基于模糊动态阈值机制的能效虚拟机合并决策方法
2022-01-28陈妍
陈 妍
(广西财经学院研究生处 广西 南宁 530003)
0 引 言
云数据中心的主机PM功耗是云计算应用研究领域不可回避的问题,它带来了巨大的能源消耗,大幅增加了云计算环境的运营成本。研究表明,云计算环境中数据中心的运营总成本中,基础设施和电力成本占近70%,而信息技术成本仅占30%[1]。利用虚拟化技术使得多个虚拟机可以部署在同一台主机上,并在多个虚拟机之间实现负载的平衡[2-6],并以此改善数据中心中主机的能效,但在此过程中涉及虚拟机资源合理合并的问题。而另一个需要面临的问题是数据中心中拥有随机变化的负载状态,它会导致虚拟机合并对主机中的资源预留产生负面影响,进一步导致服务等级协议SLA的违例,影响服务性能。同时,虚拟机合并过程中,超载主机的虚拟机需要迁移以平衡负载,而低载主机上的虚拟机迁移后会转换为节能休眠模式。这会增加虚拟机迁移次数,且每次迁移会请求额外的计算开销,从而导致功能的增加。因此,在满足SLA的同时,优化能耗和资源利用率是亟待解决的问题。
相关研究[7-11]将利用虚拟机合并优化能耗问题划分为四个步骤:1)发现数据中心中的超载主机。超载主机会导致主机资源不足和服务性能降低,导致用户得到低质量的服务。因此,为了改善超载主机的服务质量,一些虚拟机必须迁移至合适的目标主机上[12]。2)定义低载主机,将其负载迁移至其他主机上,并将该主机转换为节能模式。该步骤有利于节省空闲主机的无用功耗,但是需要将其上的所有虚拟机迁移至合适目标主机上。3)寻找来自于超载或低载主机的迁移虚拟机的合适部署目标主机。4)在超载主机上选择最优的虚拟机进行迁移。虚拟机合并[13]固然是改善主机功耗的有效方法,但是也会带来由于数据中心负载变化而引起的性能下降。
已有研究方法通过分析先前历史负载发现超载主机,多是基于资源利用率的固定阈值方法,这并不适用于无法预测负载的动态云计算环境,因为它会导致虚拟机迁移量的增加,从而影响服务质量。阈值必须根据当前负载进行自适应调整。为了解决这一问题,本文提出了一种模糊动态阈值方法对虚拟机合并过程进行决策,在动态负载环境下实现最小化的虚拟机迁移量。算法基于当前的资源利用率、预测利用率以及CPU的当前阈值,动态调整阈值的上下限。为了自适应调整,算法通过预测值与实际值的差异,计算主机的剩余资源能力和温度。而剩余能力和主机温度的计算值则进一步用于动态调整阈值的上下限。剩余能力和主机温度的模糊值则用于计算阈值变化。若阈值变化为正值,则表明需要增加先前阈值;若为负值,则需要降低先前阈值。阈值增加或降低量则由剩余能力和主机温度的模糊值进行动态决策。最终,算法可以以最小化虚拟机迁移量为目标动态改变主机资源利用阈值,消除无用迁移,降低主机功耗。
1 相关研究工作
目前,很多研究方法已集中于云数据中心的能效优化,多集中于最小化能耗的虚拟机合并方法[14-16]。该方法需要在超载主机上进行有选择的在线虚拟机迁移,以及低载主机的全部虚拟机迁移。一些方法[7,12,17]利用阈值方法完成虚拟机合并,包括静态阈值和动态阈值决定超载和低载主机。静态阈值有利于发现超载主机,而动态阈值则可以利用先前负载数据调整分析新的阈值。阈值方法中,若主机CPU利用超过上限,则将其考虑为超载主机;若低于下限,则考虑为低载主机,如文献[13,18-19]均采用了静态的上下阈值方法。这类方法试图将当前的CPU利用率保持在上下限值范围内。但是,任务负载并非一成不变,动态负载会使得虚拟机利用是连续变化的。文献[7]利用线性回归预测CPU利用率,并相应作出虚拟机迁移决策。其未来的CPU利用基于先前利用率进行预测,且在初期进行虚拟机迁移以避免SLA违例。但是,该方法得到的不必要迁移过多,计算代价过高,不适合于云环境。文献[12]利用阈值方法避免CPU被100%占用,从而导致性能下降。虽然该方法可以确保利用率低于上阈值,但是不变的阈值在面临动态负载时仍然无法准确地确定未来的资源占用。文献[13]分析了发现超载主机的不同方法,以确保在能耗和性能间取得均衡。文献设计了自适应的阈值确定方法,包括中位绝对误差法MAD、四分位法IQR、局部回归LR和局部加强回归LRR。前两种方法可以利用先前值在预测值的基础上对阈值进行自适应调整。算法主要集中于根据CPU利用率的误差长度调整上阈值。然而,MAD会由于小数量的极端值间的距离量级而产生限制,这会使最终预测结果产生较大误差。后两种方法虽然可以得到较好的预测值,但方法过于复杂,且对样本数据的要求精度过高。文献[20]利用模糊Q学习方法发现超载主机。该算法利用一种模糊聚类机制对高斯隶属度函数进行评估,但求解时间太长,收敛性能无法得到保证。
为了解决已有静态阈值方法和自适应动态阈值方法的限制,本文引入利用基于先前负载趋势的预测负载下的模糊阈值算法。算法根据当前资源利用率、预测利用率以及CPU的当前阈值,调整主机的上下限阈值。为了实现该目的,算法首先计算主机被利用服务于虚拟机后的剩余能力和主机的温度,并得到当前值与实际利用值的差值。主机剩余能力和温度值的计算值进一步用于调整上下限阈值。而剩余能力和主机温度值的模糊值则用于计算阈值的变化。若阈值变化为正值,则表明需要增加先前阈值;若为负值,则需要降低先前阈值。阈值增加或降低量则由剩余能力和主机温度的模糊值进行动态决策。最终,算法可以以最小化虚拟机迁移量为目标动态改变主机资源利用阈值,消除无用迁移,降低主机功耗。
2 基于模糊动态阈值能效虚拟机合并算法
2.1 算法设计
本文将提出的基于模糊动态阈值的能效虚拟机合并算法命名为EVMCFDT算法。算法的实施由多个组件构成,如图1所示。算法实施的云计算环境中假设多个虚拟机可运行在相同的主机上,每个虚拟机可以运行一类应用任务。具体地,系统由三个组件构成:虚拟中央处理单元VCPU利用控制组件、VCPU利用预测组件、模糊控制组件。

图1 算法模型
EVMCFDT算法根据CPU的当前利用率和预测利用率计算主机的剩余能力(以MIPS数量衡量)和主机温度。CPU利用率的历史数值进一步用于预测CPU的未来利用率。最后,主机温度计算为当前利用率与预测利用率的差值。EVMCFDT算法模型中模糊组件将主机温度和主机剩余能力值作为输入,该输入值通过子组件模糊器Fuzzifer进行模糊化,进而触发子组件推理系统Inference system中规则库Rule base中相应规则。规则库基于模糊输入值返回阈值变化的模糊值,而阈值变化模糊值通过子组件去模糊化器Defuz-zifer进行去模糊化,以得到新的阈值的语义值。三个组件的具体工作方式如下:
1)VCPU利用率控制组件。该组件负责度量处理器计算资源的当前利用率。为了对主机当前利用率计算进行形式化,令P={p1,p2,…,pN}表示数据中心内所有主机的集合。主机pi的CPU资源的当前利用率可计算为如下的矩阵形式:

因此,在时隙k内主机的CPU利用率可计算为:
(1)
2)VCPU利用率预测组件。该组件负责预测CPU的未来需求,根据历史数值计算资源的预测值。多种方法[21-22]可用于云环境中虚拟机对于CPU的未来需求的预测,本文将利用自回归积分移动平均法ARIMA在基于先前值的情况下对CPU未来需求进行预测。为了对预测模型进行形式化表示,在已有数据中心主机集合的前提下,主机pi的CPU资源利用率的预测值可计算为:
(2)

3)模糊控制组件。该组件是基于模糊逻辑的反馈控制器,其具体组成如图2所示,由四个子组件构成:模糊器Fuzzifer、推理系统Inference system、规则库Rule base、去模糊器Defuzzifier。
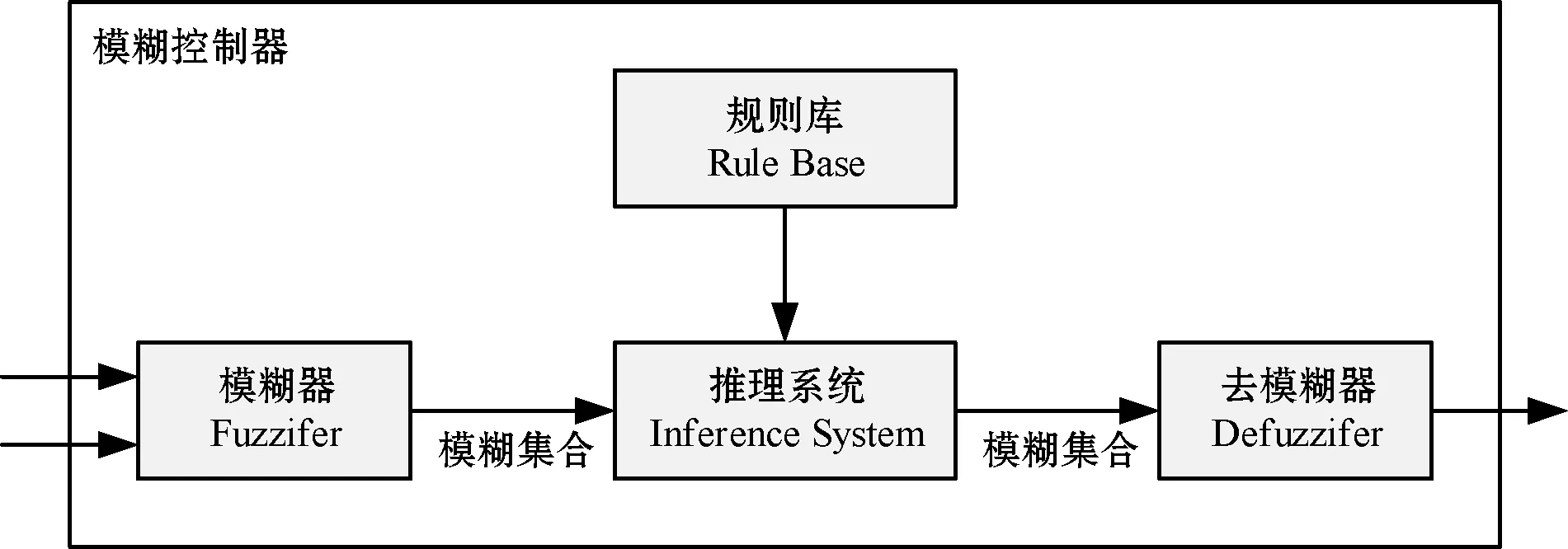
图2 模糊控制组件的结构
模糊控制组件接收两个输入参数:主机温度Ptemp和主机的剩余能力Crem。两个参数根据CPU资源的当前利用率、预测利用率以及空闲的MIPS计算得到,如图1所示。具体地,时间k时CPU的两个参数值分别计算为:
(3)
(4)
其中:Crem表示主机的剩余能力,为实际可用的CPU能力与观测到的VCPU利用率的差值;UtilizedMIPS表示主机上已经利用的CPU的MIPS;TotalMIPS表示总共分配的CPU的MIPS。推理系统接收主机温度和主机剩余能力的模糊值作为输入。主机温度和主机剩余能力的模糊值则利用模糊三角隶属度函数进行计算,如图3所示。

(a)对于Crem的隶属度函数
由图3(a)-(b),Crem可以得到三个模糊值,分别为Low、Medium和High,Ptemp可以得到三个可能的模糊值,分别为Cold、Normal和Hot。其关联度则可以通过三角隶属度函数计算得到。推理系统基于输入参数的模糊值触发规则库,生成一个模糊输出值作为阈值的变化。模糊输出值进一步通过输出隶属度函数被去模糊化,如图3(c)所示。
去模糊器子组件Defuzzifier结合规则,通过推理系统利用引力中心策略COG计算控制行为。推理系统选择的模糊规则可能得到一个以上的模糊结果。因此,利用引力中心策略,控制行为的数值结果可以计算为:
(5)
式中:μ表示隶属度函数的等级i;aij表示规则表中对应的单元值,具体如表1所示。
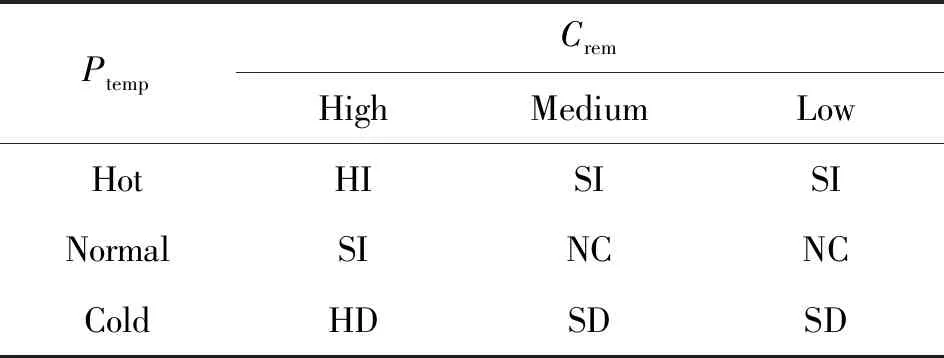
表1 算法规则库
规则库由一个模糊规则集合构成,可基于输入的模糊参数作出行为决策。规则以“If-Then”表述的形式存储,可以将控制知识转换为推理系统组件所能进一步利用的形状。具体地,规则库中的规则定义了其可被应用的条件以及控制其应用的输出。算法模型中,If将在主机温度和剩余能力的模糊输入参数下被应用以生成阈值的变化值。
表1中的每个单元代表规则库的一个具体规则。例如:IfPtemp为Hot,Crem为Low,Then输出的阈值变化为SI(small increase),即表明所获得的阈值新值为已有阈值基础上较小增加的值。
2.2 算例分析

两个输入参数值通过利用三角隶属度函数的模糊器进行模糊化,如图3(a)和图3(b)所示。如前所述,此时可以得到规则库表中的多重值,而最终的输出为多重值的聚合,并利用图4中的引力中心策略COG计算得到。算法利用的是每个单元值中隶属度函数的最小值,如图4所示。

图4 EVMCFDT算法的模糊取值过程实例
COG的最终输出值计算为:
-2.19≅-2%
所计算的阈值变化控制行为为-2,因此,新的阈值计算为:
New_Thi=C_Thi+controlAction=90-2=88%
算法实施过程中,阈值的调整周期性进行,以满足云数据中心内主机负载的动态变化。同时,算法约定若当前利用率低于30%,则主机将被视为低载主机,此时,其上部署的所有虚拟机将被迁移至其他主机上。
3 性能评估比较
3.1 实验搭建
为了评估EVMCFDT算法的性能,利用CloudSim仿真工具包模拟云环境下的数据中心。仿真环境由N台异构主机组成,利用三类型负载数据进行实验评估,主机承担的负载相关参数主要包括执行负载的整体虚拟机VM请求数量、相应负载的均值、标准方差、第1个四分位差值、中值以及第3个四分位差值,具体负载数据的相关特征描述如表2所示。可以看出,三种负载在虚拟机请求量上均有差别,负载2的请求量最多;而负载均值、标准方差等统计量的描述上的不同则说明了三种测试负载会在不同时间段出现不同的负载分布。四分位差则反映的是中间负载的离散程度,其值越小表明中间负载越集中,其值越大则表明负载较为分散。总体来说,三种负载数据之间从统计特征上来说具有较大的差异性,而负载特征的不同类型可以充分测试虚拟机合并算法的稳定性和健壮性。

表2 负载数据相关特征值
利用基于Java的开源库jFuzzy-Logic[23]实现算法的模糊逻辑。jFuzzy-Logic库提供了一种模糊推理系统FIS的完整实现方式,并可以内嵌在CloudSim平台中实现算法的模型机制。同时,实验中利用CoMon工程中的PlanetLab[24]所提供的现实负载流数据进行测试。
主机的CPU频率以每秒百万指令数MIPS表示,主机均是双核处理器配置。选择的主机类型1为HP ProLian ML110 G4,每个核心配置1160MIPS,类型2为HP ProLian ML110 G5,每个核心配置2660MIPS。每台主机提供1 GBit/s的带宽。假设虚拟机类型特征参照Amazon EC2中的实例类型进行创建,包括:high-CPU medium实例,配置为2 500MIPS、0.15 GB;extra-large实例,配置为2 000MIPS、3.75 GB,以及small实例,配置为1 000MIPS、1.7 GB;micro实例,配置为500MIPS、613 MB。仿真实验中,从PlanetLab数据流中选择了三个不同日期的负载流数作为虚拟机上的随机负载数据进行测试。
EVMCFDT算法为计算阈值变化,主要涉及三种类型的具体操作,即计算CPU利用率、预测CPU利用率以及根据主机温度和主机剩余能力的模糊输入计算阈值变化的FIS。算法的输出是调整阈值的上下限以降低虚拟机迁移频率并改善主机能效。
3.2 性能指标
1)功耗。本文利用线性功率模型度量主机功耗[12,25]。每台主机的线性功率模型表示为:
P(cu)=k×Pmax+(1-k)×Pmax×cu
(6)
式中:Pmax表示主机满负载利用时CPU的峰值功率,实验中设置为250 W;k表示静态功率系数,等于空闲处理器的功耗。由文献[25]可知,空闲CPU仍然会消耗100%利用的CPU的功耗的70%,因此,k取值为70%。
2)虚拟机迁移量。虚拟机的在线迁移代价通常较高,会导致CPU处理以及主机间的带宽的额外消耗。同时,迁移进行时,虚拟机保持不可用状态。而迁移过程中虚拟机的不可用属性将会导致SLA的违例。研究表明[13],所有虚拟机的迁移需要占用近10%的CPU利用。因此,过多数量的虚拟机迁移势必会带来功耗的增加。而本文算法的目标即是通过减少虚拟机迁移量来降低主机功耗。
3)SLA违例。利用两个参数:每个活动主机的SLA违例时间指标SLATAH和迁移带来的性能下降指标PDM度量EVMCFDT算法的性能[26]。SLATAH定义为观测到的活动主机100%的CPU利用率的时间比例,即:
(7)
PDM定义为由于虚拟机在线迁移导致的性能下降(导致SLA违例),即:
(8)
式中:N表示活动主机数量;Tsi表示主机pi的100%CPU占用的总时间;Tai表示主机在活动状态下经历的总时间;M表示虚拟机的数量;Cdj表示由于迁移导致的虚拟机j的性能降低估算;Crj表示在其生命周期内虚拟机j请求的总体CPU能力。因此,SLA违例指标可定义为:
SLAV=SLATAH×PDM
(9)
为了度量算法在SLA违例和能效ESV方面的综合性能,利用如下的ESV指标[26]:
ESV=SLAV×Energy
(10)
3.3 实验结果
选择文献[13]中的IQR算法、MAD算法、LRR算法以及LR算法进行性能对比。利用SLA违例、虚拟机迁移量、主机功耗,以及代表功耗与SLA违例均衡的ESV指标进行性能对比,结果如图5-图10所示。可以看到,EVMCFDT算法在所有测试工作流类型中均比其他算法拥有更好的性能表现。实验1中,EVMCFDT算法降低功耗约为25.12%,降低SLA违例(包括SLVA指标)约为49.09%,降低迁移量和ESV值分别约为52.69%和50.11%。实验2中,EVMCFDT算法降低功耗约为20.33%,降低SLA违例(包括SLVA指标)约为60.59%,降低迁移量和ESV值分别约为37.39%和44.19%。实验3中,EVMCFDT算法降低功耗约为22.55%,降低SLA违例(包括SLVA指标)约为59.14%,降低迁移量和ESV值分别约为41.51%和49.45%。此外,MAD和IQR算法在主机CPU利用率与先前利用率相同时出现一些限制,此时阈值会固定为接近100%。在这种情况下,MAD和IQR算法会导致更多的SLA违例。LR算法则更受观察的CPU利用率的极端值的影响,但这无法代表大多数的数据行为。本文提出的EVMCFDT算法比较四种算法在动态调整上下限阈值方面则展现出更好和更准确的模糊决策,且不会受到极端数据点和低扩散的先前数据点的影响。EVMCFDT算法利用基于当前及先前数据值的模糊推理方法,有效计算了阈值变化,正确做出了对上下限阈值的调整,从而降低了虚拟机迁移量,并减少了主机功耗。

图5 能耗指标
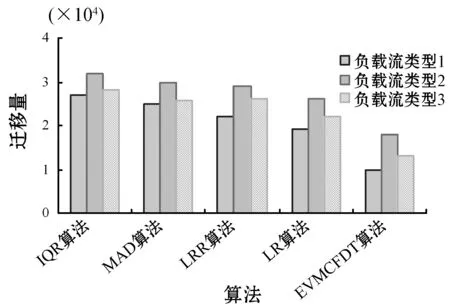
图6 虚拟机迁移量指标

图7 SLAV指标

图8 SLATAH指标

图9 PDM指标

图10 ESV指标
如图6所示,EVMCFDT算法有效降低了虚拟机迁移量,这直接影响了PDF的取值,算法也因此降低了SLAV,如图8所示。EVMCFDT算法基于历史数据利用预测负载值计算低阈值,可以降低由于超载主机上虚拟机迁移导致的功耗。
4 结 语
云数据中心动态的负载状态使得虚拟机合并技术会不可避免地带来SLA违例和能耗的增加,实时有效发现超载和低载主机是提升资源利用率、优化能耗和降低SLA违例所必须解决的关键问题。为此,提出一种模糊阈值决策方法用于动态调整主机利用率阈值。算法利用模糊推理系统动态调整主机资源利用阈值,使得超载主机上的虚拟机迁移大幅降低,并可以满足服务等级协议。三种不同负载流下的仿真结果表明,算法比较基准算法而言,在功耗、虚拟机迁移量以及SLA违例三个指标方面平均可以降低约22.52%、45.63%和56.68%。算法的不足在于仅考虑了主机资源上最为关键的CPU利用率,下一步的研究可以同时将内存以及带宽资源考虑到算法优化模型中,利用模糊推理模型分别求得多种资源的利用阈值,从而更加准确地预测负载,得到有效的虚拟机合并过程。
