基于依存图网络的汉越神经机器翻译方法
2022-01-20普浏清余正涛文永华高盛祥刘奕洋
普浏清,余正涛,文永华,高盛祥,刘奕洋
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
0 引言


图1 汉越双语语序对应图


图2 汉、越依存句法解析树对照图
于是本文提出了基于依存图网络的汉越神经机器翻译方法,并作出了以下两点创新:
(1) 在编码端,利用双编码器分别实现对依存关系和序列信息的编码。其中图编码器,实现对源语言的依存关系进行依存图结构的向量化编码,序列编码器实现对源语言的序列信息进行编码。
(2) 利用图-序列注意力机制,将两个编码器分别生成的依存图信息和序列信息融入翻译模型中,对译文的生成起到指导作用。
1 相关工作
当前,基于句法融入的翻译研究主要包括短语句法融入和依存句法融入。短语句法能够反映句子内部的成分信息,包括名词短语,介词短语,动词短语等。在短语句法融入方面,Liu[1]证明了利用源语言的句法知识,对于提高双语的词对齐和翻译准确率是有帮助的。He等人[2]提出了一种融合词根位置特征的汉-越机器翻译方法。利用状语位置、定语位置和修饰语的排序信息,定义了具有句法特征的排序块,将这种排序块融进基于短语的统计机器翻译模型中,并对解码结果进行重排序,得到符合越南语语序的译文。针对传统的序列编码器无法处理短语树结构的问题,Eriguchi等人[3]提出了树到序列的翻译模型,该模型首先利用循环神经网络[4](Recurrent Neural Network, RNN)对源语言的序列进行编码,在得到的隐向量基础上,采用Tree-LSTM[5]结构的编码器实现对源语言的短语结构进行建模。但这种自底向上的树编码结构,会导致只有顶层节点拥有丰富的句法信息,而底层节点缺乏全局句法信息的问题。于是Chen[6]等人在Eriguchi工作的基础上,提出了双向树结构的编码器,引入了基于树的覆盖机制,通过自底向上和自顶向下的双向编码的方式对句法树进行全局覆盖,实现了句法信息自底向上和自顶向下的信息流动,可以获取更多的源语言上下文信息,使模型的翻译性能得到了提升。Li等人[7]将短语句法结构转化为线性序列,通过RNN网络进行编码,避免了Tree-LSTM的复杂网络结构。Nguyen[8]等人针对短句句法树的层次结构特点,提出了一种层次累积的算法。将短语句法树向量化后的结果全部映射到一个二维矩阵中,然后对矩阵进行纵向和横向的累加操作,得到整个短语句法树向量化后的结构信息,最后将该向量化的结构信息和序列信息送入翻译模型中,利用交叉注意力机制实现在翻译模型中对短语结构信息的融入。相比短语句法,依存句法可以提供单词之间的关联关系。在依存句法的融入翻译模型的方法中,Sennrich[9]提出一种在源语言端融入依存句法的翻译方法,将依存关系标签,词性标签,词根等信息编码成特征向量,与词向量拼接作为输入向量,注意力模型和解码器保持不变。Chen[10]等提出了一种基于源语言依存结构的词向量表示,该向量包含本节点的父节点,子节点,和兄弟节点,最后将该向量作为编码端的输入送入翻译模型中。Wang[11]提出了一种基于自监督的依存句法感知的神经机器翻译方法,在基于Transformer[12]模型的框架下,不利用外部句法解析工具,将编码端的多路注意力机制自监督的学习源语言的依存句法信息,同时融入到翻译模型中。
依存句法通过树结构显示地表示词之间的依存关系,现有融入依存句法树的翻译模型,一般利用邻居节点信息,实现对依存句法层次化的结构信息进行建模和利用。本文考虑将依存树转化为依存图,基于图结构可以捕获远距离节点之间的依存关系,同时将边转化为图中的节点,实现对边信息的编码,从而获取全局化的依存句法图的结构信息。基于以上思想,本文提出了一种基于依存图网络的汉越神经机器翻译方法,将依存树转化为依存图,并利用图神经网络实现对源语言的依存图结构信息进行全局的向量化表征。并将该表征融入到模型的编、解码端,让翻译模型充分地学习源语言的依存约束关系,从而指导译文的生成。
2 基于依存图网络的汉越神经机器翻译
本模型在Transformer模型的框架上进行了扩展(图3)。该模型框架分为两个部分,第一部分是图编码器,对源语言依存图结构进行编码,获取全局的依存结构信息。第二部分是传统的Transformer结构。在序列编码器和解码器中,新增加一个图和序列的注意力机制,实现对图结构信息和序列信息的融合。下面,将详细展开介绍模型框架的内容。
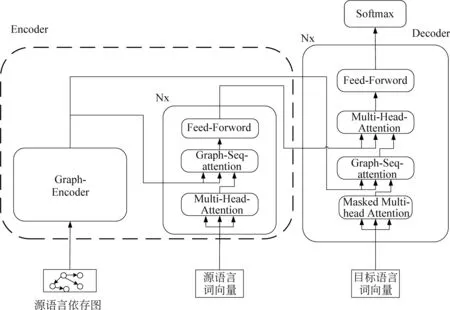
图3 模型图
2.1 依存图构建
首先将依存句法解析树转化为有向连通图,如图4所示。在转换的过程中对词节点和关系标签进行向量化表示,其中,词节点根据词表进行向量化,关系标签根据标签词表进行向量化。最后定义图集合为:G=(v,e,lv,le),v是节点集合(v,lv),e是边集(vi,vj,le),其中,lv,le分别是词节点和边信息标签词表。
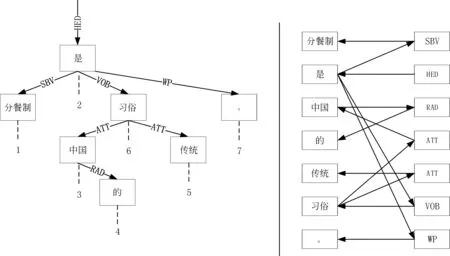
图4 依存树向依存图的转化
2.2 依存图编码器
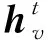
(1)
(2)
(3)
(4)
(5)
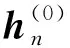
(6)
其中,i,j为神经网络的时间步。
2.3 依存图结构信息的融合
利用图和序列的注意力机制分别在Transformer模型的编码端和解码端进行依存图结构信息的融合。
2.2.1 编码端融合依存图
首先,在编码层上进行了扩展。原始的编码器包含两个子层,第一层是多头自注意力层,第二层是前馈神经网络层,如图3所示,在两个子层之间增加了一个图和序列的注意力机制,用来融合图结构信息和序列信息。在源语言序列X={x1,x2,x3,…,xn}输入编码器之前,会先对其进行向量化表示。通过词嵌入矩阵将源语言映射到一组连续的空间,得到词嵌入向量E。在映射的过程中,会加入序列的位置向量,如式(7)所示。
E={e1,e2,…,e3,…,en}
en=e(xn)+pn
(7)
e(xn)表示词嵌入向量,pn表示位置嵌入向量。位置嵌入向量是使用正余弦函数计算地得到的。对于第n个词的位置嵌入向量pn,如式(8),式(9)所示。

(10)

(11)
系数dmodel的作用是进行缩放操作,缩放可以尽量减少相关性矩阵的方差,具体体现在运算过程中实数矩阵中的数值不会过大,有利于模型训练。在第二层的图-序列注意力子层(图3),通过Multihead机制,实现对源语言的图结构信息G和源语言的序列信息D相互关注和融合,得到融合向量N,如式(12)所示。
N=MultiHead(D,G,G)
(12)
在第三个前馈神经网络子层,对向量N进行残差链接和归一化计算,最终得到序列编码器的输出向量S,如式(13)所示。
S=LN(FFN(LN(N)+LN(N)))
(13)
其中LN是归一化操作,FFN是前馈神经网络。
2.2.2 解码端融合依存图
对于长度为j的目标序列Y={y1,y2…,yj},对其向量化和增加位置向量后,得到其词嵌入序列T={t1,t2…tj},T∈dmodel×j。如图3所示,在解码层,同样增加了一个图和序列注意力机制的子层。目前每一个解码器内部包含四个子层,第一个子层是目标端的多头注意力机制,用来计算目标序列的上下文向量M,如式(14)所示。
M=MultiHead(T,T,T)
(14)
第二层是图-序列注意力层,将图编码器的输出的结构向量G和第一层输出的目标语言上下文向量M进行关注,如式(15)所示。
B=MultiHead(M,G,G)
(15)
第三层是编码-解码注意力层,将图-序列注意层输出的关注向量B和Transformer的序列编码器输出的源语言上下文向量B进行多头计算,如式(16)所示。
H=MultiHead(B,S,S)
(16)
第四层是全连接的前馈神经网络层,利用上一层的输出向量H,计算得到当解码器输出的目标端的隐向量F,如式(17)所示。
F=LN(FFN(LN(H)+×H)))
(17)
将F={f1,f2,…,fj}映射到其中目标词表空间,通过softmax层计算得到目标词yj的概率分布,如式(18)所示。
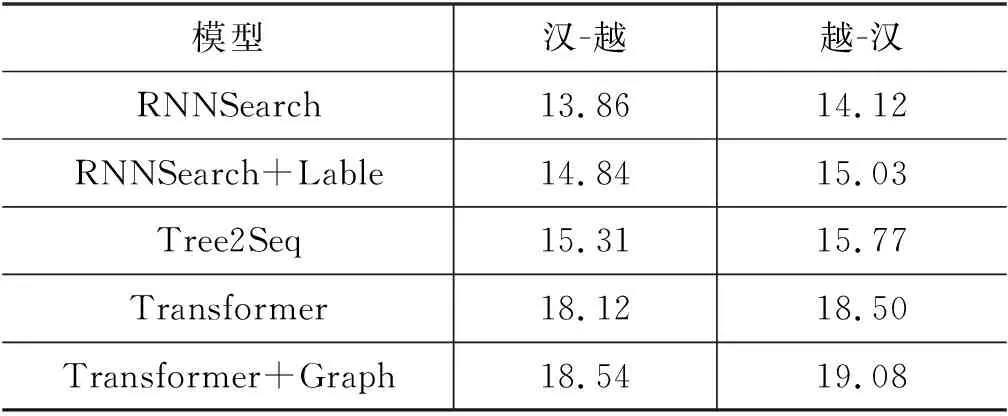
p(yj,|X,y (18) Fj∈dmodel×j为预测第j个目标词的词向量。 在训练过程中,依存图信息已和源语言融合,于是本文仍然基于标准的Transformer模型,训练标准的最大似然函数直至收敛,如式(19)所示。 (19) 其中θ是模型训练的参数。 为验证本文提出的融合依存图的汉越神经机器翻译方法,分别在汉-越,越-汉翻译方向上进行了实验。其中,汉-越语料通过互联网爬取150k的汉越平行语料,通过代码判空,过滤清洗掉无用的特殊字符,并把平行语料中,中文端的句子长度控制在10到100个字符长度之间。为了验证平行语料对的语义相似性,通过调用fast_align(1)https://github.com/clab/fast_align工具包对平行句对进行相似度计算,过滤掉语义差距较大的平行句对,最后将其分成训练集,测试集,验证集,如表1。在依存句法树获取方面,利用LTP(2)http://www.ltp-cloud.com/语言云平台对中文数据进行分词及依存句法解析,利用VnCoreNlp(3)https://github.com/vncorenlp/VnCoreNLP工具对越南语进行分词及依存句法解析,分别获取中文和越南语的解析结果。源语言和目标语言均保留50k的词表大小。 表1 数据集 本实验的模型是在Transformer模型框架下进行了扩展。其参数设置为: 批次大小为4 096,句子最大长度为256,学习率设置为1×10-4,词嵌入的维度512,编码器和解码器层数都设置为6层,多头注意力的头个数为8,训练轮次为epoch=30,dropout=0.3,采用的优化器为Adam,其中GGNN编码器层数设置为8。 选择Transformer[12]、Tree2Seq[3]、RNNSearch+Lable[7]、RNNsearch[4]作为对比实验的基准模型,下面将对这四种模型进行介绍: (1)RNNSearch: 基于传统的RNN神经网络,实现的神经机器翻译模型。其参数设置为: 编、解码端的网络层数为3层,每层隐含单元数为512个,并用1.0初始化LSTM的遗忘门偏置项。 (2)RNNSearch+Lable: 该模型是在RNNSearch的基础上,将源语言的依存句法标签向量化,作为外部知识,拼接在源语言的词向量后面融入翻译模型。其参数设置和RNNSearch保持一致。 (3)Tree 2Seq: 短语树到序列的翻译模型,基于Tree-LSTM实现短语句法树的融入。训练的参数和本文模型一致。本模型所需要的越南语短句法分析结果,采用李英[15]等人的越南语短语句法解析工具对越南语进行句法解析。 (4)Transformer: 最原始的Transformer。其参数设置和本论文提出的模型一致。 本文的实验采用单张Tesla K40m GPU进行实验。翻译结果的测评实验是通过BLEU值进行评分的。 本实验利用筛选出来的150k语料进行汉-越翻译和越-汉翻译任务,实验结果如表2所示。 表2 对比实验结果 在本次双向翻译任务中,对比分析表2中的实验结果,可看出Tree2Seq、RNNSearch+Lable在汉-越翻译任务上,比RNNSearch的翻译结果分别高1.45个BLEU值和0.98个BLEU值,在越-汉翻译任务上分别高1.65个BLEU值和0.91个BLEU值,说明将源语言的依存句法知识融入翻译模型对翻译效果的提升是有明显助益的。Transformer在不融入依存句法知识的情况下,比前三个翻译模型都取得了更好的BLEU值,说明Transformer模型本身的高效性能。本文提出的Transformer+Graph翻译模型在汉-越和越-汉翻译任务上,分别比Transformer高0.42个BLEU值和0.58个BLEU值,说明本文提出的基于依存图网络融合依存句法的翻译方法,可以更好的利用源语言的依存句法知识,也说明利用图编码器获取的全局依存句法结构知识,对提升翻译质量是有效的。 3.3.2 验证依存图结构信息在编、解码端产生的影响 为了验证源语言的依存图结构信息在编、解码端的作用,设计了消融实验,并与以下模型进行对比,定义 “Enc+Graph”表示只在编码端融合源语言依存图信息,“Dec+Graph”表示只在解码端融合源语言依存图信息,“Transformer+Graph”表示本文提出的完整模型框架。 从表3实验结果可以看出: 在汉-越翻译任务和越-汉翻译任务上,将源语言的依存图结构信息分别用于编码端和解码端,比原始的Transformer翻译结果均有BLEU值的提升,说明源语言依存句法知识对于翻译任务是有帮助的。“Enc+Graph”比“Dec+Graph”的翻译BLEU值高,说明在编码端利用多头注意力机制将源语言的依存图结构信息和序列信息融合,更有助于模型充分学习源语言内部的依存约束关系。本文提出的Graph+Transformer翻译模型在本次汉-越和越-汉翻译任务中取得了最好的翻译结果,BLEU值最高,说明在编、解码端都利用源语言的依存图结构信息,对于指导目标译文的生成更有帮助。 表3 消融实验 表4 融入依存句法的译文质量对比 在本文提出的翻译模型结果中,将依存句法知识融入翻译模型后,很明显地可以看到译文的语序更符合目标语言的句法语序,说明源语言的依存句法对于翻译模型学习源语言本身的依存约束关系是有帮助的,可以让翻译模型更有效的学习到源语言和目标语言之间的语序差异,在解码时,起到指导模型生成符合目标译文语序的作用,从而达到提升模型翻译质量的目的。 本文针对汉越低资源翻译任务,基于Transformer的模型架构,提出了一种基于依存图网络融合源语言依存句法的汉越神经机器翻译方法。通过实验证明,在低资源场景下,依存句法信息的融入,对具有句法差异的汉-越翻译任务是有所助益的。同时,将依存关系转化为依存图,利用图神经网络实现对依存图结构的全局化编码,给翻译模型提供了更丰富的全局依存信息。未来工作中,我们将会继续研究在解码端融入目标语言依存句法的翻译方法。3 实验与分析
3.1 数据获取及处理

3.2 实验模型参数设置
3.3 对比实验设置及结果分析3.3.1 依存句法对翻译结果的影响

3.4 译文示例分析


4 结论
