数据中心网络四层负载均衡技术综述*
2022-01-24刘韵洁
李 力,汪 硕,黄 韬,刘韵洁
(1.东南大学网络空间安全学院,江苏 南京 211189;2.北京邮电大学网络与交换技术国家重点实验室,北京 100876;3.网络通信与信息安全紫金山实验室,江苏 南京 211111)
1 引言
由于提供了计算、存储等资源,数据中心承担着为越来越多的网络设备、用户和业务流程提供支撑和通信的重任,成为实体经济与网络融合的一个重要环节,也是我国新基建的七大领域之一。近年随着云计算和大数据的迅速发展,数据中心规模不断扩大,据思科全球云指数报告,全球超大规模数据中心的数量在5年内增长了2倍,数据中心IP流量则以27% 的复合年均增长率增长,现已达到了15.3 ZB的数量级[1]。云服务使得用户几乎在任何有网络的地方都可以通过多种设备随时访问内容和服务,这些访问请求最终都将汇集到数据中心,根据Alexa提供的网络流量排名,大型服务提供商如Google、Youtube、淘宝和百度将可能承担亿级的并发访问,因此国内外互联网巨头不断优化数据中心结构与功能。比如Facebook数据中心机器间的流量每隔不到一年的时间就以2倍的速度增长[2],Google在10年内将数据中心容量扩展了100倍[3]。
为了应对数据的指数级增长和高并发访问,大型数据中心都需要部署负载均衡模块,以处理来自外部或内部的巨大工作负载,提高资源利用率。负载均衡器涉及数据中心几乎全部的外部进入流量和一半的内部流量[4],因此负载均衡对托管在数据中心中的服务的性能至关重要。负载均衡器一般位于路由器和最终服务器之间,能够在一组后端服务器之间平均分配工作负载,有效处理客户向服务器发出的请求。四层负载均衡主要利用传输层的信息,如IP地址和端口,来将请求均衡分发到服务器集群的节点。在很长一段时间内,负载均衡器作为硬件存在于数据中心中,典型的商用负载均衡硬件有F5[5]、Array[6]和NetScaler[7]。但是,随着服务部署逐渐云化与虚拟化,应用程序变得更加复杂,基于软件的负载均衡得到了大规模使用。章文嵩等[8]于1998年创建和开发了Linux 虚拟服务器LVS(Linux Virtual Server)开源项目,将基于IP层的负载均衡调度方法集成到了Linux内核当中,这也成为了后续多个软件负载均衡器设计的基础。如阿里巴巴在LVS的基础上增加了完全网络地址转换FullNAT(Full Network Address Translation)的转发方式和SYN代理(SYNproxy),以进行SYN泛洪(SYN Flood)攻击的防御[9],爱奇艺DPVS[10]、京东SKYLB[11]和美团MGW[12]则通过内核旁路、数据平面开发套件DPDK(Data Plane Development Kit)[13]和零复制等技术实现了更高的转发性能。
国外的互联网巨头如Microsoft提出了Ananta[4],通过三层架构实现了负载均衡的可扩展性;Duet[14]和Rubik[15]则以软硬件混合部署的方式克服了软件负载均衡器高延迟的弱点;Google提出的Maglev[16]和Github提出的GLB[17]以绕过Linux内核的方式优化了软件负载均衡器的性能;Miao等[18]提出的SilkRoad在专用集成电路ASIC(Application Specific Integrated Circuit)交换芯片上实现了有状态硬件负载均衡器的设计,能够在服务器池频繁更新的情况下保证连接的一致性;Olteanu等[19]提出的Beamer和Araujo等[20]提出的Faild通过采用服务器侧路由重定向的无状态方案,防止遭受分布式拒绝服务攻击DDoS(Distributed Denial of Service)攻击;Barbette等[21]则是将状态信息以Cookie的方式存储于数据包中,并能采用有状态和无状态2种方式部署。近3年的负载均衡设计均采用了基于ASIC交换芯片的硬件部署方式,从而以低成本获取高转发性能,可见可编程交换转发技术是目前的研究热点和发展趋势。
2 四层负载均衡设计概述
2.1 四层负载均衡概述
按照IOS七层模型的划分,负载均衡可分为四层负载均衡和七层负载均衡。四层负载均衡使用传输层定义的信息作为如何在一组服务器之间分配客户端请求的基础,即仅基于数据包头中的五元组(源/目的IP,源/目的端口,协议)进行负载均衡决策,典型的有LVS。七层负载均衡可以检查请求的内容并根据应用层的信息将请求分发到不同的服务器,即通过应用层协议、URL、浏览器类别和语言等信息进一步进行负载分担,典型的有Nginx[22]和HAProxy[23]。
四层与七层负载均衡的区别主要如下:(1) 技术原理:前者使用五元组信息进行转发,后者本质是进行内容交换和代理,建立在前者的基础之上,对负载均衡设备的性能要求更高;(2) 应用场景:前者主要用于TCP应用,客户端与后端直接建立连接,后者广泛用于HTTP协议,需要负载均衡器与后端额外建立连接,虽然增加了网络灵活性,但对报头的检查将增加网络损耗;(3) 安全性:后者可以根据应用层信息设定多种安全过滤策略,对流量进行有效的清洗,前者的安全策略所采用的信息较少,但使用场景更为广泛,对设备要求不高,能进行高性价比的基础防御。
随着云与虚拟化的发展,数据中心的资源通常被拆分为多个虚拟主机VM(Virtual Machine)共同协调处理任务,网络服务运行在多个虚拟主机上,每个VM拥有一个直接IP DIP(Direct IP address),但对外仅提供一个或少量虚拟IP VIP(Virtual IP address)。用户通过VIP访问服务,流量到达负载均衡器后将被均匀分配到每一个后端实例上。图1是数据中心典型的三级负载均衡结构,为了实现大连接并发,划分多个服务实例进行负载分担,用户流量到达路由器后根据源IP进行等价多路径路由ECMP(Equal-Cost Multi-Path routing),实现流量的初步分配,数据包到达四层负载均衡器后再根据VIP、端口号和负载均衡算法选择后端实例,将目的地址从VIP转换为DIP,七层负载均衡器再根据URL等应用信息进一步进行内容交换或代理,最终将数据包转发到服务实例。

Figure 1 Structure of data center load balancing 图1 数据中心负载均衡结构图
2.2 四层负载均衡设计原则
在部署四层负载均衡时除了要考虑不同应用场景的特殊需求和方案性能之外,还需要考虑以下几项基本设计原则:
(1)连接一致性。数据中心网络需要不断处理故障,部署新服务,升级现有服务并对流量增加做出反应,文献[18]调研显示后端VIP服务升级将导致DIP池的频繁增加或删除,其中很多集群的DIP池每分钟将更新10次以上,因此需要保证连接一致性,以免影响服务能力。连接一致性指即使在DIP池发生更改的情况下,同一连接始终映射到同一后端实体。将正在连接的数据包发往不同的DIP会导致连接断开,应用程序需要几微秒到几秒的时间才能从断开的连接中恢复,这将导致无法提供99.9%或更高的正常运行时间以满足服务等级协议SLA(Service-Level Agreement)。
(2)可扩展性。文献[4]调研指出VIP流量约占数据中心总流量的44%,对于拥有4万台服务器的数据中心,负载均衡器需要处理约44 Tbps的流量。负载均衡器需要处理的流量会随着整体流量的增加而同步增加,纵向扩展模型使得部署者不得不以极高的代价更换更大容量的负载均衡设备,且更换过程较为复杂,因此通过添加更多类似的设备来获得更大处理能力的横向扩展模型更加符合实际应用。由于采用了负载均衡集群的方式,为保证连接一致性还需要在各负载均衡器之间进行数据同步,使得多个LB可以同时处理发往同一VIP的数据包。
(3)负载分配均匀。负载能否得到有效的分配取决于负载均衡算法,常用的负载均衡算法将在2.3节介绍。由于四层负载均衡的路由决策仅基于存储在网络数据包头中的信息,缺乏对流量的可见性,很难快速判定请求的性质,因此需要提前考虑负载生成情况和可用服务器资源,并在做出路由决策时进行一定程度的猜测。有效的负载均衡策略将提高数据中心的资源利用率,针对不同的应用场景与流量特性可以采取不同的均衡算法,因此在保证连接一致性的情况下四层负载均衡能够采取多种算法增加其使用场景与灵活性。
(4)故障无缝转移。负载均衡器是满足应用程序正常运行时间SLA的关键组件,需要在计划内和计划外的停机期间均保持可用性。因此,负载均衡需要支持具有故障转移机制的N+1备份模型来维护应用程序和保证服务的高可用性。在不中断活动流的情况下,所有系统组件都可以优雅地进入和退出服务,即系统中某一节点发生故障后,另一个节点可以接管其工作负载,现有架构的每个元素,包括主机、交换机和负载均衡器自身都能够无缝添加和删除。
2.3 四层负载均衡常用算法
负载均衡算法按其状态特点可以分为静态调度算法和动态调度算法[24,25]。静态调度算法提前确定调度策略,不考虑系统负载实时变化,常用算法如表1所示。动态调度算法将根据后端服务器的负载变化动态调整调度策略,常用算法如表2所示。

Table 1 Summary of static scheduling algorithms

Table 2 Summary of dynamic scheduling algorithms
不同算法将根据其特点应用于不同的场景,如静态调度算法常用于具有规律流特性的网络或较为简单的网络,WRR和WLC可用于多服务器异构集群,LBLC和LBLCR在内容分发集群中能获得较好效果。虽然上述算法各有其特性,但仍存在难以具化服务器处理能力、权值设定主观和连接数难以完全代表负载情况等问题。因此,在这些算法的基础上,还有研究人员提出基于动态反馈的均衡算法[26]、基于负载权值的负载均衡算法[27]、基于遗传算法的负载均衡算法[28]和基于神经网络反馈机制的负载均衡算法[29]等多种调度算法。
IP地址哈希法的缺陷在于服务器节点的数量变化将导致计算得到的后端节点变化,从而违反连接一致性。根据四层负载均衡需保持连接一致性的特性,目前广泛应用于四层负载均衡的调度算法为Karger等[30]提出的一致性哈希算法,该算法能够有效降低集群扩缩容和单点故障的负面影响。如图2所示,一致性哈希将哈希值映射到0~232-1的环形空间中,这些值将顺时针分配到第1个节点上,避免因单个节点退出而造成的大量数据迁移。
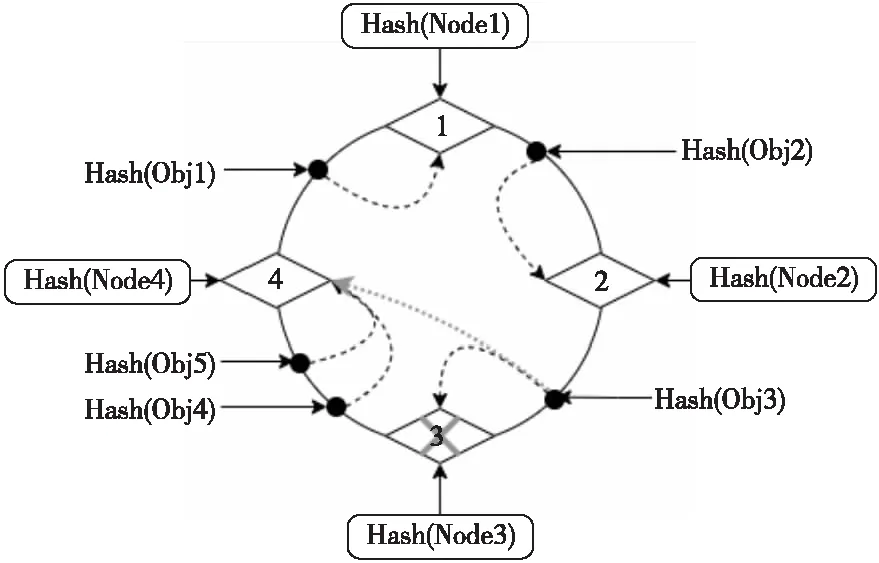
Figure 2 Consistent hash图2 一致性哈希
针对节点数量较少时易导致的不均匀性,Dynamo[31]引入虚拟节点的概念对一致性哈希进行了改进,文献[32]又提出虚拟节点的自我调整机制以减少计算开销,针对异构集群的应用场景,文献[33]提出了自适应的一致性哈希算法。
3 四层负载均衡技术应用
目前国内外已经存在多种四层负载均衡体系,负载均衡器可以作为硬件设备运行,也可以由软件定义。随着对云服务需求的增长,昂贵且难于扩展的专用硬件负载均衡器逐渐被替换为软件负载均衡器SLB(Software Load Balancer), SLB成本低、可用性高和灵活性强,但会存在一些延迟。如今,基于可编程芯片的交换机可替代SLB,同时还能降低成本、保证连接一致性,并提供更佳的性能。
3.1 基于软件的四层负载均衡体系
3.1.1 Ananta
Ananta是一个能满足多租户云环境、可横向扩展的软件负载均衡器。数据中心采用三级架构,包括顶层的路由器,运行在服务器中的软件多路复用器SMux(Software Multiplexers)和运行在每台服务器上的主机代理HA(Host Agent)。
图3为Ananta接受流量的路径图,顶层路由器通过ECMP将目的为VIP的数据包定向到某一个SMux,每个SMux通过边界网关协议BGP(Border Gateway Protocol)宣布自己成为所有VIP的下一跳,内部存储所有VIP到DIP的映射,并为VIP选择一个DIP,再通过IP-in-IP[34]协议封装数据包,将外部IP报头的目标地址设为选择的DIP。在服务器侧,由HA对传入的数据包进行解封装,重写目标地址和端口,最终发送到VM。HA还拦截VM传出的数据包,并将源IP从DIP重写为VIP,通过直接服务器返回DSR(Direct Server Return)将响应数据包转发回客户端。
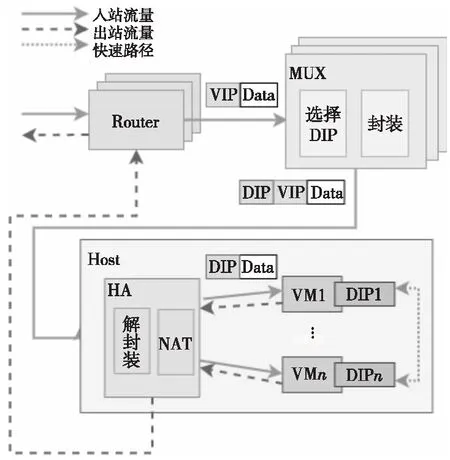
Figure 3 Data packet network flow in Ananta图3 Ananta数据包网络流向
尽管Ananta中的单个SMux的容量有限,但其可以通过扩展处理大量流量。第一,系统部署了多个SMux并通过ECMP划分流量,SMux将VIP到DIP映射存储在服务器主内存中,通过服务器的增加可以简单地进行扩展。第二,DSR使得负载均衡器不再处理响应数据包,确保只有传入流量或VIP流量才会通过负载均衡器,并且Ananta还采用了快速路径的机制来增强可伸缩性,即所有服务间流量转发直接使用DIP而非VIP,但这同时也抵消了使用VIP的好处,比如需要进行策略配置时只能使用数量极大的DIP而非VIP。
相较传统硬件负载均衡器,Ananta的设计主要解决了面对日益增长的流量负载均衡难以扩展的问题,虽然以软件的部署方式降低了成本,同时也增加了灵活性,但也会增加延迟并限制吞吐量,Ananta造成的延迟约为1 ms,且为了达到处理大流量的目的,需要部署的SMux数量约占数据中心规模的10%[14],这对现在的数据中心建设来说是不可接受的。
3.1.2 Maglev
Maglev是由Google公司开发的一个与Ananta一样运行在Linux服务器上的大型分布式软件负载均衡系统。图4为Maglev接受流量的路径图,流量从路由器通过ECMP到达Maglev,Maglev通过通用路由封装GRE(Generic Routing Encapsulation)[35]封装数据包后转发到最终服务器,最终服务器收到数据包进行解封装并使用DSR将响应数据包发回至客户端。

Figure 4 Data packet network flow in Maglev图4 Maglev数据包网络流向
Maglev将Ananta HA的网络地址转换NAT(Network Address Translation)功能用一个外部系统替代完成,取消了快速转发机制,并对单机性能进行了优化,主要方式是绕过内核,使其直接从网卡接收数据包,再用合适的GRE头部重写封装数据包后发回。处理过程如图4所示,Maglev收到数据包后首先计算五元组哈希并将数据包分配到不同的接收队列,实现批量并行处理,每个队列对应不同的包重写线程。Maglev维护一张连接表,该表存储现有连接的上次选择结果,以保证连接一致性。包重写线程执行以下操作:(1) 过滤掉没有匹配到任何VIP的包;(2) 再次计算五元组的哈希值并在连接表中查找;(3) 对于已建立的连接,如上次选择的后端可用,则将继续采用之前的选择,否则将根据一致性哈希重新选择后端,再将此结果加入连接表;(4)选择结束后以GRE头部进行封装发送到传输队列。
相较Ananta,Maglev的设计主要解决了基于内核的SLB会对网络性能造成损害的问题,其评估表示非绕过内核的设计吞吐量相较Maglev将少30%,且转发性能与网卡NIC(Network Interface Controller)有一定联系,在包重写线程数不足5时,吞吐量随着线程数增加,超过5时NIC将成为性能瓶颈,更高速度的网卡对吞吐量的提升不明显,因此Maglev难以适应更高速度的网络。
3.2 软硬结合的四层负载均衡体系
3.2.1 Duet
Duet是一个能够同时提供扩展性与高性能的负载均衡设计,通过将负载均衡功能嵌入到数据中心现有的交换机中,作为硬件多路复用器HMux(Hardware Multiplexer)实现了低延迟和高容量,并辅之一定数量的SMux以保证灵活性与可用性。之所以可以这样设计,是因为实现负载均衡器所需的流量拆分和数据包封装2个核心功能都能在交换机中实现,比如通过ECMP实现流量拆分,使用隧道技术实现数据包封装。
在虚拟化环境中,由于HMux无法2次封装数据包,因此还需要HA再次进行NAT,如图5所示。到达HMux的数据包将依次匹配3个表,首先匹配转发(forwarding )表,再根据IP 五元组的哈希值计算ECMP表的索引,每个索引对应一个隧道(tunneling)表中的DIP,最后再将匹配到的DIP封装为数据包的外部IP报头。由于交换机表容量有限,Duet将VIP到DIP的映射表划分到多个交换机上存储,并通过BGP使得目的为不同VIP的数据包路由到不同交换机处理。VIP到DIP的映射分布式存储在多个HMux的方式导致Duet难以在网络故障期间实现高可用性,因此SMux中将存储完整的连接表,在HMux不可用的时候进行功能迁移。
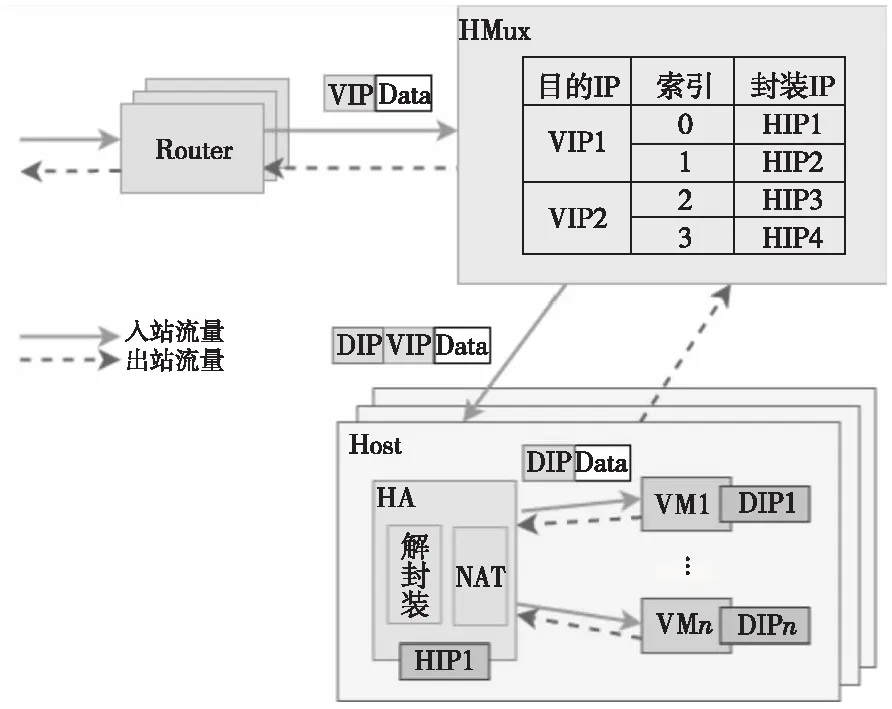
Figure 5 Data packet network flow in Duet图5 Duet数据包网络流向
相较SLB,Duet的设计主要是为了提升数据包转发的性能,同时提出了软硬件混合部署的架构,充分利用数据中心现有交换机的剩余能力,以此降低部署成本,并且其提供的容量增加了10倍,SMux的数量较Ananta减少了约87%,在SMux数量相同时延迟仅为Ananta的1/10甚至更低。Duet虽然提供了一定程度的故障转移能力,但HMux中的映射表会随着DIP池的频繁变化而变化,这将导致部分连接违反连接一致性。
3.2.2 Rubik
数据中心中的流量环回现象会大大增加数据中心网络的带宽使用率,不仅会造成成本增加,而且还容易导致网络出现瞬态拥塞,从而影响对延迟敏感的服务。为了减少重定向流量对链路利用的影响而提出了Rubik,Rubik同样使用HMux和SMux的混合设计,旨在最大程度地提高HMux能够处理的VIP流量,以降低成本。
Rubik设计时主要依据本地性和端点灵活性2个原则。本地性意在将负载均衡器更加靠近源和将要选择的后端,由于VIP流量的不平衡性,即对于特定的VIP,不同机顶ToR(Top of Rack)交换机产生的流量规模不同,从而可以在同一ToR交换机的后端集群平衡特定VIP流量,这将减少进入核心网络的总流量。端点灵活性意在使将要选择的后端更加靠近源,根据不同VIP对应的后端集群的规模,Rubik将通过分配算法决定每个VIP对应后端的位置,使其与产生VIP流量的源ToR交换机更接近。
Rubik能够最大程度地将流量负载均衡控制在单个ToR交换机内,总带宽使用量约为Duet的1/3,在总流量一致时(97%),最大链路利用MLU(Maximum Link Utilization)约为Duet的1/4,同时提供可扩展性和可用性优势,虽然Rubik进行了性能上的优化,但同样存在违反连接一致性的问题。
3.3 基于硬件的四层负载均衡体系
3.3.1 SilkRoad
SilkRoad是一个基于可编程交换机芯片的有状态负载均衡设计,其目的是应对流量激增与保证一致性,由交换机直接完成负载均衡的功能。SilkRoad部署于可编程协议无关P4(Programming Protocol-Independent Packet Processors)[36]交换机中,交换机的流水线(pipeline)可以维护多张表并执行匹配-动作(match-action)的操作,匹配项及对应动作均可自定义。
图6显示了系统中数据包的处理过程,数据包首先到达连接表,为了节约有限的片上存储,匹配字段为五元组的哈希摘要,表项匹配则转入DIP池表选择DIP并封装转发;反之,则说明需要建立新连接,匹配VIP表选定版本号并转入DIP池表,随后在连接表中插入新连接的状态,由于插入之前后续数据包就会到来,此时DIP池更新将破坏连接一致性,于是采用Transit表维持等待中的连接。Transit表采用了寄存器的方式来保证原子性,并使用布隆过滤器(Bloom Filter)进行成员资格检查,以区分新旧DIP池版本,若匹配则说明该DIP池的更新还未完成,使用旧版本号选择DIP。
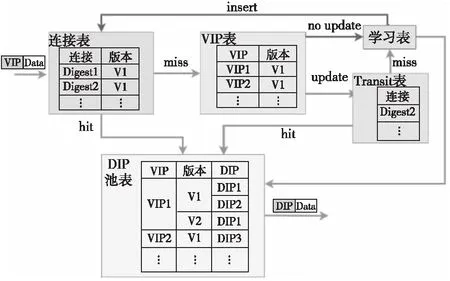
Figure 6 Data packet network flow in SilkRoad图6 SilkRoad数据包网络流向
单个基于ASIC交换机的负载均衡器可以替代数百个SLB,并将成本降低2个数量级以上,解决软件处理数据包导致的开销高、抖动和延迟高的问题。而Duet和Rubik将负载均衡功能建立在不能进行连接跟踪的传统交换机上,因而需要软件辅助完成,可编程交换机的出现使得两者得以集成,使其可以同时具有高性能与灵活性。SilkRoad虽然可以平衡约一千万个连接,但这在面临流量激增和DDoS攻击时依然显得不足,而外加存储设备又可能导致转发性能的下降,因此其适用性还需进一步验证。
3.3.2 Beamer
存储每个连接的状态并做出负载均衡决策的设计虽然易于实施,但存在服务器或负载均衡器扩展导致连接断开、因泛洪攻击而无法维护连接状态,有状态SLB吞吐量大幅降低等问题。Beamer是一个无状态可扩展的负载均衡设计,利用已经存储在后端服务器中的连接状态来重定向数据包,以保证连接一致性。
图7为Beamer处理数据包的过程,为了克服原哈希算法的缺点,Beamer设计了一个由固定数量的桶(bucket)组成的中间层,若服务器发生增减则通过在ZooKeeper[37]中存储新的映射来完成桶的迁移。Beamer为每个桶保存先前选择的后端DIP PDIP(Previous Direct IP address)及重新分配的时间TS (TimeStamp),当到达服务器的数据包非SYN或不属于本地连接时,将根据数据包头中封装的TS判断是否将数据包转发到之前的后端,最终使得新服务器可以处理新连接,已建立连接仍由先前的服务器处理。

Figure 7 Data packet network flow in Beamer图7 Beamer数据包网络流向
Beamer可以采用FastClick[38]或者P4交换机[39]2种部署方式,使用稳定哈希算法和Daisy chaining技术保证连接一致性,包处理速度相较SLB提升了2倍,面临网络故障和服务器增减时其吞吐量都能进行平滑过渡。Beamer无状态的设计虽然减轻了负载均衡的处理与存储压力,但Daisy chaining导致的服务器间频繁的流量重定向也会增加服务器开销。
3.3.3 Faild
Faild是一个针对内容分发网络CDN(Content Delivery Network)的无状态负载均衡设计,此场景下数据中心物理空间受到很大限制,需要更高效率的负载均衡机制来最大程度地吸收DDoS攻击,实现无缝故障转移,从而降低服务维护对可用性的影响,Faild主要通过交换机封装状态信息和主机端重定向实现。
图8为Faild处理数据包的过程,交换机维持FIB(Forward Information dataBase)表和ARP(Address Resolution Protocol)表,FIB将VIP映射到一组固定的虚拟下一跳,以此绕过路由表来避免连接重置。ARP表中每个下一跳IP地址都对应一个扩展MAC地址,该地址由控制器根据服务器状态通过一致性哈希算法进行修改,包含当前和之前选择的后端信息。主机端收到数据包后判断两者信息是否一致,不一致则将非首次建立的本地连接数据包重定向至之前的后端处理。

Figure 8 Data packet network flow in Faild图8 Faild数据包网络流向
Faild使数据中心任意组件的移除都不会影响现有连接,流量绕行也不会引起较高延迟和主机端的CPU开销,相较Beamer,Faild有明确的使用场景,但性能较差,且其数据平面查找表的配置依赖供应商的应用程序编程接口API(Application Programming Interface)来完成,同样只能进行一次重定向,无法应对同一DIP的多次改变。
3.3.4 Cheetha
基于哈希的算法注重保证连接一致性而非负载分担的均匀性,Cheetha是一个可部署任何负载均衡算法并保证一致性的负载均衡机制,可以无状态和有状态2种方式部署,设计的核心是将连接的状态信息编码于cookie中。
图9为Cheetha无状态设计中数据包处理过程,对于SYN包,首先根据VIP与均衡算法进行选择与转发,然后服务器将server id与五元组加密哈希的异或结果作为cookie加入数据包;对于后续的数据包,Cheetha将cookie与五元组加密哈希异或后得到server id与DIP。Cheetha有状态设计维护多个连接表,通过SYN包的五元组加密哈希建立表项并添加cookie到数据包头中,后续数据包通过cookie快速索引,由于可建立连接的数量与cookie的大小有关,因此采用了分区与cookie重用的策略。

Figure 9 Data packet network flow in Cheetha图9 Cheetha数据包网络流向
Cheetha同样可以采用FastClick和P4交换机2种方式部署,具有可扩展性、高内存效率、快速的数据包处理能力和针对阻塞攻击的恢复能力。无状态版本的流量完成时间FCT(Flow Completion Time)约为利用DPDK或接收端缩放RSS哈希的30%~50%,有状态版本增加了流的可见性,连接跟踪使其可以完成更复杂的网络功能。哈希过程中使用的密钥仅由负载均衡器维护,对服务器侧不透明,从而防御恶意流量。cookie使得表项的增删改查只需在数据平面进行,但cookie会被附加在每个请求中,无形中增加了流量。
4 四层负载均衡体系比较
4.1 四层负载均衡器性能衡量指标
(1) 部署成本与难度:主要依据是否能有效利用现有设备。软件易于部署,适应性强,且成本较低;硬件一般具有更高的设备成本和维护成本,且较难与现有架构相适应。
(2) 可靠性:主要包括是否满足连接一致性与故障转移。在节点频繁更新时违反连接一致性的连接个数将是评价服务质量的重要指标,因为这将会导致服务延迟增加甚至会话的重新建立;LB的增加和退出可能导致部分连接状态丢失,在此过程中的连接数、吞吐量等也应当得到平滑的过渡。
(3) 转发性能:主要包括连接并发数、吞吐量和转发时延。当流量到达负载均衡器时,不同设备和均衡算法的处理时间不同,小并发数、低吞吐量或高延迟将导致负载均衡器成为整个服务提供中的性能瓶颈。
(4) 负载平衡性:主要判断节点负载分配是否均匀。节点的负载率为节点当前负载与节点能力的比值,而节点的性能指标则包括CPU使用率、内存使用率和磁盘I/O活动时间等,各节点的负载率越接近负载平衡性越高。
(5) 安全性能:主要判断LB对恶意流量的防御能力。判断标准包括应对恶意流量时节点负载率、CPU消耗、占用内存和攻击响应时间等,高效益的LB在分配流量时能够进行安全防御而减少专用安全设备的成本。
4.2 负载均衡方案性能比较
结合文献[20,40,41]对部分负载均衡方案的总结,本文将从部署方式与性能2个角度对各方案进行比较,结果如表3所示。负载均衡模块能够以软件、硬件或软硬结合的方式部署,为了克服SLB的性能弱点,可通过将封装与分流的功能卸载到交换机处理,或者通过DPDK、零拷贝等方式进行优化,加速数据平面转发。传统交换机结合软件的混合架构被证明可行,同时创新地使用可编程转发芯片构建低成本高性能的负载均衡器也成为可能,但要融入现有架构还需要一段时间。
以负载均衡模块是否维护每个连接的状态分为有状态和无状态2种方案,状态可存储于承担负载均衡功能的服务器或可编程交换机中。有状态方案均衡算法一般利用一致性哈希或五元组哈希值进行ECMP,结合维护在负载均衡器中的用户状态以实现一致性,也因此得以实现更为复杂的网络功能。无状态方案均衡算法同样采用哈希和ECMP,但借助可编程转发技术或Cookie等手段将用户状态存入数据包中,再由服务器对数据包再次处理,如修改协议栈、路由重定向和创建Cookie等操作,从而实现连接一致性,因此将增加额外开销。此外,上述方案大多是一致性哈希的优化算法,Cheetha[20]能够自由选择更适应流量特征的均衡算法,从而提高了负载平衡性。
在性能方面:(1)负载均衡系统的瓶颈一般受限于其部署架构和平台,如交换芯片内存、交换机和服务器的性能,对于利用特殊结构或算法维护状态的方案,性能取决于算法的逻辑设计,如Daisy chaining引发的重定向、Cookie大小影响的连接数等;(2)硬件架构通常具有更快的速度和更低的延迟,SLB将为每个数据包增加50 μs到1 ms的处理延迟[20];(3)当负载均衡器出现故障,上层交换机将流量分配至备份负载均衡器处理,有状态方案可能因连接表丢失而造成中断连接,且目前还未出现基于可编程交换机的负载均衡集群方案,能否实现集群连接表同步还需进一步研究;(4)保存状态使得负载均衡器难以防御DDoS这样资源耗尽类的安全攻击,因为其无法判断当前连接性质,大量短链接的建立将很快耗尽设备内存,虽然可以针对连接做出超时时间的设定,但仍无法面对DDoS攻击数量和规模持续增加,文献[42,43]还提出了负载均衡与DDoS检测、缓解相结合的技术,值得进一步研究该技术与四层负载均衡方案的适配性。
4.3 展望与未来研究方向
4.3.1 负载均衡算法优化
负载均衡算法是能否保证负载均衡分配的核心,现有方案采用多种手段对一致性哈希进行优化,将连接分配给后端实例而忽略了服务器实际负载。一致性哈希旨在保证连接一致性而非均衡性,因此它既不能根据后端服务器的能力与负载合理分配请求,也无法根据流的大小动态分配流量,以达到更好的平衡。
服务实例之间的负载不均衡是导致负载均衡系统出现额外处理延迟的主要原因,现在的解决方案如流量重定向将增加约12.48%的额外流量[44],连接跟踪则会消耗大量内存,从而导致网络资源使用效率低下。针对此问题,服务器状态感知和拥塞状态感知的负载均衡系统也不断出现[45 - 48],通过周期性地探测、上报和调整权值,在满足连接一致性的同时,实现服务实例之间的负载均衡分配和最佳网络资源使用。虽然通过感知后端服务器负载可以在一定程度上缩减流完成时间,但预估流的大小并进行区分仍然是四层负载均衡的处理难点。

Table 3 Comparison of load balancing schemes
4.3.2 可编程转发技术
为了克服传统网络硬件更新周期长、灵活性差的缺点,可编程转发技术提出了一种高效益管理的网络抽象,使网络管理者可针对使用场景自由设计协议,而不依赖交换机开放的接口,因此利用成本较低的可编程交换机实现各项网络功能包括负载均衡已成为当下的研究趋势。
传统SLB一般通过现有的IP-in-IP、GRE和通用UDP封装GUE(Generic UDP Encapsulation)[49]等隧道技术将选择的DIP封装为外部包头,并由主机端完成解封装和NAT的过程,可编程转发技术使负载均衡功能可直接在转发平面定制,完成更加复杂的均衡决策。虽然目前可编程交换机还未大量部署,但随着可编程转发设备可存储和维护的信息量与使用性的提升,将促进多功能、高性能的负载均衡方案的产生。
数据中心越来越多地使用智能网卡Smart NIC(Smart Network Interface Controller)[50]支持网络虚拟化和特定于应用程序的任务,其专用的加速器和可编程的处理核心,使从通用CPU上卸载日益复杂的数据包处理任务[51,53]成为可能。基于P4语言的Smart NIC[54]也已经出现,如何基于现有及新架构的负载均衡模块卸载到智能网卡将是日后的研究热点之一。
4.3.3 人工智能与机器学习技术
数据中心网络中,负载均衡机制本质上是对流的调度,其设计受制于网络应用场景与流量特性,而对动态系统中未来事件的预先了解通常可以提高系统的性能和效率[54],如通过提前获取流大小的信息将使负载均衡决策更加合理。企业集群中超过60%的工作是周期性的,具有可预测的资源使用模式,因此可以结合机器学习技术,通过分析与归类历史流特征构建学习系统,实现根据流特性的负载决策。
软件定义网络SDN(Software Defined Network)场景下特有的流表特性提供了大量包含网络信息的数据,使机器学习技术在数据分析和挖掘方面得以利用,如分析结果可用于负载均衡决策和恶意流量识别。负载均衡技术被证明能够有效抵抗DDoS攻击[56],基于分类算法的流特征分析也被用于负载均衡系统[42]中,以应对不同类型的流量攻击,因此结合机器学习和人工智能技术的数据中心网络负载均衡方案是未来研究的一个热点。
5 结束语
流量激增使数据中心需要有效的负载均衡机制来处理高并发访问,提高资源利用率。负载均衡有软件、软硬结合、硬件3种不同的部署方式,基于服务器的软件负载均衡成本低,能够灵活实现多种网络功能;软硬结合架构充分应用交换机的剩余能力,实现了高性能的转发;基于可编程转发技术的交换机兼具灵活性与高性能,并在近年得到多种实现,但还未大规模投入生产使用,且在数据平面转发、均衡算法与安全防护等方面还需进行优化。
