2.3 两阶段回归策略
基于回归的检测算法相比基于区域的检测算法没有RPN操作,会产生大量的负默认框。本文借鉴文献[25]的方法,根据第一阶段检测层的回归结果粗调初始的默认框,然后根据第二阶段检测层的回归结果精调在第一阶段粗调过的正默认框作为最终的预测边框。为了平衡正负样本个数,在第一阶段检测层中对VRU进行二分类,通过设置阈值,将分类得分小于阈值的默认框标记为负默认框,反之,标记为正默认框。负的默认框将不参与第二阶段的边框回归。最后在第二阶段检测层中对检测目标进行实际的分类预测。模型的两阶段损失函数为:


(3)
式中:Lb表示对数损失函数;Lr为L1平滑损失函数;Lm为Softmax损失函数。具体的函数表达为式(4)-式(6)。
(4)

(5)
(6)

2.4 优化策略和参数设置
(1)将SSD的输入图像尺寸从300 提升到320,避免网络在浅层特征图上的近似计算。
(2)数据预处理时使用本数据集的RGB均值而不是ImageNet数据集的RGB均值。
(3)在C4_3层使用归一化处理。
(4)对前两轮迭代使用gradual warmup预热减轻损失波动。
(5)对数据做水平翻转,随机裁剪,颜色扭曲增强处理。
(6)使用VGG16预训练权值初始化主干网络,Kaiming方式初始化其余卷积层。使用随机梯度下降,动量系数为0.9,权重衰减系数为0.000 5,批次为32,初始学习率为0.002,衰减系数为0.1,重叠率为0.5,迭代250轮,学习率衰减区间为[2,140,220,250]。
3 实 验
实验使用Ubuntu16.04.64位操作系统,显卡Tesla p100,Pytorch框架。
3.1 数据集介绍
研究发现,现存的行人数据集有很多,对于骑车人样本只在一些数据集中少量存在,不足以用于检测。为了能够对现实环境中行人和骑车人检测,通过从现有的数据集中抽取相关检测样本构建数据集。数据来自于BDD100k[23]、KITTI[22]、Tsinghua-Daimler Cyclist Benchmark(TDCB)[10]和Cityscapes[24]4个数据集。
选取KITTI训练集中全部的行人和骑车人样本,图片大小为1 242×375。BDD100K中包含行人的图片数量远大于骑车人,对仅包含行人的图片进行欠采样使与骑车人的图片数量保持均衡,图片为1 280×720。抽取TDCB和Cityscapes中全部的行人和骑车人样本,图片大小为2 048×1 024。TDCB和Cityscapes图片的尺寸与另两个数据集图片相比过大,对图片按宽度1 024裁剪和过滤掉不包含目标类别的图片。为了增加骑车人样本的数据量,从TDCB的训练集中筛选包含骑车人的图片,经裁剪过滤处理保留包含目标类别图片。最后每个数据集中抽取的图片数量如表2所示。
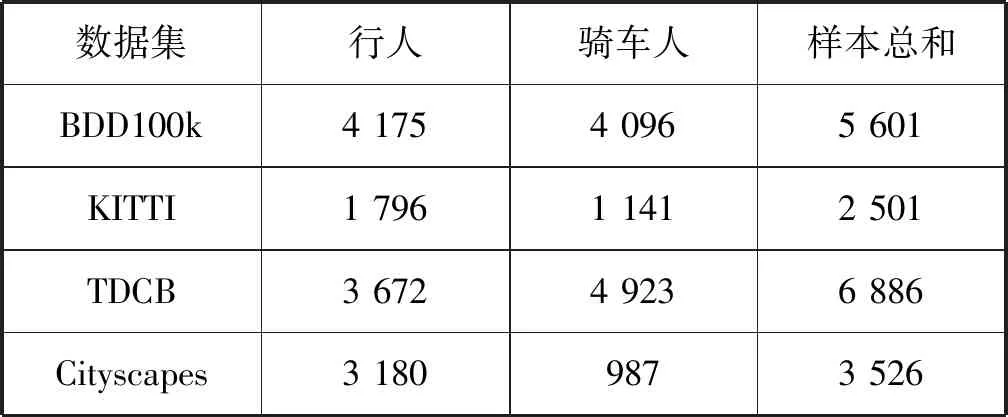
表2 每个数据集抽取图片的数量 单位:幅
对每一个数据集都按照6∶4的比例划分训练集与测试集。最后合并四个数据集的训练集和测试集,具体划分如表3所示。
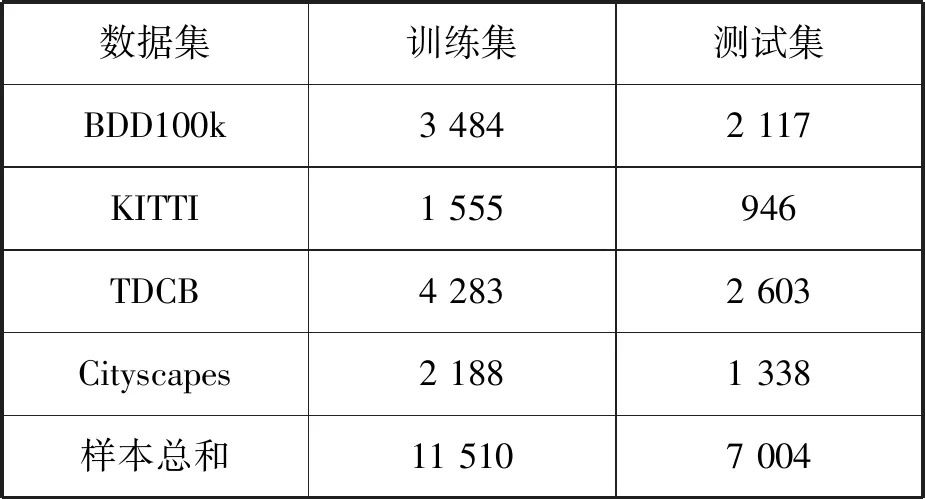
表3 数据集划分
使用mAP评估模型,值越大,检测性能越好。使用PR(Precision-Recall)曲线下的面积直观评估模型中每个类别的性能,面积越大性能越好。使用FPS (Frame per Second)度量模型的检测速度。
3.2 模块的实验对比
1)默认框的实验对比。在上述的数据集中通过5组实验对默认框的设计策略进行对比,5组实验输入图片都为300×300,使用6个检测层,实验结果如图7所示。第一组为基准网络SSD,其余4组实验只有默认框常数k取值不同,其余参数设置均相同,常数k分别取2、2.5、3、3.5。后四组实验与第一组比较mAP分别增长1%、2.5%、2.1%、0.2%,由于SSD的默认框最小尺度为60,不能很好地匹配小尺度的VRU,所以检测结果相比其余四组最低,证明新的默认框策略要优于SSD。后四组实验对比发现,当k取2.5时的结果相比k取2时上涨了1.5%,因为k取2时默认框比较集中检测小的VRU,而忽略了大尺度的VRU。k取3.5时相比k取2时mAP下降了2.3%,因为k取3.5时,默认框的最大尺度已经超过了输入图像的分辨率且默认框的尺度设置整体偏向于大的VRU,而忽略小尺度的VRU。当k取3时与k取2.5时结果相差不大,只有0.4%的变化。
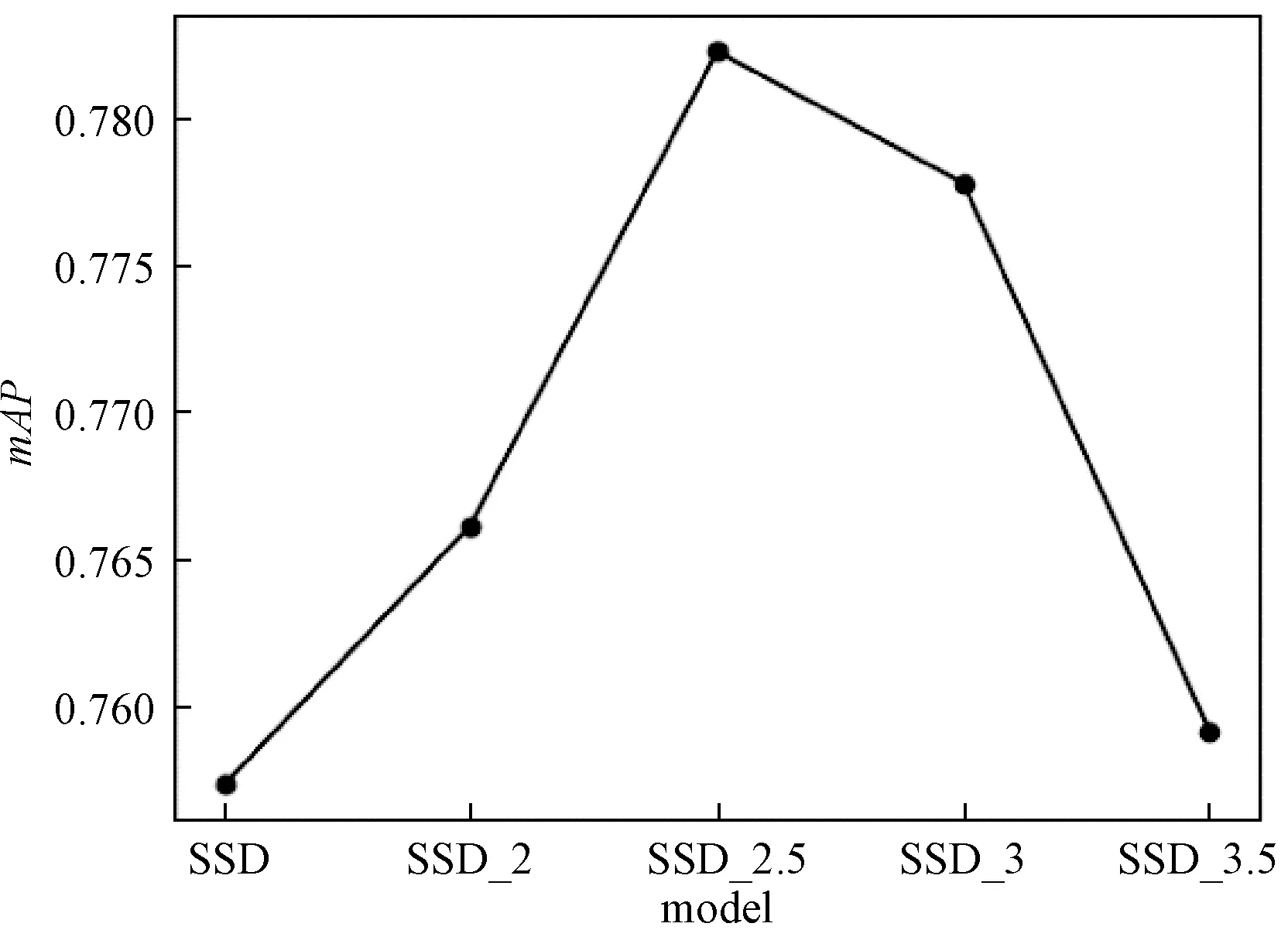
图7 不同默认框策略下mAP对比曲线
图8表示上述每组试验中每一个类别对应的PR曲线,k取2.5时,行人和骑车人类别PR曲线下的面积最大,结果最优。
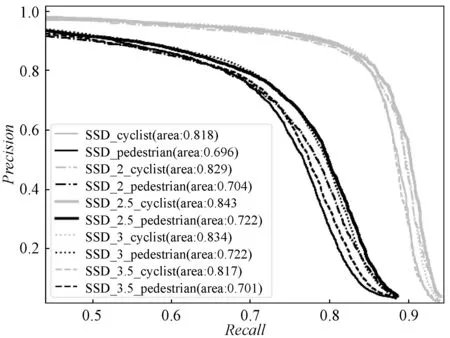
图8 不同默认框策略下各类别的PR曲线
2)特征融合的实验对比。表4中第三行和第四行两组实验输入图片为320×320,k取2.5,第三行使用5个检测层,第四行使用6个检测层,两组实验结果相差无几。因此在下面的4组实验中均使用5个检测层,两步回归策略,输入图片大小为320×320。通过实验对比验证本文特征融合的有效性。第一组实验使用FPN结构的特征融合方式,剩余三组使用本文特征融合方式。第二组实验PFFM_connect_2使用4个PFFM模块,每个PFFM模块对2层特征层融合。第三组实验PFFM_connect_3使用3个PFFM模块,每个PFFM模块对3层特征层融合。第四组实验PFFM_connect_4使用2个PFFM模块,每个PFFM模块对4层特征层融合。结果如图9所示,后3组实验相比第一组的mAP分别提升了0.3%、0.6%、0.4%,证明此融合方式的有效性。后3组实验结果对比发现,PFFM_connect_3实验结果最优为0.826。PFFM_connect_4的mAP开始下降低是因为底层特征层融入了太多高层无用信息,引入了噪声,而PFFM_connect_2的mAP低于PFFM_connect_3的原因是为当前的特征层融入了较少的高层语义信息。
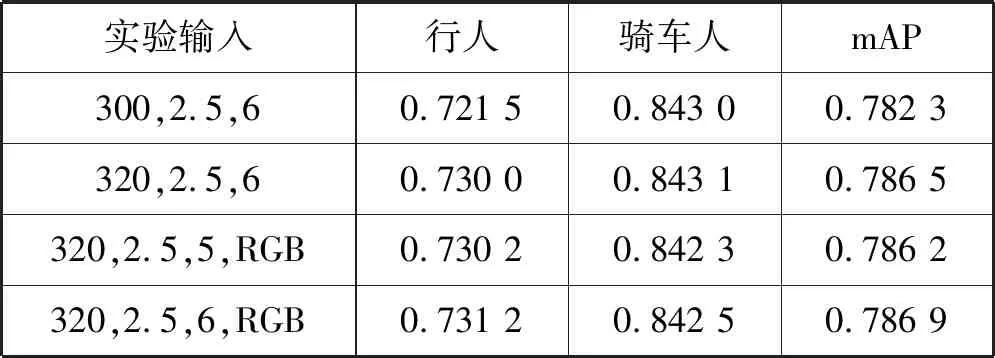
表4 输入尺寸和RGB实验mAP对比

图9 不同特征融合方式下mAP对比曲线
3)优化策略的实验。表4所示的四组实验中,第一组实验输入尺寸为300,参数k取2.5,使用6个检测层,使用ImageNet数据集的RGB值。第二组实验相比第一组实验只是将输入图像尺寸从300提升至320,用于抵消模型下采样时近似计算带来的回归误差,两组实验结果对比可知mAP提升了0.4%。第二组实验和第四组实验的配置只是使用的RGB值不相同外,其余配置均相同。第二组实验使用ImageNet数据集的均值,而第四组实验使用本论文中数据集的RGB均值,两组实验对比发现,模型对于RGB的使用不太敏感。
4)消融实验。消融实验的结果对比如表5所示。常数k取值为2.5时的默认框能够更好地匹配不同尺度的VRU,结果相比SSD的mAP上涨了2.5%。将输入图片的尺寸提升至320和使用本论文数据集的RGB均值时,与SSD的mAP相比增长了2.9%。最后使用新的特征融合方式PFFM时,mAP增长至0.826。

表5 消融实验的mAP变化
由图10可知,每一步的实验改进,行人和骑车人PR曲线下的面积都有较大的增长。

图10 消融实验中各类别PR曲线
3.3 其他算法对比
使用RFBNet[29]、SSD[20]、refineDet[25]、Faster RCNN[13]与本文算法对比。结果如表6所示,本文算法检测VRU的mAP最高为0.826,检测速度与SSD也接近。

表6 对比实验的mAP
在PR曲线中,对于每一个分类,本文的算法较其他方法相比,也有较大的优势。
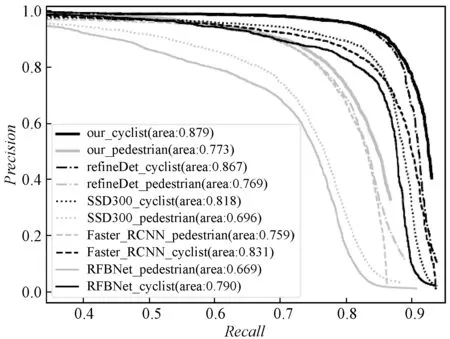
图11 不同算法中各类别对应的PR曲线
4 结 语
本文通过建立VRU检测数据集并提出并行的局部特征金字塔网络。以SSD网络为基础,通过增大SSD模型的输入图像分辨率来抵消下采样时的近似计算,重新设计默认框的策略使模型适合VRU的检测,使用并行的局部特征金字塔融合方式。在增强底层特征的时候,不引入高层的噪声,极大地提升了网络对VRU的检测能力。但是,此模型对遮挡和密集环境中的行人和骑车人的检测能力有待提高,下一步将遮挡问题作为研究的重点。
