基于一维卷积神经网络的糖尿病周围神经病变预测模型研究
2022-01-24侯伟赵耕刘玉良杨伟明郭丽
侯伟,赵耕,刘玉良,杨伟明,郭丽
1.天津科技大学电子信息与自动化学院,天津 300222;2.天津医科大学代谢病医院检验科,天津 300070
前言
目前,糖尿病是全世界已知的并发症最多的疾病,对人类健康造成了很大的影响。临床研究显示,30%以上的患者会在糖尿病确诊以后的几年内,引发糖尿病并发症,而且可能出现不止一种并发症[1],糖尿病并发症患者的死亡率比只患有糖尿病患者的死亡率要高,所以更应该引起足够的重视[2]。其中,糖尿病周围神经病变(Diabetic Peripheral Neuropathy,DPN)作为糖尿病慢性并发症中最常见一种,会导致患者出现一系列周围神经功能障碍症状,而且下肢症状比上肢更常见[3]。60%~90%的糖尿病患者有不同程度的DPN 并发症,其发病机制目前尚不明确,并且很难通过药物根治,甚至会对身体造成不可逆转的损伤[4],严重影响了患者的生活质量。对于DPN患者来说,除了对血糖控制和对症处理以外,目前并没有其他更好的治疗手段[5],而预防是现阶段最好的治疗措施。因此,早期预防显得尤为重要,越早开始治疗,预后效果越好,治愈率也会相应地提高,建立疾病预测模型是预防DPN的一种有效措施。
目前深度学习作为人工智能领域最热门的一个方向,在图像处理、语音识别等应用领域得到了很大的发展[6],在医疗领域的应用也越来越多。深度学习本质上是一个复杂的机器学习算法,是在神经网络基础上的延伸和拓展,它的优势在于可以自动提取特征,避免用传统人工提取的方式来获取特征信息[7]。深度学习具有很强大的特征学习能力,可以发掘出数据中更深层次的有用特征。与传统机器学习算法相比,深度学习覆盖范围广,能够适应于不同的领域和应用[8]。随着医疗信息化的发展,各大医院在患者的治疗过程中保留了丰富的电子病历数据。不论是疾病类别还是数据的数量级都有了大幅提升,病历数据的积累不仅可以提高辅助诊疗的准确率,而且可以作为医学研究的资源来使用。病历中的数据主要为自由文本,是一种高维、离散的数据,并且包含了患者大量的化验指标以及诊疗记录等信息[9]。
DPN 属于糖尿病并发症疾病,与化验指标有着很大的关系,由血液和尿液化验指标就可以完成初步筛查,因此,可将深度学习方法应用到DPN 病历数据处理当中,通过对病历数据进行学习和分析来构建DPN预测模型。
卷积神经网络(Convolutional Neural Networks,CNN)作为典型的深度学习方法之一,是一种包含卷积计算且具有深度结构的前馈神经网络[10],它的主要特点是具有良好的自学习能力、自适应性能以及容错能力[11],可以自动地完成提取输入数据的特征工作,将提取到的特征信息用于进一步的分类或者预测[12]。其中一维卷积神经网络(1D-CNN)主要应用于序列类的数据处理,所以本研究采用1D-CNN自动识别病历中的临床变量和指标,通过学习和挖掘数据的指标信息以及内在规律,从而可以初步判定是否患有DPN 疾病。这样可以辅助医生诊断和治疗,提前筛查患者的得病情况,进而提升了医生的诊疗效率;而且患者可以对自己病情进行自我管理与及时监测,从而降低DPN疾病的发病率、复发率。
1 数据预处理
1.1 数据描述
本研究所使用的数据来源于天津医科大学代谢病医院。按照国际通用的做法,医学检验数据去掉病案号、姓名、电话和住址等信息,经过脱敏处理之后,该数据总共包含898 个数据样本,每个样本包括51 个指标变量,记录了就诊患者的体征和临床指标。这些数据样本中包含了DPN 患者和非DPN 患者,并且每条数据中包含了与DPN 相关的指标:性别、年龄、空腹静脉血糖、糖化血红蛋白、白细胞、葡萄糖、胆红素等。DPN 原始数据集存在格式混乱、异常值、缺失值、特征冗余、特征纬度高等问题,因此需要对其进行预处理来提高数据的质量,进而改善模型的预测效果。
1.2 数据清洗
原始数据格式混乱,需要将数据整合为1 行1 条患者信息的形式,每1条数据包括各项指标与诊断结果,之后的数据处理都是以此表为基础进行的。数据清洗是数据预处理中的重要步骤,主要包括剔除异常值和缺失值处理等内容。对于某些不符合要求或有明显错误的数据,比如尿液颜色出现了数字、化验指标不符合常理等问题,可将这些错误的指标当作缺失值来处理,利用现有的指标对数据进行缺失值填补;但是对于个别的特征指标,如果出现它与平均值的偏差超过两倍标准差的异常情况,则直接剔除该异常指标,同时使用缺失值处理方法来处理。
此外,由于DPN 属于糖尿病并发症,而并发症多发生在年龄较大的人群中,所以本研究将删除年龄在20 岁以下的病历数据。在原始数据中本来还存在着一些空缺值,对于指标缺失严重的数据,直接将其删除,本研究删除了样本中5条数据,占比非常小,因此并不会影响整体的数据量。对于有些缺失率低的数据,同样选择缺失值填补。本研究需要填充的特征缺失值有总胆红素3 个、白细胞1 个、糖化血红蛋白2 个,都采用K-means 的方法进行填补,它是利用欧式距离或相关分析来确定离缺失值最近的K个数据,再把这K个值通过加权平均来估算该数据的缺失样本。该方法根据缺失值以外的特征信息来对缺失值进行相似性的填补,有效地提高了数据的利用率。
1.3 数值化处理
对于非数值型的指标,需要进行数值化处理,主要目的是为了方便预测模型的构建。将非数值型的指标变量转化为0~3 等级划分变量。DPN 作为糖尿病并发症的一种,患病率与年龄有很大的关系,年龄越大患病率越高,所以年龄也按照年龄段进行等级划分。对于其他数值型化验指标不做转换处理。具体指标赋值情况如表1所示。其中“+”、“-”分别代表阳性和阴性;“1+”、“2+”、“3+”代表某一项指标的严重程度,数字越大代表指标的严重程度越高,DPN诊断结果作为预测模型的因变量指标,其中1 代表DPN 患者,0 代表非DPN 患者。经过数值化处理,数据类型得到了很好的统一。

表1 指标赋值表Table 1 Index assignment
1.4 数据标准化
为了消除特征之间的量纲影响,将其转换为无量纲的纯数值,便于不同单位或量级的特征进行比较或加权,需要进行标准化处理。数据的标准化(normalization)是将数据按一定的比例压缩,使之缩小到一个小的特定区间里。最常用的标准化方法为z-score标准化,其函数公式为:

其中,μ为某一特征的总体平均值,σ为某一特征的总体标准差,x为某一特征的值。数据经过z-score 标准化处理以后,有效地把数据变换为统一的标准,使得不同特征之间具有了一定的可比性。
1.5 特征相关性分析
由于原始数据的指标较多,部分指标彼此之间可能存在一定的冗余度,这样会对模型预测精度造成一定的干扰和影响。在数据预处理之后,通过热力图对各个临床指标进行相关性分析,从而衡量指标之间的关联程度。热力图是一种非常流行的数据展示方法,展示各个变量的分布情况,通常用数据处理库函数Seaborn绘制,它是基于Matplotlib的Python可视化库,可以提供一种高度交互式界面。热力图如图1所示,图中的每个方块里的颜色深浅代表横纵坐标上的指标相关程度,颜色越浅代表相关性越大,可以很直观地反映出特征之间的相关情况。热力图右侧的刻度展示了不同相关系数对应的颜色深浅,横纵坐标0~50 代表指标变量,51 代表诊断结果。由图中可以看到,靠近对角线和右下角出现了很多浅色的方块,说明部分指标之间相关性较高,即存在很强的多重共线性,说明特征之间存在一定的冗余度,为此需进行下一步降维处理。

图1 热力图Figure 1 Thermodynamic diagram
1.6 主成分分析(Principal Component Analysis,PCA)
PCA 是实际应用中最常用的数据降维方法。PCA 的主要思想是通过某种线性投影的方式,将高维的数据映射到低维的空间中表示,即用更少的k维特征代替原先的n维特征,这k维被称为主成分,并且在所投影的维度上特征的方差是最大的[13]。PCA 原理如图2所示。
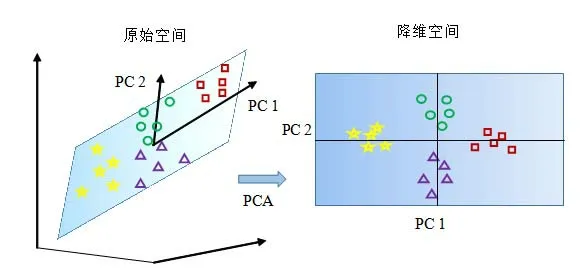
图2 PCA原理Figure 2 Principle of principal component analysis
具体来说,用scikit-learn 工具里的sklearn.decomposition 包来实现PCA 降维,通过参数n_components 指定PCA 降维后的特征维度数目或者所占比例,在这里指定参数n_components=0.98,即占总方差值98%的维度数量,最终降维后的维度数为34,也就是有34个投影特征被保留。
2 预测模型的建立
预处理后的数据不仅可以提高数据的质量,而且可以降低模型训练所需要的时间,提高预测模型的精度。经过一系列的数据处理工作,最终确定892个样本用于研究,并且经PCA降维操作后,得到34个指标,将其作为预测模型的输入变量。然后采用支持向量机(Support Vector Machine,SVM)、BP 神经网络、1D-CNN 3种算法分别建立预测模型。
2.1 SVM
SVM是目前最好的监督学习算法之一,基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大。SVM算法常用来解决二分类问题,并且在对非线性、小样本、高维数的问题解决上有较大的优势,被广泛应用于处理分类和预测问题[14]。
核函数将数据映射到高维特征空间,从而在高维空间中寻找最佳的超平面,然后再对其分类。核函数选用高斯函数,在经过数据预处理以后,采用交叉验证的网格搜索算法,搜索SVM 两个最优参数:惩罚系数C和核函数参数gamma。最终通过网格搜索得到最优参数C为5,gamma为0.02。参数调优之后,使用测试集验证模型的预测性能。
2.2 BP神经网络
BP神经网络是一种按误差反向传播训练的多层前馈神经网络,是人工神经网络基础上进行的延伸和扩展。它的学习过程分为前向传播和反向传播两个阶段。前向传播时,样本从输入层传入,经过若干隐藏层,最后从输出层传出,然后实际输出值与期望值进行对比,若在输出层得不到预期的结果,则进入反向传播阶段,根据实际值与预测值之间的误差来更新神经网络中权重和偏置[15]。
网络输入层的维度为降维后的特征数量,即34个。输入层的输出维度设为64,最后一层为预测结果,输出层节点数为1。隐藏层的节点按照经验选取,经过反复的尝试,隐藏层选为4层,节点数依次为48、48、48、64。隐藏层的激活函数采用relu函数,因为它可以避免梯度消失的问题,加快收敛速度和计算速度,为了避免过拟合的出现,加入Dropout层。模型采用梯度下降法调整网络权值,进而更新网络参数。
2.3 1D-CNN
1D-CNN 中的输入是一维向量,因此其卷积核也相应的采用一维结构,每个卷积层和池化层的输出同样也是一维特征向量,因此被广泛使用在序列数据的特征识别以及提取上[16]。1D-CNN 是一种端到端的模型结构,鲁棒性极高,若输入为电子病历数据,通过对病人的医疗数据进行学习和分析,从而给出可靠诊断与预测。跟二维类似,它同样具有局部连接和权值共享的特性。其中,局部连接利用空间拓扑结构建立相邻层之间的非全连接空间关系减少了模型需要训练的参数个数[17];权值共享用于避免算法过拟合。在结构上,它由卷积层、激活层、池化层和全连接层构成。
卷积层的作用是对输入数据进行特征的提取,通过一个卷积核依次滑动对目标输入进行局部的卷积操作,卷积核就是一个局部感受野所学习到的权重矩阵[18]。该层主要的特点就是采用了权值共享和局部连接方式,一维卷积的运算如式(2)所示:

其中,*表示卷积运算,yi为第i个输出特征图,xi为第i个输入特征图,kij为本层卷积计算所用到的卷积核,bj为第j个特征图的偏置。在CNN 中,非线性激活函数一般会选择relu 函数,relu 函数的特点主要是能够使一些神经元的输出为0,提高了网络结构的稀疏性,并且降低了参数的相互依存关系,抑制了过拟合问题的出现。
池化层通常又称为下采样层,其主要作用是在保持特征不变性的前提下去掉一些冗余信息把重要的特征抽取出来[19],在一定程度上可以防止过拟合。池化方法主要分为两种:最大值池化法、平均值池化法,它们分别用公式(3)、公式(4)表示:

其中,p为池化得到的特征矩阵,l为特征图的宽度,a为卷积层激活后的特征矩阵。最大值池化和平均值池化分别计算相邻矩形区域内的最大值和平均值,而通过最大值池化可以得到与位置无关的信息[20]。
全连接层主要用来完成最后的预测工作。该层每个输出神经元都和上一层神经元相连接,对输入特征进行组合运算,然后使用激活函数输出预测结果。对于预测问题,输出层给出的是预测类别的概率值。一般用0.5作为阈值,输出概率值≤0.5时,为未患DPN,输出概率值>0.5 时,为患有DPN。因此用sigmoid函数作为输出层的激活函数。
本文构造了11层的1D-CNN,如图3所示,包括1个输入层、6 个一维卷积层、3 个池化层、1 个Dropout层和1个全连接层。该网络模型采用梯度下降法,实现损失函数的最小化,然后对网络结构中的权重参数进行逐层逆向调整,模型采用卷积层和池化层交替设置的方式完成自适应特征学习,这样反复交替会学到更抽象的特征。

图3 一维卷积神经网络模型结构Figure 3 Structure of one-dimensional convolution neural network model
输入数据的矩阵大小为34×1,第一个卷积层:卷积核长度为3,深度为1,共有64 个卷积核,步长为1,卷完后数据由34×1 变为32×64;第二个卷积层参数和第一个卷积层一样,经两层卷积之后得到的矩阵大小为30×64;接着进入池化层,池化层的窗口大小设为2,这意味着该层的输出矩阵大小仅为输入矩阵的二分之一,所以池化完矩阵大小为15×64;接着再经过3 层卷积层和最大池化层得到的矩阵大小为4×128;再通过1次卷积和平均池化操作,进一步提取更抽象的特征,这样会把多维向量平铺成一维向量,输出矩阵的大小为1×256;下一步加入Dropout层,比率设置为0.7,即随机将Dropout 层70%的神经元权重赋了零值,这样可以减弱神经元节点间的联合适应性[21],并且增强了泛化能力。该层的输出仍然是1×256 的神经元矩阵。最后输入到全连接层并且用sigmoid激活后,获得对输入数据的DPN预测值。
3 实验结果与分析
本次实验将样本数据随意打乱后,抽取80%的样本数据作为训练集用于训练预测模型,剩余20%的数据作为测试集。训练模型时,BP 神经网络和1D-CNN 都以交叉熵作为损失函数,使用Adam 优化器,将学习率设为0.000 2,迭代次数为200次,模型训练完毕后,将测试集样本输入网络进行预测。本研究选用准确率、召回率、F1 值和AUC 值来对模型进行评估,模型评估在相同的实验环境下进行,分别将构建的3 种DPN 预测模型在测试集上进行验证。它们的受试者工作特征(Receiver Operating characteristic Curve,ROC)曲线如图4所示。

图4 3种ROC曲线Figure 4 Receiver operating characteristic curve of different models
图4中的横坐标是假阳率,表示在阴性样本中,被识别为阳性的概率,纵坐标为真阳率,表示在阳性样本中,被识别为阳性的概率。ROC曲线越接近左上角,则模型性能越好。AUC值表示ROC曲线下面积,它越接近于1,说明预测效果越好。从图中可以看到,1D-CNN的AUC值为0.98,高于其他模型。最后计算并整理每个模型的指标值,预测结果如表2所示。
从表2可以看到,3 种DPN 预测模型的测试集上预测准确率都在96%以上,但是1D-CNN 模型的预测准确率最高,达到了98.3%。从召回率的角度来看,BP 模型和1D-CNN 模型非常接近,但是高于SVM。F1 值是精确率和召回率的综合指标,显然1D-CNN模型高于其他两个模型;综合对比发现,1DCNN 模型预测效果最佳,有较好的学习能力和泛化能力,说明该模型在处理本文所采用的病历文本数据具有更好的适应性,该模型在DPN 疾病预测方面具有很高的应用价值。

表2 预测结果比较Table 2 Comparison of prediction results
4 结语
本文通过1D-CNN 建立的DPN 预测模型,表现出较好的预测性能,具有一定的现实应用价值。它不仅可以帮助医生进行诊断决策,对DPN 的早期筛查起到很好的辅助作用,而且患者也可以对自己病情进行实时监测与预防。因此本研究为DPN 患者发病预测提供了一种新方法。但本论文也有一定局限性,仍需进一步完善。由于条件限制,所用到的数据集样本数量相对较少,数据类型比较单一,因此在以后的研究中,将融入更大、更全面的医疗样本集,比如医嘱信息、住院记录以及影像数据等,以进一步完善预测模型。
