基于深度学习的非合作目标装配位姿视觉检测
2022-01-22叶晗鸣王逍遥
叶晗鸣,苏 宁,王逍遥
(1. 北京航空航天大学 机械工程及其自动化学院,北京 100191;2. 江南造船(集团)有限责任公司,上海 201913)
0 引言
随着数字化相关技术的快速发展,数字化装配技术凭借其智能、高效、高精度的特点,在工业领域的应用日益广泛[1]。目前针对数字化装配过程中的目标位姿测量问题,主要的测量手段包括使用全站仪、激光跟踪仪等大型测量设备进行测量和机器视觉位姿测量两种。其中,使用全站仪、激光跟踪仪等大型测量设备进行测量的目标位姿测量方法,测量范围大,测量精度高,但均为接触式测量方法,需要为此设计工装以固定靶球,并在待测部件上安置工装[2-3],方法较为繁杂,且会对装配过程造成一定的干扰,同时测量过程操作复杂,难以实现实时测量。而属于非接触测量的机器视觉位姿测量方法,以其系统结构简单,测量过程操作方便,实时性强的特点,被广泛应用于各种工业装配过程的实时装配测量中[4]。
根据位姿测量过程中是否使用人工靶标进行划分,机器视觉位姿测量可以分为合作目标位姿检测[5]和非合作目标位姿检测[6]。合作目标检测通过视觉测量单元识别人工设计靶标解算相对位姿,而非合作目标位姿检测,通过解析物体的自然特征,给出相对位姿估计结果。合作目标位姿测量的精度一般较高,需要的图像处理算法也较为简单,但在机器人自动化装配等复杂装配场景下,由于场景复杂,装配空间有限,并不一定具备安装人工靶标的条件。在这种情况下,非合作目标位姿测量成为机器视觉位姿测量的最佳选择。
传统的非合作目标位姿视觉检测方法大多依赖于图像处理算法对物体自身低层次特征的提取效果,一般首先需要提取图像中的低层次特征,如图像边缘点、角点、直线等显著特征,再根据特征点自身的性质构造不同的特征描述子,对特征描述子进行匹配,在根据计算机视觉多视图几何的原理,解算目标的相对位姿。如P,David等人[7]将直线匹配问题和位姿问题有机结合,建立一个全局目标函数来解决位姿估计问题;张政等人[8]参照点特征的正交迭代方法,提出直线特征的位姿估计正交迭代方法求解目标位姿;Markus Ulrich[9]等通过获取目标物体 CAD不同姿态下的成像以建立模板库,然后将待测图像与模板进行相似性匹配获取目标位姿;桂阳[10]将目标的三维模型投影生成不同姿态下的二维图像,计算图像中目标轮廓的 MSA 矩,利用距离图迭代最小二乘法得到最终的位姿参数。但是,依赖于图像处理算法非合作目标位姿视觉检测方法往往鲁棒性不足,其具体算法实现与物体结构、颜色等相关,因此在实现上需对某种或某类物体定制算法,方法的普适性、泛化能力相对较低。当待检测目标处于复杂背景或光照情况多变时,难以实现对特征的准确提取[11]。如何在复杂装配场景下,实现对非合作目标特征的精确提取,成为相关研究人员研究的重点。
近年来,深度学习技术以其数据驱动、鲁棒性较强、拟合能力强大、适用场景多样的特点在机器视觉领域的应用愈加广泛,并在图像分类、目标检测、目标跟踪等领域取得了良好的效果。相比于传统图像处理算法,基于深度学习的视觉算法模型能够提取图像中高层次的语义特征,受背景条件或光照情况的影响较小,更适用于复杂装配场景中待装配目标的特征提取。为探究深度学习技术在视觉位姿检测中的应用,本文提出了一种基于深度学习的装配位姿非合作目标视觉检测方法。利用SingleshotPose深度学习模型对待装配目标的轴对齐包围盒特征点的像素坐标进行估计,再结合Opencascade软件对目标数字模型的轴对齐包围盒特征点在目标坐标系下三维坐标的求解结果,进行PnP求解,得到装配目标坐标系相对于相机坐标系的位姿关系,进而实现在装配坐标系下对目标位姿的实时检测。
1 基于深度学习的位姿检测原理
1.1 装配过程位姿视觉检测原理
装配过程中目标位姿检测的目的是得到待装配目标上装配关键点在指定的装配过程基坐标系下的坐标后执行后续装配操作,也即求得位姿转换矩阵,使得下式成立:

式中Xtarget为装配关键点在目标坐标系下的坐标Xbase为装配关键点在基坐标系下的坐标。

根据相机成像过程,有:

式中,K为相机内参矩阵,Q为三维坐标的齐次化表示形式,r为尺度常量因子,q为二维像素坐标的齐次化形式,将上式写为矩阵形式,即有:
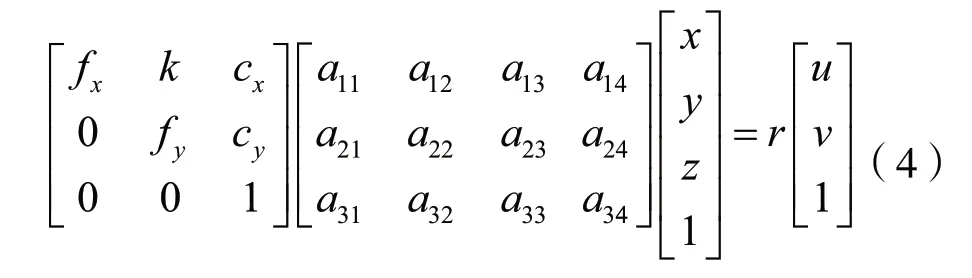
内参矩阵K可由内参标定获得,则由上式可知,中的12个未知参数,通过构建包含n≥6的3D-2D点对的PnP问题即可解出,进而结合标定得到的,求得,完成对目标位姿的检测。
因此,解决目标位姿视觉检测问题,关键在于找到n≥6的3D-2D点对。本方法是通过深度学习和数字模型结合的手段,找到9对3D-2D点对,构建PnP问题求出,实现目标位姿检测。
1.2 非合作目标位姿视觉检测方法
在非合作目标位姿的估算中,选择目标的特征点构建PnP问题,决定了后续特征提取算法和位姿计算方法。一般可选择的特征包括点特征、直线特征、边缘特征等。由于实际生产过程中,不同待检测目标的形状尺寸各不相同,需要使用一种对不同形状目标都适用的特征,作为进行非合作目标位姿估算的依据。为此,本文选择目标物体的轴对齐包围盒的8个角点和1个中心点,作为非合作目标特征。
轴对齐包围盒采用一个长方体将物体包围,长方体的各条棱均与坐标系的某个轴平行,因此称其为轴对齐包围盒。因此,在目标坐标系下,轴对齐包围盒8个角点的三维坐标为:{xmin,ymin,zmin},{xmin,ymin,zmax},{xmin,ymax,zmin},{xmin,ymax,zmax},{xmax,ymin,zmin},{xmax,ymin,zmax},{xmax,ymax,zmin},{xmax,ymax,zmax}:中 心点三维坐标为:。
在工业生产过程中,待检测目标的三维数字模型一般是可以得到的。通过Opencascade对目标的三维模型进行离散网格化,再调用轴对齐包围盒计算相关的功能函数,就可精确获得目标坐标系下9个特征点的三维坐标。Opencascade获取轴对齐包围盒的算法流程及效果图像如图 1所示。
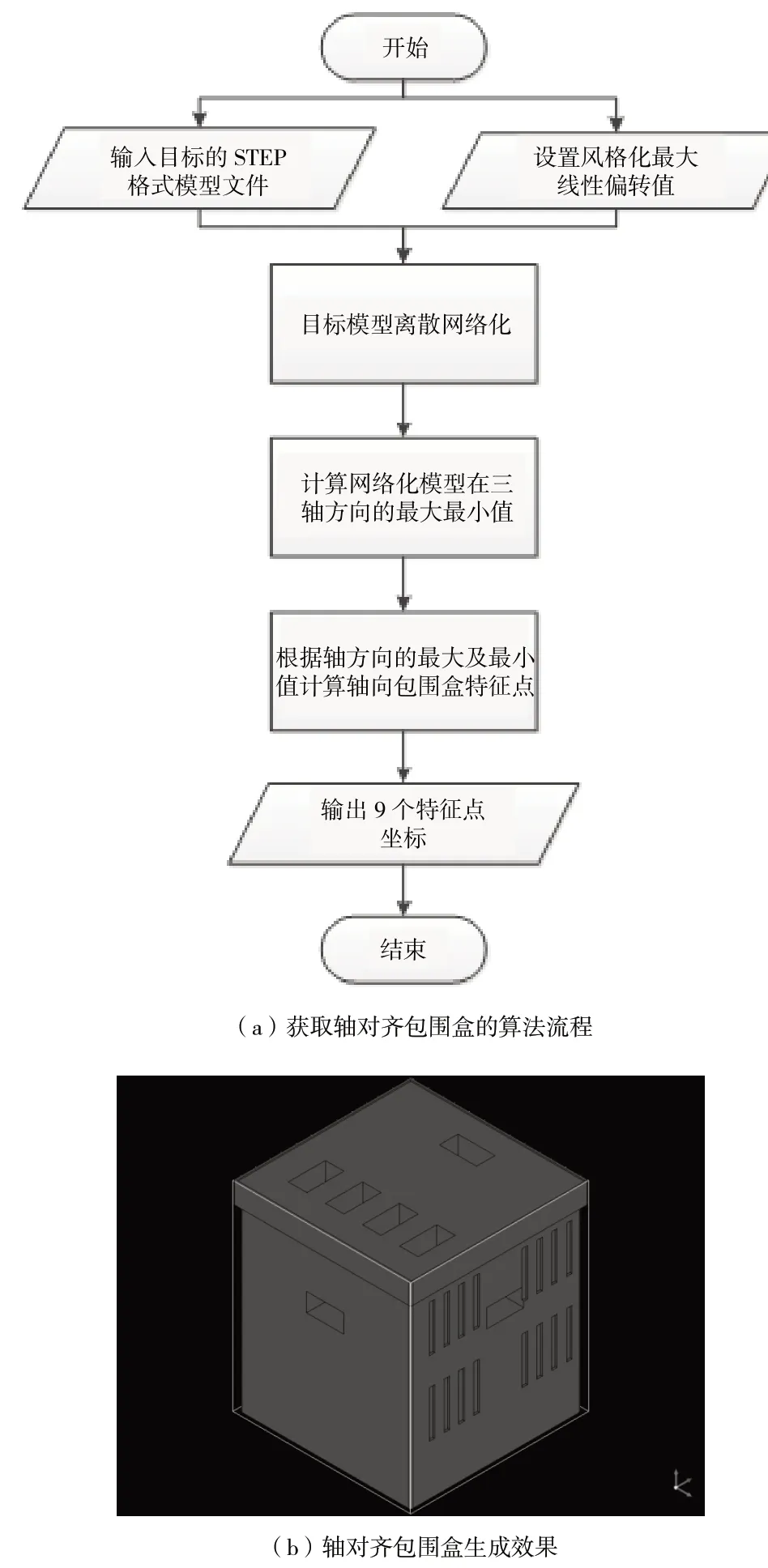
图1 Opencascade生成轴对齐包围盒流程及效果
设目标的轴对齐包围盒8个角点及1个中心点在像素坐标系下的坐标为{ui,vi},i=1,2,…,9。本文通过SingleShot关键点回归模型[12]获取9个三维特征点在图像上的对应的二维点坐标,方法流程如图 2所示。
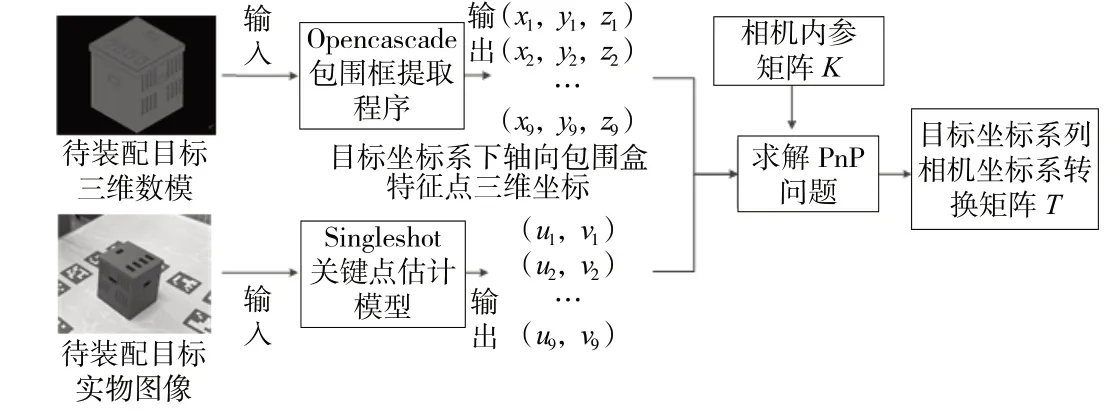
图2 相对位姿关系矩阵求取流程
SingleShot关键点回归模型是在目标检测模型YOLO的基础上发展而来的,模型的输入为RGB图像,输出为图像中物体的类别编码,以及该物体的轴对齐包围盒8个角点和1个中心点的二维像素坐标。
在YOLO网络中,由于预测量为2D包围盒,因此,采用预测包围盒和真实包围盒的重叠区域分数(IoU Score)作为评判置信概率的标准。由于研究在三维的3D包围盒的重叠区域分数难以计算,极大地影响了训练速度。因此,本文采用如下置信函数:
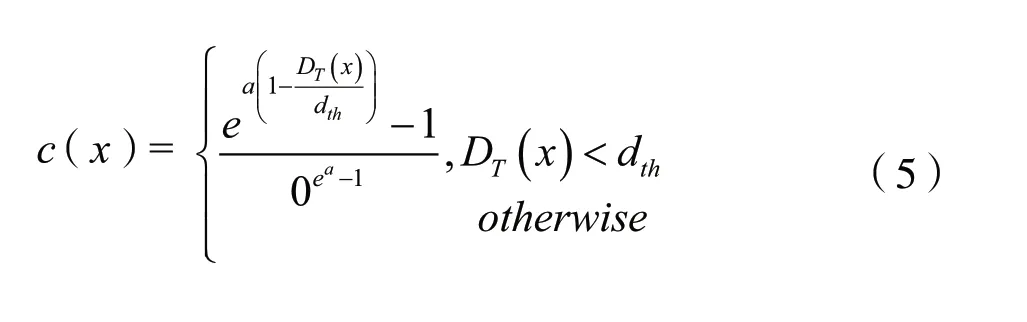
式中,DT(x)表示预测的2D点x到其真实值的欧式距离值,a表示指数函数的陡峭程度,dth为阈值。预测点距离真实点越近,DT(x)越小,函数c(x)的值越大,预测的置信度越高;反之,DT(x)越大,函数c(x)的值越小。对所有预测的2D点都进行如上的计算,取其均值作为该次训练的置信值。当DT(x)大于阈值时,令其置信度为0。
在通过SingleShot关键点回归模型得到物体的3D包围盒8个角点和1个中心点的二维像素坐标后,构建9对3D-2D点对进行 PnP求解,即可解得相机与目标之间的相对位姿关系矩阵,结合相机标定的结果,即可得到代表目标位姿的矩阵。
2 非合作目标位姿视觉检测试验
2.1 深度学习数据集制作
作为数据驱动的算法,深度学习算法模型需要规模较大的数据集才能达到理想的算法效果。考虑到人工制作标注SingleShot关键点回归模型数据集不仅费时费力,而且难以保证特征点标注的准确性,本文设计了一种自动化的标注方法,以RGBD相机采集数据,通过场景标志符的辅助,结合图像信息与深度信息,通过算法自动标注各帧图像中目标物体的轴对齐包围盒。本文试验的数据集制作实验场景如图 3所示。

图3 SingleShot关键点回归模型数据集采集场景
进行数据集采集时,首先要在转台平板上粘贴场景标志(共计13个),并将目标物体放置中央;将RGBD相机固定在平板上方,转动转台,采集物体在不同角度的RGB图像和点云数据;完成环绕物体360°的图像采集之后,改变相机的俯仰角,重复以上操作,由此得到目标物体在不同视点下的RGBD数据。本文试验共计采集了626组数据。
进行数据集自动标注时,通过识别每张图片中的场景标志符,即可解算出各帧图像相对于第一帧图像的位姿变换矩阵。再通过拼接各帧图像点云,得到第一帧图像的场景点云,剔除场景点云中多余的点,即可得到较为完整的目标物体3D点云,如图 4所示。

图4 目标物体3D点云
根据目标物体目标点云,转化为step格式文件,并使用Opencascade求取物体轴对齐包围盒角点的三维坐标。根据第一帧图像中的场景标志符,解算出RGBD相机的内参矩阵和在第一帧图像下的外参矩阵;根据内参矩阵、外参矩阵,将包围盒角点的三维坐标投影为第一帧图像中的二维像素坐标;再根据已知的各帧图像的位姿变换矩阵,可将轴对齐包围盒角点投影至各帧图像上,得到各帧图像的标注结果,如图 5所示。

图5 轴对齐包围盒标注效果图
2.2 深度学习模型训练
为了对深度学习模型进行训练和测试,试验将采集到的数据划分为训练集和测试集,其中训练集包含500组数据,测试集包含126组数据。试验设置了500个训练周期,在每个周期只向SingleShot关键点回归模型输入训练集中的样本进行训练,并保存该周期时SingleShot关键点回归模型的权重文件。从第20个周期开始,每训练10个周期,在测试集上对模型效果进行测试,通过计算轴对齐包围盒9个特征点像素坐标预测值与真值的平均像素误差来对模型效果进行评估。测试像素误差曲线如图 6所示。

图6 轴对齐包围盒特征点坐标测试像素误差
由图 6可知,自第100个训练周期后,模型的特征点坐标平均像素误差开始收敛,并在第220个训练周期时达到了最小值,故选择第220个训练周期下模型的权重文件作为时SingleShot关键点回归模型最佳权重,进行目标位姿检测试验。
2.3 目标位姿检测试验
利用训练得到的SingleShot关键点回归模型最佳权重,结合前文所述方法,进行目标位姿检测试验。SingleShot关键点回归模型对轴对齐包围盒特征点的输出可视化如图 7所示。其中,绿色框为轴对齐包围盒8个角点连接得到的对轴对齐包围盒在像素坐标系下的投影。

图7 SingleShot模型输出可视化结果
考虑到目标装配位姿视觉检测过程中,误差主要来自相机与目标实时位姿解算的过程,即对的估计过程,而由标定得到,误差一般较小。因此,可从相机与目标相对位姿估计误差和相对位姿预测准确率两方面评估的估计精度,进而评估目标位姿检测的精度。对测试集数据进行分析和统计后,相机与目标相对位姿平均误差结果见表 1,位姿估计准确率结果见表 2。

表 1 测试集相对位姿估计平均误差统计表

表2 测试集相对位姿估计准确率统计表
由表 1和表 2可知,在测试集上,本方法的距离准确率达到了95.24%。可以认为,本方法能够对目标与相机间相对位姿进行较精确的检测,即保证的精度;进而可以认为,在标定精度得到保证的情况下,本文方法能够对目标装配位姿进行较精确的检测。
3 总结
本文以非合作目标的位姿估计问题为研究对象,提出一种基于深度学习方法的非合作目标相对位姿估计方法。本文的主要工作包括:
(1)提出了基于SingleShot关键点估计模型的非合作目标位姿估计方法,通过SingleShot模型输出待装配目标轴对齐包围盒9个特征点的二维像素坐标,再利用Opencascade获取目标轴对齐包围盒特征点在目标坐标系下的三维坐标,求解PnP问题,得到目标和相机之间的相对位姿,进而完成目标在基坐标系下的位姿检测。
(2)设计了一种基于RGBD相机的自动化标注算法,通过目标点云数据与三维模型的匹配和坐标系转换,实现对SingleShot关键点估计模型所需数据集的自动标注。利用实验室条件下采集和标注的数据集,对本文提出方法进行了试验验证。实验结果表明,本文方法能够在一定精度范围内基本满足位姿估计需求。
本研究目前仍存在一定不足,深度学习模型数据需求量较大,且位姿估计的精度仍有提升空间。未来的研究中,需要对本方法进行优化,以尽量小的深度学习数据集,实现精度更高的目标位姿检测。
