基于迁移学习的社交评论命名实体识别
2022-01-28李业刚史树敏
张 晓 李业刚* 王 栋 史树敏
1(山东理工大学计算机科学与技术学院 山东 淄博 255000) 2(北京理工大学计算机学院 北京 100081)
0 引 言
命名实体识别[1](Named Entity Recognition,NER)是自然语言处理(Natural Language Processing,NLP)领域的核心基础性任务之一,其主要任务是从非结构化文本中提取特定类型的实体,例如:人名、地名、机构组织名和包括时间、日期、百分比在内的数字表达式。
目前,随着深度学习在NLP领域的广泛应用,越来越多的研究人员利用深度神经网络进行命名实体识别。深度学习方法相对于机器学习方法,具有更好的泛化能力,能够有效地避免对专家知识和复杂人工特征的依赖。Huang等[2]提出的BiLSTM-CRF模型能够有效地处理NLP中的序列标注任务,在CONLL2003数据集上F1值达到90.10%。Ma等[3]提出的BiLSTM-CNNS-CRF模型通过卷积神经网络(Convolutional Neural Networks,CNN)将字符转化为字符级别的特征表达,与预训练好的词向量相拼接,作为网络结构的输入,在CONLL2003数据集上取得了领先水平。Limsopatham等[4]利用长短时记忆网络(Long Short-Term Memory,LSTM)对噪声文本进行实体识别,提出了CambridgeLTL模型。该模型在国际计算语言学协会COLING2016大会组织的关于用户生成嘈杂文本命名实体测评(WNUT)中的各项任务取得了十支队伍中最好的名次。
采用深度学习方法[5]处理通用命名实体识别领域中表现出了较好的性能。在一些特定领域由于缺乏大规模的标注数据,其性能通常会下降,识别效果差强人意。如何提高特定领域内命名实体识别性能成为近期研究的重点问题之一[6]。随着网络技术的发展和一些社交软件在用户中的广泛使用,越来越多的人通过微博、Twitter等社交平台发表自己的观点看法。从海量的网络文本数据中提取突发热点新闻、进行话题追踪、避免网络攻击和了解社会舆论等方面都离不开命名实体识别,社交媒体中的命名实体识别对于国家部门、各大公司机构获取舆情信息具有重要的意义。因此,从Twitter、微博等社交媒体文本识别出命名实体成为近期研究的热点[7]。
本文提出了一种融合迁移学习算法的神经网络模型(TL-BiLSTM-CRF)迁移学习模型。首先利用字词结合的词向量作为BiLSTM的输入,得到序列的概率分布矩阵,通过CRF计算出全局最优的标记序列,构建基本模型;其次在基本模型中引入适应层,通过CCA算法弥合源域和目标域词向量特征空间的差异,对基本模型进行迁移。对比实验表明,TL-BiLSTM-CRF迁移学习模型在Twitter数据集上获得了较好的实验性能并超过了先前最好的模型。
1 相关工作
迁移学习[8]通过利用数据、任务和模型之间的相似性,运用已有的源域知识对目标域问题进行求解,是机器学习中的前沿研究领域。迁移学习在自然语言处理[9]、计算机视觉[10]和语音识别[11]等领域得到了广泛的研究。
根据Pan等[12]按学习方法的分类形式可以将迁移学习分为基于实例、基于特征、基于模型和基于关系四大类。Weiss等[13]按特征的属性进行分类可以将迁移学习分为同构迁移学习和异构迁移学习两大类。
基于模型的迁移方法是指从源域和目标域数据中找到模型之间共享的参数信息,构建参数共享模型。近年来,随着神经网络模型在许多领域都有成功的应用,特别是计算机视觉领域,在网络模型中进行迁移学习取得了大量的成果。目前,通过迁移学习来提高NLP神经网络模型的可移植性得到了研究人员的关注。
Mou等[14]针对NLP任务在卷积神经网络中如何迁移给出了INIT和MULT两种模式,并通过文本分类任务验证了迁移学习在神经网络中的可行性。其中,INIT模式是指使用来自源域的标记数据训练神经网络模型,随后用所学习的参数初始化目标模型,最后使用来自目标域的标记数据微调初始化的目标模型。如在计算机视觉领域ImageNet分类数据集中有预训练图像分类模型VGG[15]、ResNet[16]等,由于源领域训练数据规模大,可以将预训练好的网络模型迁移到目标任务上,使得模型更鲁棒、泛化能力更好。LSTM-CRF模型作为命名实体识别领域的基线模型,很多领域上的迁移模型也是基于LSTM-CRF模型进行改进,对于由源领域预训练好的模型,LSTM网络已经具备特征提取能力。如Giorgi等[17]利用LSTM网络,在含有大量标注的生物医学数据集上进行模型的训练,然后将模型参数迁移到小规模的数据集上,实验结果与基准模型相比F1值提高了9%,证明了在LSTM网络中进行领域间模型和参数共享的可行性。
MULT模式使用源域数据和目标数据同时训练两个模型,在学习过程中,两个模型之间共享部分参数。Yang等[18]针对跨域迁移、跨应用迁移和跨语言迁移设计了三种神经网络模型,该方法利用源域数据和目标域数据同时训练模型,在训练过程中共享某些参数,有效地提高了目标域数据集F1值。通过实验验证融合迁移学习算法的神经网络模型能显著提高序列标注问题的性能。
基于特征的迁移方式是指通过特征变换的方法来减少源域和目标域之间的差距,将源域和目标域的特征空间变换到统一的特征空间中。文献[18]直接使用通用词向量分别作用在源域和目标域中,假设了源域和目标域词向量具有相同的特征空间,将其简单地作为同构迁移学习会影响提升的效果。本文将基于特征、模型的迁移方法与神经网络模型进行了有机的结合,提出了TL-BiLSTM-CRF迁移学习模型进行社交评论命名实体识别。该模型既能够通过迁移学习算法缓解深度学习对少量数据学习效果不佳的问题,又能够通过神经网络自动学习特征,减少对外部字典和人工特征的依赖。
2 TL-BiLSTM-CRF迁移学习模型
图1给出了本文中的框架模型,模型分为四个部分:字词结合的表示层、用于编码单词序列的BiLSTM层、用于解码的CRF层和模型迁移过程中用到的词适应层。

图1 TL-BiLSTM-CRF迁移学习模型
2.1 字词结合的表示层
文本中的语义特征在命名实体识别任务中扮演着重要角色,这些语义特征为模型提供了上下文信息,从而使模型更好地推断识别出实体类型。本文利用开源工具Glove[19]分别训练目标域和源域生成具有语义信息的低维度稠密词向量。
对于文本中的每个单词w=[C1,C2,…,Cn],首先通过查询字符向量表获得每个字符的字符向量,由字符向量组成单词的字符向量矩阵,利用BiLSTM获得每个单词的字符级别特征wchars∈Rd1,例如,每个单词的大小写、拼写规律等。然后与词向量wglove∈Rd2进行拼接,最终得到字词结合的向量表达式:w=[wglove,wchars]∈Rn,其中n=d1+d2。
2.2 BiLSTM层
LSTM通过门控机制将短期记忆和长期记忆相结合,在一定程度上解决了循环神经网络(Recurrent Neural Network,RNN)模型梯度消失和梯度爆炸的问题[20],能够有效地提取上下文信息。LSTM单元结构图如图2所示,其内部结构表达式为:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot⊗tanh(Ct)
(6)
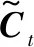

图2 LSTM网络单元示意图
相较于LSTM,BiLSTM能够更加有效地提取上下文信息,可以将每个序列向前和向后表示为两个独立的隐藏状态,分别捕获过去和将来的信息,其序列状态可表示为:
(7)
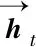
2.3 CRF层
CRF是一种用来标注和划分序列结构的概率化模型。对于命名实体这类序列标注问题,CRF层能够通过分析相邻标签之间的关系,加强标签语法的合理性和约束性。本文将CRF层接入BiLSTM层之后,进行句子级的序列标注,计算出一个全局最优的标记序列。
对于给定序列x={x1,x2,…,xn}和对应的预测标签序列y={y1,y2,…,yn},其得分计算式表示为:
(8)
式中:矩阵P为BiLSTM层的输出结果,其大小为n×m;n代表单词个数;m代表标签的种类;Pij表示句子中第i个单词的第j个标签概率。矩阵A是一个(m+2)×(m+2)的转移矩阵,Ai,j表示由标签i到标签j的转移得分。
整个序列的得分由LSTM输出的P和CRF的转移矩阵A两部分决定。随后可以通过指数函数和归一化处理将其转换为概率,其计算式表示为:
(9)
式中:y′代表正确的标记值。
在训练过程中采取极大似然估计原理对其进行优化,标记序列为如下形式:
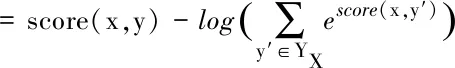
(10)
预测过程中通过Viterbi算法来求解最优路径,获取预测结果最优值:
(11)
2.4 词适应层
典型相关分析(CCA)算法是度量两组多维变量之间线性关系的多元统计方法,可以用来提取两组数据间的共有特性[21]。其目标就是为两组观测矩阵找到一对投影向量使得在投影空间内的新特征空间达到最大相关程度。
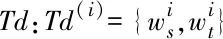
a′=avb′=bw
(12)
投影向量v、w可以通过最大化相关性函数ρ(a′,b′)获得:
(13)
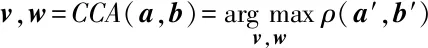
(14)
得到的v、w可以线性投影整个词汇表:
(15)
在词适应层中,通过CCA算法将源域和目标域的词向量弥合到同一空间向量中。
TL-BiLSTM-CRF迁移学习模型的训练过程如图3所示。首先采用基于模型的迁移学习算法,使用源域数据训练构建的基本模型,采用INIT模式参数初始化TL-BiLSTM-CRF迁移学习模型,调整并优化所有层的权重。其次通过基于特征的迁移学习算法,构建词适应层。目标域数据通过词适应层弥合与源域词向量空间差异。训练过程中对TL-BiLSTM-CRF进行微调。
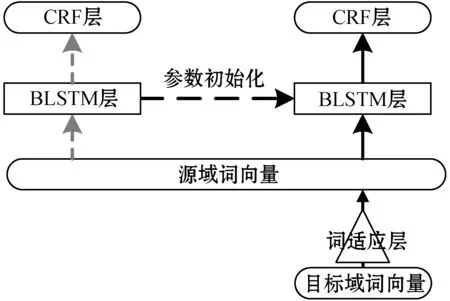
图3 TL-BiLSTM-CRF迁移学习模型训练过程
3 实 验
3.1 实验数据集与评价指标
实验中源域数据集选择的是在实体识别任务广泛使用且公开发表的CONLL 2003数据集[22]和OntoNotes-nw数据集[23]。目标域的社交媒体语料库Twitter数据集是从Archive Team中爬取下来的Twitter内容。数据集结构如表1所示。

表1 数据集
实验将数据集分为训练集、测试集和验证集三个部分,其中CONLL 2003数据集中训练集占语料总数的70%,测试集和验证集分别占数据的15%。OntoNotes-nw数据集中训练集、测试集和验证集分别占80%、5%和15%。
Twitter数据集中训练集占语料总数的80%,测试集和验证集分别占10%。语料详细信息情况见表2。

表2 Twitter数据集分布

续表2
Dai等[24]研究工作表明语料采用BIOES的标记效果要优于BIO2方式,能够更加清楚地表示和划分语料中实体的边界,因此,实验中采用了BIOES标记方式。
实验中采用精确率P、召回率R和F1值三种评价指标分别进行评价。其中,F1值是精确率和召回率的加权调和平均,能够综合评价模型整体的性能。计算式分别表示为:
(16)
3.2 实验环境配置
本次实验在Linux操作系统下,采用TensorFlow框架的1.2版本,语言采用Python3.5。训练过程中利用随机梯度下降法,在模型中加入Dropout层[25]来减少模型过拟合问题。同时,在验证集上使用early stop,当验证集上的错误率不再下降时提前停止迭代。词向量维度设置为100,LSTM隐层向量维度为300,Dropout设置为0.5,early stop设置为10,学习率设置为0.005。实验过程中采用NVIDIA的1060Ti GPU进行加速处理。
3.3 结果分析
为了验证TL-BiLSTM-CRF迁移学习模型的有效性和泛化性,对所提出模型进行了两个维度的实验,分析验证模型性能。与现有工作对比,评估模型的性能。
3.3.1模型性能分析
为验证基于模型迁移学习方法和词适应层对模型的影响。根据所提TL-BiLSTM-CRF迁移学习模型得到了以下几种模型变体:
1)BiLSTM-CRF(Non-transfer)。在本文模型上去掉了迁移学习相关的算法,用BiLSTM网络结构提取特征,接入CRF层计算全局最优的标记序列。作为基本模型。
2)BiLSTM-CRF+INIT。在BiLSTM-CRF的基础上,加入基于模型的迁移学习方法,在模型中通过INIT模式初始化目标模型。此实验将OntoNotes-nw数据集在BiLSTM-CRF网络结构上预训练模型,在目标任务Twitter数据集上复用模型LSTM网络组件,对LSTM参数进行微调,最后进入特定领域的CRF层进行标签转移限制的学习。
3)BiLSTM-CRF+INIT+词适应层。在BiLSTM-CRF+INIT的基础上加入词适应层,即本文构建的TL-BiLSTM-CRF迁移学习模型。
(1)源域模型性能对迁移效果的影响。此实验探究了源域模型的性能对目标域模型性能的影响,分别验证了在不同epoch下模型对Twitter数据集提升的影响。实验结果如图4所示。
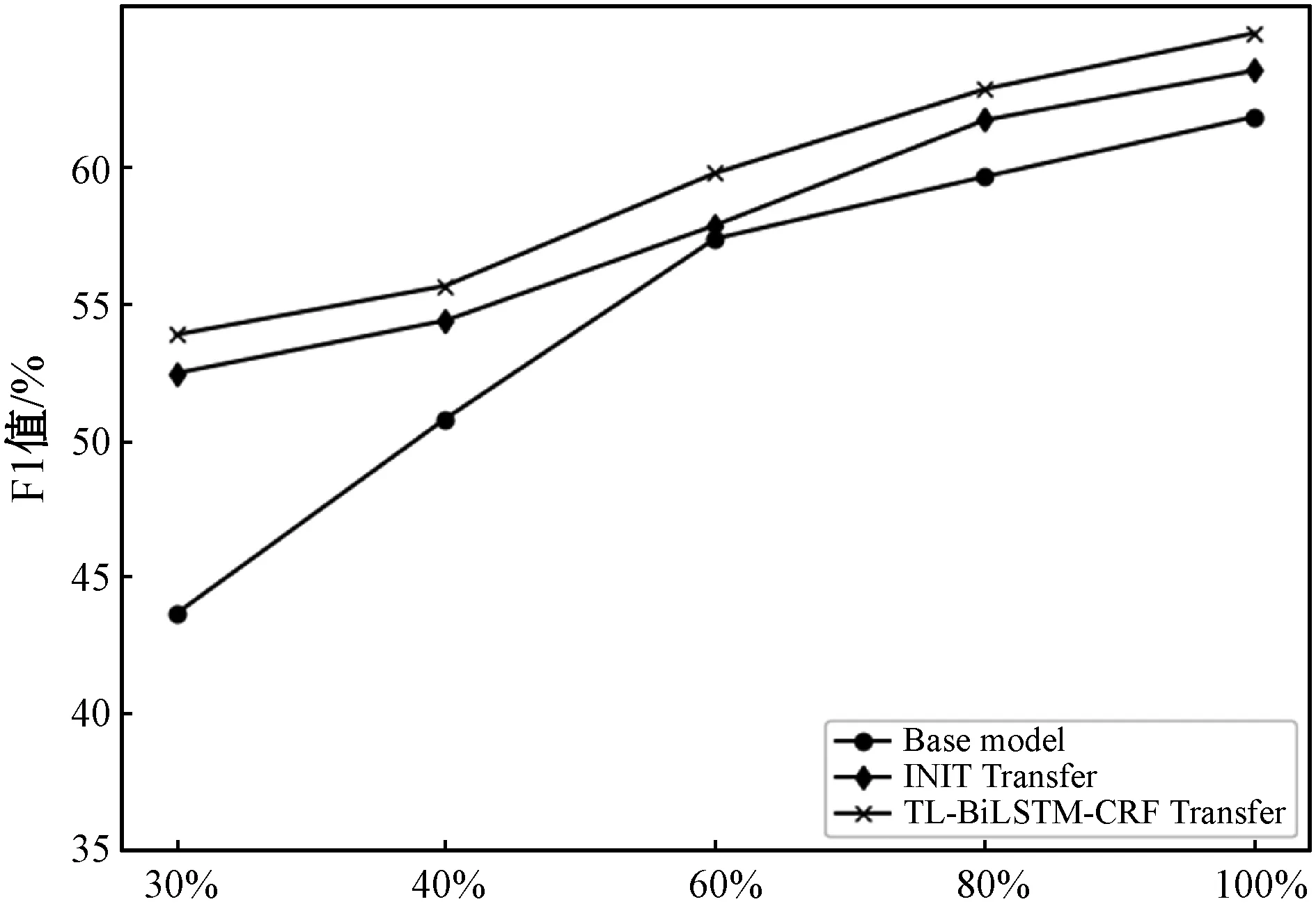
图4 不同epoch下模型对Twitter数据集F1值的影响
当源域模型训练为10epoch时,迁移的效果最好,F1值达到了64.87%。在源域模型训练为60epoch时,模型出现了负迁移现象。究其原因,源域模型性能越高,则参数与源域数据集的关联越大,可能会造成过拟合现象,此时不再适合对目标域数据进行知识的传递。源域中F1值在前8轮中迅速增长,后面训练过程则增长缓慢,说明如果直接从源域前几轮中进行参数学习,可以节约训练源域的时间,同时提升目标域中的性能。
(2)Twitter数据集大小对迁移效果的影响。此实验主要是评估迁移学习在模型中提高目标域中社交媒体命名实体识别性能的程度,量化目标数据集大小对迁移效果的影响。在迭代次数为10epoch的情况下数据集大小对迁移性能的影响如图5所示。

图5 Twitter数据集大小对迁移效果的影响
相较于基本模型,BiLSTM-CRF+INIT和BiLSTM-CRF+INIT+词适应层通过对源域知识的迁移都提高了F1值,说明目标域可以从源域数据集中学到的特征进行利用以提高目标域的性能。通过对比BiLSTM-CRF+INIT和BiLSTM-CRF+INIT+词适应层可以看出,加入词适应层后F1值在不同比例训练集大小上都有进一步提高。词适应层能够弥合源域和目标域词向量空间差异,使其具有相同的特征空间,因此可以提高模型的命名实体识别性能。
随着目标数据集的增大,迁移提升效果会逐渐降低。当使用目标数据集的30%时(此30%对应的是Twitter训练集大小的比例),迁移效果最佳,比基本模型F1值提高了10.21%。如果将目标域中的所有训练集都用于训练,F1值也有3.06%的提升。
3.3.2对比实验
(1)CRF-PRED[26]。机器学习中序列标注最为经典的方法。采用开源工具包CRFsuite—0.12建立模型。
(2)Rodriguez(2018)模型[26]。Rodriguez(2018)是一种基于模型的迁移学习算法,采用Pre-training方法,在源域数据集上训练神经网络,利用训练好的权值初始化神经网络,并对目标域模型进行微调,在社交媒体命名实体识别中取得了较好的性能。
(3)Lample(2016)模型[27]。Lample(2016)模型采用BiLSTM-CRF神经网络结构,在命名实体识别任务中得到了广泛的应用。
(4)Yang(2017)模型[18]。Yang(2017)模型采用多任务学习的方式构建了一个融合迁移学习的深度层级网络模型,能够缓解目标领域标注和内容数据稀缺问题,在社交媒体命名实体识别中达到了目前最优的性能。
(5)TL-BiLSTM-CRF迁移学习模型。本文提出的一种基于特征、模型的迁移方法与神经网络相结合的模型。表3中对比了与其他主流模型在Twitter数据集上的对比情况。

表3 Twitter数据集上F1值对比
从实验结果可以看出,TL-BiLSTM-CRF迁移学习模型召回率远远高于CRF-PRED,能够避免手动构造特征模板等不足,实现了端到端的训练。
与Rodriguez(2018)模型相比,本文的TL-BiLSTM-CRF迁移学习模型在精确率、召回率、F1值均有所提高。实验表明基于特征、模型的迁移方法与神经网络相结合的TL-BiLSTM-CRF迁移学习模型比单独基于模型的迁移学习算法的Rodriguez(2018)模型进行社交媒体命名实体识别有更好的性能。
与Lample(2016)模型相比,TL-BiLSTM-CRF迁移学习模型在精确率、召回率、F1值均优于Lample(2016)模型的实验结果,分别提升了2.56%、3.76%、3.45%。主要原因是TL-BiLSTM-CRF迁移学习模型通过迁移学习算法通过利用源域OntoNotes-nw数据集来提高模型性能,解决了目标域数据集少的问题。
TL-BiLSTM-CRF迁移学习模型优于目前最好的Yang(2017)模型,F1值提高0.56%。Yang(2017)模型通过多任务学习的方式,每次训练都需要同时训练源域和目标域的数据。尤其是当源域数据很大时,会额外增加训练的时间、消耗更多的资源。而TL-BiLSTM-CRF模型仅需在源域模型中训练一次,避免了Yang等的模型重复构建模型的不足。
表4中分析了Twitter数据集中10种实体类型的精确率、召回率、F1值情况,实验结果由十折交叉验证求取均值获得。

表4 Twitter数据集上F1值对比不同类型

续表4
可以看出:person类、geo-loc类、facility类作为常规实体类型其F1值相对较高;Product类、tvshow类、Movie类的精确率高但召回率较低,究其原因是这类命名实体结构较为复杂,类型长度没有限制、新词更新速度较快且实体名称没有统一的命名规范,故召回率相对较低;Musicartist类的精确率、召回率、F1值均较低。通过分析标注结果来看是由于Musicartist类实体储备较少且存在别名、缩略词,例如测试集数据中的“30stm”是美国摇滚乐30 Seconds To Mars的简称,模型未能识别。
本文利用公开数据集WNUT16进行实验验证模型的泛化能力。WNUT16数据集是国际计算语言学大会组织的关于用户生成嘈杂文本命名实体测评数据集,数据集是从社交平台、网络论坛在线评论的嘈杂文本上整理。表5对比了提交模型中F1值前三名的CambridgeLTL模型、Talos模型、Akora模型,其F1值分别达到了52.41%、46.16%、44.77%;TL-BiLSTM-CRF模型F1值到达了53.11%,优于CambridgeLTL。

表5 WNUT16数据集F1值对比
综上所述,基于迁移学习的TL-BiLSTM-CRF通过INIT模式与词适应层的构建,从源域数据集中学习到更多的知识,提升了模型在社交评论领域中模型的性能。
4 结 语
针对社交评论命名实体任务,本文提出的TL-Bi-LSTM-CRF迁移学习模型能够充分利用BiLSTM网络获取单词形态特征的字符向量,通过字词结合的方式补充单一词向量的不足,并且在迁移过程中加入词适应层,弥合了源域和目标域词向量空间的差异,进一步提高了命名实体任务中社交评论实体识别性能。实验结果表明,基于TL-BiLSTM-CRF迁移学习模型的命名实体识别在Twitter数据集上取得了性能上的提升,F1值为64.87%,优于目前最好的模型。
TL-BiLSTM-CRF迁移学习模型在命名实体识别的处理中,通过深度学习和基于特征、模型的迁移学习算法的结合,能够在不同的领域中学习构建模型发挥重要的作用。相较于通用领域NER准确率,特定领域NER还有很大的提升空间。下一步可以尝试使用更为复杂的神经网络模型并在消除目标域与源域向量空间差异等方面开展工作。
