基于非线性协整理论的灌区水资源供需时序研究
2022-01-26邓海军
邓海军
(江西省潦河工程管理局,江西 宜春 330700)
我国有较多的大型灌区,在确保我国粮食安全方面,灌区生产的粮食具有非常重要的作为。在农业用水总量中,很大一部分都用于灌区灌溉[1]。近些年,气候、人类活动等多种因素对灌区的农业发展产生了较大影响,导致灌溉水量无法较为准确地预测,造成灌区水资源浪费,对灌区的灌溉用水安全产生了极大威胁[2-3]。
灌区水资源供需时序的匹配程度直接影响灌区水资源和用水的安全性。为了能更加有效地管理和控制灌区水资源短缺风险,提高灌区用水的安全性,需要有效识别灌区水资源供需时序的相关性,对灌区水资源的系统风险进行有效评估。水资源供需时序受多种因素影响,如人类活动、气候变化、下垫面条件等,采用常规方法难以对水资源供需时序间的相关性进行准确确定[4-6]。
同其他时间序列一样,灌区水资源供需时序也具有多时间尺度特征[5]。在分析水资源供需时序相关性的过程中,为了保证分析结果更加准确,并接近实际,采用基于多时间尺度分解的水资源供需时序关系可以达到较好的效果,可以更加精细地认识和了解序列的内在特征和发展趋势,目前,基于多时间尺度分解的水资源供需时序分析得到了越来越多学者的关注[7-8]。
在灌区水资源供需时序系统中,水资源供需时序的各个要素在较长时期内表现出均衡关系,在短期内这种关系并不明显,采用传统的回归计算方法描述这种均衡关系时,存在“伪回归”问题,在拟合度与t统计量方面,这个模型可以达到较好的效果,但是其DW检验值一般不会达到较高的水平。针对水文水资源领域中存在的这种问题,学者们提出将协整理论引入进来进行研究。协整理论就是为了解决非平稳序列“伪回归”现象,这种理论考虑了序列的不平稳性,在经济学领域有着广泛应用[9]。在水文与水资源领域中,很多数据具有不平稳性,而协整理论可以较好的解决水资源供需时序的不平稳性[10]。
本文选择某灌区作为研究对象,以非线性协整理论作为研究灌区水资源供需时序和相关变量之间关系的方法,构建灌区降雨量、灌溉水量和作物需水量三个变量间的非线性协整关系,深入分析灌区水资源供需时序的不确定性关系,对灌区的灌溉水量进行科学预测,以期灌区水资源调配能力和灌区的用水安全水平得以提高。
1 非线性协整理论
如果一组时间序列具有长期的均衡关系,且该组序列满足同阶单整特点的要求,则可以采用线性协整理论进行研究,如果一组时间序列不满足线性协整关系的判定条件,则序列的协整关系很难采用线性组合方法予以消除,为此就需要采用非线性理论处理序列。在非线性协整关系的研究中,张喜彬等在非线性协整的研究中引入了神经网络理论,建立了非线性协整关系模型,并进行了验证[11-12]。
设Xt=(x1t,x2t,…,xnt)T表示一个n维时间序列,{Xt}的分量就是非线性协整,若:
(1)xit为一个长记忆序列,i=1,2,…,n;
(2)存在一个非线性协整函数f(·),可以使yt=f(x1t,x2t,…,xnt)为一个短记忆过程。
如果f(·)函数满足线性关系,即:
(1)
式中,α=(α1,α2,…,αn)T为RT中的向量,且{Xt}中分量序列的长期记忆性为单整性,则可以用线性协整关系表示非线性协整关系。所以非线性协整可以认为是线性协整概念的一个应用。
综合不同学者的研究理论,引入小波神经网络,以此构建非线性误差校正模型,具体过程如下。
(1)证明数据具有非线性协整关系。建模数据序列分为两个集合,第一个是训练集,第二个是预测集。分析训练集数据的分形维数,如果分形维数互不相等,则证明训练集数据存在非线性协整关系。采用赫斯特指数和分数维经验公式可以计算数据的分形维数。
(2)非线性协整函数f(·)的确定。采用小波神经网络建立非线性协整关系,为了使小波神经网络模型的收敛精度满足要求,优化模型时,采用修改隐含层数、动量因子、学习速率的方法实现。
(3)输出序列的检验。采用非线性协整模型检验小波神经网络的输出序列。当赫斯特指数小于0.5时,则训练集序列具有非线性协整关系。
(4)确定非线性误差校正方程。采用差分方法处理非线性协整函数f(·)和训练集序列,将处理结果的数据代入非线性误差校正方程。
(5)预测分析。采用差分方法处理预测集序列,将处理结果的数据代入第(4)步的非线性误差校正方程,得到预测结果,对预测结果的精度进行分析。
2 灌区水资源供需时序及预测分析
在灌区水资源供需时序分析中,灌区作物需水量受多种因素影响,需要了解和掌握灌区灌溉水量、降雨量、作物腾发量三个影响因素之间的关系。研究中,选择的自变量为灌区降雨量P、作物需水量ETc,因变量为灌区灌溉水量IR,分别建立BP神经网络模型、非线性协整模型进行分析,对比BP神经网络和非线性协整模型两者的预测精度。对灌区水资源要素的供需非线性协整关系进行研究。
2.1 三变量的多时间尺度BP神经网络分析
建立BP神经网络模型对3个变量进行分析,训练集为1975—2008年的数据,预测集为2009—2018年的数据,目标精度设定为0.01,输入层和输出层节点数量分别为12和1。通过训练发现,训练集均方误差达到最小时对应的学习速率为0.85,隐含层节点数为10,最大迭代次数为1800,且满足迭代收敛的要求。如图1所示,给出了训练过程曲线。

图1 BP神经网络训练过程曲线
从图1中可以看出,当迭代次数为1175次左右时,均方误差趋于稳定,收敛值为0.104,和0.01有一定的差异,但是模型的整体效果较好。模型训练完成后,利用预测集数据预测降雨量,得到降雨量预测值和实际降雨量值以及两者的误差见表1。

表1 灌溉水量BP神经网络模型预测值和预测误差
从表1中可以发现,2011年,三变量的BP神经网络模型预测误差为43.54%,达到最大值,2017年的预测误差为7.55%,达到最小值,平均预测误差为21.85%,2010、2011、2012、2014、2018年的预测误差均大于20%,整体误差较大。
2.2 三变量的原始序列非线性协整分析
在三变量的原始序列非线性协整分析中,自变量为作物需水量ETc和降雨量P的原始序列,因变量为灌溉水量的原始序列,3个原始序列的赫斯特指数计算结果见表2。

表2 三个变量的原始序列赫斯特指数
从表 2中可以得出,变量P和ETc原始序列的赫斯特指数近似相等,说明两个序列在短记忆性方面具有相似性,主要因为根据气象要素可以获得ETc,而P通过直接观测得到,所以相似性较高。
原始序列的分形维数采用式(2)计算,计算得到的分形维数如所示。
D=2-H
(2)
式中,D—分形维数;H—赫斯特指数。
从表3中可以得出,降雨量和作物需水量的分形维数近似相等,但不完全相等,说明两者之间存在非线性协整关系。

表3 三个变量的原始序列分形维数
采用Eviews软件对三个变量的滞后阶数进行计算,结果等于2。在非线性误差校正方程中,输入训练集的参数值和34组数据的差分值,采用Eviews软件计算非线性协整方程的系数,该方程如下:
IRt=28.5·ETct-1-20.02·Pt-1-
1.58·YNN+25.379
(3)
式中,P—降雨量的一阶差分;ETc—作物需水量的一阶差分;YNN—三个变量的非线性函数;t-1—第t-1位置。
对该灌区2009—2018年10年的作物需水量、降雨量、灌溉水量原始序列数据进行一阶差分,将这些数据代入非线性误差校正方程中,得到灌溉水量非线性协整模型预测误差结果,见表4。

表4 灌溉水量非线性协整模型预测值和预测误差
从表4可以发现,2012年灌溉水量的非线性协整预测误差为32.5%,达到最大值,2011年灌溉水量的非线性协整预测误差为7.26%,达到最小值。计算得到10年的平均预测误差19.51%。2010、2012、2015、2017年的预测误差均大于20%,整体误差较大。
2.3 三变量的多时间尺度非线性协整预测分析
采用前文的建模步骤,对三个变量进行多时间尺度非线性协整预测分析研究,见表5,给出了输入序列的赫斯特指数。

表5 三变量多时间尺度赫斯特指数
降雨量和作物需水量多时间尺度序列的分形维数采用式(3)计算。
根据表5的数据可以得到降雨量和作物需水量的分形维数,结果见表6。
从表6中可以看出,灌区灌溉水量原始序列的分形维数和灌区降雨量、作物需水量的分形维数存在显著差异,表明3个变量间存在非线性协整关系。采用灌区1975—2008年的数据进行分析。在三个变量非线性协整关系拟合中,选择小波神经网络,在网络模型中,输入、输出节点数目分别为12和1,为了保证训练集的均方误差最小,在测试中,确定隐含层、动量因子、学习速率的最佳取值分别为6、0.2、0.07。训练的过程曲线如图2所示。
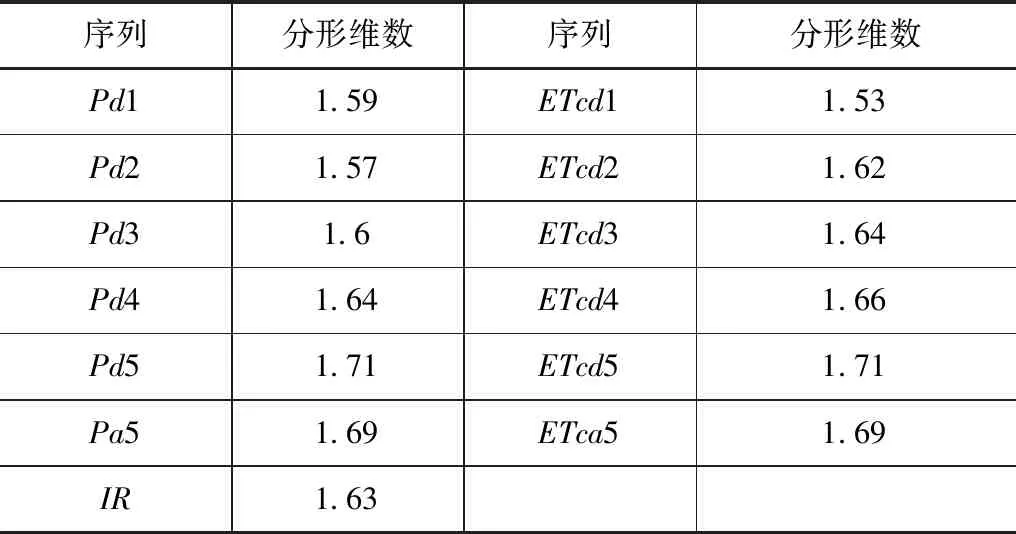
表6 三变量多时间尺度分形维数
分析图2可以看出,迭代次数达到108次后,训练集的均方误差已经趋于收敛,表明模型已经处于稳定状态,收敛值为0.095,收敛效果较好。模型训练完成后,利用该模型,采用预测集数据对降雨量进行预测分析,获得的降雨量预测结果如表7所示。
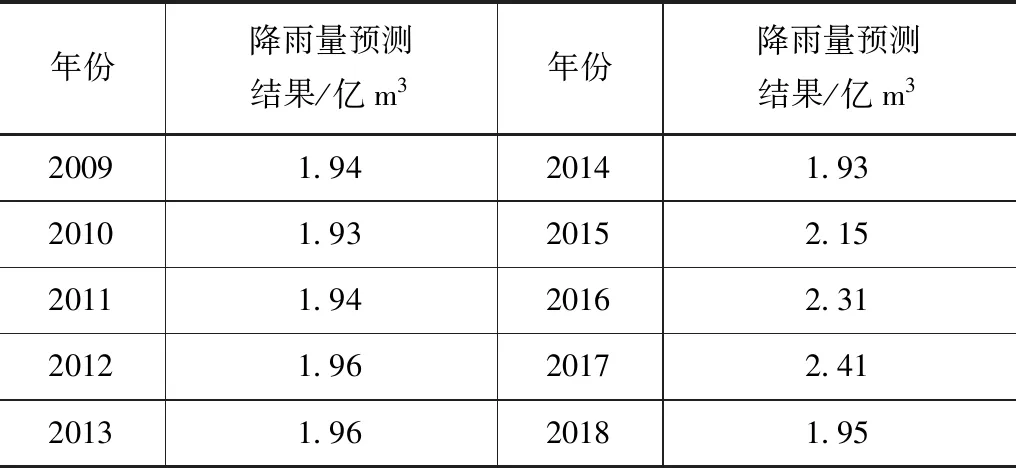
表7 小波神经网络降雨量预测结果
预测序列的赫斯特指数等于0.43,该值小于0.5,则预测序列为非线性协整序列,这个预测序列具有非线性协整关系。
采用Eviews软件对三个变量的滞后阶数进行计算,结果为2。在非线性误差校正方程中,输入小波神经网络训练集的参数集和34组数据的差分值,采用Eviews软件计算非线性协整方程的系数,该方程如下:
IRt=0.0014·P1t-1-0.0019·P2t-1+0.016·P3t-1+
0.45·P4t-1+2.24·P5t-1-20.5·P6t-1-
0.0027·ETct-1-0.0043·ETc2t-1+0.041·
ETc3t-1-0.71·ETc4t-1-1.55·ETc5t-1+
28.02·ETc6t-1+17.28·IR1t-1-
1.08YNNt-1+32.47
(4)
式中,P1,…,P5—一阶差分,该一阶差分是降雨量P的多时间尺度分层Pd1,…,Pd5的结果;P6为Pa5的一阶差分,ETc类似;IR1—IR的一阶差分;YNN—三个变量的非线性协整函数;t-1—第t-1位置。
利用该灌区2009—2018年的作物需水量、降雨量的多时间尺度数据,灌溉水量原始序列数据,同时结合神经网络的灌溉水量预测数据,进行一阶差分,将这些数据代入非线性误差校正方程中,得到灌溉水量非线性协整模型预测误差结果,见表8。

表8 灌溉水量非线性协整模型预测值和预测误差
从表 8可以发现,2010年的降雨量、作物需水量、灌溉水量的多时间尺度非线性协整预测误差为13.23%,达到最大值,三个变量的多时间尺度非线性协整预测误差为0.23%,达到最小值。计算得到10年的平均预测误差7.35%。10年的预测误差均小于14%,整体误差较小,说明在建模预测的过程中,采用多时间尺度非线性协整模型可以满足精度要求。
3 分析与讨论
采用非线性协整关系理论检验了该灌区1975—2018年的灌溉水量与作物需水量、降雨量的非线性协整关系,建立了变量之间的非线性协整模型,证明了3个变量之间具有非线性协整关系,针对灌区水资源供需关系的量化分析,可以采用非线性协整误差校正方程。
通过对比3个变量的多时间尺度非线性协整误差校正方程系数得到:在灌区作物需水量、降雨量多时间尺度分解结果中,系数值最大对应的是趋势项ETca5和Pa5,正负性分析结果与相关性分析结果相同,低频项系数较大,高频项系数较小,证明了在多时间尺度分解结果中,占据主导作用的是趋势项。
采用误差分析的方法对多时间尺度非线性协整模型、多时间尺度BP神经网络模型、原始序列非线性协整模型进行对比分析,可以得出,非线性协整模型在序列的预测中可以达到较好的预测精度,在预测突变点的过程中,采用多时间尺度非线性协整模型优势更加显著,说明在波动修正“拉回”的过程中,协整理论表现突出。
4 结语
以某灌区为例,基于非线性协整理论对该灌区水资源供需时序关系进行了研究,通过选择BP神经网络模型作为对比,研究得到了以下结论。
(1)灌区1975—2018年的灌溉水量与作物需水量、降雨量三个变量间存在非线性协整关系,说明在灌区水资源供需时序研究中可以采用非线性协整模型。
(2)在降雨量预测方面,通过10年的实际数据和预测数据对比,采用多时间尺度BP神经网络模型的预测精度较低,整体误差较大,而采用多时间尺度非线性协整模型的预测精度较高,整体误差较小,可以达到较好的预测效果,且多时间尺度非线性协整模型可以达到较好的波动修正“拉回”效果。
