基于双模态融合特征的模糊语音识别研究
2022-01-25冯晓静白静薛珮芸戎如意
冯晓静,白静,薛珮芸,戎如意
(太原理工大学信息与计算机学院,山西晋中 030600)
语音作为信息交互最直接、最便捷的载体,在人机交互中发挥着重大作用。语音识别作为一种人机交互的关键技术,发展到如今已经取得飞跃性的进步。但是在某些特定词汇的识别中,其性能就变得差强人意。如模糊语音,即那些具有相近发音机理,在听觉上易混淆,容易被系统误识的语音。这些语音的存在是影响语音识别的主要因素,是汉语普通话语音识别错误的主要来源。
对于模糊语音的研究,单靠音频信息一种模态是远远不够的,而语音是一种多模态的通讯方式,包括视觉、听觉、发音器官运动等多种自然模态和大脑活动等非自然模态[1],可以选择多种器官协同工作的“多模态”机理[2]来进行研究。近年来,多模态融合的研究方式逐渐增多,例如黄立鹤[3]的《语料库4.0:多模态语料库建设及其应用》、基于决策融合的双模态语音情感识别[4]以及特征融合的双模态[5]识别研究。
基于此,文中从数据库出发,选择了5 位男生和5位女生共计10 位被试者,利用电磁发音仪(Electromagnetic Articulograph,EMA)和笔记本电脑同步采集被试者说话时发音器官的运动数据与音频数据,经过滤波、筛选、加噪,建立双模态模糊语音数据库。然后从特征域出发,选择声学特征与发音器官运动特征。为了研究不同信噪比下模糊语音的鲁棒性与抗噪性,设计了以支持向量机(SVM)为模型的语音识别实验进行分类,并且对单模态特征与双模态融合特征进行了对比研究。
1 特征提取
为了进一步提高恶劣环境中语音识别的正确识别率,分别提取不同信噪比下模糊语音的声学特征与运动学特征[6],对不同的特征进行特征层融合验证,得到不同的双模态融合特征组合。
1.1 运动学特征
语音的产生过程是一个十分复杂的过程。由大脑、呼吸系统、声带以及舌部、唇部、齿等发音器官的相互配合最终形成人们所需要的语音。通过研究发音器官的生理特性,以鼻梁和双耳为参考点减小头部转动带来的误差,采集舌、唇、颌部的运动数据,根据发音器官的轨迹数据计算唇、舌尖、舌中的位移、速度、发音运动起始时间等作为发音动作特征[7](Articulatory Movement Features,AMF)。
发音运动特征的数据由EMA 采集,每个传感器都是一个独立的信息通道,并且所有传感器都在同一个三维坐标空间中,前后方向为X轴,左右方向为Y轴,垂直方向为Z轴。通过软件Visartico 来观察发音器官的运动轨迹并提取运动学特征。实验结果表明,舌部和下颌的运动轨迹幅度要大于唇部的运动幅度,X轴和Y轴的运动幅度也比Z轴的运动幅度大,可以更加清晰地表征语音的信息,所以最后选择舌部和下颌的Z轴和Y轴来提取发音运动特征。音素/an/和/ang/的发音轨迹对比如图1 所示,所选数据是舌尖和下颌在Y轴和Z轴方向的运动轨迹,由图中可以看出这两个音素的发音轨迹有明显的区别,相较于下颌,舌尖的运动轨迹区别尤为明显。
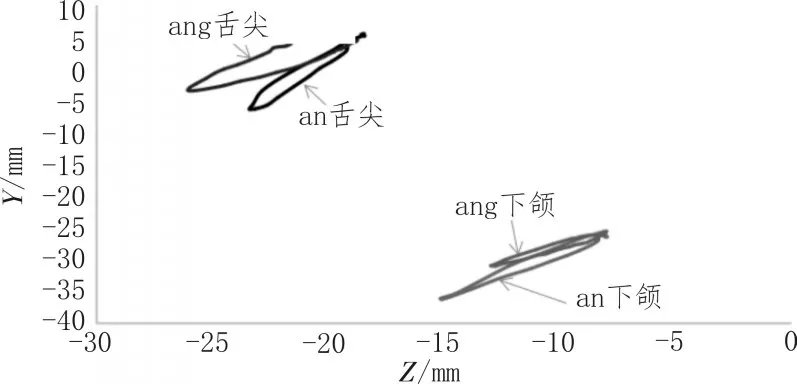
图1 /an/和/ang/的发音轨迹对比
从运动轨迹提取速度与位移特征,位移指相对于初始位置传感器的移动距离;速度指发音器官在每一时刻的位移变化量,是位移对时间的一阶导数,计算公式如式(1)所示:
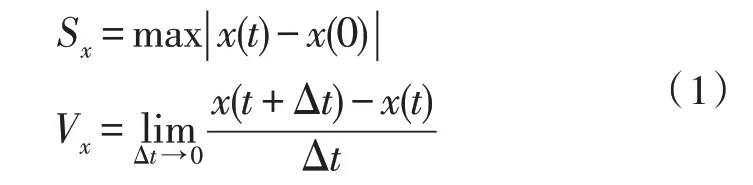
式中,Sx表示X轴最大位移,x(t)表示t时刻传感器的X轴坐标值,x(0)表示初始时刻传感器的X轴坐标值,Z轴同理。
如图2所示,是/an/的发音器官舌尖和舌根的运动轨迹与其对应的语音波形图。可以看出发音器官从开始发音到发音结束是一个完整的信号[8],并且运动轨迹波形先于发音波形,因此选择发音运动的起始时间(Articulator Onset Time,AOT)作为另一种运动特征。

图2 /an/的发音器官运动轨迹及语音波形图
最终选择舌尖、舌根以及下颌3 个传感器上X轴与Z轴的AOT、速度和位移数理统计值的最大值、最小值、标准差作为最终的运动学特征,共计42 维。
1.2 声学特征
除了对运动数据提取发音运动学特征之外,还需要对音频数据提取声学特征,而文中所选的声学特征包括韵律特征、伽玛通滤波倒谱系数[9-10](GFCC)、梅尔滤波倒谱系数(MFCC)以及耳蜗滤波倒谱系数[11](CFCC)特征。
韵律特征指的是语音中除音质特征之外的高音、音长和音强方面的变化,是语音研究中的重要特征。文中选择语速(一维)、平均过零率(一维)、振幅及振幅变化率的统计值(6 维)、基频及基频变换率的统计值(6 维)、短时能量及其变换率的统计值(6 维)中前3 个共振峰的统计值及一阶差分(24 维),共计44 维的韵律特征。
MFCC[12]是现如今语音识别领域使用最经典的声学特征之一,基于人耳听觉特性,采用梅尔滤波器。在梅尔刻度下,人耳对声音频率的感知呈线性关系,具体如式(2)所示,其中f为语音频率。
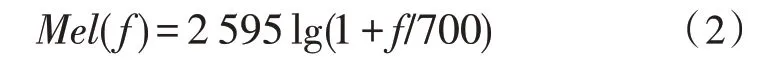
文中选择离散余弦变换后的前12 维特征进行数理统计,选其最大值、最小值、平均值、中位数和标准差共计60 维。
GFCC 与MFCC 的不同之处在于用伽玛通滤波器代替了梅尔三角滤波器,在一定程度上减小了噪声对特征提取的影响。每个滤波器的带宽与人耳的临界频带有关,如式(3)所示:
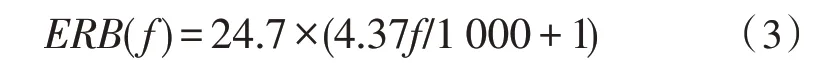
CFCC[13]是2011 年开始提出的一种使用听觉变换提取的特征参数。将耳蜗滤波函数作为一种新的小波基函数,运用小波变换实现滤波过程,代替快速傅里叶变换模拟人耳听觉机理。
首先定义了一个耳蜗滤波函数ψ(t),并且满足以下条件:
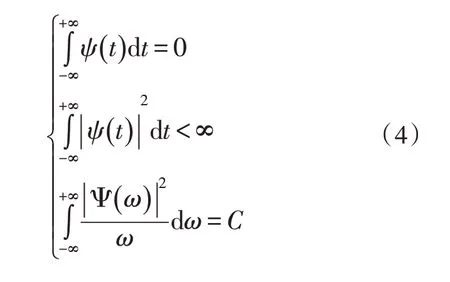
假设f(t)为经预处理后的语音信号,经过听觉变换后在某一频带范围内的输出为:
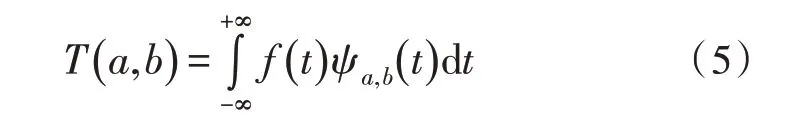
具体的耳蜗滤波函数如式(6)所示,u(t)为单位阶跃函数,b为可变实数,为尺度变量,α和β是大于0 的实数,取经验值3 和0.2。
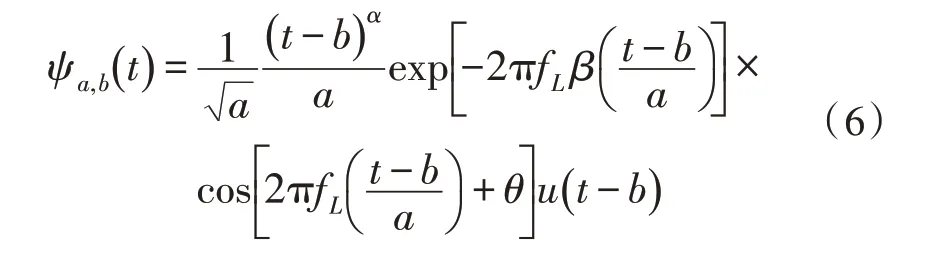
经过听觉变换的信号还要通过耳蜗内的毛细胞去极化才能转变为人脑可分析的电信号。其中毛细胞函数用式(7)来模拟:
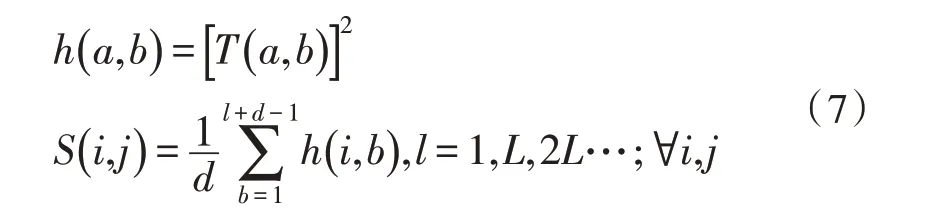
然后对毛细胞函数的输出结果进行非线性变换,将能量值转换为感知响度。传统的CFCC 进行立方根变换如式(8)所示:

最后进行离散余弦变换,减去贡献量很小的特征向量,降低特征向量间的相关性,减小特征向量的冗余度,得到耳蜗滤波倒普系数CFCC1。
根据MFCC 的提取过程,改进非线性变换函数,可以对毛细胞输出结果进行对数变换,如式(9)所示:

语音信号的每一帧对于识别结果的贡献是不同的,并且特征参数的阶数越高越不易受噪声影响,可以有很好的抗噪性与鲁棒性。因此选择半升正弦函数进行倒谱提升,对特征参数进行改进,降低易受噪声干扰的低阶向量。所选用的倒谱提升窗函数为式(10)所示,第一个1/2 的作用是保证倒谱分量的完整性,第二个1/2 是对低阶分量进行加权计算。

最终经过提升对数变换和半升正弦函数倒谱,改进后得到新的特征CFCC2。计算公式如式(11)所示:
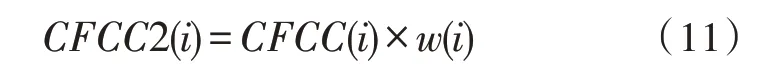
1.3 特征层双模态融合
目前多种信息融合的方法主要有两种,分别是特征层早融合和决策层晚融合[14]。特征层融合的优势是可以同时得到更多的模态信息,更好地捕捉各模态间的关联。
首先进行运动特征间各传感器的特征融合,将各传感器的特征向量首尾相连组成一个新的特征向量。
然后进行运动学和声学双模态间的特征融合。假设x,y是两个模态的特征向量,则复合向量z=x+iy(i 是虚数单位)为x,y的融合特征向量。如果维度不一致,则对低维补0。
最后通过核主成分分析(KPCA)对融合特征降维。KPCA 是对主成分分析(PCA)的非线性扩展,能够挖掘到数据集中蕴含的非线性信息,在保持原数据信息量的基础上达到降维的目的。文中选择高斯径向基核函数(RBF)来完成降维工作,如式(12)所示:
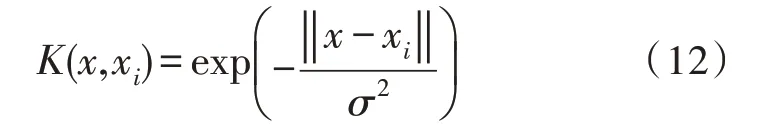
通过非线性函数映射到高维后对其进行主成分分析,在高维空间进行降维,通过KPCA 降维后的数据如式(13)所示:

其中,Q是在高维降维后的降维矩阵。
2 语音识别模型选择
支持向量机(Support Vector Machine,SVM)根据统计学知识和结构风险最小化来构建分类器和回归器,结合了感知机和logistic 分类回归思想。对于线性不可分的样本,通过核函数把原来的样本空间映射到高维空间上来寻求最优分类的超平面,即最大间隔分离超平面,从而将非线性分类问题转换为线性分类问题。SVM 超平面分类示意图如图3 所示。
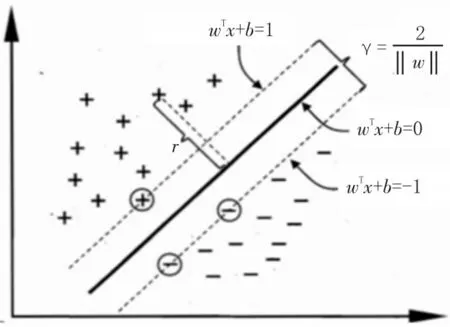
图3 SVM超平面分类示意图
文中选用的是RBF 核函数,采用六折交叉验证进行分类实验。利用平均分类精度(MCA)得出6 个识别结果,再取6 个结果的平均值为最终的评价指标。假设有N个数据,随机分成6 份,每一份都循环作为测试集,其他5 份作为训练集。MCA的定义如式(14)所示:

其中,Ni表示预测类别标签与真实类别标签相同的个数。
3 实验数据
该文主要研究了双模态模糊语音在不同信噪比下的抗噪性与鲁棒性,所选实验数据应该包含多种模态信息。伴随着发音器官数据采集技术的改进,从X-ray 到实时磁共振技术(rMRI)再到EMA 和电声门图仪(EGG),采集难度降低的同时对人体伤害也减小。目前,国外包含发音器官运动的多模态语音数据库有USC-TIMIT 语料库[15],是MRI 唯一公开的大型MRI 数据集;EMA-IEEE 数据集[16]包括4 名男性与4 名女性以正常速度和快速读720 条语音平衡的IEEE 句子。但是很难找到汉语普通话含发音器官运动数据的多模态语音库,所以文中选择自建双模态模糊语音数据库。
选择10 位(5 男5 女)被试者,要求每个被试者的水平都在普通话二级乙等以上,并且都不曾进行过口腔手术。对筛选后的文本信息进行录制,每个文本录制3 次。具体筛选后的文本信息如表1 所示,选择8 对容易混淆的韵母音素,与不同的声母组成孤立词。

表1 韵母文本信息表
通过笔记本电脑和EMA 仪器同步录制音频数据和发音器官的运动数据。其中音频数据的采样率为16 kHz,EMA 的采样率为400 Hz。一共设置11 个传感器,其中8 个用于收集有效数据,具体位置[17]是舌部设置3 个传感器,最佳位置距舌尖19.93 mm,38.2 mm 和80.51 mm;唇部设置4 个传感器;下齿槽设置一个传感器,最佳位置距下唇的距离为26.37 mm 处。另外3 个是参考传感器,目的是消除头部运动产生的误差,分别位于鼻梁、左耳后和右耳后。
用Praat 筛选声学数据,Visartico 软件筛选运动学数据,经过双重筛选之后,对音频数据加入不同信噪比的白噪声和混合噪声。筛选后数据库中语音类型数量如表2所示,共计1 268条运动数据,6 300条含噪语音数据。
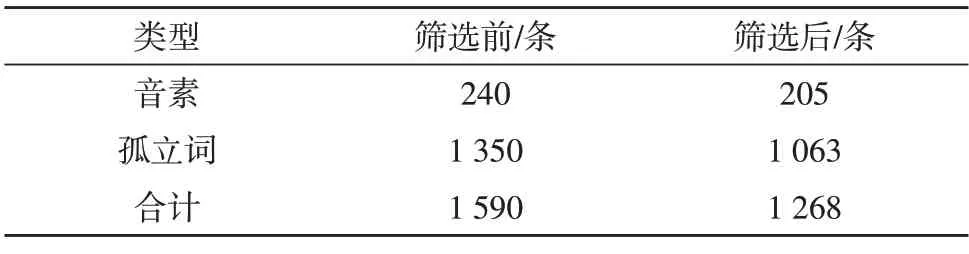
表2 筛选后数据库中语音类型数量
4 实验结果与分析
为了验证模糊语音的不同特征在两种噪声条件下的识别性能,选择文中自建的双模态模糊语音数据库,分别提取单模态的特征以及双模态的融合特征,经过语音识别模型后得出确切的识别率。
4.1 单模态特征识别结果
对提取的5 种声学特征进行特征识别性能验证,白噪声条件下的识别率如表3 所示,混合噪声条件下的识别率如表4 所示。

表3 单模态白噪声识别率
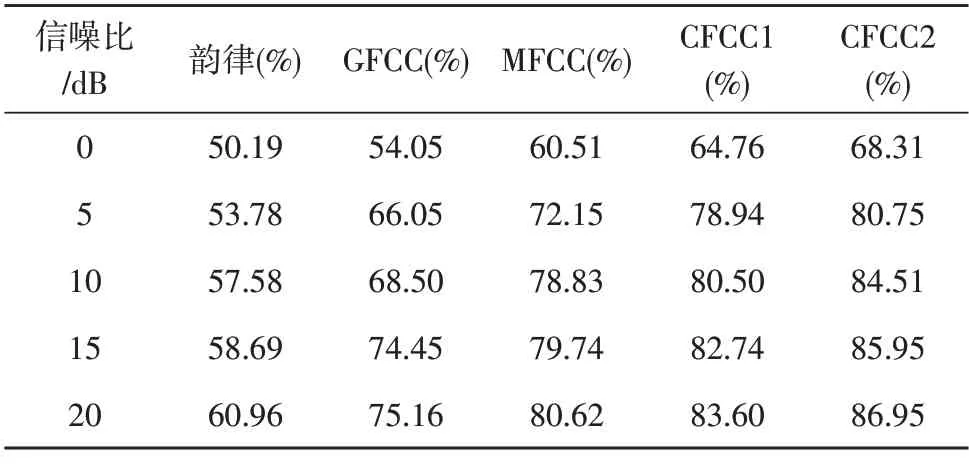
表4 单模态混合噪声识别率
从表3 和表4 中可以发现,韵律特征的识别率在5 种声学特征中最低,CFCC 特征相较于GFCC 和MFCC 有较好的识别率,说明基于听觉变换滤波的特征相比于梅尔变换滤波和伽玛通滤波的特征能更好地表征语音的信息。而对数变换的CFCC2 的识别率又优于传统立方根变换的CFCC1 的识别率,说明对数变换相较于立方根变换能更好地模拟耳蜗听觉变换。
对比表3 和表4,在低信噪比时,白噪声下的韵律特征和GFCC 特征的识别率要高于混合噪声下同类噪声的识别率,但是总体而言,混合噪声下的识别率要高于白噪声下的识别率。
4.2 双模态融合特征识别结果
选择单模态中识别率较高的3 种特征:MFCC、CFCC1 和CFCC2,与提取的运动学特征进行双模态融合,然后分别得到融合1、融合2 和融合3 三种双模态融合特征,将它们作为输入样本进行分类识别,在白噪声和混合噪声两种噪声背景条件下,具体的分类识别结果如表5 和表6 所示。
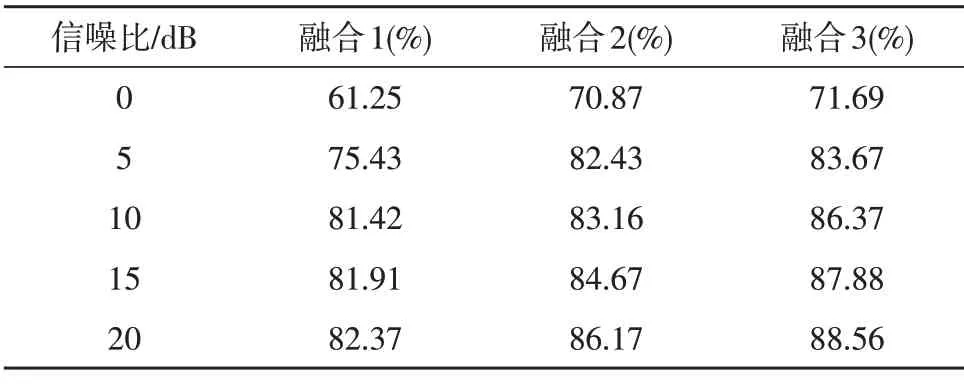
表5 双模态白噪声识别率
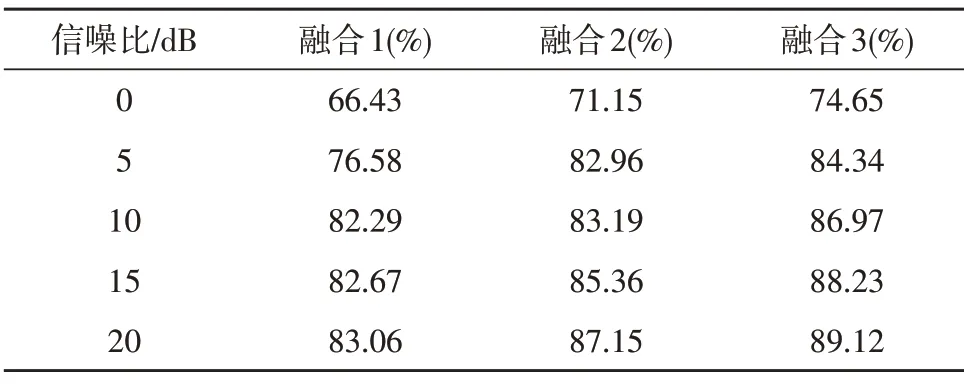
表6 双模态混合噪声识别率
对比表3和表5,表4和表6,可以发现3种融合特征都比原单模态的识别率有所提升,说明了双模态融合特征相较于单模态特征能更完整的表征语音中蕴含的信息,可以对单一信息进行补充,混合噪声下的识别率依旧高于白噪声下的识别率。计算不同信噪比下识别率的提升幅度,得出如图4、图5 的结果。
观察图4 和图5,在同一信噪比下,不同特征的提升幅度不同,同一种特征在不同信噪比下的提升幅度也不同。但总体而言,低信噪比下的提升幅度要高于较高信噪比下的提升幅度。随着信噪比的增加提升幅度越来越小,在白噪声背景下,提升幅度最高为6.53%,混合噪声下提升幅度最高为6.39%。
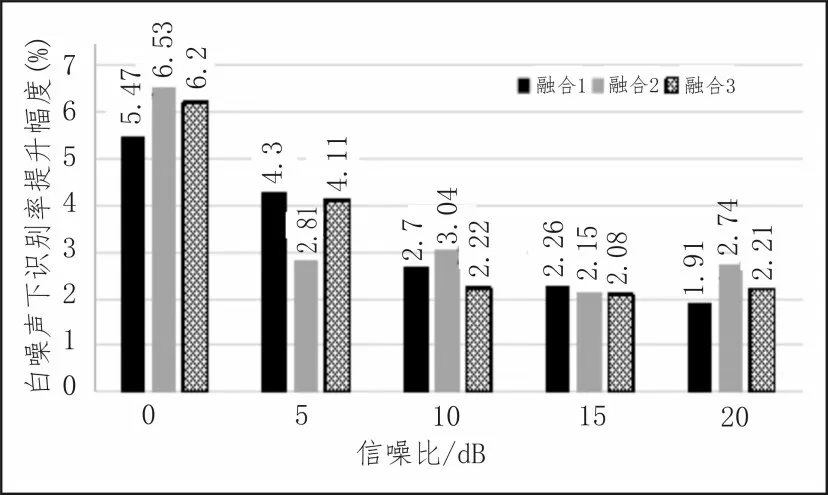
图4 白噪声下识别率提升幅度
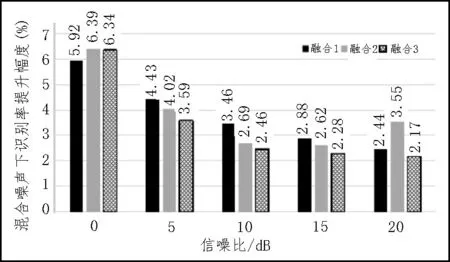
图5 混合噪声下识别率提升幅度
5 结论
文中建立了含有发音器官运动数据和语音音频数据的双模态模糊语音数据库,其中包括音素和孤立词两种类型的文本,总计有1 268 条运动数据和6 300 条语音数据。然后从特征域入手,对具有相似发音机理、在听觉上容易混淆且易被智能机器误识的模糊语音提取声学特征以及运动学特征,从特征层进行双模态融合,选择核主成分分析算法通过降维减小冗余,然后根据支持向量机模型设计语音识别实验,在白噪声和混合噪声的背景条件下对所提出的特征进行测试,研究其抗噪性与抗鲁棒性。实验结果表明,在两种噪声条件下对数变换的耳蜗倒谱系数特征CFCC2 始终优于GFCC、MFCC 和立方根变化的CFCC1,可达86.95%。双模态融合特征可以从多个角度更加完整的表征语音信息,相比于单模态特征识别率有较大提升,在低信噪比情况下的提升幅度要明显的大于较高信噪比下识别率的提升幅度,最高可提升6.53%。在今后的研究中,可以进一步地扩充双模态模糊语音数据库,为模糊语音识别研究提供可靠的语音数据平台。
