基于表征学习的模拟电路故障诊断*
2022-01-24谈恩民
谈恩民,王 晨
(桂林电子科技大学电子工程与自动化学院,广西 桂林 541004)
1 引言
随着电子工业的快速发展,电路故障诊断在工业系统的可靠运行和工业系统维护中起着至关重要的作用。大规模电路技术发展至今,虽然数模混合电路占整个电路的比例约为60%,且混合信号电路中模拟电路所占比例为20%,但当电路发生故障时,模拟电路发生故障的比例却达到了80%[1]。
模拟电路故障诊断的主要任务就是在已知网络拓扑结构、激励信号和故障响应条件的情况下找到故障的位置[2]。然而,由于故障模型复杂,元件容差,非线性以及被测点难以选取等问题,使得故障很难检测和诊断,从而造成了电路系统的不稳定以及电路芯片的高成本。因此,对模拟电路故障诊断技术的深入研究就显得尤为重要[3]。
模拟电路故障诊断的主要模型是:信号处理+分类器[4]。目前主要的信号处理方法有小波分析法[5]、主成分分析法[6]和经验模态分解EMD(Empirical Mode Decomposition)算法[7],经常使用的分类算法有支持向量机SVM(Support Vector Machine)[8]和极限学习机ELM(Extreme Learning Machine)[9]等。常用的优化算法有粒子群算法[10]、正弦余弦算法[11]、蚁狮算法和果蝇算法[12]等。SVM主要用于将复杂的非线性问题转化为极为简单的二次寻优问题,通过 SVM 对所描述问题的求解,绕开了很多智能算法不能直接求解局部极值的问题[13]。ELM能够克服BP(Back Propagation)算法所面临的一些挑战,它可以提供更好的泛化性能和通用逼近分类能力,具有极快的学习速度。虽然上述算法都已经成功应用于模拟电路故障诊断,但是当故障信息中特征较多时,难以对数据特征进行选择提取,从而达不到预期的效果。
随着时代的发展,表征学习的出现使得数据处理更加容易,它的主要工作是通过数据的转换设计来获得有意义的数据特征表示。因此,本文提出了一种基于H-DELM(Hierarchical Deep Extreme Learning Machine)的模拟电路故障诊断模型。该模型直接将原始故障数据作为H-DELM的输入,不需要对数据进行单独的信号处理和筛选,就可以快速地实现故障诊断。而且传统的神经网络算法在训练中需要设定很多参数,而H-DELM的基本单元是DELM-AE(Deep Extreme Learning Machine Auto-Encoder),对于DELM-AE的训练只需要设置2个参数:隐藏层节点数L和正则化参数C。最后通过2个实验电路表明此模型具有分类准确率高、鲁棒性强、学习速度快等优点,在模拟电路诊断中具有重要的研究意义。
2 极限学习机
2006年Huang等[14]首次提出了极限学习机ELM的概念,ELM是一种简单的具有3层结构的SLFN(Single-hidden Layer Feedforward neural Network)[15],其中包括1个输入层、1个隐藏层和1个输出层。ELM的基本思想是随机初始化隐藏层的参数,通过特征映射将输入数据从输入空间转换到高维隐藏层空间,而输出参数通过ELM学习算法进行确定。ELM网络结构如图1所示。

Figure 1 Network structure of ELM 图1 ELM网络结构图

H=g(X;W,b)=
(1)
其中,(wi,bi)是第i个隐藏层节点参数,W=(w1,w2,…,wL)是从输入层节点到隐藏层节点的输入权重矩阵,隐藏层偏置b=(b1,b2,…,bL),隐藏层参数(W,b)可以根据任意连续的概率分布随机分配。在这里,g(x)是激活函数。通常,g(x)可以是任何非线性分段连续激活函数。
标准ELM试图以零误差逼近这些样本,可以写成如式(2)所示的矩阵形式:
Hβ=T
(2)
其中,H∈RN×L是隐藏层输出矩阵,β∈RL×m是输出权重矩阵,T是训练数据目标矩阵。
(3)
ELM的目标是同时最小化训练误差和输出权重范数,以提高稳定性和泛化能力,如式(4)所示:

(4)
其中C表示正则化参数,控制训练误差与模型复杂度之间的权衡,通过ELM对β的梯度设置为零,可以得到β的以下解:
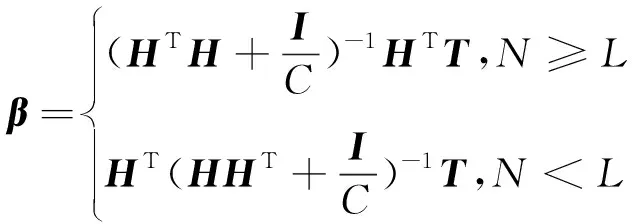
(5)
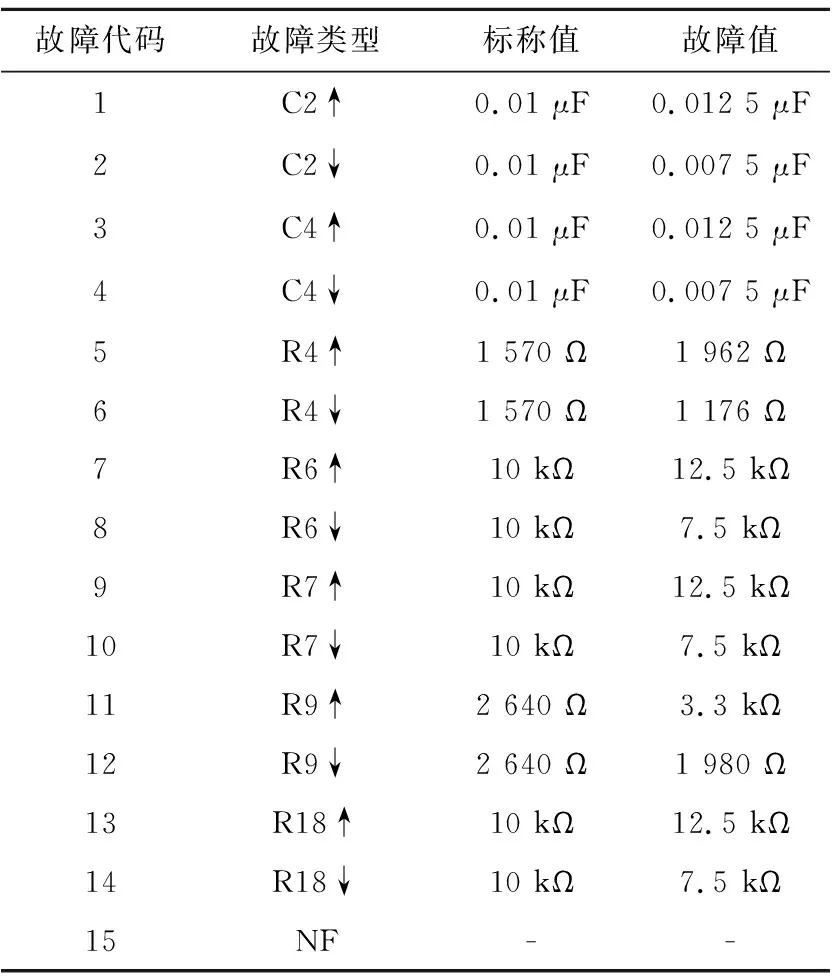
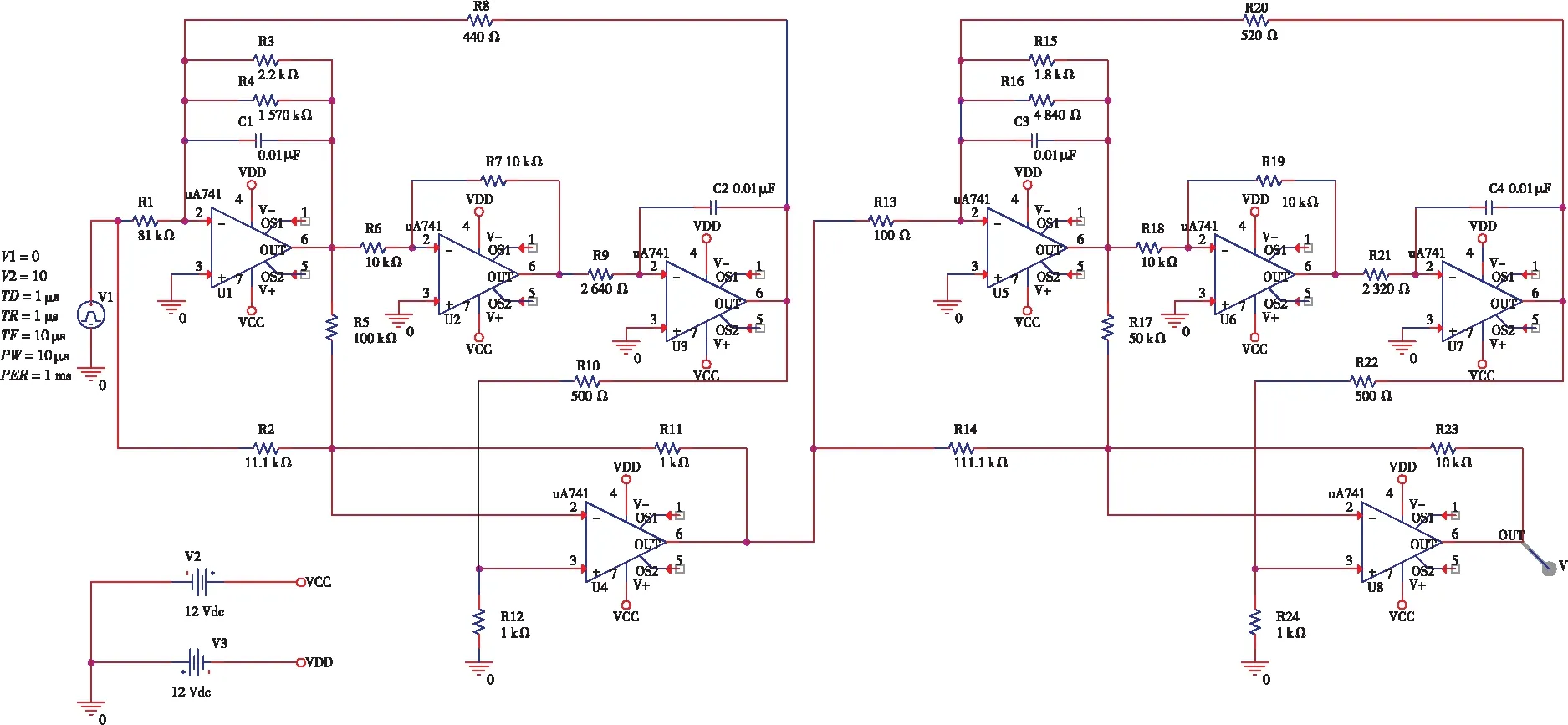
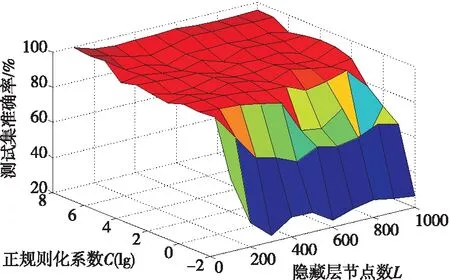
其中I为单位矩阵,如果N≥L,I的维数为L,如果N 训练ELM可以概括如下: (1)随机分配隐藏层输入权重W和偏置b; (2)计算出隐藏层输出矩阵H; (3)根据式(5)计算出输出权重β。 综上所述,ELM可以在随机生成隐藏层参数后确定输出权重,而且可以提供稳定、高效的解决方案。 当ELM-AE(Extreme Learning Machine-Auto Encoder)[17]逐层堆叠形成深度ELM-AE时,当前ELM-AE的输入是前一个学习ELM-AE的特征码,并且输出与输入相同[18]。ELM-AE是一种尽可能再现输入的神经网络,所以深度ELM-AE作为深度学习框架中的特征提取器是合理有效的,但如果在前几层存在错误,则该模型将无效。因为先前的ELM-AE学习的特征信息只保留了原始数据信息的一部分,后面的ELM-AE只是尽可能多地复制以前的特征代码,进而深度ELM-AE会形成累积误差,使学习后的特征不能更好地表达原始信息,这将导致深度模型的性能下降。 因此,对ELM-AE的第1个改进是将其输出修改为原始信息,并且输入仍然是先前ELM-AE学习的特征码,称此模型为单随机隐层ELM-AE SELM-AE(Single random hidden layer Extreme Learning Machine-Auto Encoder),如图2所示。因此,在SELM-AE表征学习的过程中,它可以学习基本特征来重构原始信息,且特征信息与原始信息更相关、更具有表现力。 Figure 2 Network structure of SELM-AE 图2 SELM-AE网络结构 通常,高维空间中的样本数据不能在整个空间中扩散,它们位于一个嵌入在高维空间中的低维流形中,流形的维数是数据的内在维数[19]。另一方面,因为高维空间显著地增加了数据的存储和计算需求,所以研究人员实际上希望达到降维效果,即希望得到输入的压缩表示。然而在降维的过程中,丢弃某些维度会不可避免地导致信息的丢失。 SELM-AE可以看作是一种转换表示的方法,主要目标是用以下2种不同的方式进行表示。当输入层节点数小于隐藏层节点数时,可以将输入数据从低维表示空间转换到高维表示空间,特征表示可以称为扩展数据维度。相反,当输入层节点数远远大于隐藏层节点数时,可以将高维输入数据映射到压缩的特征空间,特征表示可以称为压缩数据表示。 综上原因,本文设计了一种新的网络模型DELM-AE,在ELM-AE的基础上增加了一个隐藏层。如图3所示,双随机隐藏层用于编码特征,一个输出层用于解码特征。首先,将较低维的数据随机映射到高维表示空间,得到扩展维数数据,然后将特征从高维空间随机变换到低维空间,得到压缩后的特征,即学习的特征代码。DELM-AE的输出与原始输入信息相同,目标是计算输出权值。因此,在DELM-AE表征学习的过程中,它可以作为基本单元,它的2个变换表示可以实现更多完整的特征,以保存更多的信息,进而实现训练的快速性。此外,DELM-AE训练算法类似于SELM-AE的训练算法。 Figure 3 Network structure of DELM-AE 图3 DELM-AE网络结构 训练DELM-AE的过程如下所示: 假设输入数据矩阵X、惩罚系数C和隐藏层节点数L,目标是计算输出权重β。 (1)随机分配第1个隐藏权重w1,偏置b1(第1层的偏置矩阵),并计算第1隐藏层输出矩阵H1。 (2)随机分配第2个隐藏权重w2和偏置b2,并计算第2隐藏层输出矩阵H2。 (3)根据式(6)求出权重: (6) 以上介绍了2种基本模型SELM-AE和DELM-AE的网络结构,可以通过层叠SELM-AE和DELM-AE,分别形成H-SELM和H-DELM模型。如图4所示为H-DELM的训练过程,它逐层学习数据特征,以尽可能地重构原始信息。 Figure 4 Network structure of H-DELM 图4 H-DELM网络结构 H-DELM网络结构由2部分组成:(1)用于无监督特征提取的多层DELM-AE;(2)用于监督特征分类的ELM。 H-DELM训练网络结构由2个阶段组成 : (1)分离阶段:无监督的多层表示学习和监督特征分类。在前一阶段,采用堆叠DELM-AE层形成一个H-DELM-AE,它将原始输入转换成更高级别的表示。随着层的增加,学习的特征变得更有表现力和紧凑。注意,由于每个DELM-AE的输出始终是原始输入数据X,当得到每个DELM-AE的结果基β时,相应的特征表示是: (7) 其中,f为学习到的特征缩写。H-DELM-AE无监督特征提取是一种通过子空间或投影映射函数来保存数据空间的几何结构。 (2)分类阶段:在获得最终的特征之后再通过ELM来获得最终分类结果。 由于H-DELM的无监督多层DELM-AE可以重现更多紧凑数据的表征学习,故不需要进行单独的信号采集,只需要把样本数据输入到H-DELM中进行测试和训练,如图5所示,具体包括故障样本数据采集、添加标签、数据标准化、构造样本和故障分类5个步骤。以下所有实验环境均为CPU为英特尔酷睿3.5 GHz,内存为8 GB的台式机上,所使用的软件为Candence 16.5和Matlab 2014a。 Figure 5 Fault diagnosis process of analog circuit using H-DELM图5 H-DELM模拟电路故障诊断流程 4.1.1 诊断电路及故障参数设置 本节选取四运放双二次高通滤波器电路作为验证对象,电阻和电容的容差分别为5%和10%。电阻故障范围是[50%X,95%X]∪[105%X,150%X],电容故障范围是[50%X,90%X]∪[110%X,150%X],其中X为元件的标称值。电路图如图6所示,经过灵敏度分析,故障敏感元件为C1、C2、R1、R2、R3。构建单故障集为{R1↑,R1↓,R2↑,R2↓,R3↑,R3↓,R4↑,R4↓,C1↑,C1↓,C2↑,C2↓,正常},共13种状态,↑和↓分别表示高于或者低于标称值的50%,具体设置参数如表1所示。 Figure 6 Quadruple operational amplifier double-order high-pass filter circuit图6 四运放双二次高通滤波器电路 对实验电路施加的激励信号参数如图6所示,选取OUT点为被测节点。对表1所示的故障类型分别进行200次蒙特卡罗MC(Monte-Carlo)分析,采集2个周期内(2 ms)的输出端波形并保存,提取出原始数据。针对每个故障样本,取前400个故障输出端电压,这样每个故障都能获得200个400维的样本,构成的总样本集X∈(200,400),构成200×400的矩阵。对故障样本添加标签,采用二进制编码,故障样本标签如表1所示,然后从中随机选取80%作为训练样本,20%作为测试样本。 Table 1 Single fault code and type 4.1.2 故障诊断结果分析 针对四运放双二次高通滤波器电路,将本文的模型与近几年较好的模型相比较,模型所使用的环境设置相同。由表2可以看出,各类模型的分类准确率都比较高,但准确率都没有达到100%。由于此电路的复杂程度高和故障样本数量较多,文献[10,11]的模型诊断时间变得很长,分别达到了71.440 s和38.310 s。文献[8]模型与文献[10,11]模型相比,诊断时间较短,诊断率较高,但文献[8]的模型优化过程过于复杂。相比之下,H-SELM以及H-DELM的分类准确率均可以达到99%以上,甚至H-DELM可以达到100%。此模型多增加了一层随机隐藏层,增强了其有效特征提取的能力,且分类时间很短,在1 s左右,在诊断时间和准确率方面均优于其他与之对比的模型。由此说明了表征学习方法在模拟电路故障诊断中的泛化能力、快速性和有效性。 Table 2 Comparison of fault diagnosis results 4.2.1 诊断电路及故障参数设置 为了检验模型的通用性,本节选取更复杂的二级四运放双二阶低通滤波器电路作为验证对象,电路图如图7所示,因为该电路比图6所示电路更加复杂,当电路前级稍微发生一点故障,后级电路都会将故障放大。 电阻容差为5%和电容容差为10%。元件参数偏离标称值±25%时,定义为软故障。经过灵敏度分析之后可知,故障敏感元件为C1、C4、R4、R6、R7、R9、R18,从而构建单故障集为{C2↑,C2↓,C4↑,C4↓,R4↑,R4↓,R6↑,R6↓,R7↑,R7↓,R9↑,R9↓,R18↑,R18↓,正常},共15种故障模式。↑和↓分别表示高于或者低于标称值的25%,故障参数如表3所示。 Table 3 Fault code and type 对实验电路施加的激励信号参数如图7所示,选取OUT点为被测节点。对表3所示的故障类型分别进行100次MC分析,采集300 μs内的输出端波形并保存,提取出原始数据。针对每个故障样本,取前195个故障输出端电压,这样每个故障都能获得100个195维的样本,一共有1 500个原始故障样本。对故障样本添加标签,采用二进制编码,即故障1的标签为100000000000000,依此类推,然后按4∶1比例随机选取训练样本和测试样本。 Figure 7 Two-stage four-op-amp biquad lowpass filter circuit图7 二级四运放双二阶低通滤波器电路 4.2.2 故障诊断结果分析 为了验证本文模型的有效性,对图7采集到的单故障样本分别进行故障诊断,通过对测试集的分类准确率来评判H-DELM和H-SELM的性能。与传统的神经网络训练模型相比,H-DELM和9H-SELM只需要设置2个参数:隐藏层节点数L和正则化参数C。为了公平起见,对2个模型设置类似的结构,H-SELM模型的网络节点数为196-200-150-100-13,H-DELM模型的网络节点数为196-(400-200)-(300-150)-100-13。在实验中,C的变化范围设置为[0.01,0.1,1,…,108],L的变化范围设置为[100,200,…,1000]。H-SELM与H-DELM的三维精度曲线分别如图8与9所示。 Figure 8 Testing 3D accuracy curves in (C,L) subspace for H-SELM图8 H-SELM在(C,L)子空间中的三维测试精度曲线 Figure 9 3D accuracy curves in (C,L) subspace for H-DELM图9 H-DELM在(C,L)子空间中的三维测试精度曲线 由图8和图9可知,对于H-SELM,测试精度在6.33%~99%,平面曲折,对参数非常敏感,但是当C比较大时,测试精度还是比较高。而对于H-DELM来说,测试精度在23.67%~100%,虽然也受到参数的显著影响,但是平面比较平滑,说明对参数的鲁棒性更强。由此可以看出,将ELM-AE的输出更改为原始信息和DELM-AE的2个随机隐藏层编码特征都能提高系统的鲁棒性。由图8和图9知,C和L都影响着模型的诊断精度,但是相比之下,模型对参数C更敏感。C和L对模型的性能有不同的影响,实际上需要仔细选择C,C较小会在训练误差中加轻处罚,导致模型性能不佳;C较大将产生较小的误差,但会导致过拟合。C对模型的性能有较大的影响,故应该选择一个相对大的C。虽然L对模型性能影响不是很明显,但也应该根据实验以及经验进行调整。 单故障测试集分类结果如表4所示,将本文模型与PSO-GMKL-SVM、DBN、PSO-ELM进行对比。 Table 4 Comparison results of diagnostic models 由表4可以看出,本文提出的H-SELM与H-DELM的单故障诊断分类准确率分别达到了99.6%与100%,诊断时间均在1 s左右,并且对复杂电路的诊断率和诊断速度都优于其它与之对比的模型。虽然此电路的结构比较复杂,但是表征学习方法的故障诊断率和诊断速度并没有降低。由此说明本文的表征学习方法可以提取出故障数据的高级特征,有助于故障识别。 本文采用了一种新的表征学习方法对模拟电路故障进行诊断。通过DELM-AE进行表征学习,它是一种双隐层ELM-AE,2个随机隐藏层用于编码特征,1个输出层用于解码特征。在DELM-AE中,节点数较多的第1个隐藏层用于随机变换,而节点数较少的第2个隐藏层用于表征学习。当DELM-AE按层次结构叠加形成H-DELM时,当前隐藏层的输入是前一个DELM-AE学习到的特征码,但输出总是与原始输入数据相同。因此,H-DELM可以尽可能地再现原始输入数据,以更快的训练速度学习更具表现力的紧凑特征。通过2个复杂电路进行了实例验证,结果表明,H-DELM可以提供与其他模型相当甚至更好的性能。此外,H-DELM具有分类准确率高、鲁棒性强和学习速度快等优点,在实际应用中具有重要的意义。3 H-DELM模型
3.1 SELM-AE

3.2 DELM-AE



4 H-DELM的模拟电路故障诊断

4.1 四运放双二次高通滤波器电路



4.2 二级四运放双二阶低通滤波器电路


5 结束语
