应用门循环神经网络的变电站智能记录分析装置信息配置方法
2022-01-27李铁成曾四鸣刘清泉任江波杨经超王敏学
李铁成,曾四鸣,刘清泉,任江波,杨经超,王敏学
(1.国网河北省电力有限公司电力科学研究院,石家庄 050021;2.国网河北省电力有限公司,石家庄 050021;3.武汉凯默电气有限公司,武汉 430223)
建设状态全面感知、信息互联共享、人机友好交互、设备诊断高度智能、运检效率大幅提升的智能变电站是国家电网公司战略目标的核心任务之一。该任务的基础,是保证由二次设备在线监视系统、运维主站、智能录波器与继电保护测试设备组成的智能变电站智能运维体系信息采集工作的正确性。
智能运维体系信息采集工作正确运行依赖于以智能录波器为核心的智能记录分析装置对二次设备数据输出端口地址信息的正确配置,投运时录波器将解析相关端口地址信息,准确采集各二次设备不同类型运行数据。目前主要配置方法是依据设备端口描述文本,人工配置相应的端口地址信息至录波器不同的信息组,录波器信息组包括压板信息组、告警信息组与状态信息组,各信息组又包含子信息组,例如,硬压板信息组、面向通用对象的变电站事件GOOSE(generic object oriented substation Event)断链告警信息组、在线监测信息组等。上述端口地址信息与端口描述文本均包含于智能变电站的全站配置描述SCD(substation configuration de⁃scription)文件中。在电压等级高、规模大、二次设备较多的智能变电站中,人工配置时间长、效率低且准确率难以保证,不符合变电站智能运维发展的要求。此外,由于智能电子设备能力描述文件ICD(intelligent electronic device capability description)模型没有统一规范,导致二次设备端口描述文本没有统一约定,而SCD文件由设计院基于ICD采用系统集成工具生成,因此难以实现SCD文件中二次设备端口地址条目的自动映射。
二次设备端口描述文本的自动分类映射的本质是中文文本分类问题。它分为文本的预处理[1]、文本表示、特征提取和分类器选择4个步骤。传统的分类方法有朴素贝叶斯法[2]、基于决策树法[3]、支持向量机法[4]等,这些浅层算法对数据的挖掘能力有限,且泛化能力不足。近年来深度学习已经广泛应用于自然语言识别[5]、图像识别[6]、音频处理等领域,深度学习分为统一特征提取与分类评估两个阶段,特征提取适合运用在文本分类中。在电力系统中,神经网络与深度学习理论[7]逐步发展应用,文献[8-9]构建了电力系统的基于深度学习构造的文本挖掘框架,并利用深度卷积神经网络分类模型对电力缺陷文本进行分类,结果表明,所提出的模型在分类准确率和效率上相比传统方法有显著提高;文献[10]利用循环卷积神经网络RCNN(recurrent con⁃volutional neural network)进行文本分类,可更好地融合上下文信息及最大可能的保留关键语义。
鉴于此,本文以门循环单元GRU(gate recur⁃rent unit)神经网络算法为基础构造文本分类模型,依据分类结果进一步实现端口描述文本对应地址信息的正确配置;结合实例样本进行实验分析,找出适用于二次设备输出接口描述文本的超参数。并将这一文本分类模型与其他主流深度学习文本分类算法进行性能对比,结果显示本文提出的模型在准确率和收敛速度上综合表现良好,从而有效提高了智能运维体系信息自动采集与灵活运用的能力。
1 智能变电站二次设备端口描述文本处理
1.1 二次设备接口描述文本的解析获取
在二次设备端口描述文本的获取中,首先,需要解析该变电站的SCD,利用Python语言中Ele⁃menTree模块解析该文件;然后,遍历智能电子设备IED(intelligent electronic device)标签,找到对应的具体二次设备。例如“主变本体测控”,通过检索IED标签的子标签功能约束数据属性FCDA(func⁃tionally constrained data attribute)值可以获取二次设备端口的地址描述信息,结合上述FCDA值与子标签数据对象实例DOI(data object instance)属性值、子标签数据属性实例DAI(data attribute in⁃stance)属性值,可获取端口匹配的具体描述文本,该文本包含于DOI标签属性desc中。
1.2 二次设备接口描述文本的特点
特点1文本中专业词汇多,如“断线”、“纵联”等,对于同一个事件描述可能用不同的词汇表达,例如“间隔层A-GOOSE4通信中断”和“间隔层AGOOSE4断联”等。
特点2二次设备接口描述文本篇幅短小,基于文本构造的词典词汇量较少,中英文混杂,文字呈现结构性特点。
特点3分词处理时需要额外扩充词汇。本文使用python中的jieba工具进行分词,在分词前需输入“高压”、“光口”、“光耦”等专业词汇扩展其分词词典,保证其分词的准确性。
1.3 基于word2vec的文本向量化表示方法
Word2vec[11]是一种词嵌入表达方法,它可以将一个高维稀疏向量映射到另一个低维稠密的向量中实现“嵌入”,显著减少了运行时间和内存资源的使用,其模型训练速度快,使用非常广泛的词向量分布式表达方法。Word2vec包含连续词袋CBOW(continuous bag of words)模型 和skip-gram两种模型。CBOW模型如图1所示。
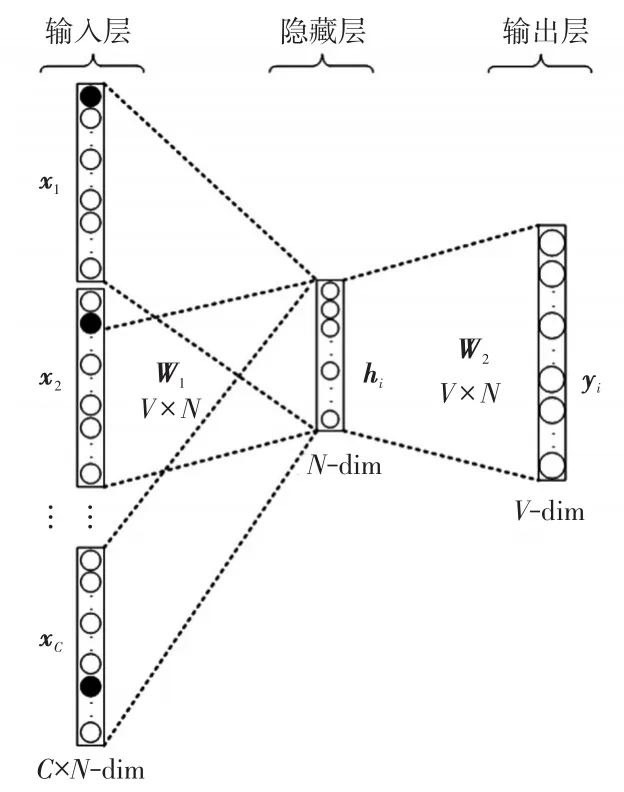
图1 CBOW模型示意Fig.1 Schematic of CBOW model
图1中,W1、W2分别为输入层矩阵和输出层矩阵;V为词向量的维度;N为隐藏层的维度。文本隐藏层词向量的平均值h可表示为

式中:xi为图中文本的第i个one-hot编码,i=1,2,…,C,C为文本中词的个数;vi为隐藏层的词向量;T为矩阵的转置。
文本的输出层向量w可表示为

模型损失函数E定义为

式中:wk为向量w中第k行的值:w0为目标词汇的值。通过梯度下降算法不断更新矩阵W1,最后用文本的one-hot编码乘以更新完成后的矩阵W1,可以得到该文本的分布式词向量,故W1又被称为查询矩阵。
训练一个样本需改变所有权重,训练速度慢,计算量大,为了提高训练效率,需要引入负采样技术,非目标词语的词向量即为负样本,负采样技术只选取少量的负样本减少需要更新的权重来提高计算速度。进行负采样前需要先进行二次采样,即先抽取少量的词作为样本,其中词抽中的概率与其出现的频率呈负相关,即

式中:wi为第i个词向量;p(wi)为词被选中称为二次样本的概率;z(wi)为词在样本集中出现的频率;t=10-5。


2 基于GRU神经网络的二次设备描述文本分类模型
本文选择了改进型长短期记忆LSTM(long short-term memory)神经网络的GRU神经网络分类器[12]。它将LSTM神经网络原有的遗忘门、输入门和输出门3个门整合为更新门和重置门2个门。在许多情况下,基于GRU神经网络与LSTM神经网络有同样的结果,但GRU神经网络的训练速度更快且过拟合问题较少。
2.1 GRU神经网络的结构单元模型
GRU神经网络结构如图2所示。

图2 GRU神经网络结构Fig.2 Structure of GRU neural network
图2中,zt为更新门;rt为重置门;ht-1为上一个神经元的输出;xt为现在的神经元输入;ht为该神经元的输出;为隐藏层状态;⊗为矢量相乘。
GRU神经网络的前向传播公式可表示为


2.2 GRU神经网络的文本分类过程
GRU神经网络的分类模型结构[13]如图3所示,其中,x1,x2,…,xn分别为二次设备的文本通过word2vec的词向量,h1,h2,…,hn分别为神经元隐藏层的状态量,可表示为

图3 基于GRU神经网络的分类结构Fig.3 Classification structure based on GRU neural network

式中:U为输入层权重矩阵;V为隐藏层权重矩阵。
分类器为softmax分类,预测某个二次设备描述信息的类别分类概率向量yi为

式中:t为故障录波器需要配置的信息组数;W为输出层的权重参数矩阵;为向量的第i个分量,其维度和智能录波器待分类的信息组数相等。
基于GRU神经网络文本分类模型的损失函数为交叉熵函数的logit变换(cross entropy with log⁃its),其表达式为

式中:T为二次设备的描述文本量;Yi为实际的类别分类概率向量。使用梯度下降法,在求得损失函数最小值的过程中不断更新权重矩阵,最后训练得到基于GRU神经网络的二次设备端口描述信息分类模型。
3 二次设备端口地址信息配置
在录波器运行时,通过解析其配置文件、端口地址标签等不同信息组内地址信息的描述数据,准确索引二次设备不同类型的运行数据输出端口,并采集相应数据至各信息组。录波器配置文件与SCD文件类似,本文在将端口地址描述数据录入前,依据端口描述文本对信息组的分类结果确定对应地址描述数据的信息组映射标签,通过Ele⁃mentTree模块遍历二次设备各信息组找寻正确类别,自动录入文本描述对应的端口地址描述数据,即FCDA相关属性值,完成端口地址信息的自动化配置。
4 实例分析与超参数调整
为了验证本文模型配置二次设备端口地址描述信息能力,选取某电网1 500组二次设备端口描述文本样本作为实例分析,其分类准确性代表端口地址描述信息配置的准确性。样本随机分为5份,其中4份选作训练集,1份选作验证集。训练集的作用是通过梯度计算,训练和更新模型中的各神经元的链接参数;验证集的作用是验证和评价网络的性能,用于确定正确的网络参数。
本文的训练样本待分类信息组源于压板信息组中的功能压板信息组、告警信息组中的光电牌告警信息组、状态信息组中的在线监测信息组,选取这3类信息组样本是因为它们具有样本最多、多样性最强、最具代表性的特点,其分类的准确度代表了分类总样本的准确度,部分文本样本举例如表1所示。

表1 文本样本举例Tab.1 Examples of text samples
本文模型采用Python语言编程,并加载使用Tensorflow工具包,CPU为Intel Core i5-6300HU,主频2.3GHz,模型超参数设置如表2所示。

表2 GRU神经网络模型超参数设置Tab.2 Hyper parameter settings of GRU neural network model
4.1 文本词向量的可视化分析
文本采取word2vec进行词向量表示,为了更直观的观测到词向量表达效果,选取录波器信息组的“功率”、“可视化”、“压板”作为中心词,并从二次设备输出接口文本找出与中心词词向量最接近的几个词,利用主成分分析法,将输出的词向量降维至二维空间,部分词向量的值如图4所示。

图4 Word2vec词向量聚类结果Fig.4 Clustering results of word2vec word vectors
由图4可知,在文本中同时出现次数较多且语义连接较为紧密的词,在二维空间中的距离就会比较近,例如“高压”和“保护”等。在文本中同时出现次数较少,语义关联度不大的词语在图中的距离很远,比如“功率”和“远方”等。由此可知,基于word2vec的文本词语向量表达的方法可以根据词向量距离来判断语义的关联程度。
4.2 基于二次设备描述文本的模型参数优化
4.2.1 特征提取能力优化
在GRU神经网络模型参数中,影响文本语义挖掘和分类能力的因素主要为隐藏层的层数。当隐藏层层数H=0时,能够处理可用函数表示的分类问题;当H=1或2时,搭配激活函数可以处理由一个有限空间向另一个有限空间的连续映射问题;当H>2时,网络可以学习更加复杂的分类问题。在实际中,往往需要先定性的确定H的大致范围,再通过实验来确定H的具体值。
本文根据二次设备接口描述文本的短文本特征构造了隐藏层层数为1~4的GRU神经网络,其中dropout比例为理论最优值0.5,取验证集的分类准确率作为模型的评估指标,设隐藏层层数为H,评估结果如图5所示。

图5 不同隐藏层下的GRU神经网络模型分类性能对比Fig.5 Comparison of GRU neural network model’s classification capability with different hidden layers
由图5可知,当H=1时,模型准确率最高为96%左右,这是由于二次运行设备的短文本较多,所以只需要一层隐藏层就有很好的分类效果;当H=2时,模型在更新次数为370次左右时开始收敛,并逐渐稳定,准确率最高为95%左右;当H=3、H=4时,出现了过拟合且准确率不足90%,不能满足分类需求。综上所述,当H=1时,模型的分类性能最好。
4.2.2 泛化能力优化
GRU具有强大的语义特征提取能力,但也隐藏了泛化性能差的风险[14],因此本文模型通过引入dropout层,随机舍弃部分特征提取结果以降低过拟合风险,dropout是指在深度学习网络的训练过程中按照一定的概率将神经网络单元暂时从网络中丢弃。为寻找dropout层较优的神经元保留比例dp,本文设置了dp=0.2,0.5,0.7,1的4种模型,并验证模型分类能力与泛化能力,设dropout层保留比例为dp,评估结果如图6所示。

图6 不同dropout值下的GRU模型分类性能对比Fig.6 Comparison of GRU model’s classification capability with different dropout values
由图6可知,当保留比例dp过小,即dp=0.2时,模型拟合能力变差,导致验证集准确率的收敛时间急剧上升,且分类精度下降;当模型不考虑舍弃神经元提高泛化性能,即dp=1时,验证集准确率的曲线出现了下降的趋势,说明模型复杂度过高;当训练集已发生过拟合现象,经过交叉验证,可以看出隐含节点dp=0.5时准确率最高。这是由于当dp=0.5时,所有神经元的排列组合数最多,即随机生成的网络结构最多,这样再将这些网络训练结果进行平均时,网络稳定性更好,泛化性能强,网络不容易出现过拟合。
4.3 不同文本分类模型的性能比较
为了验证GRU分类器的性能,本文选取LSTM神经网络和文本卷积神经网络TextCNN(text convo⁃lutional neural network)两种在文本分类领域应用较多的深度学习模型来进行性能对比实验,3者参数均选用最佳性能参数。
本文的分类模型性能对比如图7所示,具体参数见表3。由图7及表3可知,TextCNN虽然在收敛速度上优于GRU神经网络,但准确率却不如GRU神经网络,因为其分类性能受卷积核尺寸的影响,卷积核较小时难以对较长的文本序列建模;GRU神经网络模型结构相较于LSTM神经网络模型更为简单,在样本集不大的情况下,GRU神经网络模型的准确度和收敛速度都优于LSTM神经网络模型。由于二次设备端口文本篇幅短小、结构简单、词汇量少,TextCNN、LSTM神经网络和GRU神经网络模型处理1 500个实验样本的收敛时间分别为11 s、14 s和12 s,本文模型收敛时间较快,可以满足工程需求。

表3 分类性能对比Tab.3 Comparison of classification performance

图7 文本分类模型性能对比Fig.7 Comparison of performance among text classification models
5 结语
本文考虑到智能录波器依据二次设备端口描述文本实现端口地址信息自动化配置时,因描述文本专业术语较多、结构化较弱导致自动化配置困难,以及人工配置工作量大、误差率高的现状,提出了基于GRU神经网络文本分类的二次设备端口地址信息自动配置方法。首先,对二次设备端口文本描述进行分词处理;然后,用word2vec方法对其进行词向量表达,有效实现了端口描述文本词向量关联关系映射,降低了运算复杂度;最后,利用实例文本进行实验,证明当GRU神经网络分类器的dp=0.5,H=1时分类器性能最优,并且基于GRU的文本分类模型准确率可达96%以上,对比其他主流文本分类模型有明显优势。
