基于XGBoost分类算法的热舒适预测模型
2022-01-25沈雅倩黄志甲
沈雅倩,黄志甲,周 涛
(安徽工业大学建筑工程学院,安徽 马鞍山 243032)
随着经济的快速发展和物质生活水平的提高,人们对居住环境的安全性和舒适程度有更高的要求,但由于个体差异使每个人追求的热舒适环境不同,研究个性化热舒适模型对个性化空调的控制具有重要意义。国内外学者关于个体差异性如年龄[1-3]、体重[4]、性别[5-7]等因素对人体热舒适性影响进行了大量研究。部分学者采用线性回归的方法对个体差异的单因素进行研究,如Jiao 等[8]以上海地区老年人为研究对象,通过实验测试计算出老年人冬季可接受的温度范围为14.1~19.4 ℃,夏季为23.8~27.0 ℃,与标准舒适温度相比[9],老年人冬季对舒适温度的要求低于标准,夏季对舒适温度的要求在标准范围;张样等[10]以大学生为研究对象,测试教室、图书馆等大学生活动较多场所的湿度、风速、平均辐射温度等参数,用predicted mean vote-predicted percentage dissatisfied(PMV-PPD)公式对其进行计算,结果表明,PMV 在1.18~2.25 之间,PPD 在34.91%~86.52%之间;Ferrato 等[11]通过实验测试发现男性和女性对环境温度的要求不同,女性比男性更易感受热和冷。部分学者采用机器学习的方法如神经网络[12]、支持向量机[13]等对个体差异的多因素进行研究,如Wang等[14]使用逻辑回归算法,通过调研受试者的热感觉预测热环境温度可接受性,预测准确率达87%;翁虎等[15]使用神经网络算法,以空气温度、房间类型、月平均气温等参数为输入预测PMV;Jiang等[16]以空气温度、相对湿度等环境参数及服装热阻的个体因素参数为输入,利用支持向量机算法对人体热感觉进行预测,发现支持向量机模型的准确率高于PMV模型的准确率。
综上可看出:现有基于热舒适机器学习算法的研究以环境参数为主要输入参数,考虑的个体因素仅服装热阻和代谢率,但性别、年龄等其他个体因素也会对热舒适环境造成影响;研究方法多集中于神经网络等复杂模型,此类模型计算规律更多地与“黑箱”理论相似,较难解释[17]。XGBoost算法以其精度高、正则化、可并行处理等优点在数据挖掘领域被广泛应用。因此,引入新的机器学习算法—XGBoost分类算法,以公共建筑自然通风条件下不同个体的影响因素为输入参数建立模型,识别影响个性化热舒适的关键因素,以期为个性化空调的指标确定提供参考。
1 数据描述
使用的数据为ASHRAE 全球热舒适数据库II中巴西地区的数据集,调研该数据集的目的是了解居住者在自然通风条件下的舒适度,调研对象为圣卡塔琳娜州联邦大学教室的学生,共2 292 份问卷,男女比例接近1∶1。圣卡塔琳娜州联邦大学的教室为主要由混合模式系统(带有可操作的窗户和调节房间温度的空调)组成的房间。人体热反应会随季节的变化而发生改变,冬季偏暖、夏季偏冷是一个普遍的特征现象,故将冬夏季分开考虑[18]。筛选夏季数据为样本数据,样本数据共1 382 条,每条样本包含身高、体重、空气温度等10个特征,具体见表1。
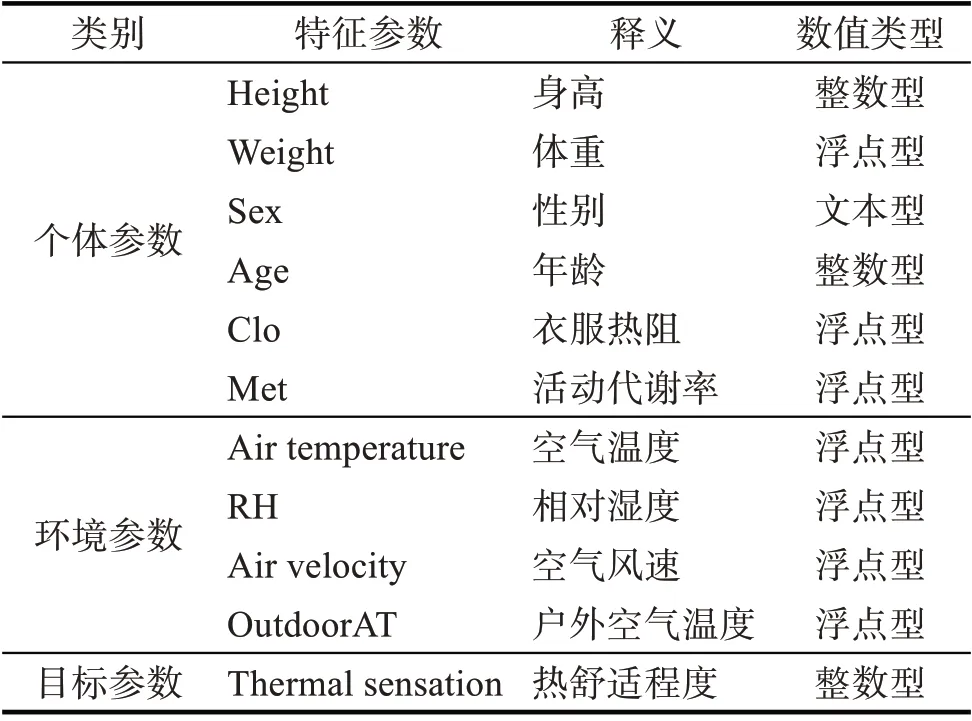
表1 特征参数Tab.1 Characteristic parameters
2 预测模型
2.1 XGBoost分类算法
XGBoost 是将多个弱分类器累加组合成一个强的分类器,使目标损失函数达到最小的一种梯度提升决策树。XGboost的目标函数O是由一个损失函数和一个正则化项两部分组成,其定义表达式如下

式中:L为损失函数,用于判断模型中预测值和真实值之间的损失或错误;Ω(ft)为正则化项;ft为每一颗分类树;t为树的棵数,用来控制模型的复杂度,避免过拟合[19]。
2.1.1 损失函数
XGBoost分类算法可看作是由K棵树组成的加法模型,在保留原模型不变的基础上,将上一次预测产生的误差作为参考进行下一棵树的建立,也就是说,将预测值与真实值的残差作为下一棵树的输入。其加法过程有如下表示:
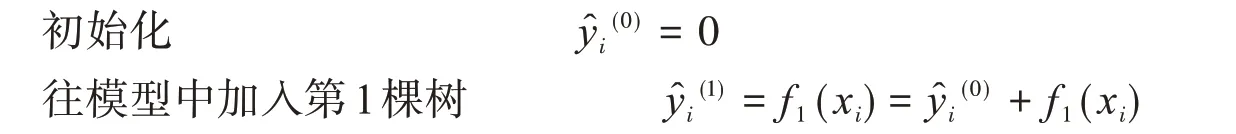

2.2 预测流程
热舒适预测模型的预测流程可分为以下步骤:在Python 软件中输入样本数据集并对样本中的数据进行预处理,包括缺失值的处理和特征参数数据类型的转换,其中缺失值采用均值方法填充,采用独热编码的方法将特征参数Sex 的文本形式转换成数值形式;将预处理后的数据集生成4∶1 的训练集和测试集,设定模型常用的Max_Depth、Learning_Rate 等训练参数;利用网格搜索和交叉验证方法进行调优。网格搜索算法是对指定参数进行穷举性的搜索算法,将各参数之间可能的选择和取值分别进行排列和组合,列出所有可能的选择和组合结果[20];将各项目的组合应用于XGBoost 的训练,使用5 折交叉对其表现进行评估,得到的最优参数如表2。

表2 最优参数值Tab.2 Optimal parameter value
2.3 模型评价指标
为判断热舒适预测模型的优劣,选择分类模型中常见的AUC 和准确率作为模型的评价指标。AUC (area under the curve)表示受试者工作特征(receiver operating characteristic,ROC)曲线下的面积,用以衡量模型整体的性能[21],ROC 曲线是以假阳率(false positive rate)为横轴、真阳率(true positive rate)为纵轴绘制成的曲线;准确率可反映预测正确样本的能力。各指标计算公式如下:

式中:T为真阳率;F为假阳率;A为准确率;TP,TN分别为正确预测的正负样本数;FP,FN分别为错误预测的正负样本数。其中,正样本数是受试者认为舒适的数目,负样本数是受试者认为不舒适的数目。
3 结果与讨论
3.1 模型预测效果
为验证热舒适预测模型的有效性,选取夏季为样本数据集,将处理完毕的数据按照4∶1划分,训练集数据1 106 条,测试集数据276 条。以特征参数表1 中10 个指标为输入变量,利用训练好的XGBoost分类算法模型对测试集数据进行舒适度的预判,结果如图1。由图1 可看出,测试数据集中实际有233 个样本感到舒适,而模型正确预判出193 个样本感到舒适,准确率达82%,表明该模型具有一定的可靠性和有效性。
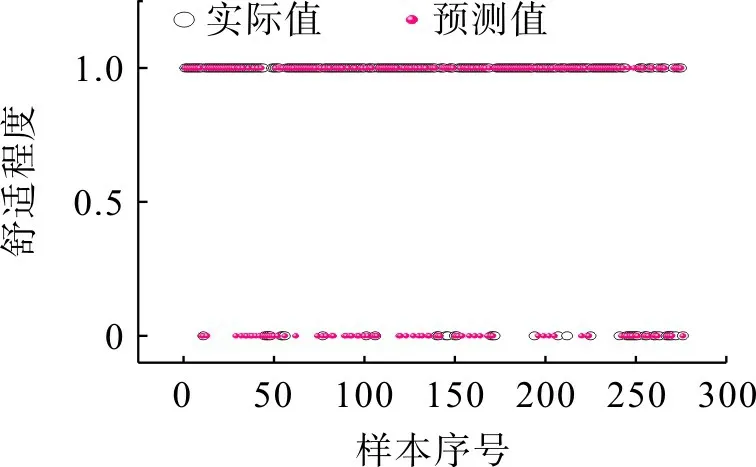
图1 模型预判结果Fig.1 Predicted results of the model
为进一步评估热舒适预测模型的预测效果,选取逻辑回归、随机森林、支持向量机和神经网络4种代表性的机器学习算法作为对比模型,以AUC和准确率为指标评估模型的性能效果,各算法预测结果见表3。由表3 可看出,XGBoost 模型的AUC 和准确率分别为0.95,89%,均优于其他算法,表明建立的XGBoost 模型对公共建筑热舒适预测有一定的优势。
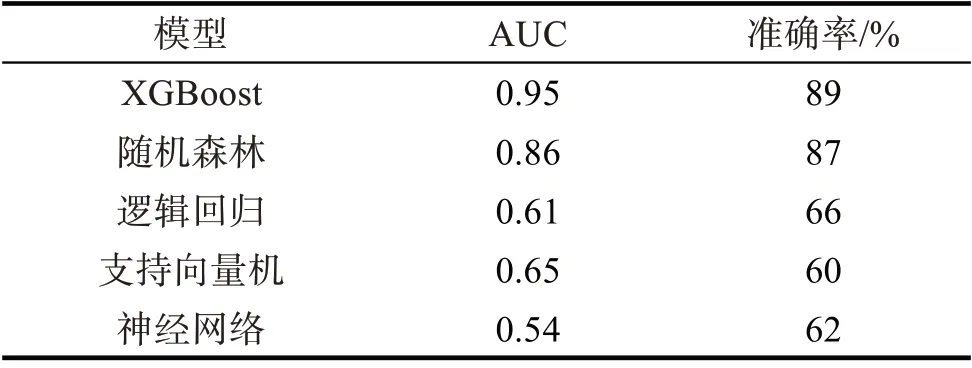
表3 各算法评价指标结果Tab.3 Evaluation index results of various algorithms
3.2 基于SHAP值的模型解释分析
XGBoost传统的feature importance(特征重要性)只能反映出特征的重要程度,并不清楚特征是如何影响预测结果的。SHAP 值可量化每个特征对模型预测的贡献,判断样本中各变量对模型预测产生的影响。其可反映出每一样本中特征参数的影响力数值,又可指出特征参数的正负性。图2 为SHAP,XGBoost 两种算法训练后的特征参数重要性对比。

图2 SHAP,XGBoost特征参数重要性对比Fig.2 Comparison of the feature parameter importance of SHAP and XGBoost
观察图2 可发现:两种算法训练后,前5 的特征参数排序不完全相同,但特征参数相差不大,结合两种算法特征参数的重要度排序可得出,影响舒适程度的关键因素是空气温度、相对湿度、空气风速、体重;两种算法在进行重要性排序时空气温度均在第一位,但XGBoost算法的值较大。具体而言,夏季空气温度越高,受试者越不舒适;相反,夏季风速越大,受试者越感到凉爽,风速重要程度在SHAP和XGBoost两种方法中排名均在前3。
图3 为每个特征参数SHAP 值的分布情况,正负SHAP值表示特征参数变量和输出结果之间的正负相关性。从图3 可看出,Air temperature(空气温度)、RH(相对湿度)、Air velocity(风速)、Weight(体重)等特征参数对模型的影响较显著。其中:空气温度对受试者的舒适程度造成负面影响,具体而言,随空气温度的升高,SHAP 值减小,对应的舒适程度相应低(即受试者感到不舒适);风速、相对湿度、体重对受试者舒适程度的正面影响较明显,且随这些特征参数值的增大,SHAP 值相应增大,正面影响的程度增大。以体重为例,体重偏胖的受试者,对凉爽环境的舒适程度不敏感(即受试者感到舒适),这是超重的受试者身体脂肪绝缘增加的缘故[22]。

图3 特征参数SHAP值分布Fig.3 Distribution of characteristic parameter SHAP value
4 结论
基于XGBoost 分类算法建立一种热舒适预测模型,以受试者工作特征曲线下的面积(AUC)和准确率作为指标评估所建模型的性能,结果显示:所建模型的AUC 和准确率分别为0.95,89%,均优于随机素材、逻辑回归、支持向量机、神经网络等算法模型,表现出较高的预测整体性和准确率。利用SHAP 值对所建模型预测结果的影响因素进行解释,识别出影响个性化热舒适的关键因素是空气温度、相对湿度、空气风速、体重,其中空气温度与模型的输出负相关,风速、相对湿度、体重与模型的输出正相关。研究结果表明所建模型可对个性化热舒适进行预测,可为个性化空调的指标确定提供方法。
