基于多任务学习的生成式阅读理解
2022-01-20黄荣涛邹博伟
钱 锦,黄荣涛,邹博伟,2,洪 宇
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 新加坡资讯通信研究院,新加坡 138632)
0 引言
机器阅读理解是在阅读和理解自然语言的基础上,根据文本内容回答用户提出的问题,是当前自动问答领域的研究热点之一。
近年来,随着大规模阅读理解数据集的构建,如SQuAD[1]、HotpotQA[2]、CoQA[3]等,以及预训练模型的提出,如BERT[4]、UniLM[5]、ENRIE-GEN等[6],机器阅读理解技术取得了巨大发展。目前主流的机器阅读理解模型通常将答案设定为段落中的一个连续片段,这种抽取式阅读理解模型存在一定的局限性,仅能直接以段落中的片段作为答案,导致在针对某些问题时,无法给出自然流畅的答案,例如,表1段落(a)中的True/False问题。此外,如果将问题与答案分离,仅根据答案无法获得完整清晰的信息。表1中段落(b)中例子所示,严格意义上说,抽取式模型给出的答案“Season 5(第5季)”并不通顺,在某些应用场景(如聊天机器人)中,会对用户体验造成影响。

表1 抽取式与生成式机器阅读理解
与抽取式阅读理解相比,生成式阅读理解不再局限于直接从段落片段中抽取答案,而是参考段落、问题,甚至词表,生成更为自然和完整的表述作为答案。例如,表1段落(a)中,生成式阅读理解模型给出的答案能够与问题更自然地衔接;而表1段落(b)中的生成式答案与抽取式答案相比更完整,确保了答案在独立于问题和段落时仍能够保持完整的信息。而现有的生成式阅读理解模型通常基于整个段落生成答案,缺乏对答案边界和问题类型信息的理解,生成答案有时未参考段落中用于生成答案的片段以及问题的具体类型,导致生成的答案和真实答案之间存在一定差距。
为解决上述问题,本文提出一种基于多任务学习的生成式阅读理解框架。多任务学习能够学到多个关联任务的共享表示,并适应这些不同但相关的任务目标,使主任务获得更强的泛化性能。基于此,本文将答案生成任务作为主任务,将答案抽取和问题分类任务作为辅助任务,在训练阶段,通过多任务学习的参数共享机制,让模型在生成答案的同时加强对答案边界和问题类型的理解,从而让答案抽取和问题分类任务辅助答案生成任务,最终提升生成式阅读理解模型的泛化性能。
针对答案生成任务,本文提出的生成式阅读理解模型由编码层和任务层组成。其中,编码层基于深度双向Transformer[7]编码器,并借鉴UniLMV2[8]模型中特殊设计的自注意力掩码机制控制答案生成过程中的可见信息;任务层分为答案生成模型、答案抽取模型和问题分类模型,答案生成模型在训练阶段通过预测被遮蔽答案单词的原始信息,增强模型的生成能力,在测试阶段直接采用训练好的编码层,以及束搜索(Beam Search)[9]对问题和段落进行解码,生成答案;答案抽取模型采用指针网络[10]识别答案在段落中的起始位置和结束位置;问题分类模型采用线性层判断问题的具体类型。
本文实验采用CoQA[3]、MS MARCO[11]和NarrativeQA[12]三个阅读理解数据集验证模型性能。实验结果表明,本文模型在CoQA语料上取得了86.7%的F1值,比目前最好的生成模型提升了2.20%;在MS MARCO和NarrativeQA语料上的BLEU-1值分别为80.53%和57.94%,分别比目前最好的系统提升了2.39%和3.81%(绝对性能提升)。
本文的主要贡献如下:
(1) 提出基于多任务学习的生成式阅读理解模型,通过答案抽取模型和问题分类模型优化生成式阅读理解模型的性能。
(2) 本文在三个阅读理解数据集上进行详细实验,均取得了目前生成式模型的最佳性能。
1 相关工作
1.1 生成式机器阅读理解
近年来,随着如SQuAD[1]、TriviaQA[13]、SearchQA[14]、HotpotQA[2]和QuAC[15]等大规模阅读理解数据集的构建,以及在以神经网络为代表的深度学习技术和计算资源的推动下,机器阅读理解领域获得了巨大发展。目前,MS MARCO[11]、NarrativeQA[12]和CoQA[3]等数据集提供人工编辑生成的答案,要求机器能够理解问题和段落中相关句子的潜在联系,依赖一定的推理能力生成正确的答案,而非简单的文本匹配。随着生成式阅读理解数据集的发布以及自然语言生成技术的发展,研究者开始关注使用生成模型来解决阅读理解问题。McCann等人[16]和Bauer等人[17]采用基于RNN的指针生成机制进行单文档阅读理解答案的生成,Tan等人[18]在多文档阅读理解中采用管道(Pipeline)的方法,先从多篇文档中抽取出最有可能成为答案的片段,然后将该片段作为答案合成模块(Seq2Seq生成模型)的一个特征,最后综合问题、文档和抽取特征合成答案。而本文所提出的是端到端的生成式阅读理解模型,旨在让答案生成、答案抽取以及问题分类共享模型编码层参数并进行优化,最终达到提升生成模型性能的目的。
目前,预训练模型如Mass[19]、UniLM[5]、BART[20]以及ERNIE-GEN[6]等在各个自然语言生成任务中相继取得最佳性能,这些模型只需在特定任务(如阅读理解、文本摘要以及机器翻译等)进行微调就能取得令人满意的成绩。其中,Bao等人[8]提出UniLMV2模型,其使用一种新颖的伪遮蔽语言模型(pseudo-masked language model, PMLM)将自编码模型和部分自回归模型统一起来训练,在问题生成、自动摘要等多个领域取得当前的最佳性能。本文将UniLMV2模型作为基线模型,并在此基础上进行多任务学习的实验。
1.2 多任务学习
多任务学习是一种提高泛化性能的迁移机制,现有研究表明它在提高模型泛化能力上十分有效。该机制同时学习多个相关任务,让这些任务同时共享知识,利用任务之间的相关性,提升每个任务的泛化性能。多任务学习的一般做法是,在所有任务上共享模型编码层,而针对特定的任务层有所区别。例如,Wang等人[21]证明通过共享文档排序任务和多文档阅读理解任务的编码层能够提升整体的性能。Nishida等人[22]在阅读理解、文档排序和问题分类三种任务上共享问题和文章阅读模块,有效提升了模型的整体性能。Liu等人[23]提出的MT-DNN模型在BERT的基础上对4种下游任务单句分类、成对文本分类、文本相似度打分和相关性排序进行联合微调,在性能上较BERT有了极大提升,证明了多任务学习能有效提升模型的泛化性能。此外,与MT-DNN模型在下游任务上进行多任务学习不同,ERNIE 2.0[24]在模型预训练阶段引入多任务学习,通过和多个先验知识库进行交互并采用增量学习的方式,使得模型能够学会多样化的语言知识,最终在各种下游任务上性能得到提升。
受到上述工作的启发,为了解决现有的生成式阅读理解模型缺乏对答案边界信息和问题类别信息的理解的问题,本文提出基于多任务学习的生成式阅读理解模型,通过答案抽取模型和问题分类模型优化生成式阅读理解模型性能。
2 基于多任务学习的生成式阅读理解模型
本节首先给出生成式阅读理解问题的形式化定义;然后介绍模型的编码层;最后介绍模型的任务层,其具体由答案生成模型、答案抽取模型和问题分类模型三部分组成。基于多任务学习的生成式阅读理解模型框架如图1所示。
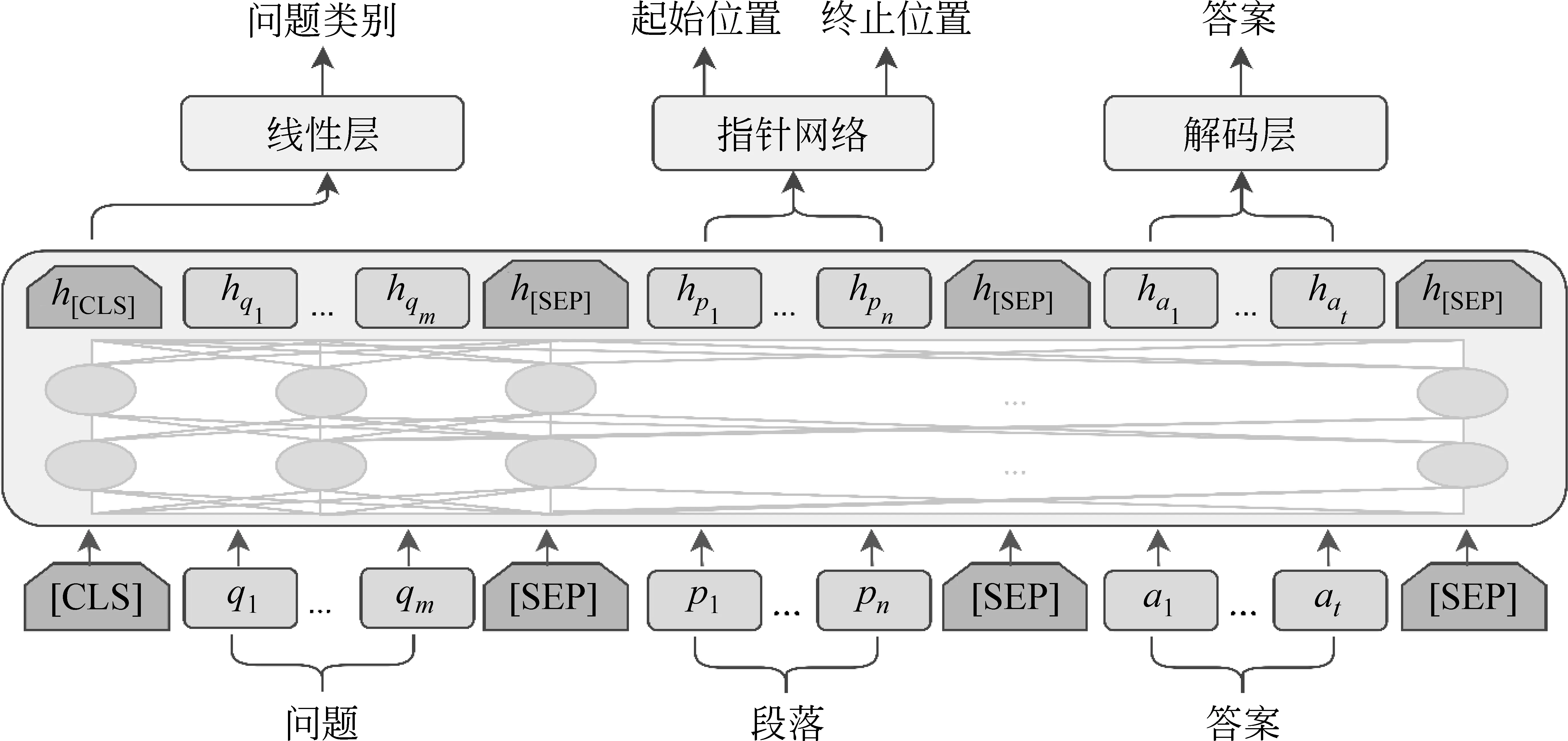
图1 基于多任务学习的生成式阅读理解框架
2.1 问题定义

(1)
其中,P(a|Q,P)表示在给定Q和P的条件下,生成答案的对数条件概率。
2.2 编码层
本文基于预训练模型UniLMv2(1)https://github.com/microsoft/unilm构建编码层,采用预训练的BERT进行问题和段落的交互,得到其表示,并在BERT的基础上改进注意力遮蔽矩阵,采用伪遮蔽语言模型,使得模型能在阅读理解任务上根据问题和段落逐字或逐片段预测被遮蔽的答案。以下介绍编码层的具体工作原理和过程。
预处理阶段,采用WordPiece分词工具,将问题、段落和答案分词,得到子词(sub-word)级别的若干词项,其中对答案中的部分词项以一定概率进行遮蔽,并将其拼接后作为模型输入。每个词项表示为词向量WE(wi)、段向量SE(wi)和位置向量PE(wi)的和,维度均为dw,其中词向量用于表示不同词项,段向量用于区分词来自源序列还是目标序列,位置向量用于表示词在输入序列中的绝对位置。词向量Xi表示如式(2)所示。
Xi=WE(wi)+SE(wi)+PE(wi)
(2)
其中,wi为第i个位置的词项。
(3)
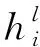
Tranformer网络由多头自注意力机制和前向神经网络两个子层组成,每个子层均使用残差连接和层正则化,因此每个子层的输出可表示如式(4)所示。
LayerNorm(x+SubLayer(x))
(4)
第l层Transformer网络的自注意力头Al计算如式(5)~式(7)所示。


图2 注意力遮蔽矩阵
通过上述词嵌入层和Tranformer网络,得到输入序列的上下文表示H1,H2,…,H12。本文使用最后一层输出H12作为整个序列的表示。H12中包含问题、段落和答案表示,其中,段落表示部分记作Hp,答案表示部分记作Ha,问题类别表示记作Hcls。根据图2所示的注意力遮蔽矩阵可知,问题和段落不会和答案进行交互,保证了训练和测试阶段Hp和Hcls所含信息的一致性。
2.3 任务层
作为基于多任务学习框架的核心部分,任务层由答案生成模型、答案抽取模型和问题分类模型三部分构成。
2.3.1 答案生成模型
训练阶段,真实答案会以一定概率被随机遮蔽,并且同时保留其原始位置信息来实现部分自回归(随机预测答案被遮蔽的片段),答案中被遮蔽的词项在经过编码后得到答案表示Ha。答案生成模块通过解码层对原始答案中被遮蔽的词项进行预测来生成答案。具体来说,Ha首先经过线性层并用Gelu函数激活后进行层正则化,如式(8)所示。
Ha=LayerNorm(Gelu(Linear(Ha)))
(8)
然后通过线性层将每个被遮蔽的词项映射到模型词表空间,获得预测分数。最后,使用Softmax函数计算词的概率向量α,如式(9)所示。
α=Softmax(Linear(Ha))
(9)
本文采用有标签平滑优化的交叉熵损失函数计算答案生成模型的目标函数,如式(10)所示。
(10)

测试阶段,模型对输入的问题和段落,每个时间步经解码层预测当前词的生成概率,同时使用束搜索每次保留生成概率最大的前k个序列,直至模型预测出[EOS]终止符结束解码。最后,模型将束搜索结果中生成概率最大的序列解码输出,其概率计算,如式(11)所示。
(11)
2.3.2 答案抽取模型
经过编码层后,段落被表示为矩阵Hp,答案抽取模型通过指针网络对答案的起始和终止位置进行识别。具体地,Hp分别经过线性层得到对应起始位置分数和终止位置分数,并通过Softmax函数对分数进行归一化,得到相应的概率向量,如式(12)所示。
s,e=Softmax(Linear(Hp))
(12)
其中,s为预测答案的起始位置概率向量,e为答案终止位置概率向量,s和e由不同参数的线性层计算得到。
本文采用交叉熵损失函数计算答案抽取模型的目标函数,如式(13)所示。
Lextract=ys·logs+ye·loge
(13)
其中,ys表示真实答案的起始位置概率向量,ye表示真实答案的终止位置概率向量。
2.3.3 问题分类模型
由于CoQA数据集中存在多种问题类型,包括事实型问题(Factoid question)、是非类问题(True/False question)和不可回答问题(Unanswerable question)。针对不同类型的问题,答案的模式通常差别较大,例如是非类问题,答案通常以“Yes/No”头。本文采用4种问题类型标签{0: yes;1: no;2: unanswerable;3: factoid},以上四种问题类型(其中是非类问题被分为两种不同类型)。如图1所示,输入经过编码后,取出[CLS]表示用于获得问题类型表示,即Hcls,并经过线性层为问题类型打分,最后将分数进行归一化后形成分类概率,如式(14)所示。
c=Softmax(Linear(Hcls))
(14)
其中,c代表问题类型的分数向量。
本文采用交叉熵损失函数计算问题分类模型的目标函数,如式(15)所示。
(15)
其中,K=4表示问题类别数,yck表示真实类别标签,ck表示预测类别标签。
2.3.4 多任务学习
本文采用多任务学习的方法,在训练阶段同时学习和更新答案生成、答案抽取和问题分类模块共享的编码层参数,让答案抽取和问题分类任务辅助答案生成任务提升阅读理解模型的性能。模型的损失由生成损失、抽取损失和分类损失三部分共同组成,整个模型的目标函数为,如式(16)所示。
LOSS=Lgenerate+λ1Lextract+λ2Lcls
(16)
其中,λ1和λ2为调和系数,用于调节辅助任务权重。
3 实验
本节首先介绍生成式阅读理解任务数据集和实验设置,然后报告本文提出的基于多任务的生成式阅读理解模型性能,并针对实验结果进行分析。
3.1 生成式阅读理解任务数据集
现有阅读理解数据集大多针对抽取式模型,即答案为篇章中的一个片段,如SQuAD[1]、HotpotQA[2]等。采用这些数据集无法全面评价生成式阅读理解模型。与抽取式模型相比,其在答案的可读性、表述的完整性及应对多段答案的问题上,均有较大区别(详见本文第一节)。基于上述原因,本文实验中采用以下三个数据集。
CoQA(2)https://stanfordnlp.github.io/coqa/(Conversational Question Answering): CoQA基于多个领域的多轮对话进行构建,并保持了人类对话简短的特征,存在大量指代和省略现象,问题和答案普遍偏短[3]。值得注意的是,为了保证该数据集尽可能贴近自然对话,其中78%的答案经过人工编辑;此外,该数据集中存在较多的是非类问题(19.8%)和不可回答问题(1.3%),部分问题无法仅采用抽取式阅读理解模型回答。尽管如此,目前在CoQA评测榜单上排名较高的均为抽取式模型,而生成式模型,如UniLM和ERNIE-GEN,仅报告了在验证集上的性能,因此,本文将CoQA的验证集作为测试集评价系统性能,调参使用的验证集从CoQA训练集中划分。
MSMARCO(3)https://microsoft.github.io/msmarco/(Microsoft Machine Reading Comprehension): MS MARCO是一个多文档问答数据集,其中特别提供了一个自然语言生成(NLG)子数据集[11],该数据集由人工编辑答案,其答案并非严格匹配文档中的片段,因此,本文采用MS MARCO(NLG)作为评价生成式阅读理解模型的数据集。注意,由于该数据集还包含了文档检索任务,而本文研究重点仅在于机器阅读理解,因此仅采用人工编辑答案时依据的文档,即最佳文档(golden passage)。此外,由于在MS MARCO评测榜单上NLG数据集同样包含了文档检索任务,因此本文仅报告模型在MS MARCO(NLG)验证集上的结果。
NarrativeQA(4)https://github.com/deepmind/narrativeqa: NarrativeQA是一个生成式阅读理解数据集,该数据集基于书本故事和电影脚本构建,答案由人工编辑[12]。本文基于数据集的摘要子集进行阅读理解,并在其测试集上进行测试。
表2列出了本文所采用三个数据集的统计数据。CoQA中存在28.7%的命名实体类问题、19.6%的名词短语类问题和9.8%的数字类问题;NarrativeQA中存在30.54%的人名类问题、9.73%的地点类问题和约10%左右的事件、实体、数字类问题,且CoQA和NarrativeQA明确允许简短、自然的答案,因此CoQA和NarrativeQA的答案普遍较短。 MS MARCO(NLG)中存在53.12%的描述型问题,且答案会融入问题信息形成完整的表述,答案普遍较长。

表2 CoQA、MS MARCO和NarrativeQA数据集
3.2 实验设置
本文使用的模型为微软开源的unilm1.2-base-uncased(5)https://github.com/microsoft/unilm,该模型在大多数自然语言生成任务上取得了最佳性能。针对不同数据集,表3列出了模型使用的超参数设置。

表3 参数设置
在CoQA多轮对话数据集中,当前问题可能存在指代或省略现象,因此本文选取当前问题之前的至多两轮问答对作为对话历史,并与当前问题进行拼接,当作完整的问题Q,同时使用上一轮答案和当前问题的词在段落中出现的频率选取文章中最佳的段落作为段落P。训练时,根据答案A计算出其在段落P中的起始位置和终止位置(答案不在段落中时,起始位置和终止位置均设为0)。实验中,问题最大长度为60,问题和段落(源序列)的最大长度为470,答案(目标序列)的最大长度为42,该数据处理与Dong等人[5]论文里的方法保持一致。模型的优化器为AdamW。
在MS MARCO多文档阅读理解数据集中,每个问题Q会给定10个参考段落,本文直接选取最佳的段落进行拼接作为段落P。训练时,根据答案A计算出其在段落P中的起始位置和终止位置(答案不在段落中时,起始位置和终止位置均设为0)。实验中,问题和段落(源序列)的最大长度为176,答案(目标序列)的最大长度为40。模型的优化器为AdamW。
在NarrativeQA数据集中,本文使用问题Q的词在段落中出现的频率选取摘要中最佳的段落作为段落P。训练时,使用F1值选取段落P中与答案A最为接近的片段作为抽取答案,并根据抽取答案计算出答案A在段落P中的起始位置和终止位置。实验中,问题和段落(源序列)的最大长度为470,答案(目标序列)的最大长度为42。模型的优化器为AdamW。
本文在CoQA数据集上使用F1值[1]来评价模型的性能,在MS MARCO和NarrativeQA数据集上使用BLEU[25]和ROUGE-L[26]来评价模型的性能。
3.3 实验结果与分析
为了验证本文基于多任务的生成式阅读理解方法的有效性,本文与以下阅读理解模型进行了比较:
UniLM[5]: 由Dong等人提出,是第一个在CoQA数据集上报告实验性能的预训练生成模型,本文在实验设置上和它保持一致。
ERNIE-GEN[6]: 由Xiao等人提出的基于多流(multi-flow)机制生成完整语义片段的预训练生成模型,在CoQA生成式阅读理解中达到了目前最好的性能。
Masque[22]: 由Nishida等人提出的多风格生成式阅读理解模型,在MS MARCO(NLG)和NarrativeQA数据集的相关指标上达到了目前的最好性能。
UniLMv2[8]: 由Bao等人提出,采用伪遮蔽语言模型的预训练生成模型,是UniLM的改进版本。本文使用UniLMv2分别在三个数据集上进行实现作为我们的基线模型,并简单修复了wordpiece分词在解码时出现的分词错误。
MLT-Model: 本文提出的基于多任务学习的生成式阅读理解模型,由答案抽取和问题分类任务辅助生成式阅读理解模型。
表4为本文提出的模型在CoQA验证集上的性能,我们的模型在F1指标上比当前性能最好的生成式模型ERNIE-GEN提升了2.2%,同时较基线模型UniLMv2提升了0.6%。本文针对预训练生成模型在答案解码时出现的子词结合不准确问题加以修复,实现的基线模型UniLMv2高于原始版本的性能,较ERNIE-GEN提升1.6%的F1值。

表4 模型在CoQA验证集上的性能
表5列出了本文模型在CoQA上的消融实验性能,在去除答案抽取任务和问题分类任务之后,性能较MLT-Model分别下降0.5%和0.7%的F1值。这是由于CoQA中存在20%左右的是非类问题和不可回答问题,这两类问题在训练阶段答案的起始和终止位置均设为0,因此仅用答案抽取任务辅助生成模型,会弱化模型对这两类问题的生成能力;而仅用问题分类任务来辅助生成模型,模型会缺少对答案在段落中边界信息的理解,所以只有将答案抽取和问题分类任务一起和答案生成任务进行多任务学习,才能从整体上提升生成模型的性能。

表5 模型在CoQA验证集上的消融实验
表6为本文提出的模型在MS MARCO(NLG)验证集上选取最佳文档的性能表现。本文模型较基线模型UniLMv2在BLEU-1指标上提升0.77%,在BLEU-4指标上提升0.95%,在ROUGE-L指标上提升0.55%。这是由于MS MARCO(NLG)数据集中答案和选定段落中的部分片段相似度较高,答案抽取任务能够辅助模型关注答案在段落中的边界信息,并增强生成模型对问题和段落中答案片段之间关系的理解,最终提升生成模型的性能。我们在同样设置下和Masque模型进行了对比,本文所提模型在BLEU-1指标上提升了2.39%,ROUGE-L指标上提升了1.84%。这主要是由于Masque模型仅使用静态的预训练词向量并基于Transformer网络进行答案生成,而本文模型基于网络更加复杂的预训练模型UniLMv2生成答案,因此在实验性能上取得较大提升。
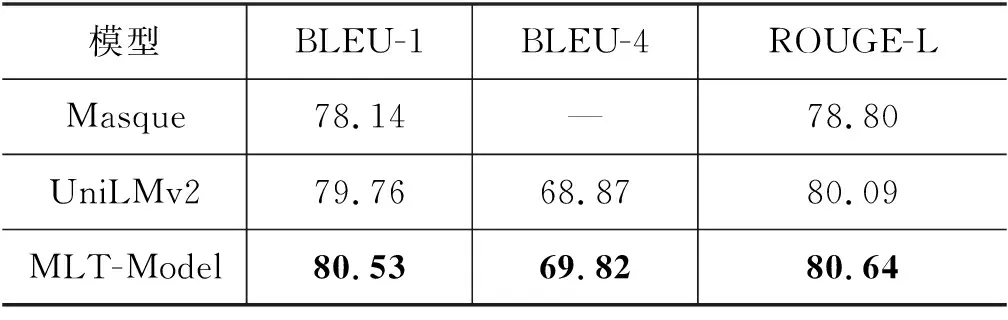
表6 模型在MS MARCO(NLG)验证集的消融实验
表7为本文模型在NarrativeQA(summary)测试集上的性能表现。本文模型较基线模型UniLMv2在BLEU-1指标上提升0.39%,BLEU-4指标上提升0.61%,ROUGE-L指标上提升0.1%。NarrativeQA数据集的答案长度普遍偏短,因此我们的模型并未在ROUGE-L指标上有明显性能提升,但是BLEU指标证明了答案抽取任务有助于生成模型生成更准确的答案。此外本文模型较目前性能最好的Masque模型在BLUE-1指标上提升了3.81%,在BLEU-4指标上提升了1.24%,但在ROUGE-L指标上下降了0.53%。可能的原因是Masque模型基于整个摘要生成答案,而本文的模型是基于规则选取的滑窗作为段落来进行生成式阅读理解,在选取滑窗时丢失了部分性能;Masque模型在该数据集上使用MS MARCO数据进行多风格学习,而本文模型并未采用增加额外训练数据的方法训练模型。我们还比较了在相同训练数据的情况下,本文模型较Masque模型在BLEU-1指标上提升了8.83%,在BLEU-4指标上提升了10.69%,在ROUGE-L指标上提升了4.6%。该提升较在MS MARCO(NLG)数据集上更为显著,主要原因为NarrativeQA的答案更偏向于推理性质的概括总结,而MS MARCO(NLG)的答案则更偏向于基于段落中的答案片段进行完整的表述,这也表明了MS MARCO(NLG)的任务难度比NarrativeQA小,预训练模型在推理方法中更占优势。
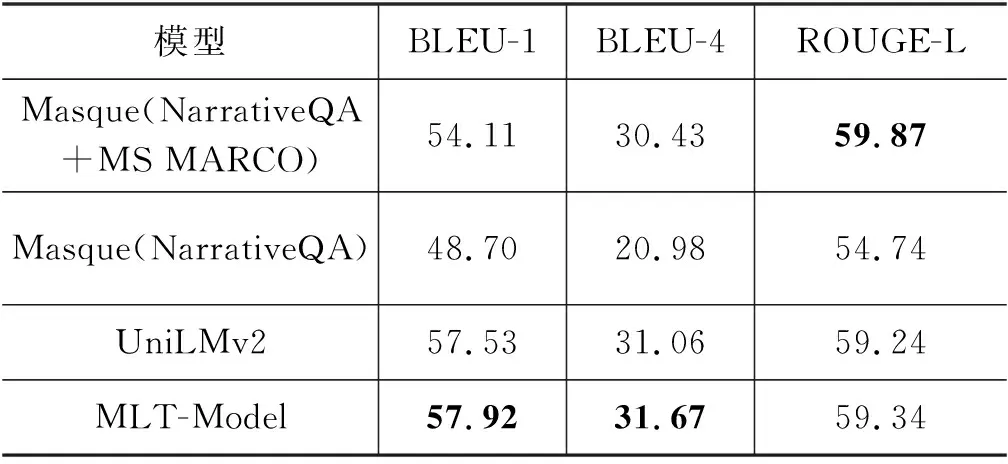
表7 模型在NarrativeQA(summary)测试集上的性能
4 结语
本文针对生成式阅读理解模型缺乏答案边界和问题分类信息理解的问题,提出一种基于多任务学习的生成式阅读理解模型,通过答案抽取模型和问题分类模型优化生成式阅读理解模型。在三个阅读理解数据集上的实验结果表明,本文提出的基于多任务的生成式阅读理解模型能够有效地学习答案的边界信息和问题分类信息,在三个数据集上均取得了目前生成式模型的最好性能。
在未来的工作中,我们将研究如何将该模型迁移至面向长文本的机器阅读理解任务上,使得该模型能够学习整个长文本的同时确定答案的边界信息,并以此生成答案。
