基于深度学习产品质检命名实体识别研究
2022-01-22冯一铂
方 红, 张 澜, 苏 铭, 冯一铂
(1. 上海第二工业大学 文理学部,上海201209;2. 喀什大学 应用与统计学院,新疆喀什844000)
0 引言
75%的搜索查询中就包含一个命名实体,研究命名实体可以优化搜索结果, 为构建知识图谱奠定基础。中文命名实体识别(CNER)是中文自然语言处理领域的一项重要任务,为自然语言处理很多下游应用提供基础, 例如机器翻译[1]、自动文本摘要[2]等。命名实体识别(NER) 的目标是从文本中识别实体名称, 并将其类型分为不同的类别[3], 如人名、地理位置、组织等。若给定一句话“XXX 在北京打篮球”, NER 就可以识别出 “XXX” 为人名,“北京”为地理位置,“篮球”为某个实体。本文通过爬取、清洗处理、人工标注等方式构建产品质量检测(pruduct quality inspection,PQI)数据集,针对PQI数据特点, 优化NER 模型, 对该领域的NER 展开研究。
1 相关工作
NER 实现方式有4 种,第1 种基于规则和词典,无需带有标签的数据,仅依赖于手工构造的规则,这种方法在实际应用中,编写规则和构建知识库容易产生错误,且移植性较差,因此很快被淘汰; 第2 种为无监督学习方法,根据语义相似性聚类,从聚类中抽取命名实体, 再用统计的方法判别实体类型; 从传统机器学习发展衍生了第3 种方法,在基于特征的监督学习方法中,NER 被转化为一个多分类任务,结合监督学习算法和特征工程, Bikel 等[4]提出了第1 个基于NER 的隐马尔科夫模型(hidden markov model,HMM)[5],用于识别姓名、日期、时间等,这种方法极大提升了识别准确率和简洁度,但缺点在于特征的选择和提取会对结果产生影响,且需要大量的时间和资源进行训练;随着Word2Vec 的出现,基于深度学习的方法广泛应用于自然语言处理领域,这种方法可以自动学习特征,在NER 中相较于传统机器学习具有更好的性能。循环神经网络(recurrent neural network, RNN)在学习句子组成部分[6]的能力非常强大,后来很多的NER 方法都基于RNN 改进,但RNN 在处理长文本序列时,容易丢失重要信息。Lamplel 等[7]将双向长短时记忆神经网络(Bidirectional long short-term memory,BiLSTM)和条件随机场(conditional random fields, CRF) 结合, 构成NER 的基本结构, 但该方法处理文本的顺序固定无法改变, 识别结果和效率仍有可提升的空间, 后来衍生出的Transformer[8]被证实比传统的RNN 具有更好的效果。卷积神经网络(convolutional neural network, CNN)与RNN 不同,它可以以前馈方式处理序列,能有效利用GPU 并行性。注意力机制在自然语言处理领域得到广泛应用,通过添加注意力机制, NER 模型可以捕获输入中信息量最大的元素,Pandey 等[9]提出了一种双向注意机制的神经网络结构,通过文档级别的注意力机制,更好地获取标签之间的关系。
CNER 相比英文实体识别, 挑战性更高[10], 主要是由于以下几点: ①中文实体缺乏英文实体特有的表现形式, 比如大小写字母; ②中文实体依赖于上下文信息,汉字的多重语义在文本中可以作为实体也可以作为非实体,例如“时间是在上海市工作”,其中“时间” 一词不能被正确识别为人名; ③汉字的复杂性, 也没有英文的分隔符, 实体边界难以确定,例如“张凯平常去河北检查工作”,算法可以理解为 “张凯平/常/去/河北/检查/工作”,也可以理解 “张凯/平常/去/河北/检查/工作”。中文领域的文本数据训练有限, 且缺乏完善的词典, 识别效果相较于英文,仍有很大提升空间。
当前,针对PQI 的NER 研究工作较少,语料库也存在空白,而研究PQI 的实体识别对后续的关系抽取、开发问答系统有重要意义。PQI 数据存在以下特点: ①概念和专有名词多且组成复杂,例如“橡胶密封圈” “车用机油” 等; ② 实体长度不固定, 有“电脑” 这种短文本实体, 也有“塑料绝缘防触电控制电缆” 这种长文本实体, 特征较为复杂。本文提出一种融合注意力机制的CNN-BiGRU-CRF 模型,识别已标注8 种实体类型,能够较全面的提取文本的特征,该模型在公开和定制数据集上都有很好的效果。
2 CNN-BiGRU-CRF 模型
2.1 模型概述
本模型实体识别基本框架如图1 所示。将构建好的PQI 数据进行分词、人工标注等处理,将CNN层获取的特征向量和预训练获得的词向量、词长特征向量结合输入到BiGRU 层, 在BiGRU 层输出后分配不同的注意力权重, 最终通过CRF 输出预测标签序列。

图1 CNN-BiGRU-CRF 模型图Fig.1 CNN-BiGRU-CRF model diagram
2.2 CNN 层
CNN 层通常包含卷积层、池化层、全连接层等,一般应用于图像识别较多。通过CNN 中的滤波器对句子进行卷积操作,提取句子的局部特征。可计算出滤波器学习得到的上下文特征:

式中:Cmax为最大特征;c1,c2,··· ,cn为各个特征。
2.3 BiGRU 层
门控循环单元[12](gated recurrent unit,GRU)是一种由长短期记忆(long short-term memory,LSTM)改进而来的神经网络,简化了LSTM 复杂的门结构,也能很好地解决序列中时间距离较大的依赖问题,在实现长C 记忆的同时运算速度更快[13]。GRU 的单元结构如图2 所示,图中:

图2 GRU 单元结构图Fig.2 GRU unit structure diagram
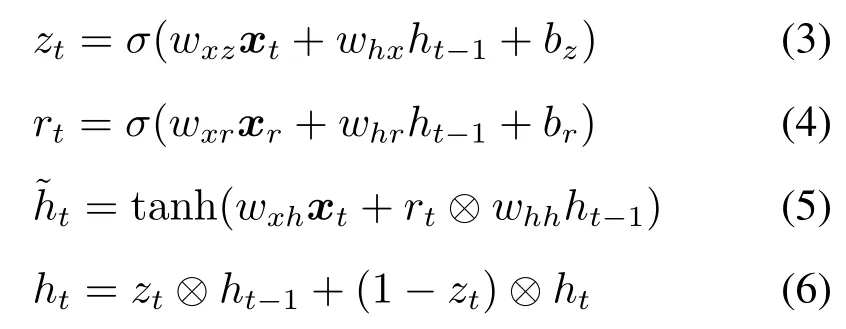
式中:zt为更新门;rt为重置门;σ为 Sigmoid 函数;xt为t时刻的输入向量;xr为r时刻的输入向量;bz、br为偏移系数;wxz、whx、whr、whh、wxr为权重系数;ht−1为t −1 时刻隐含状态输入;ht为t时刻隐含状态输入; ˜ht为候选隐藏状态;⊗为矩阵的Hadamard 积。
将CNN 获取的特征向量与预训练的词向量、词长向量拼接输入。使用GRU 不仅能通过正向计算考虑文本的前序信息,还能通过反向计算提取到文本后续信息的特征,最终两个输出向量值拼接形成BiGRU 层输出向量, 从而获取序列的全部信息,图3 为BiGRU 模型图。

图3 BiGRU 模型图Fig.3 BiGRU model diagram
2.4 Attention 层
当输出序列较长时,引入Attention 机制可以减少关键信息丢失,为了把有限的注意力分配给重要信息使输出更准确,将BiGRU 的输出层与Attention结合,各特征向量与对应权重的乘积相加后获得新的输出向量。
对于i时刻的模型输出向量, 利用注意力权重分布向量对编码的源序列的隐藏层输出进行加权求和计算,得到针对当前输出的全局特征:

式中:aij为注意力权重;βij、βik为给定向量;va,ωa,ωb为权重矩阵;Ci−1为上一时刻注意力机制的状态;P=[P1,P2,··· ,Pj]为 BiGRU 神经网络输出的向量表示;n为输入元素的数目;Ci为利用注意力机制输出新的特征向量。
2.5 CRF 层
对于输入序列x= (x1,x2,··· ,xn), 设C为p×k大小的Attention 输出矩阵,p为句子的长度,k为标签数量,那么预测序列y= (y1,y2,··· ,yn),得到的分数为:

cmn表示第m个词的第n个标签的分数;Amn表示从第m个标签转移至第n个标签的分数。YX表示所有可能输出标签序列的集合, ˜y为真实标记预测,产生的序列y的概率为:

得到最佳标签序列公式:

3 数据及其处理
3.1 数据说明
2005 年之前,NER 的数据集主要由包含实体类型的新闻文本构成,适用于粗粒度的NER 任务,例如Conll2003、Onenote5.0 等。此后, 文本源上开发了很多包括维基百科文章、YouTube 评论和W-NUT中的帖子构成的数据集,作为公开数据集,被学界广泛使用。
对于目前还未公开的质量检测监督数据集,本文通过数据采集、数据预处理、数据标注3个步骤, 建立产品质量监督检测实体识别语料库。PQI 数据集源于上海市质量监督检测技术研究院 (http://www.sqi.com.cn/sq-iweb-new/index.html),经过数据预处理后人工标注的产品质量监督检测数据集包括全国各地不同产品的质量监督检测报告,数据集规模如表1 所示, 按照一定比例分为7 386条训练集、1 741 条验证集和1 741 条测试集,共计10 868 条语句。

表1 PQI 数据集规模(单位: 条)Tab.1 Scale of PQI dataset(unit: sentence)
本数据集主要包含8 个实体类型,分别为文教体育用品、家用电器及电器附件、电子信息技术产品、儿童用品、家具及建筑装饰装修材料、服装鞋帽及家用纺织品、交通用具及相关产品、日用化学制品及卫生用品和其他(非实体)。表2 为PQI 数据集标注标签、含义及示例。

表2 PQI 数据集标注标签含义及示例Tab.2 PQI dataset annotation label meaning and examples
3.2 标注规范
BIOE 标记比BIO 标记能更清楚地划分实体边界。本文对数据集的标注使用BIOE 标注模式, 具体标注意义如表3 所示, 其中Type 代表不同实体分类。

表3 BIOE 标记Tab.3 BIOE mark
本文所用的数据格式全部为Conll 格式, 分为数据和标签两列。表4 为部分实体标注的数据和标签对应情况。

表4 部分数据集标注Tab.4 Partial dataset annotation
4 实验和结果分析
4.1 实验环境
本文采用Python 编程语言3.6 版本, 实验和硬件具体参数如表5 所示。

表5 实验和硬件参数Tab.5 Experiment and hardware parameters
4.2 实验参数设置
主要采用网格搜索法来进行参数调节,一部分来自于现有的实验结论,另一部分在模型训练中进行实时调整,具体的实验参数配置如表6 所示。

表6 参数设置Tab.6 Parameter settings
4.3 实验评价指标
本文实验中使用序列标注任务常用的准确率(precision rate,P)、召回率 (recall rate,R)和F1值作为模型性能的评价指标:

式中,TP(true positive) 表示被判定为正样本, 事实上也是正样本;FP(false positive)表示被判定为正样本,但事实上是负样本;FN(false negative)表示被判定为负样本,但事实上是正样本。
4.4 实验结果
为了验证该模型在公共数据集(这里采用简历数据集Resume[14]) 和在PQI 数据集的识别性能, 与以下几个模型(CRF、BiLSTM、BiLSTMCRF、Lattice、CNN-BiLSTM-CRF) 进行对比, 并比较了各模型对实体的识别性能,详细对比结果如表7、8 所示。

表7 Resume 语料对比结果Tab.7 Resume corpus comparison results
由表7 可知, 由于Resume 数据集的文本简单且结构单一,在各个模型的实验表现优秀。本文的模型相比于BiLSTM-CRF 在各个指标均有所提升,验证了CNN 和Attention 机制的有效性。由表8 可知, 针对PQI 数据集的识别, 单个CRF 识别的准确率为62.5%, 说明传统的机器学习能够有效对此类文本抽象建模, 具有良好的适应性。BiLSTM 的准确率比CRF 提升了2.6%, BiLSTM-CRF 在准确率上相对于BiLSTM 提高了5.0%, 在F1值上提高了4.0%, 说明BiLSTM 与CRF 结合可以捕捉长距离信息, 并且能够充分利用相邻标签的关系, 输出最优化标签序列。CNN-BiLSTM-CRF 的准确率比BiLSTM-CRF 提高了3.0%,F1值提高了4.2%,表明CNN 特征抽取可以有效提升识别效果。本文的模型相较于CNN-BiLSTM-CRF 模型加入了Attention机制解决了序列过长的问题,在3 个指标上均有所提升,并且模型所需训练时间较短,得到最高F1值74.8%。
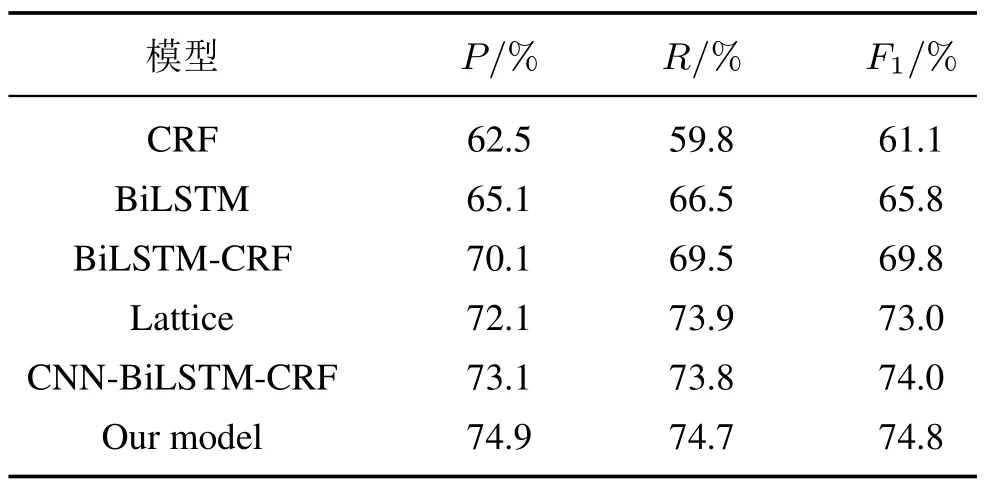
表8 PQI 语料对比结果Tab.8 PQI corpus comparison results
5 结 语
本文研究了应用于PQI 领域的NER。首先通过数据挖掘、处理和标注, 构建了一个产品质量监督检测语料库, 填补了在该领域的数据集空白。此外提出了一个融合注意力机制的CNN-BiGRU-CRF 模型,将文本的词向量、词长向量和CNN 提取的特征向量结合,充分提取文本的全部特征,获取整个序列最优标注。
与其他模型相比,该模型能有效识别8 种实体,不用添加人工特征,通过少量有标注的语料可以学习到文本所包含的特征信息,在小规模质检语料上取得了比现有方法更高的P、R和F1值,验证了该模型的有效性。但由于缺乏完善的词典库, 细粒度的中文NER 有很大的提升空间。
