电子液压制动控制单元的混流装配线平衡优化研究*
2022-01-27蔡啟明李伟伟
蔡啟明,李伟伟
(南京航空航天大学 经济与管理学院,江苏 南京 211106)
0 引 言
国内某汽车零部件制造商加大对零部件的研发与投入,新开设了汽车电子液压制动控制单元的混流装配线。
电子液压制动系统是一种比机械制动更为高级的汽车安全技术,能够大大缩短制动距离。而电子液压制动控制单元是电子液压制动控制系统的核心元器件,对电子液压制动系统发出指令,直接影响汽车的制动性能。
混流装配线要能够满足多品种、小批量的需求,是一种能将多种具有相似工业流程的产品进行混合生产的装配线。但是,企业运用混流装配线时涉及到混流装配线的平衡问题,例如:工作站的数目过多,占用过大的面积,造成空间的浪费;各个工作站的装配时间分布差距过大会导致生产瓶颈的出现,工人负荷不均,生产停滞;分配工人在不同的工作站,不同的分配方式带来的成本也不一样;装配线的生产节拍,影响到企业能否完成企业的生产目标,等等。
目前,有很多学者关注混流装配线的研究。姚午厚[1]研究了混流装配线的多种优化算法对混流装配线进行了平衡的排序,开发了智能家居行业混流装配线平衡与排序系统。揣博君[2]以生产节拍、平滑指数和操作工人成本为多目标函数,用改进的遗传算法来进行求解。宋春雷[3]以最小化完工时间、零部件消耗速率均衡化和相邻产品相似度最大化为目标,建立了多目标投产排序模型,应用遗传算法和Pareto排序思想对模型进行了求解。张志文[4,5]建立了以MODAPTS为基础的标准工时系统,并结合线平衡理论建立了流水线平衡模型,再利用遗传算法求解出了最优化方案。戴韬[6]对混流汽车液压电子制动控制单元工艺过程进行了数学建模,采用优化遗传算法进行了求解。苏平等人[7]提出了一种综合运用遗传算法和仿真分析的混合装配线平衡问题的求解方法。胡罗克等人[8]应用工业工程方法和仿真技术,对实际企业的装配线做了系统科学的平衡分析和改善。BUKCHIN Y等人[9]通过对工人安排方案进行编码,用遗传变异寻求最小化工人空闲时间,提高了生产线的效率。LI Z等人[10]为了解决双面混合装配线的平衡问题,采用了多种启发式算法综合比较,证明了改进的迭代贪婪算法具有有效性。RASHID M[11]利用多目标离散粒子群优化算法来对整个混流装配线平衡和排序的问题进行了建模和优化。SAHU A等人[12]提出了一种新的遗传算法,提高了求解最小工作站数、瓶颈时间等参数的效率。AKPINAR S,SUNGUR B,DELICE Y等人[13-15]对混流装配线的工人分配进行了优化。
但是上述学者关注的是混流装配线的研究,还很少有人对汽车电子液压制动控制单元的混流装配线进行研究。
笔者通过建立以工作站数最小、装配节拍最小以及各工作站装配时间的均方差最小的多目标数学模型,利用改进的自适应遗传算法加快收敛速度,得到满意解,降低设备与库存成本,减少各工作站装配时间的波动,平衡生产线。
1 混流装配线平衡理论和研究问题
1.1 基本概念
此处所涉及到的几个关键的混流装配线键术语,详细基本概念可以参见参考文献中的前4条文献。
(1)工序优先关系图。表示产品装配过程中各个作业元素的先后关系。
A、B两种产品的作业元素优先图如图1所示。
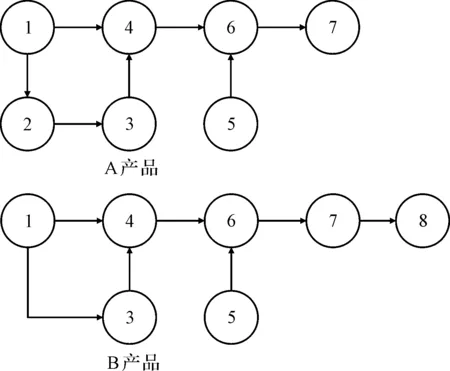
图1 A、B产品的作业元素优先图
(2)优先关系矩阵。将产品的作业元素优先图用矩阵来表示。
上图中A、B产品的优先关系矩阵如图2所示。


图2 A、B产品的优先关系矩阵
(3)综合作业优先关系图。A、B两种产品的综合作业优先关系图如图3所示。
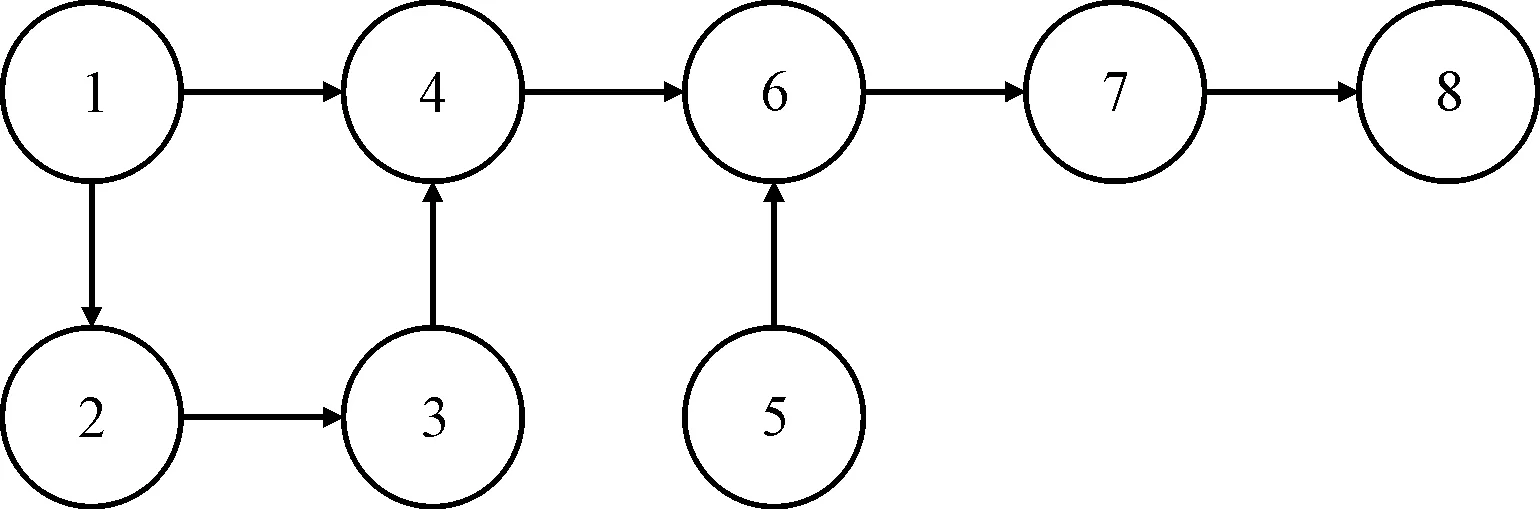
图3 A、B两种产品的综合作业优先关系图
1.2 电子液压制动控制单元的混流装配线
通过对某汽车零部件公司的电子液压制动控制单元的混流装配线进行研究发现,该公司主要装配3种不同型号的控制单元,包括零件的压装、电子控制-液压控制-马达合装、综合测试3大部分。其中,零件的压装是指利用压力机对组件进行压装;电子控制-液压控制-马达合装是指利用螺丝、压力机将液压控制单元、电子控制单元和电机三者连接;综合测试部分包括对传感器、油泵、制动器、电机等关键零件进行测试。
笔者绘制出3种制动控制单元的综合作业优先关系图,如图4所示。
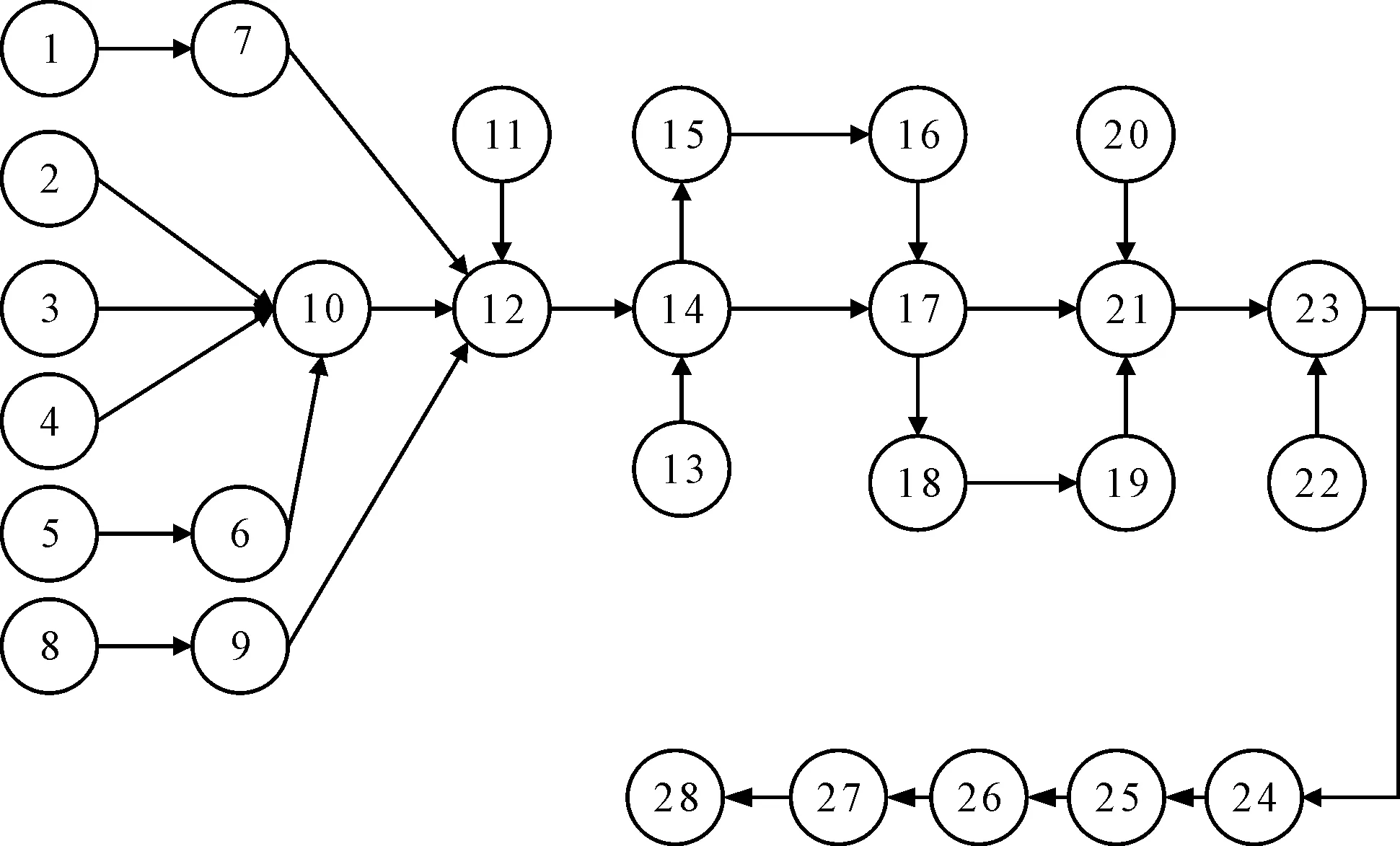
图4 3种制动控制单元的综合作业优先关系图
已知A、B、C 3种产品的需求量D1、D2、D3分别为400、100、100,所以各产品的需求比例q1、q2、q3分别为2/3、1/6、1/6;测得每个产品各工序的时间,并求得在综合作业优先关系图(即在混流装配线)中,装配这3种产品时各个工序的时间,如表1所示。
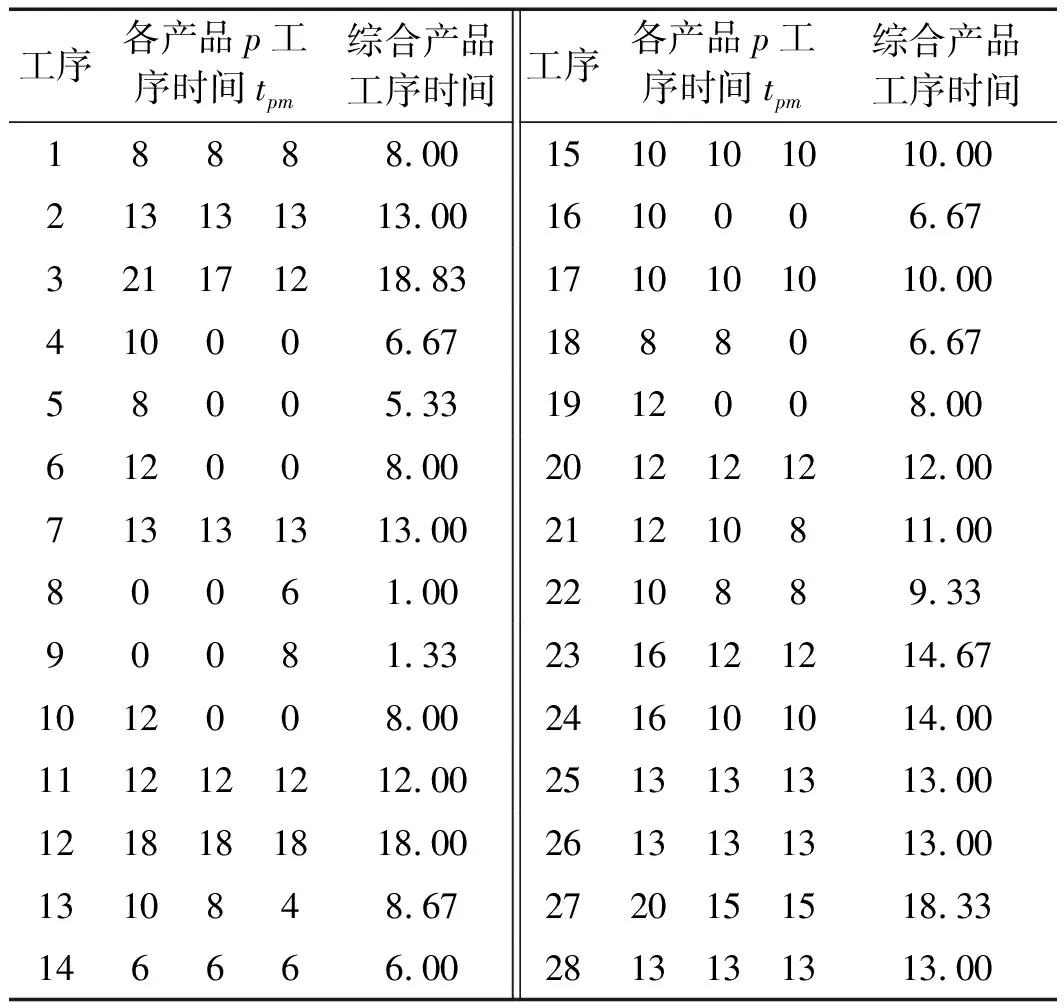
表1 各工序的时间
2 装配线平衡数学模型的建立
传统的混流装配线平衡主要包括3类:
(1)给定生产节拍,求解最小的工作站数;
(2)给定工作站数目,使得生产节拍最小;
(3)给定生产节拍和工作站数,使得各工作站负荷均衡。
汽车电子液压制动控制单元的混流装配线平衡问题在传统问题的基础上进一步拓展,笔者综合考虑生产节拍、工作站数和工作站间负荷均衡3个指标,对混流装配线进行统筹优化。
以下是具体的数学模型。
2.1 数学符号假设
TT—总有效生产时间;
D—所有产品的总需求量;
P—产品的种类;
Dp—第p种产品的需求量;
CTtheory—理论生产节拍,CTtheory=TT/D;
CTreal—实际生产节拍;
m—第m个作业元素,M—作业元素的总和;
qp—第p种产品的比例,qp=Dp/D;
w—第w个工作站,Wreal—实际工作站总数,Wtheory—理论工作站数;

tpm—第p种产品第m个工序所花费的标准时间;
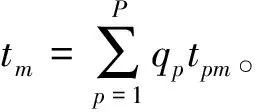
2.2 目标函数
为了使得企业获得更多的利润,对混流装配线平衡的研究已经不仅仅局限于单目标、双目标甚至多目标以提升多方面效益,例如:工人成本费用最少、生产节拍最小、工作站数目最少、各个工作站的负荷差异最小、传送带停止时间最少、总切换时间最少,等等。此处主要根据企业的实际需求,设定了3个目标函数:工作站的数目最少、生产节拍最小、各工作站的负荷均衡。
(1)工作站的数目最少
各工作站的数目最少为混流装配线平衡研究中的第一类问题,即在知道理论生产节拍时,确定最小的工作站的数目,来减少装配所需的空间、工人成本,等等。根据企业当前的有效生产时间和在有效时间内需装配的产品数量,来确定理论生产节拍,再根据综合作业优先图,得到总时间与理论的生产节拍的比值,得到理论上最少工作站的数目,即:
(1)
在进行作业元素分配时,会发现Wtheory太小,工作站的数目不能容纳所有的作业元素,这时再逐个增加工作站的数量得到实际工作站数目Wreal,即:
Wreal=Wtheory+k
(2)
式中:k—新增的工作站数目。
(2)生产节拍最小
求生产节拍最小是混流装配线平衡研究中的第二类问题,就是使得各工作站总时间的最大值最小化,它决定了能否在规定的时间内生产出足够的产品数量来满足客户的需求。
所以,实际的生产节拍最小化为:
(3)
(3)装配线平滑指数L最小
装配线平滑指数L用以衡量各工作地之间的作业负荷分布是否均匀,它是混流装配线中的第3类问题。装配线平滑指数L越小,表明各个工作站之间的加工时间越接近,作业元素的分配越合理。
装配线平滑指数L为:
(4)
2.3 约束条件
(1)每一个作业元素只能分配给一个工作站,即:
(5)
(2)每个工作站生产的时间不能超过CTtheory,即:
(6)
(3)必须要满足各个作业元素之间存在着产品工艺上的先后顺序,即:
(7)
式中:pre(m)—在工作元素m的紧前工序集合。
(4)各个决策变量必须为0或1,即:
xiw,xmw∈{0,1} ∀i,m,w
(8)
2.4 目标函数权重的确定
因此,这是一个多目标的优化问题,绝大多数情况下,多个目标函数不能同时取得最优解。对于决策者而言,当目标函数达到一定的范围即可认为是最优解。这里采用加权法来赋予3个目标函数不同的加权,使得多目标优化问题转化为单目标的优化问题,而加权由决策者的偏好决定。
这里采用层次分析法(AHP)的判断矩阵来确定各目标的权重,判断矩阵由3个目标重要性程度的比值组成。判断矩阵的元素一般用数字1~9来确定,代表不同的重要性程度。工作站的数目影响了混流装配线的占地面积、工人成本、空闲时间,等等。
实际生产节拍的大小决定了单位时间里生产的产品数量以及产品能否按时交付给客户,其重要性不言而喻,明显重要于各个工作站之间的负荷分配是否均衡。
因此,笔者构造多目标的判断矩阵如表2所示。
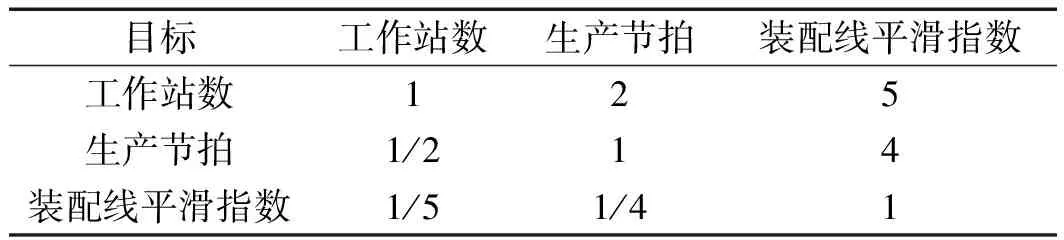
表2 目标函数的判断矩阵
根据判断矩阵求解,可得到3个目标的权重分别为0.57、0.33和0.1。此时,多目标优化就转化成了单目标优化,即:
minf=0.57Wreal+0.33CTreal+0.1L
(9)
(10)
3 自适应遗传算法求解
该类数学模型属于NP-hard问题,一般利用启发式算法求解。遗传算法就是一种启发式算法,根据适者生存的原则,利用适应度函数来对方案进行评价,从而择优汰劣;各个方案之间再进行交叉、变异生成更好的方案,再次进行择优劣汰,如此迭代一定的次数得到最优方案[16]。
遗传算法流程图如图5所示。
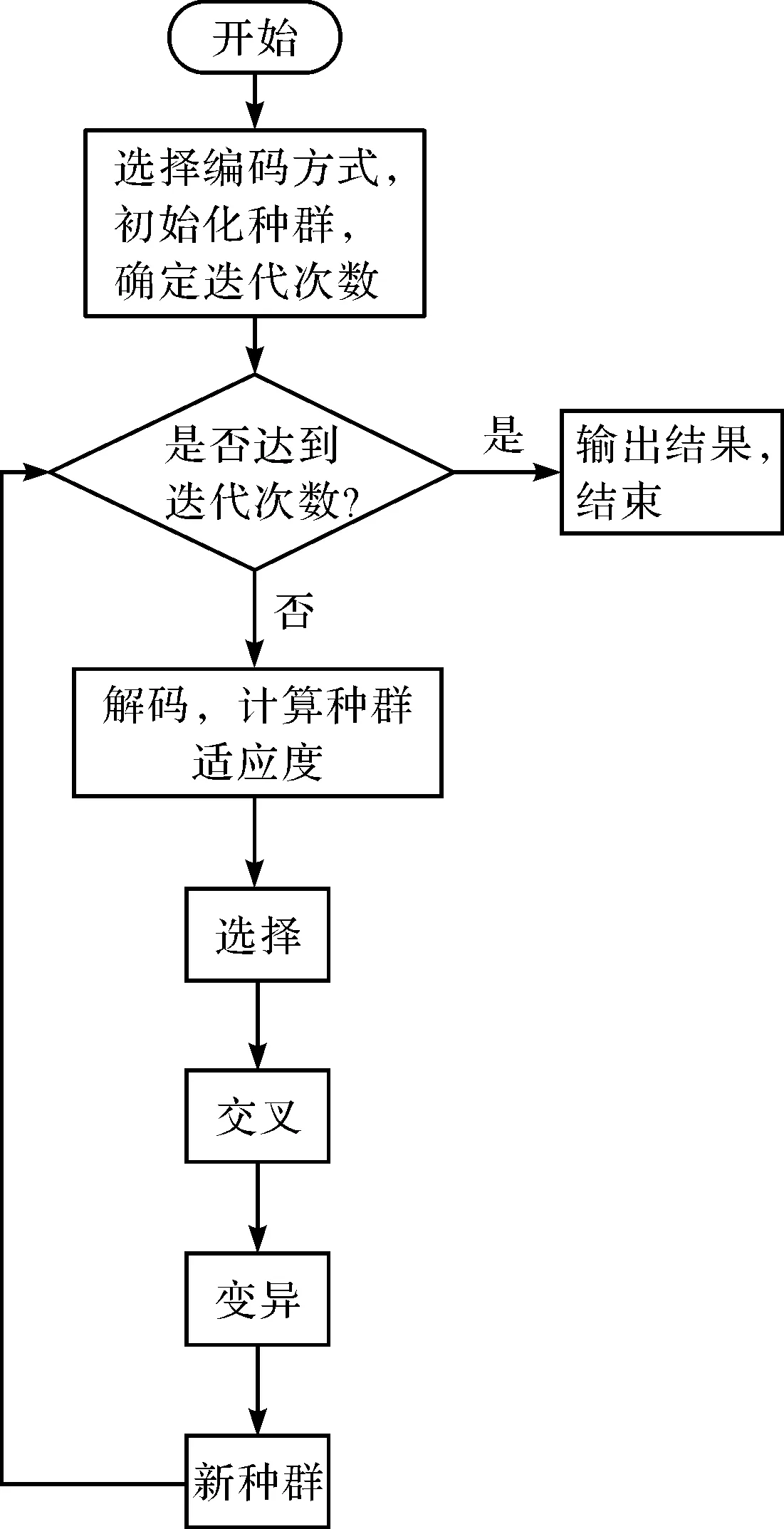
图5 遗传算法流程图
3.1 编码方式
自适应遗传算法的第一步就是确定编码的方式,合理的编码方式便于计算适应度,简化交叉和变异操作,提升算法的执行效率。编码方式分为二进制编码、整数编码、实数编码等。不同于标准遗传算法的编码方式,笔者采用基于综合作业优先图的整数编码,各个位置上的基因排列必须遵循作业元素的先后顺序,并且每个工序只能出现一次,染色体的长度与工序的个数相等。
根据综合作业关系优先矩阵来得到一条染色体的基因序列,其编码过程分为两步:
(1)创建s=Judge(PA)函数,用于生成可以分配的工序s,s是函数返回值,并且这些s满足当前综合作业关系优先矩阵条件。假设PA为综合作业关系优先矩阵,y代表工序的个数,i代表工序的编号。具体操作过程如下:
Step1:i=1,判断PA第i列是否全部为0,如果是则将工序i放入s中去,否则执行Step2;
Step2:i=i+1,重复Step1,直到i=y结束,将此时的s作为函数的返回值;
(2)创建c=P_chrom(PA)函数,用于生成当前PA条件下的一条染色体c,染色体c是函数返回值。y代表工序的个数,j代表s的长度,i代表工序的编号。具体操作过程如下:
Step1:i=1,利用Judge(PA)函数得到s;
Step2:从s中随机抽取一个工序t放入染色体c中;
Step3:使得PA中的t列为inf,t行为0;
Step4:i=i+1,重复Step1、Step2、Step3,直到i=y结束,将此时的c作为函数的返回值。
下面将图2中A产品的优先关系矩阵作为PA,举例说明编码操作:
Step1:i=1,利用Judge(PA)函数得到s={1,5};
Step2:从s中随机抽取一个工序5放入染色体c中;
Step3:使得PA中第5列为inf,第5行为0。此时,PA作业优先关系矩阵如图6所示。

图6 PA作业优先关系矩阵
Step4:i=2,利用Judge(PA)函数得到s={1};
Step5:从s中随机抽取工序1放入c中;
Step6:使得PA中第1列为inf,第1行为0。此时,PA作业优先关系矩阵如图7所示。

图7 PA作业优先关系矩阵
Step7:重复以上步骤直到安排完所有工序。
最终,可以随机得到A产品的一条染色体如图8所示。

图8 A产品的一条随机染色体
3.2 种群初始化
种群初始化就是确定随机产生的染色体数目。种群数目过大会导致算法收敛过早,并且造成算法运行时间变长,效率降低。种群数目过小可能使得算法“早熟”,导致适应度陷入局部最优解。因此,要合理确定种群的数目。笔者设置初始种群pop的大小n为80,具体初始化种群的算法如下所示:
Step1:i=1,利用c=P_chrom(PA)函数生成一条染色体作为pop的第i行;
Step2:i=i+1,当i到达种群的大小n时,算法结束。
3.3 计算适应度与译码
在自适应遗传算法中,可以根据适应度f′来判断染色体的优劣和靠近最优解的程度。因为此处选择了轮盘赌选择法,适应度大的染色体,遗传到下一代的概率大;反之,概率则小。适应度值就像是数学模型中的目标函数,适应度越大的染色体越接近最优解。而在式(9)中,目标函数的最优解是一个最小值,因此需要对目标函数进行转化。该文以f′=50-0.57Wreal+0.33CTreal+0.1L作为适应度函数。
当已知一个种群时,并不能比较染色体之间的优劣。因为种群的染色体中包含的信息只有基因的排列顺序(即工序的顺序),比较种群的优劣需要最小工作站数Wreal、实际生产节拍CTreal和装配线平滑指数L的信息。译码的操作就是根据一条染色体排列的顺序求得Wreal、CTreal、L。
3.4 选择
选择算子是为了保留优质染色体,淘汰劣质染色体。该文选择了轮盘赌法选择法作为选择算子,它模拟博彩游戏的轮盘赌,一个轮盘被划分为n个扇形(n为种群的大小),而每个扇形的面积与它所表示的染色体的适应度成正比;为了选择种群中的个体,设想有一个指针指向轮盘,转动轮盘,当轮盘停止后,指针所指向的染色体被选择。因为一个染色体的适应度越大表示该染色体的扇形面积越大,所以它被选择的可能性也就越大。
具体操作如下:
Step1:计算种群各个染色体的适应度fi;
Step4:在[0,1]区间产生一个随机数r;
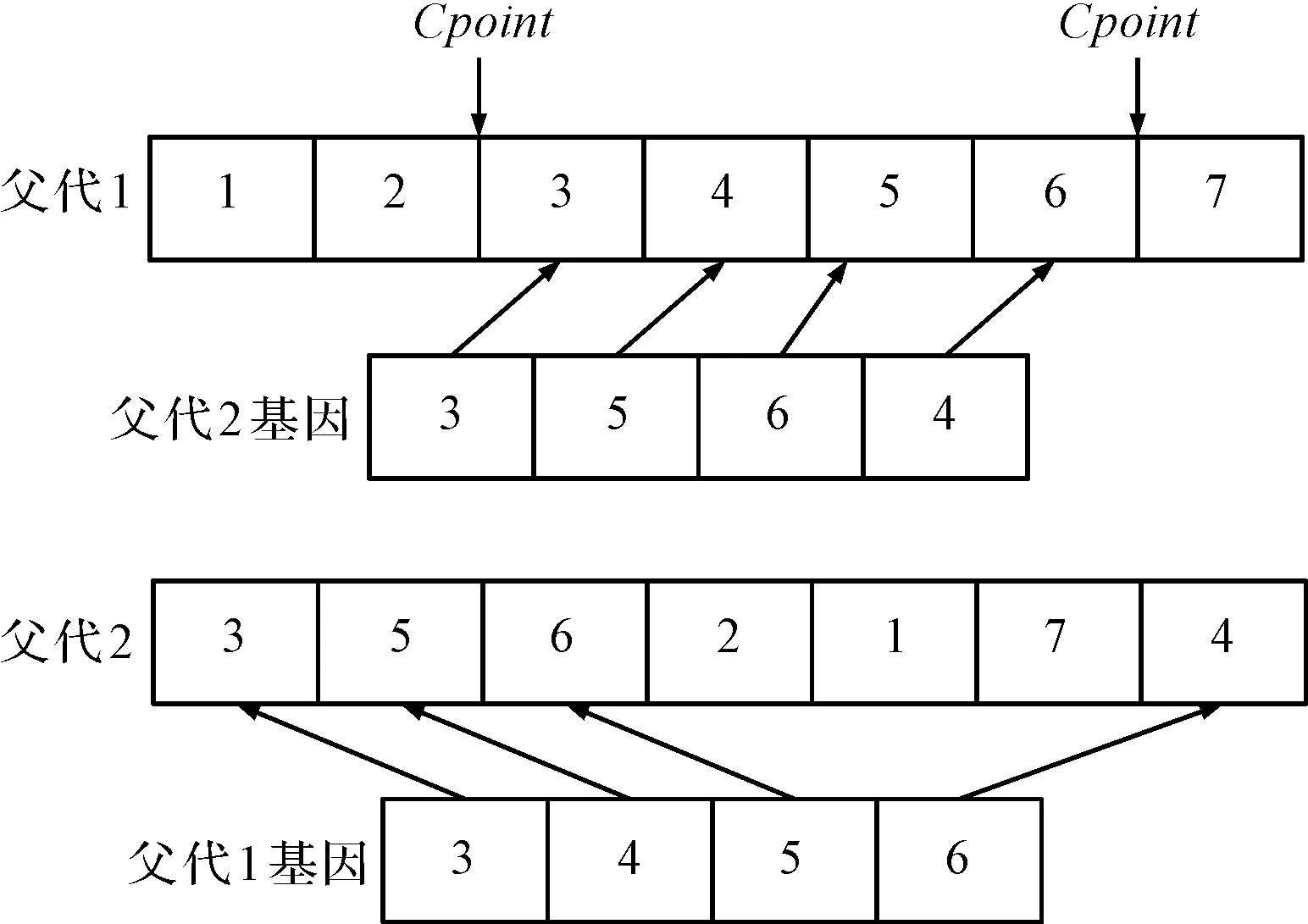
Step5:若r Step6:重复Step4和Step5共n次。 显然,一定数量种群的染色体,一般很难得到最优解。那么,在种群数量固定的情况下,要得到或者是接近最优解,就要使染色体的基因相互交叉,就是使种群多样化的一种算子。此处的交叉操作不同于一般遗传算法中染色体的交叉,随意地交叉会破坏优秀染色体中符合综合作业优先关系的基因。因此,笔者采用了两点交叉的方式。 为了更方便理解,下面用一个例子来说明本文交叉算子的思想,假设父代1和父代2的基因排列顺序均满足某个作业装配工序的优先顺序,如图9所示。 图9 两点交叉算子的示意图 Step1:当rand pc的表达式为: (11) 式中:pcmax—最大交叉概率;pcmin—最小交叉概率;i—当前迭代次数;m—总迭代次数。 Step2:逐个找到变量temp中的成员在Chrom2(即父代2)中的位置,存入变量index中(index的含义是Chrom1交叉的染色体在Chrom2中的索引),即index={1,7,2,3}; Step3:将index从小到大进行排序,得到新的index={1,2,3,7}(新的index即为temp在Chrom2中的排列顺序,有Chrom2(index)={3,5,6,4},即为图9中箭头所指父代2的基因); Step4:在Chrom1中Cpoint1到Cpoint2基因位置存入Chrom2(index)={3,5,6,4},生成子代1。 Step5:在Chrom2中的索引位置即index={1,2,3,7},分别存入temp={3,4,5,6}。生成子代2。 新生成的子代1和子代2不仅丰富了种群的多样性,增加了搜索的范围,还符合综合优先关系图的优先顺序。对于更加复杂染色体的交叉算子,原理与这个例子一致。 为了丰富种群的多样性,增加搜索范围,此处引入变异算子。变异就是使得染色体中的某个基因发生变化,然而平凡的变化会破坏基因应符合的顺序,产生不可行解。为了消除不可行解,笔者采用了考虑综合作业优先关系矩阵的单点变异。 为了方便更好地理解变异算法,下面举例说明,已知某混流装配线的综合作业优先关系图和综合作业优先关系矩阵如图10、图11所示。 图10 综合作业优先关系图 图11 综合作业优先关系矩阵 假设已知一条满足该装配顺序的染色体c={1,2,3,4,5,6},变异思想主要是随机产生一个变异点mpoint;前面的基因序列保持不变,将mpoint处基因及后面的基因序列重新排列。 解决这个例子算法的步骤如下: Step1:当rand 图12 单点变异示意图 pm的表达式为: (12) 式中:pmmax—最大变异概率;pmmin—最小变异概率;i—当前迭代次数;m—总迭代次数。 Step2:当基因1、2保持不变,求出此时的综合作业优先矩阵PA如图13所示。 图13 变异后的综合作业优先关系矩阵 Step3:用3.1中的Judge(PA)函数得到s={3,4}; Step4:随机选择一个基因,这里假设选择基因4放入染色体3号位中; Step5:再保持基因1、2、5不变,求出此时的综合作业优先矩阵PA; Step6:重复上述步骤,最终得到一条变异后的染色体如图14所示。 图14 变异后的染色体 新生成的染色体再次丰富了种群的多样性,也增加了算法的搜索范围,防止算法陷入局部最优解。对于该文更加复杂染色体的变异算子原理与此例一致。 第一次试验将种群大小设定为n=80,迭代次数m={100,200,300,400},最大交叉概率为0.9,最小交叉概率为0.5,最大变异概率为0.01,最小变异概率为0.005,目标在8 h生产A、B、C 3种产品共600件。 MATLAB的执行结果,不同的迭代次数与适应度函数值的关系,如图15所示。 图15 不同的迭代次数与适应度函数值的关系 图15是种群为80时,不同的迭代次数与适应度函数值的关系。 MATLAB的执行结果,即不同的迭代次数对适应度函数值的影响,如图16所示。 图16将图15中的4条曲线放入一张图中,从而更好地观察适应度函数收敛的重合程度。结果发现,当迭代次数达到60左右时,适应度函数值收敛,再增加迭代的次数,适应度函数值无明显的变化。因此,综合考虑到算法的效率和局部最优解的情况,笔者将迭代的次数设定为100。 第二次试验将种群大小设定为n={80,160,240,320},迭代次数m=100,最大交叉概率为0.9,最小交叉概率为0.5,最大变异概率为0.01,最小变异概率为0.005,目标在8 h生产A、B、C 3种产品共600件。 执行的结果,即不同种群下适应度函数值和迭代次数的关系,如图17所示。 图17 不同种群下适应度函数值和迭代次数的关系 当种群为80时,适应度函数值在100次迭代过程中可以完全收敛,而增加种群的数目到160、240、320,与种群为80时的收敛值几乎一致;并且没有搜索到更优解,只是略微增加了适应度函数的收敛速度。考虑到算法的效率和局部最优解,将种群的大小设置为80。 在具体固定了种群的大小和迭代的次数后,就可以进行多次试验来求得最优解。 笔者进行了30次试验,选取4次在MATLAB中的实验结果,适应度函数值和迭代次数的关系曲线如图18所示。 图18 适应度函数值和迭代次数的关系曲线 从图18可以看出,虽然初始种群的适应度函数值不一样,但在迭代的过程中不断地选择、交叉、变异后,适应度函数值都收敛于31与31.5之间的某个数。 笔者进行了30次试验,选取4次在MATLAB中的实验结果,目标函数值和迭代次数的关系图如图19所示。 图19 目标函数值和迭代次数的关系图 在图19中可以发现与图14之间存在着联系,因为在3.3节中设计适应度函数值时,将目标函数值进行了转化,即f′=50-f,所以适应度函数和目标函数关于y=25对称。可以发现在迭代过程中,目标函数值收敛于18.5和19之间的某个数。 利用MATLAB中绘制传统遗传算法得到的工序分配方式,如图20所示。 图20 优化前各工序在8个工作站的分配柱状图 自适应遗传算法在30组实验中求得优化后的工序分配方式,如图21所示。 图21 优化后各工序在7个工作站的分配柱状图 最优解显示最小工作站数Wreal为7,实际生产节拍CTreal为44.33,装配线平滑指数为2.47,目标函数值f为18.87,适应度函数值f′为31.13,在规定有效工作时间内可以生产出649件产品,超出目标产量49件。 分别用传统遗传算法与自适应遗传算法来解决混流装配线平衡问题,得到优化前后的参数对比如表3所示。 表3 优化前后混流装配线的参数对比 由表3可知: (1)减少了1个工作站,降低了工人与设备的费用; (2)平滑指数降低了59.36%,使得各个工作站之间的装配时间波动更小,装配作业的负荷更加均衡; (3)实际生产节拍增加了2.66秒/件,使产量减少42件; (4)在完成目标产量600件的基础上还降低了库存量46.15%,降低了库存成本。 针对汽车电子液压制动控制单元的混流装配线平衡问题,笔者建立了装配线的多目标数学模型,利用MATLAB编写了改进后的自适应遗传算法,并对此进行了求解,通过调整参数设置得到了其最优解,最后将其与传统的遗传算法进行了对比分析。 研究结果表明: (1)利用自适应遗传算法对汽车电子液压制动控制单元的混流装配线平衡进行优化,其效果优于传统遗传算法; (2)优化后,减少了1个工作站,平滑指数降低了59.36%,生产节拍增加了2.66秒/件,完成目标产量并降低库存,大大降低了混流装配线工人与设备的成本,提升了混流装配线的平衡率。 在后续的研究过程中,笔者将利用NSGA-II算法来解决多目标决策的问题,使得各个目标函数都尽可能能找到最优的解集,并将其应用于汽车电子液压制动控制单元的混流装配线平衡。3.5 交叉
3.6 变异

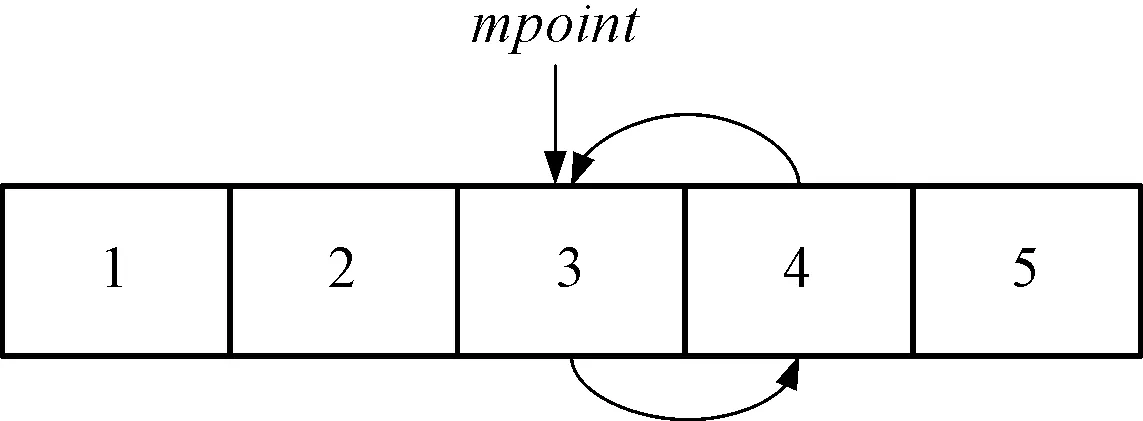

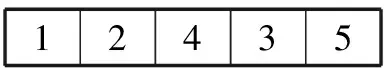
4 自适应遗传算法运行结果分析
4.1 参数设置
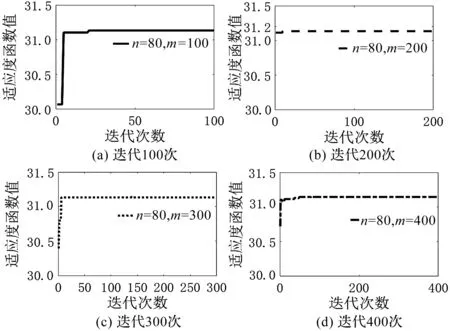
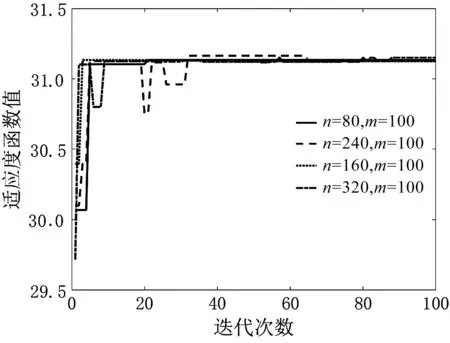
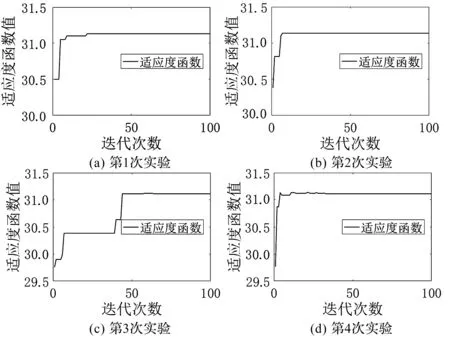
4.2 运行结果分析与对比
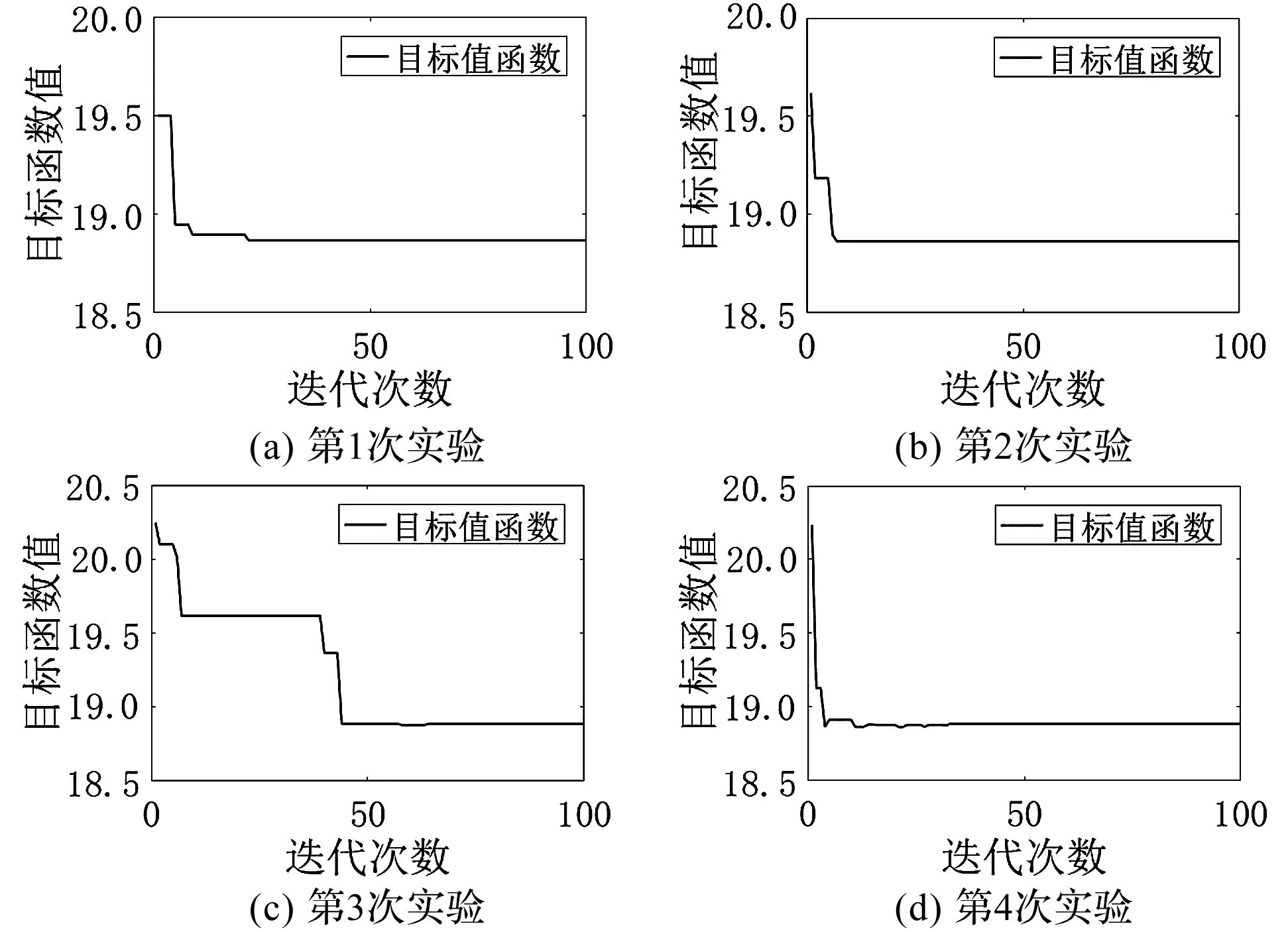


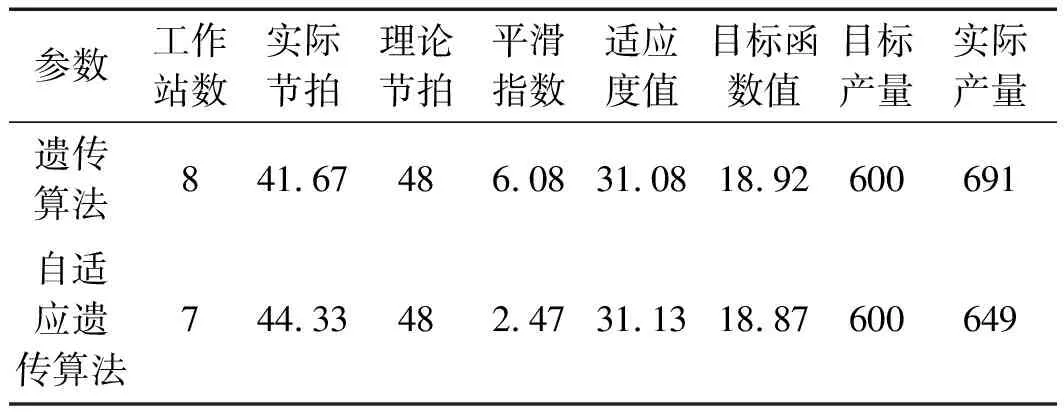
5 结束语
