引入源端信息的机器译文自动评价方法研究
2022-01-20李茂西
罗 琪,李茂西
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
0 引言
机器译文自动评价是机器翻译的重要组成部分。它不仅能在一定程度上度量翻译系统的整体性能,还能在开发翻译系统时指导其特征权值的优化。因此,研究机器译文自动评价对机器翻译的发展和应用具有重要意义。
近年来,许多机器译文自动评价方法被相继提出,它们将机器翻译系统的输出译文与人工参考译文进行对比来定量刻画译文的质量。根据对比时涉及的语言知识层次,它们可分为: 基于词语匹配的方法,如BLEU[1]和NIST[2]等;基于浅层句法结构匹配的方法,如POSBLEU[3]和POSF[3]等;基于深层语义信息匹配的方法,如引入复述的指标Meteor Universal[4]和TERp[5]等;引入语义角色标注的指标MEANT[6]等。随着深度学习的发展及其在自然语言处理中的广泛应用,一些研究者利用词语深度表示和神经网络结构对比翻译系统输出译文和人工参考译文进行译文自动评价,如基于静态词向量Word2Vec[7]的方法[8]、基于动态词向量BERT[9]的方法[10]、基于神经网络结构的方法ReVal[11]和RUSE[12]等。
然而,这些方法评价机器译文的主要思路还是遵循BLEU[1]的基本观点: “机器译文越接近于人工参考译文,其译文质量越高”。从这个观点出发,译文自动评价即等同计算机器译文和人工参考译文的相似度评价。这样的译文自动评价完全忽略了源语言句子,即在没有对源语言句子充分利用的基础上进行该项任务。所以,找到结合源语言句子进行译文自动评价的切入点,势必能提高译文自动评价与人工评价的相关性。因此,我们尝试引入从源语言句子及其机器译文中提取的质量向量(Quality Embedding, QE),并将其与基于语境词向量的译文自动评价方法[10]进行深度融合来增强译文自动评价效果,提高译文自动评价与人工评价的相关性。
1 相关工作
在基于深度神经网络的机器译文自动评价中,Lo[6]和Chen等人[8]提出利用词语的分布式表示,静态预训练的词向量Word2Vec[7],来提高机器译文和人工参考译文对比时同义词、近义词和复述等匹配的准确率。Guzmán等人[13]提出了一种基于词向量和神经网络的机器译文自动评价方法,其目标是在给定人工参考译文的情况下,从一对机器译文中选择最佳译文,使用神经网络可以方便地融合由词向量捕获的丰富语法和语义表示。Gupta等人[11]用基于树结构的长短时记忆网络[14](Long Short-Term Memory network,LSTM)对机器译文和人工参考译文进行编码,根据两者之间的元素差异和夹角计算机器译文的质量得分。Shimanaka等人[12]使用双向LSTM(Bidirectional LSTM,Bi-LSTM)对机器译文和人工参考译文进行编码,并利用多层感知机回归模型计算机器译文的质量得分。Mathur等人[10]基于BERT[9]语境词向量使用Bi-LSTM网络结构学习机器译文和人工参考译文的句子表示,并将自然语言推理中启发式方法[15]和增强序列推理模型[16](Enhanced Sequential Inference Model, ESIM)引入到机器译文自动评价中,该方法在WMT’19译文自动评价任务(Metrics Task)上取得了优异成绩,因此,本文将在Mathur等人[10]的工作基础上,将利用源语言句子提取的质量向量融入译文自动评价中,进一步增强译文自动评价的性能。
2 背景知识
2.1 基于语境词向量的译文自动评价
自然语言推断关注假设结论(hypothesis)是否可以从前提语句(premise)中推断获取,它与译文自动评价任务非常类似。译文的质量越好,机器译文被人工参考译文表示(推断)的程度越高,同时人工参考译文被机器译文表示(推断)的程度也越高;反之亦然。在自然语言推断的框架下,Mathur等人[10]使用语境词向量分别表示机器译文和人工参考译文,并根据两个表示的交互程度来度量机器译文的质量。使用自然语言推断中启发式方法[15]以及ESIM方法[16],Mathur等人[10]分别提出了(Bi-LSTM+attention)BERT译文自动评价方法和(ESIM)BERT译文自动评价方法。
2.1.1 (Bi-LSTM+attention)BERT译文自动评价方法
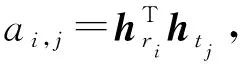
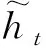
m=[t⊕r⊕(t⊙r)⊕(t-r)]
(3)
其中,符号“⊕”表示向量拼接操作;符号“⊙”表示两个向量逐元素相乘操作。最后向量m被作为前馈神经网络的输入用于预测机器译文被人工参考译文表示的程度,即译文质量的得分。
2.1.2 (ESIM)BERT译文自动评价方法
ESIM方法利用式(4)和式(5)计算机器译文被人工参考译文表示的增强向量mt和人工参考译文被机器译文表示的增强向量mr。为降低模型参数的复杂性,利用一个前馈神经网络层将mt和mr转换至模型的维度。Bi-LSTM网络用作对降维后的信息进行编码,以便得到其局部信息的上下文表示向量。将编码后的向量进行平均池化和最大池化,并将池化后的结果vr,avg、vr,max和vt,avg、vt,max进行拼接,形成固定长度向量p,即:
最后向量p作为前馈神经网络的输入用于预测机器译文质量的得分。
2.2 译文质量向量提取方法
译文质量向量是译文质量估计中描述翻译质量的向量,其从源语言句子和其相应的译文中抽取,完全不需要借助人工参考译文进行计算。目前主流的质量向量提取方法包括基于循环神经网络(Recurrent Neural Network, RNN)的编码器-解码器模型[17]的方法[18-19]和基于Transformer模型[20]的方法[21-22]。它们将源语言句子及其机器译文使用强制学习的方式输入已训练好的神经机器翻译模型,截取在使用前馈神经网络进行softmax分类前一层网络的输出向量,作为机器译文当前位置词语的质量向量。
给定源语言句子,为了获取机器译文中每个词语的质量向量,基于联合神经网络的模型(Unified Neural Network for Quality Estimation,UNQE)[19]被用作提取质量向量。联合神经网络模型使用译文质量估计任务数据集联合训练基于RNN的编码器-解码器模型和基于RNN的预测器,可以提取更优的质量向量,并且该模型在WMT18句子级别质量估计任务中取得了优异的成绩[23],证实了其效果。
3 结合质量向量的机器译文自动评价
为了把源语言句子信息引入译文自动评价中,我们以质量向量作为切入点,将给定源语言句子情况下机器译文质量的表示和给定人工参考译文情况下机器译文的增强表示进行融合。模型结构如图1所示,其中,符号src、mt和ref分别表示源语言句子、机器译文和人工参考译文。图左边部分描述通过
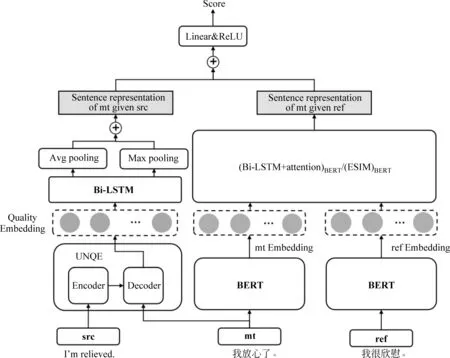
图1 引入译文质量向量增强机器译文自动评价的模型架构
UNQE方法[19]从源语言句子及其机器译文中提取出描述翻译质量的词语级质量向量,并将其利用Bi-LSTM网络处理成句子级别的质量向量;图右边部分描述通过(Bi-LSTM+attention)BERT或(ESIM)BERT方法[10]将机器译文和人工参考译文抽象为交互表示的增强向量,图上表示将质量向量与交互表示的增强向量进行拼接,将拼接后的向量输入前馈神经网络以预测机器译文质量得分。
3.1 (Bi-LSTM+attention)BERT+QE译文自动评价方法
由于从源语言句子和机器译文中抽取的质量向量是词语级的,即机器译文中每个词(token)使用一个实数向量描述其翻译质量,而机器译文和人工参考译文的交互表示增强向量是句子级的,为了在同一层次将二者进行融合,需要将质量向量进一步抽象成句子级别表示。Bi-LSTM网络被用来对词语级质量向量eqe1:k(k=1,…,lt)进行编码,得到eqe1:k的包含上下文信息的向量hqe,k(k=1,…,lt),通过对hqe进行最大池化和平均池化处理,将池化后的结果拼接即得到了句子的质量向量表示qe,如式(7)~式(9)所示。
在机器译文和人工参考译文的交互表示增强向量方面,Bi-LSTM网络被用来对人工参考译文和机器译文的语境词向量编码,利用式(1)、式(2)求得人工参考译文和机器译文的相互表示,随后利用式(8)的池化操作和式(9)的拼接操作求得人工参考译文句子表示r和机器译文句子表示t。
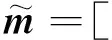
(10)
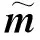
(11)
其中,参数w,W,b,b′均为前馈神经网络的权值。
为了训练模型的所有参数,译文自动评价得分yscore与人工评价得分h的均方差被用来对模型进行优化,优化目标正式描述如式(12)所示。
(12)
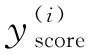
3.2 (ESIM)BERT+QE译文自动评价方法
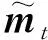

获取了机器译文句子级别分值后,我们对整个测试集(或文档集)中机器译文的句子级别得分取平均值作为翻译系统的系统级别(或文档级别)得分。
4 实验
4.1 实验设置
为了验证引入源端信息的机器译文自动评价方法的效果,我们在WMT’19 Metrics task[24]的德英任务、中英任务和英中任务上进行实验。为了比较不同译文自动评价方法的性能,我们遵循WMT评测官方的做法利用皮尔森相关系数与肯德尔相关系数分别计算自动评价结果和人工评价结果的系统级别相关性和句子级别相关性,皮尔森相关系数或肯德尔相关系数越大,相关性越好。
UNQE提取的中英、英中任务上的质量向量维度为700,德英任务上质量向量维度为500。模型中Bi-LSTM隐藏层状态维度均固定为300,Dropout设置为0.2,使用Adam优化器优化训练,初始学习率为0.000 4,训练批次大小为32,使用“bert-base-uncased”提取英文句子语境词向量,使用“bert-base-Chinese”提取中文句子语境词向量。
实验中,我们不仅将本文提出的方法与BLEU[1]、chrF[25]以及BEER[26]等经典的方法进行比较,而且与Mathur等人[10]提出的自动评价方法、与不使用人工参考译文的译文质量估计方法UNQE[19]进行了对比。需要说明的是,Mathur等人[10]是混合所有相同目标语言(如德英和中英)译文自动评价训练集语料进行模型训练,而我们引入了源端信息,考虑实际译文打分需求且避免受不同源语言差异性的负面影响,我们针对每个语言对利用其训练集数据单独训练模型。德英语言对使用的是WMT’15-17 Metrics task[27-29]德英语言对的句子级别任务数据集。对于中英和英中语言对而言,单独训练可用训练集语料规模太小,因此加入了CWMT’18翻译质量评估在中英和英中语言对上的语料。德英方向按照9∶1的比例划分训练集和开发集,中英和英中方向完全使用CWMT’18翻译质量评估数据的训练集和开发集,具体数据统计如表1所示。测试集为WMT’19 Metrics task的数据集,具体数据统计如表2所示。
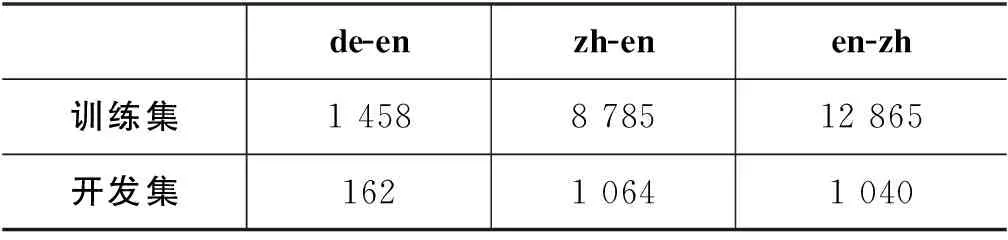
表1 德英、中英和英中训练集、开发集数据统计
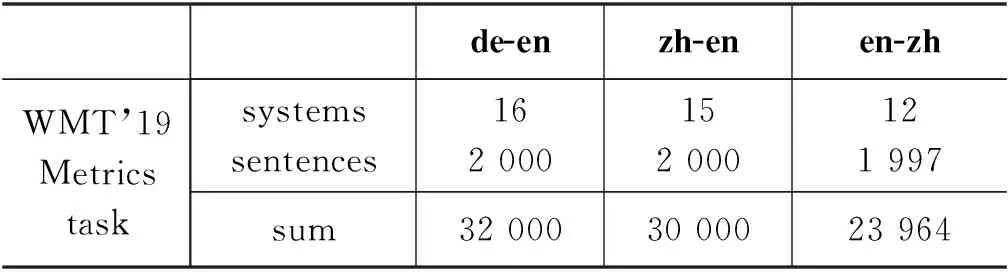
表2 WMT’19 Metrics task德英、中英和英中任务的测试集数据统计
4.2 实验结果
表3和表4分别给出了在WMT’19 Metrics task上引入源语言句子信息的译文自动评价方法和对比的译文自动评价方法与人工评价的句子级别和系统级别的相关性。
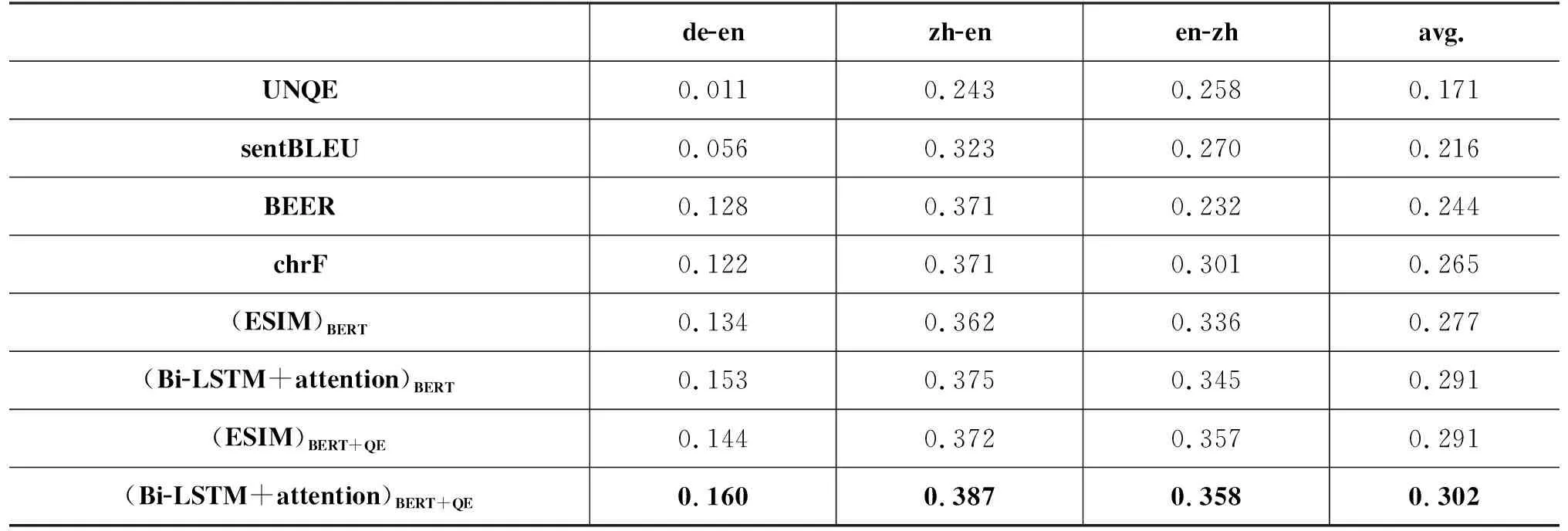
表3 在WMT’19 Metrics task的德英、中英和英中任务上自动评价与人工评价的句子级别相关性
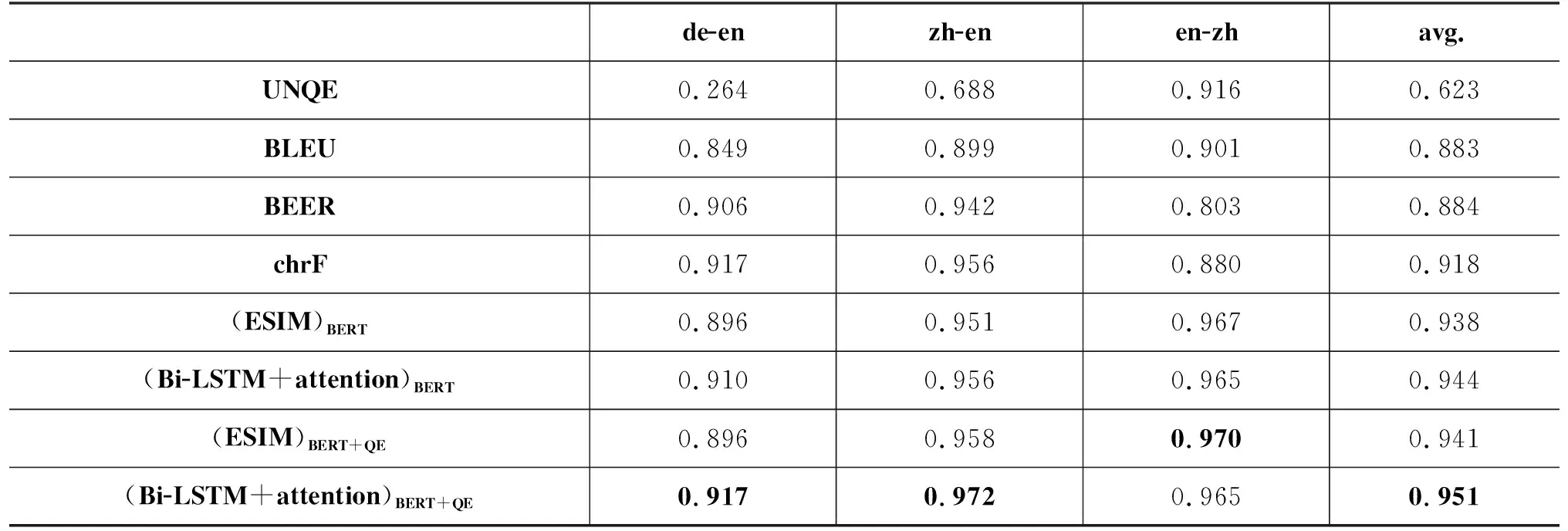
表4 在WMT’19 Metrics task的德英、英中和中英任务上自动评价与人工评价的系统级别相关性
表3的数据表明引入源语言句子信息的方法“(Bi-LSTM+attention)BERT+QE”和“(ESIM)BERT+QE”在德英、中英和英中三个语言对上,与人工评价的句子级别相关性均值分别高于使用语境词向量的方法“(Bi-LSTM+attention)BERT”和“(ESIM)BERT”。“(Bi-LSTM+attention)BERT+QE”相对于“(Bi-LSTM+attention)BERT”在德英、中英、英中三个任务上分别提升了4.6%、3.2%和3.8%,“(ESIM)BERT+QE”相对于“(ESIM)BERT”方法分别提升了7.5%、2.8%和6.3%。其中,“(Bi-LSTM+attention)BERT+QE”方法在三个语言对任务中句子级别相关系数均最高。这说明引入源端信息能增强机器译文自动评价与人工评价的句子级别相关性。
表4的数据表明,本文所提方法“(Bi-LSTM+attention)BERT+QE”和“(ESIM)BERT+QE”在德英、中英和英中三个语言对评测任务上,与人工评价的系统级别相关系数的均值分别高于“(Bi-LSTM+attention)BERT”和“(ESIM)BERT”。“(Bi-LSTM+attention)BERT+QE”相对于“(Bi-LSTM+attention)BERT”方法在德英、中英任务上提升了0.8%和1.7%,在英中任务上保持一致,“(ESIM)BERT+QE”相对于“(ESIM)BERT”方法在中英、英中任务上分别提升了0.7%和0.3%,在德英上保持一致。这说明引入源端信息能增强机器译文自动评价与人工评价的系统级别相关性。
令人惊奇的是,仅使用源端信息,完全不使用人工参考译文的UNQE方法,也与人工评价结果有较好的相关性。尽管其在平均相关性上劣于所有使用人工参考译文的方法,但是它与sentBLEU方法在平均句子级别相关性和平均系统级别相关性上的差距并不大,在英中的句子级别相关性(0.258)上甚至稍高于BEER方法(0.232),在英中的系统级别相关性(0.916)上高于BLEU(0.901)、BEER(0.803)、chrF(0.880)等方法。这说明源端信息对译文自动评价非常有帮助,从一个侧面佐证了正确地将质量向量引入译文自动评价必将提高译文自动评价的性能。
4.3 实验分析
为了进一步分析融合源端信息的译文自动评价方法的特点,我们在开发集上分别抽取了中英和英中翻译自动评价的实例进行分析。表5给出了对两个译文进行打分的实例,其中HTER是指将机器译文mt转换成人工后编辑的参考译文ref需要的最少编辑次数与译文长度的比值,它可以看作是译文人工打分的结果。自动评价方法对机器译文的打分越接近人工打分(1-HTER),表明该自动评价方法对译文的评价越准确。

表5 不同自动评价方法对机器译文打分实例
在第一个实例中,源语言句子中“对城市交通来说”在机器译文中缺乏对应翻译,存在漏译的情况,但(Bi-LSTM+attention)BERT和(ESIM)BERT却给了很高的分值,而本文的方法打分均更接近人工HTER分值,说明(Bi-LSTM+attention)BERT+QE和(ESIM)BERT+QE方法结合了源语言句子信息对译文进行评价,能更准确地描述译文的完整度特征,因此,相比于仅结合人工参考译文信息打分的(Bi-LSTM+attention)BERT和(ESIM)BERT方法,引入源端信息的方法的评价更准确。在第二个实例中,机器译文中存在多译、过度翻译的情况,源语言句子中“Tokyo, Japan”被过度翻译成“东京”和“日本”两个地方。对于这种情况,本文方法依然比(Bi-LSTM+attention)BERT和(ESIM)BERT更接近人工打分结果HTER。这定性地说明结合源端信息的机器译文自动评价方法能更充分地利用源语言句子的信息对译文质量进行评价。
5 结论
本文提出引入源端信息的机器译文自动评价方法。与传统的BLEU、BEER、chrF等评价指标相比,引入源端信息的机器译文自动评价方法,融合了源语言句子、人工参考译文、机器译文三者的信息,能更全面且有效地描述译文质量。未来的工作中,我们将尝试在更大的语料库、更多的语言对上进行实验,以及引入更先进的模型和方法来挖掘源端信息,以提高机器译文自动评价方法的性能。
