融合医学词典的条件随机场模型多文本实体识别研究
2022-01-25沈同平
沈同平, 俞 磊
(安徽中医药大学 医药信息工程学院,合肥 230012)
实体识别是自然语言处理技术的一个重要研究方向,自1995年在第六届信息抽取会议上提出实体识别评测任务后,文本命名识别研究在国内外迅速发展,聚焦于金融、新闻媒体、医学文本处理等方面,并取得了丰硕的成果。命名实体的研究方法主要有基于规则和词典的方法[1-2]、传统的机器学习方法[3-4]、深度学习方法[5]、注意力机制模型和迁移学习方法[6-7]等。随着国家医疗信息化进程地加快,电子病历数据量迅速增加,电子病历中包含了大量的隐性医学知识。相关研究表明,电子病历是知识密集型文本,医学实体分布的密集程度高于通用领域文本,具有非常重要的研究价值。和通用领域文本相比,电子病历中的文本的实体类型主要有症状、疾病名称、检查手段和方式等。这些实体数量众多、类型丰富,且实体长度变化多样,实体结构存在别名、缩写词等问题,造成电子病历文本中实体识别效果不佳。
针对这些问题,有些学者采用构建词典的方式来提升模型的效果。吴金星等[8]提出CRF和词典相结合的方式,对蒙古文地名进行识别研究,准确率达到94.68%。龚乐君等[9]通过对外部资源的统计分析构建医疗领域词典,再结合条件随机场,进行了两次不同粒度的标注,将领域词典识别的准确性和机器学习的自动性融为一体,从中文电子病历文本中识别出疾病、症状、药品、操作四类医疗实体,取得良好的效果。任雪菁等[10]采取了词典和 CRF 算法相结合的方法,来提升模型整体的识别精度,并采用Python等工具构建中文生物医学实体自动标注平台。珠杰等[11]利用条件随机场的方法,研究触发词、虚词、人名词典和指人名词后缀为特征的不同特征组合与优化,取得一定的模型效果。晏雷等[12]根据老挝语机构名构词特点,将前缀词提取构造成一个机构名称特征词典, 基于词典与SVM模型确定老挝机构名称前界,再使用融合多特征的CRF模型识别机构名称,取得了较好的识别效果。
相对于通用领域文本,对特殊领域文本如医学文本、少数民族语言以及小语种来说,单独的CRF模型效果一般不尽人意,可以通过构建相应的领域词典来提高CRF模型的识别效果。采用两种不同类型数据集,通用领域文本(简历数据集)和特殊领域文本(CCKS2017电子病历)进行对比分析和验证,从而提升CRF模型在中文文本中实体识别效果。
1 相关方法
1.1 条件随机场(CRF)模型
条件随机场(CRF)是典型的无向概率图模型,2001年由Lafferty等专家提出,结合了大熵模型(MEMM)和隐马尔可夫模型(HMM)的优点,利用丰富的内部及上下文特征信息,充分考虑了输出序列的联合概率分布,在词性标注、实体识别等自然语言处理任务中取得了不错的成绩。CRF模型属于判别式模型,使用最多的是线性链条件随机场,x=(x1,…,xn)表示观察数据序列,y=(y1,…,yn)表示状态序列,需要计算的条件概率如下式所示:
P(y1,…,yn|x1,…,xn)=P(y1,…,yn|x),x=(x1,…,xn),
(1)
CRF模型与HMM等模型相比,可以定义数量更多、种类更丰富的特征函数,同时,特征函数的权重没有任何限制。我们可以为每个特征函数赋予一个权值,用以表达我们对这个特征函数的信任度。假设tk的权重系数是λk,sl的权重系数是μl,则CRF由我们所有的tk,λk,sl,μl共同决定。
(2)
其中,Z(x)为规范化因子:
(3)
CRF模型的重要任务就是在训练数据中使用最大似然估计算法,计算不同特征权重λ。在模型训练时,通过函数L的计算,使得P(s|o,L)对数值最大为1的估计值。
(4)
函数L计算出来后,采用动态规划的最短路径求解方法维特比(Viterbi)算法,求解最可能的状态序列并输出。定义了两个局部状态进行递推。首先,计算在时刻t隐藏状态为i的所有可能的状态转移路径i1,i2,...it中的概率最大值,记为δt(i):
(5)
由δt(i)的定义可以得到δ的一般递推公式:
(6)
在前一个局部状态的基础上进行第二个局部状态计算,求得在时刻t隐藏状态为i的所有单个状态转移路径(i1,i2,...,it-1,i)中概率最大的转移路径中第t-1个节点的隐藏状态为Ψt(i),计算公式为
(7)
1.2 专业医学词典构建
通用文本和医学文本的特征和用词方式都存在很大差异,为了提升CRF模型在医学文本中的实体识别效果,需要构建专业的医学词典。构建的步骤:利用爬虫从丁香医生、百度百科等网站上爬取相关医学知识。对爬取的医学文本进行中文分词、去除噪音以及人工标注等操作,形成专业医学词典。实验数据集采用CCKS2017电子病历文件,因此医学词典的标注按照身体部位(Body)、检查手段(CHeck)、疾病名称(Disease)、症状(Signs)和治疗手段(Treatment)五种实体类型进行标注,规范如下:
(1)身体部位:患者全身的各个部位,比如“咽部”、“双肺”、“四肢”和“头颅”等,描述患者各种不适的身体部位。
(2)疾病名称:医生根据检查手段以及临床经验,诊断出患者所患疾病,一般以“病”或“症”“炎”作为实体的最后一个词。比如“支气管肺炎”和“糖尿病”等。
(3)症状:患者因疾病导致的各种不适或异常表现或者患者在描述自身情况的介绍,比如“头痛头晕”“麻木无力”和“呕吐”等。
(4)检查手段:根据患者的症状描述以及身体部位情况,采用一定的检查项目进行疾病判断。比如“跟膝腱反射”“双侧巴氏征”和“肠鸣音”等。
(5)治疗手段:结合检查手段,针对具体疾病给予具体的治疗方式和手段,比如“胰岛素”、“降压药物”和“阿托伐他汀”等。
2 实验结果与分析
2.1 实验数据集
采用两个公开的数据集对模型进行评测,分别是CCKS2017电子病历数据集和简历(Resume)数据集,CCKS2017电子病历数据集主要是从电子病历的角度进行专业医学实体识别。因此采用模型验证的数据集具有一定的扩展性,既有常规的文本,又有专业的医学文本。
CCKS2017电子病历数据集包括7种实体名称,分别是身体部位(Body)、检查手段(Check)、疾病名称(Disease)、症状(Signs)和治疗手段(Treatment)。训练集中各实体的数量如表1所示。

表1 CCKS2017数据集训练集各实体数量
简历数据集(Resume)包含7种实体名称,分别是国籍(CONT)、姓名(NAME)、学历(EDU)、职称(TITLE)、公司(ORG)、民族(RACE)、专业(PRO)和籍贯(LOC)。训练集中各实体的数量如表2所示。

表2 Resume数据集训练集各实体数量
2.2 数据集标注与评价指标
文本中的实体识别,通常需要对数据集进行序列标注,进而实现不同的实体识别。数据集主要采用BMES标注体系。在CCKS2017数据集中,以实体Treatment为例,“B- Treatment”表示治疗手段实体的首字符,“M- Treatment”表示治疗手段的中间字符,“E- Treatment”表示治疗手段实体的最后一个字符,“S- Treatment”表示单独的治疗手段实体,“O”表示5个实体外的其他字符。在简历数据集(Resume)中,以实体LOC为例,“B- LOC”表示籍贯实体的首字符,“M- LOC”表示籍贯实体的中间字符,“E- LOC”表示籍贯实体的最后一个字符,“S- LOC”表示单独的籍贯实体,“O”表示8个实体外的其他字符。
采用通过精确率(Precision)、召回率(Recall)、F1值和精确率(Accuracy)对模型评价,验证本文模型的有效性。
(11)
(12)
(13)
Acc=(Tp+Tn)/(Tp+Fn+Tn+Fp),
(14)
其中,Tp表示真正例,Fp表示假正例,Tn表示正负例,Fn表示假负例。
采用Pytorch平台搭建实验环境,具体配置如表3所示。

表3 模型实验配置环境

续表3
2.3 实验结果
为了对提出的模型进行评价,分别对简历数据集(Resume)和CCKS2017电子病历数据集进行评测,其中针对Resume数据集,采用CRF模型进行评测,CCKS2017电子病历数据集分别采用CRF模型和CRF模型+词典进行评测,结果如表4和表5所示。
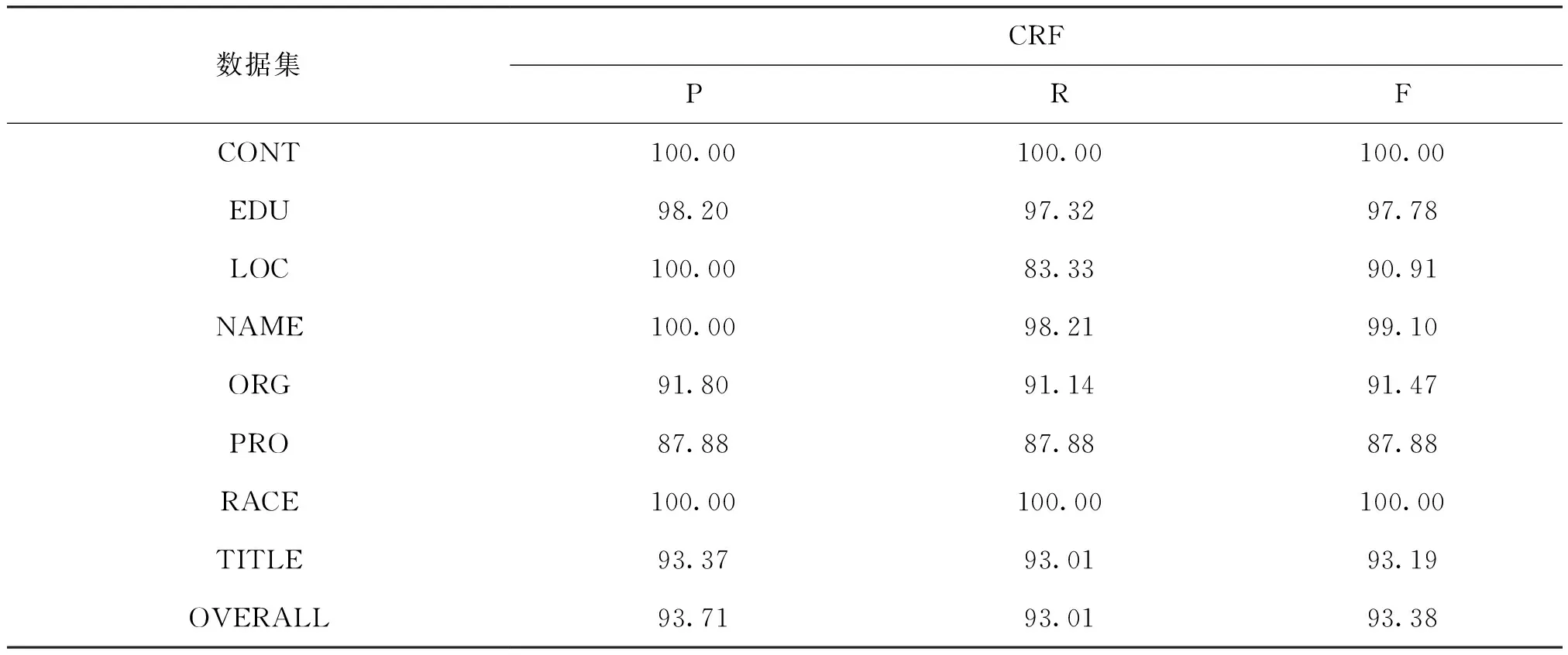
表4 简历数据集(Resume)测评结果

表5 CCKS2017电子病历数据集测评结果
从表4可以看出,CRF模型对简历数据集(Resume)取得了不错的效果,准确率为93.71%,召回值93.01,F值达到93.38。简历数据集中的文本类型是普通文本,CRF模型能取得较不错的评测效果。国籍(CONT)和民族(RACE)两个实体,F值达到100,因为这两个实体字段比较固定,不容易产生歧义,模型能够高效的进行区分和识别。但对公司(ORG)和专业(PRO)这两个实体识别效果相对较差,因为专业和公司名称众多,同时容易产生混淆,比如专业名称“临床医学专业”、“中医临床医学专业”和“中西医临床医学专业”等。
从表5可以看出,在CCKS2017电子病历数据集中,实体Disease和Treatment在训练集中的数量分别是515个和813个,而Signs、Body和Check的数量分别为6 486个、8 942个和7 987个。实体Disease和Treatment的评测效果相对降低,召回值只有70.06和72.26,表明训练集中实体数量多少直接影响模型的测评性能。
相对于简历数据集(Resume),CCKS2017电子病历数据集模型评测效果相对较差,准确率、召回值和F值分别为89.32、88.00和88.54。这是因为医学文本中的医学实体长度不定、结构复杂和专业术语较多等原因导致CRF模型在医学文本上识别效果较低。为了提高CRF在医学文本中的识别效果,文章提出将医学词典结合CRF模型进行评测,评测效果取得了一定程度地提升,CCKS2017电子病历数据集模型的准确率、召回值和F值分别为94.04、94.18和94.06,表明本文提出的模型结构的有效性。
3 结语
在对中文实体识别分析的基础上,对比分析CRF模型在通用文本和医学文本中实体识别的效果。实证结果表明,CRF模型在通用文本中取得了较为理想的测评效果,但由于医学文本中的医学实体长度不定、结构复杂和专业术语较多, CRF模型在医学文本上识别效果较低。为了提升在医学文本上的识别效果,构建了专业的医学词典,实验结果表明,CRF+词典的模型能够有效提升在医学文本中各类医学实体的识别效果。本次实验的数据集采用的是BMES标注体系,后续还需要对BIO标注体系和BIEOS等标注体系进行对比研究。
