结合SE与BiSRU的Unet的音乐源分离方法
2022-01-27张瑞峰白金桐关欣李锵
张瑞峰 白金桐 关欣 李锵
(天津大学 微电子学院,天津 300072)
音乐源分离是音频信号处理中的核心研究领域之一,它的主要目标是在提取一个或多个目标源的同时抑制其他音源和噪声。比如在音乐源分离的SiSec Mus评估活动[1]中,就将原始混合音乐音频分离为鼓、低音音轨、人声和其他音轨。音乐源分离是特殊的源分离问题,由于音乐自身结构的复杂性而更具挑战,但在实际应用中又十分重要。利用分离后的音频可以更好地完成音乐信息检索(MIR)的许多任务,例如音乐-歌词对齐、歌词转录、音乐转录(和弦转录、鼓转录、节拍跟踪)、人声旋律提取以及歌手识别、情感流派多标签分类等问题。
音乐源分离的方法大致可分为两大类:基于声源假设的方法和数据驱动方法[2]。基于声源假设的方法是假设主音或其他伴奏各声源具有各自的特性,然后根据这些假设设计算法进行分离。比如在人声与伴奏分离问题中,用谐波结构为人声建模[3],并且将伴奏视为多余的部分,寻找可用于音源分离的重复信息[4- 5]。但是基于假设模型的分离方法有一个主要的问题,即它们的核心假设可能不完全适用于所研究的信号。例如,待分离的主声源可能不具有谐波结构,或者人声或伴奏可能不具有重复结构,而总是在变化的,以及可能不能将伴奏部分看作多余的等。在这种情况下,基于声源假设的方法容易出现较大偏差,分离性能不佳。数据驱动方法的模型不依赖假设,而是让模型从大量有代表性的示例数据中学习。例如,Ozerov等[6]提出了一种贝叶斯模型。首先利用高斯混合模型(GMMs)和梅尔频率倒谱系数(MFCC)将一首混合音乐音频分成人声和非人声部分,然后利用最大后验概率方法[7],在音乐的非人声部分上改进了一个通用的音乐模型。由于模型改进自非人声部分,所以该模型对音乐中人声与非人声的比例、音乐相似性有一定要求。Boulanger等[8]提出将递归神经网络(RNN)正则化引入非负矩阵分解(NMF)框架,在分解过程中对激活矩阵进行时间约束。此种方法直接对整首音乐建模,不需对音源进行限制,但是其没有对NMF和RNN模型进行联合优化。传统数据驱动的机器学习方法模型复杂度有限,从而限制了模型的学习能力和表示能力。
近些年,随着海量数据的积累和计算机算力的提升,出现了更多深层的学习网络。一些深度神经网络架构已经超越了传统浅层方法,获得了目前为止最优的性能。这些深度学习方法按所处理音频数据的形式分为频域和时域方法。
从音频频域数据出发的频域方法一般采用编码器、分离网络和解码器框架。编码器处理的是由短时傅里叶变换(STFT)生成的频谱图,在每个帧和每个源的幅度谱上生成一个掩码,后续解码器部分通过对掩码频谱图进行短时傅里叶逆变换,重新混合输入相位来生成输出音频。其中的分离网络可以是各种各样的网络。Jansson等[9]将广泛应用于医学图像处理的Unet[10]结构引入音乐源分离中。Takahashi等[11]提出MMDenseLSTM,将Dense-net[12]与处理时间序列的长短期记忆网络(LSTM)[13]结合,目前在SiSec活动中取得了最好的性能。值得一提的是,除了网络结构的优化外,Nugraha等[14]的研究工作表明,维纳滤波是基于频谱图模型的有效后处理步骤。目前频域方法中所有分离效果较好的模型均采用了维纳滤波进行后处理。但是频域方法存在以下缺点:①模型训练仅利用了幅度谱,没有充分利用音频的相位信息;②分离性能无法超过所采用的理想掩膜,因此存在性能上限;③可能存在比STFT更好的特征表示方法,比如MFCC等其他基于心理声学的特征表示方法。针对频域方法的上述问题,出现了时域类方法。
从时域波形出发的时域方法有两种思路。一种是通过数据学习特征表示的基函数,替代STFT中固定的余弦基函数,并且和分离网络一起联合优化。Conv_Tasnet[15]是遵循这个思路的一种语音分离模型,它通过学习,替代STFT变换及其逆变换,从而能够更好地表达原始音频数据。Défossez等[16]将其进行了适合处理音乐源分离问题的改进,取得了此类时域方法的最优性能。另一种时域方法的思路则是直接学习混合音频和分离音频之间的映射关系,不进行显式的特征变换,是一种从混合时域波形到分离时域波形的端到端模型,此类方法聚焦于模型网络设计,目前还处于探索起步阶段。由Stoller等[17]提出的Wave-U-Net是时域方法中最具代表性的一种,它改进自Unet,采用深层端到端模型,但其信号失真比(SDR)[18]指标仅为3.23 dB。Perez等[19]借鉴了图像分类中采用的最小超球面能量(MHE)损失函数,通过多样化滤波器形式提升了分类性能,将其引入Wave-U-Net后,SDR指标进一步提升为3.56 dB。由Défossez等[16]提出的Demucs采用一种广义的编码器-解码器体系结构,它由广义卷积编码器、双向LSTM和广义卷积解码器组成,编码器和解码器通过Unet的跳过连接链接,在MUSDB18数据集上SDR取得了平均5.58 dB的分离性能,为先前端对端模型中性能最优的方法。虽然较深的网络和较多的通道数带来了性能的提升,但却使模型巨大而难以收敛。
为了寻求更适合音乐源分离的时域端对端网络结构,在Demucs基础框架上,文中的方法主要在以下3个方面进行改进:①改进挤压-激励块(SE)[20],使其适用于一维音频信号,并将其引入广义编码层与解码层,该模块所提供的注意力机制可以根据待分离音频的类型有选择地提取特征;②在一维卷积后增加组归一化(GN)[21]层,对输入分布进行归一化处理,以应对可能存在的梯度爆炸和梯度消失问题,从而稳定学习过程;③将双向LSTM改进为双向简单循环单元(BiSRU)[22],进一步提高训练速度,降低模型参数量。
1 Unet-SE-BiSRU音乐源分离方法
文中提出的Unet-SE-BiSRU方法,其原理框图如图1所示,它呈类似Unet的网络结构,模型输入端为原始音乐混合音频,其波形幅值y为经过广义编码层、循环网络层和广义解码层,输出端为J个双声道音源。在Demucs基础框架上,文中的模型在广义编码层和解码层中增加了组归一化和挤压-激励模块。桥连接部分采用了双向简单循环单元结构。
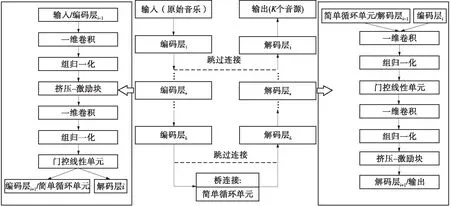
图1 Unet-SE-BiSRU原理框图
(1)

对于该网络结构,经过对比实验,训练时的目标函数采用了L1范数:
(2)
以衡量多个音源与原始音乐音频在时域波形幅度上的差异。
1.1 桥连接的改进
考虑到音乐本身具有时间序列的特性,在桥连接中采用RNN。但RNN对于音乐源分离中这种较长的时间序列,在模型训练时经常出现梯度消失的问题。针对这种问题,目前RNN大多采用具有“门机制”的LSTM或GRU[23]等网络结构。
而对于LSTM或GRU等网络结构来说,又存在难以并行化的问题。以LSTM为例,其网络结构如图2(a)所示,其遗忘门Ft、输入门It以及单元状态Ct不仅依赖当前时刻的输入,还需要前一时刻隐藏单元的输出Ht-1,这就只能串行处理,从而阻碍了运算的并行性。
为此,Unet-SE-BiSRU方法中采用了双向SRU[22],其单元结构如图2(b)所示。其中,当前时刻t输入为Zt,当前时刻输出隐藏层状态Ht、输出单元状态Ct如式(3)和(4)所示:

(a)LSTM单元结构示意图
Ht=Rt⊙g(Ct)+(1-Rt)⊙ct
(3)
Ct=Ft⊙Ct-1+(1-Ft)⊙ct
(4)
式中,⊙为矩阵对应元素之间的点乘运算,g为tanh激活函数,遗忘门Ft、复位门Rt、中间输出状态ct的定义如式(5)至式(7)所示:
Ft=σ(WFZt+bF)
(5)
Rt=σ(WRZt+bR)
(6)
ct=WZt
(7)
式中,σ表示Sigmoid激活函数,WF、WR、W分别为待学习的遗忘门、复位门、输入到中间输出状态变换的参数矩阵,bF和bR为对应偏置。
在传统的RNN比如LSTM中,每个门状态(图2(a)中的遗忘门Ft、输入门It、输出门Ot)的计算都依赖于上一时刻隐藏层的输出(图2(a)中的Ht-1)和当前时刻的输入Zt。而SRU依据式(5) 和(6)仅依靠当前时刻的输入Zt,解除了连续时刻状态间的强制约性,从而使得门状态的计算只依赖于当前时刻的输入信息,因此SRU能够极大提高并行化程度,从而提高了模型的训练速度。而Ct和Ht的时间上依赖性正是RNN这类网络的特点,SRU虽然无法解除其连续时刻状态间的强制约性,但这些计算仅为矩阵对应元素之间的相乘,而非计算门状态时的矩阵相乘,因而计算速度较快。
对于给定输入序列{z1z2…zl},在所有时间步中批量分配矩阵乘法,可以显著提高计算效率(比如GPU使用率),批处理乘法如式(8)所示:
(8)
其中,l为序列长度,VT∈Rl×3h,h为隐藏层参数。
1.2 广义编码层与解码层的改进
在传统的卷积、池化过程中,默认特征图的每个通道都是同样重要的,即给予同样的权重,但在音乐源分离问题中,不同的通道往往具有不同的重要程度。为了进一步提升模型性能,Unet-SE-BiSRU在卷积运算后加入了SE块,SE的注意力机制使模型能自适应地赋予不同通道不同的权重,从而进一步提升模型的表示能力。由于SE块最初应用于二维图像,为了适用于一维的音频信号,在Unet-SE-BiSRU中对其进行了改进。除SE外,较流行的注意力机制还有SK[24]块,它使用不同大小的多个卷积核执行卷积操作,并给予不同权重,但文中实验表明SE块更适用于此网络模型。另外,Unet-SE-BiSRU为了进一步加速模型的收敛,在模型中加入了GN层作归一化处理。
1.2.1 适用于一维音频信号的挤压-激励块
由Hu等[20]提出的SE关注核函数之间的关系,自动学习不同核函数所提取特征的重要程度,通过显式建模网络卷积特征通道之间的相互依赖关系来提高网络的表示能力。
为适用于一维音频信号,改进后的SE仍由挤压和激励部分构成,其中挤压部分收集数据的全局信息,而激励部分进行自适应重新校准,给予不同通道以不同的权重。其基本结构如图3所示,蓝色虚线部分为基本的一维卷积操作,输入P∈RL′×Q′,其中Q′为通道数,L′为音频帧数。经过一维卷积Ftr后,得到特征U。之后进行压缩Fsq传递特征U,即图3中的红色虚线部分。通过时间维度将特征U压缩成通道描述符T∈Rq,该描述符包含通道维度特征的全局信息,供较低层利用。其中T的第q个元素为
(9)
接下来是自适应重新校准,为图3绿色虚线部分。它实现了网络特征的重新校准。通过该机制,网络可以利用全局信息有选择地增强有效特征,并抑制不太有用的特征。最终通过显式建模卷积特征通道之间的相互依赖关系提高网络的表示能力,具体的计算公式为

图3 改进后的SE原理框图
S=Fex(T,X)=φ(X2φ(X1T))
(10)

该块的最终输出通过对特征U进行重新缩放,为图3中的黑色虚线部分:
(11)

SE块通过对一维卷积的通道重新校准所提升的性能可以在整个网络中累积,而且SE块在计算上是轻量级的,只会增加很小的模型复杂性和计算负担。
1.2.2 改进的归一化层
这一层对数据进行归一化处理。在传统的深度网络中,过高的学习率可能会导致梯度爆炸或消失,归一化有助于解决这一问题。
通过对整个网络的激活值进行归一化,可以防止训练陷入非线性饱和状态。目前,大多采用批归一化(BN)方式[26]。BN通过减少内部协变量偏移来提升训练速度,由于其沿批处理轴归一化,需要足够大的批处理尺寸,所以占用大量内存。若减小BN的批处理尺寸,会导致批处理统计信息不全面,从而大大增加模型误差,所以,许多模型采用非常大的批量尺寸,进而限制了模型的复杂度。
文中采用组归一化GN[21]作为BN的改进方案,其不同之处如图4所示。GN将通道划分为组,然后归一化每个组内特征,不利用批次维度的数据,并且其计算与批尺寸无关。

(a)BN
首先,与其他归一化方法相同,GN也要进行式(12)所示的计算:
(12)
式中,η为输入数据均值,μ为标准差,w=(wN,wY,wE)是按(N,Y,E)顺序索引特征的3D矢量,其计算公式分别为
(13)
(14)
式中,ε为一个小常数,Dw为根据音频帧计算的平均值和标准差集合,m为该集合的大小,如式(15)所示,这也是GN和其他特征标准化的主要不同之处。
(15)

类似于其他归一化方法,GN也学习了每组通道的线性变换以补偿可能的性能损失,最终输出如式(16)所示:
(16)
式中,γ和β为可学习的缩放系数和偏移量。
2 实验结果与分析
2.1 数据集及评估指标
实验所用数据为开源数据集MUSDB18,其中包括150首音乐,100首为训练集、50首为测试集。每首音乐都由混合音频及其对应的人声、鼓声、贝斯和其他组成。所有音乐音频数据均为双声道,采样率为44.1 kHz。
为提升分离网络的泛化能力,实验中对原始数据集进行了如下扩充[27- 28]:①为每个音源随机交换左右声道;②对音源的振幅进行随机缩放;③将每个音源随机分块,构成序列,然后随机混合来自不同曲目的音源;④每个音源波形乘以±1。
这些数据扩充方法也被当前大多数音乐源分离方法,如MMDenseLSTM[11]、Demucs[16]、Open-Unmix[29]等采用,扩充后的数据可达约1 200首音乐。

(17)
式中,starget、einterf、enoise、eartif分别代表可能存在失真的音源、干扰项、噪声项和伪影误差项。
SDR则定义为
(18)
该指标数值越高说明分离效果越好,实验部分计算结果为MUSD18数据集中50首测试数据SDR指标的中位数。类似地,文献[18]还定义了SIR、SAR音乐源分离指标。
(19)
(20)
2.2 实验设置
本文分离网络性能实验的环境如下:Ubuntu16.04操作系统;3张12G GeForce RTX 2080ti显卡;PyTorch深度学习框架。其中,批尺寸均设置为12,各层网络参数设置如表1所示。

表1 Unet-SE-BiSRU网络参数
2.3 对比实验
在实验初期对比了3种损失函数,分别基于1范数L1、2范数L2和平滑后的1范数Smooth L1,其实验结果如表2所示,最终在Unet-SE-BiSRU网络中选取了分离性能最好的基于L1范数的损失函数作为优化目标。

表2 不同损失函数网络模型性能对比Table 2 Model performance comparison with different loss funtions
2.3.1 注意力机制SE块的有效性
SE特征加权的有效性可以通过观察每个编码层中SE激活值的分布情况进行验证。以测试集中的两首音乐为例,第1、5个编码层上SE的激活值分别如图5所示。

(a)第1个编码层
从图5(a)可见,第1个编码层中SE的激活值分布几乎集中在0.4~0.6之间,而且两首测试音乐的激活值在各个通道具有高度相似的分布,这说明对于音乐源分离问题而言,网络浅层可能提取的是音频信号所共有的特征。随着网络加深,网络提取的特征开始侧重于表示不同音源的差异性。从图5(b)可以看出,随着网络的加深,SE的激活值分布逐渐分化,SE的作用逐渐变得明显。
为了比对两首音乐在第5个编码层上激活值的不同,各通道激活值相减的结果如图6所示,SE对不同曲目进行自适应重新校准,可以通过不同的激活值选择性地增强有效特征的权重,同时抑制不太有用的特征通道,进而提高网络的表示能力。

图6 两首音乐在第5个编码层上SE中的激活值之差Fig.6 Difference of activation values of two music in SE on the fifth coding layer
网络特征表示能力的提升促进了分离效果的改善,如图7所示,在加入SE后,SDR指标在训练时的各轮次均高于未加入SE的Unet-BiSRU网络。

图7 Unet-BiSRU、Unet-SE-BiSRU的SDR指标
2.3.2 不同典型注意力机制模块的对比
实验中比较了SE和SK两种注意力机制的分离性能和训练耗时,实验结果如表3所示,在相同实验条件下,Unet-SE-BiSRU和Unet-SK-BiSRU支持的最大批尺寸分别为12和6,其SDR分别为5.68 dB和5.21 dB。实验表明,在同样的显存大小限制下,SE相对于SK更适用于文中网络模型。其原因为:首先,虽然采用SK的模型所增加的参数量与SE基本持平,但是SK额外的卷积计算会产生大量的中间变量,并且随着网络深度增加,通道数也随之增加,最终导致模型占用过多的显存;其次,SK采用的是批归一化,批尺寸最大只能为6,过小会导致其性能下降。

表3 采用不同注意力块的模型性能对比Table 3 Performance comparison of models with different attention blocks
为了探索SE和SK在相同批尺寸大小下的表现,将SK的BN修改为GN,实验结果如表3所示。实验表明,在相同较低批尺寸为6的情况下,Unet-SK-BiSRU(GN)的性能比Unet-SE-BiSRU有微小的提升,但仍远低于相同显存大小限制下,批尺寸可为12的Unet-SE-BiSRU。
2.3.3 桥连接部分采用BiLSTM与BiSRU的性能对比
为了选取循环网络,对比了BiLSTM、BiSRU两种方案,其训练和测试时各轮次损失值如图8所示。从图中可以看出BiLSTM的收敛速度略优于BiSRU,但BiSRU验证损失略优于BiLSTM。由于SRU网络结构能够在GPU上并行处理,所以BiSRU的训练速度优于BiLSTM,BiLSTM每轮次训练需要18 min,而BiSRU仅需要12 min。而且BiSRU参数量(3.328×104)仅为BiLSTM参数量(6.656×104)的一半。两种网络的SDR分别为5.68、5.55 dB。选取BiSRU改善了网络的时间复杂度、分离性能,具有扩大通道容量的可能,为进一步提升分离性能提供了空间。

图8 采用不同循环网络时各轮次损失值
2.3.4 采用不同归一化方式时的性能对比
当未加入归一化层时,模型难以收敛,甚至损失值不但不下降,反而出现了上升的现象,如图9所示。对比BN与GN,采用BN模型的训练损失一直高于采用GN的模型。对比两种方法最终得到的SDR指标,GN(5.68 dB)可比BN(5.34 dB)

图9 采用不同归一化策略的各轮次损失值
提高0.34 dB。本实验中,批尺寸为12,并且使用3张显卡,所以实际每张显卡所处理的批尺寸仅为4,如1.2.2节所言,当批尺寸较小时仍采用BN策略会降低网络性能。而GN不受批尺寸的影响,所以当批尺寸仅为4时,仍能得到不错的网络性能。
2.4 Unet-SE-BiSRU各创新点对分离性能提升的贡献情况
Unet-SE-BiSRU模型中进行了通道加权SE、桥连接SRU和组归一化GN 3处改进,综合3处改进的实验结果如表4所示。这3处改进中,通道加权SE对分离性能SDR的影响最大,组归一化GN的影响次之,桥连接SRU相对最小。这点从表中可以看出,Unet-SE-BiSRU去掉通道加权SE模块后,虽然能节省少量训练时间,分离性能指标SDR却会下降0.43 dB,与之相较,组归一化GN的影响为0.34 dB,而桥连接SRU替换为LSTM或GRU性能分别下降0.13 dB和0.31 dB。从表中还可以看出,3处改进中,桥连接SRU能大幅缩短训练时间,同时在一定程度上提升分离性能。

表4 不同结构网络模型性能对比Table 4 Model performance comparison of different structures
综上所述,通道加权SE、组归一化GN在不增加时间复杂度的同时,显著提升了网络的分离性能,而桥连接SRU大幅降低了网络的时间复杂度。
2.5 Unet-SE-BiSRU与基准模型Demucs的性能比较
在进行Unet-SE-BiSRU与Demucs对比实验时,取通道数分别为16、32、64,由于显卡内存限制,未能给出通道数为96时Unet-SE-BiSRU模型的性能指标,对比实验结果如表5所示。从表中可以看出,随着通道数的增长,Demucs与Unet-SE-BiSRU的模型性能都得到了显著的提升。值得注意的是:在通道数为64时,Unet-SE-BiSRU就已经超越了Demucs在通道数100时的性能。从通道个数增加时各性能参数的变化趋势看,当Unet-SE-BiSRU通道数提升到96时,有可能获得更好的性能。另外,在通道数相同时,Unet-SE-BiSRU的训练速度明显快于Demucs。源64通道Demucs模型训练总时长为4 800 min(20 min×240),Unet-SE-BiSRU训练总时长为1 920 min(12 min×160),约为源模型的2/5。

表5 不同通道数时Unet-SE-BiSRU与Demucs的性能对比Table 5 Performance comparison between Unet-SE-BiSRU and Demucs with different channel numbers
组归一化虽然不受批尺寸限制,但却受通道个数限制。而模型采用的GN归一化的组数是32,即2个通道认为是同一组,所以通道数为16时,修改了模型,将GN归一化组数减小为16。同通道数为32一样,当组数与通道数刚好相等时,GN处于一种特殊情况,即实例归一化(IN)。如图10所示,它只能依靠空间维度来计算均值和方差,并且错过了利用信道依赖的机会,这是在16、32通道数时,Unet-SE-BiSRU性能不如Demucs的可能原因。

图10 实例归一化示意图
此外,在实际应用场景时,前向推断时间较模型训练时间更重要,本文将64通道下的Demucs和Unet-SE-BiSRU的实际测试时间进行对比。实验使用Ubuntu16.04操作系统以及1张12 G GeForce RTX 2080ti显卡,测试数据为MUSDB18数据集中的所有歌曲(50首wav格式、采样率为44.1 kHz的音频文件),总时长约195.7 min,Demucs和Unet-SE-BiSRU所需分离时间分别为46.4和37 min,即分离1 min的音频分别需14.2和11 s,故Unet-SE-BiSRU在实际应用时的分离速度也较Demucs有较大提升。
2.6 Unet-SE-BiSRU与典型模型的性能比较
在MUSDB18数据集上,对当前最具代表性的模型针对各具体音源的最好分离性能进行了比较,SDR结果如表6所示,可见Unet-SE-BiSRU具有目前较好的综合分离性能。具体到音源,Unet-SE-BiSRU网络在鼓声和低音部分的分离效果与其他类最优方法相当,甚至有更高的SDR指标,但在人声部分和其他音轨的分离效果上并非最优。值得一提的是,还有一个MMDenseLSTM模型使用了8倍于MUSDB18的训练集,也就是804首额外的训练数据后,其SDR指标能够达到6.04 dB。从分离性能角度考虑,这在一定程度上显示了训练数据量的重要性。

表6 在MUSDB18数据集下不同模型的性能对比Table 6 Performance comparison of different models under the MSUSDB18 dataset
3 结论
文中提出了一种用于音乐源分离的Unet-SE-BiSRU端对端网络模型。实验结果显示,Unet-SE-BiSRU网络在目前检索到的文献的音乐源分离时域端到端模型中的SDR最高,接近于频域方法和时域非端对端方法的最好性能。在相同实验条件下,Unet-SE-BiSRU网络的SDR指标比基准Demucs模型提高了0.34 dB,训练总时长仅约为基准模型的2/5。对于网络中增加的SE、BiSRU、GN 3个模块的对比试验,验证了各模块对于提升模型性能均有显著贡献。通过对实验结果的分析,可以得出如下结论和进一步深入研究的着眼点:①时域端到端网络的表示能力仍有很大的提升空间,更好地提取音频特征有利于获得更好的源分离效果;②增加通道数有利于提取输入音频中更多的有效信息,从而能够进一步提升模型的分离性能;③更多的音频数据可以使模型更好地学习、逼近音频数据真实的特征分布情况,从而提升模型的泛化性;④Unet-SE-BiSRU网络模型在对人声的表征方面还有待进一步的深入研究。
