在线论坛中学习者兴趣与行为主题联合建模研究*
2022-01-18王志锋刘清堂
张 思 陈 娟 夏 丹 王 涛 王志锋 刘清堂
(华中师范大学 人工智能教育学部,湖北武汉 430079)
一、引言
“互联网+”时代,在线教育已成为一种新常态。依托在线学习平台,学习者在论坛中可自由发表个人看法和主观感受,以及和他人进行社会性互动(朱祖林,2015)。在线论坛也有助于教师快速掌握学习者的学习状况,包括学习态度和知识建构水平,便于及时答疑解惑、提供反馈,因而被越来越多的高校教师所采纳(刘智,等,2018)。在线论坛中生成着大量非结构化数据,包括文本和图片,以及音视频资料等(孙洁,等,2017),而文本是其中最常见的一种媒体形式。学习者在论坛中所发帖子,真实地体现了他们在某一阶段的情感状态、学习动机、知识建构以及认知发展水平等(左明章,等,2018)。深入挖掘学习者的实际需求、“学习痛点”并提供帮助,可为个性化服务提供参考(潘芳,等,2021)。学习者在在线论坛中的互动行为和潜在的情绪状态,也被证明是影响学习绩效的关键因素(Kaplan,et al.,2016)。
情感分析目前已被广泛应用于各领域,并成为教育领域的研究热点之一(Zhou,et al.,2020)。从文本大数据中发现学习者潜在的关注点和情感变化,进而挖掘学习者兴趣所在,有助于教师了解和深入剖析学习者潜在的学习偏好。而探究学习者情感状态与学习成绩的关系,则有助于教师实现对不良状态的精准干预(张文梅,等,2021)。教学情境的数字化,使得学习行为数据化成为可能。相较于传统的教学方式,在线论坛能帮助教师和研究者更为便捷地获取学习者多维度的行为数据。运用相关理论对学习者潜在行为进行分析,不仅可以促进教学模式多元化、教育资源个性化,为个性化教学提供新的发展方向; 而且对于教师在教学过程中有针对性地进行教学调整,也有一定的帮助(张志龙,等,2020)。
但目前研究,大多是将在线论坛中学习者的情感和行为进行孤立分析,缺少对二者的联合建模,以及在时间维度上观察联合分布的变化趋势。为此,本文旨在构建一种基于行为—情感—主题—时间的联合主题挖掘模型,以挖掘并探究在线论坛中学习者兴趣和行为主题的联合变化,及其与学习成绩之间的关系,以便为在线论坛中的高质量社会性互动提供依据。
二、相关研究
(一)情感分析与兴趣建模
情感分析(Sentiment Analysis,SA),即对给定文本或文本中某一片段的情感极性或者情感强度,进行分析和辨别(张志华,2016)。作为一门多学科融合的交叉学科(周佳勇,2020),情感分析已经成为自然语言处理领域研究热点之一(王艺皓,等,2021)。目前,情感分析相关技术包括情感词典、传统机器学习与深度学习等。基于词典的情感分析是依据人类的先验知识构建词典,以此为基准,来对文本或语料中包含的情感词或固定搭配进行比较计算,得出文本的情感向量(陆文星,等,2012)。情感词能在一定程度上体现文本情感倾向(陈迪,等,2021)。有研究者构建了包含积极、消极与混淆三种类别的情感词典,对SPOC 论坛中学习者帖子的情感进行计算和可视化分析,并比较了不同绩效组学生的情感差异(Liu,et al.,2018a)。还有研究者创建了词汇数据库,把情感等级分为-3 到+3,以对词汇的情感极性进行定义(Aung,et al.,2017)。张公让等人(2021)以“百度口碑网”中快递服务企业的客户评论文本数据为例,使用词云图、语义网络、LDA 主题模型,对评论数据进行特征分析,并构建情感词典获取评论的情感得分,用于分析客户的情感倾向与影响因素。
基于机器学习的方法首先是对训练数据进行情感极性标注,然后依据标注好的数据集进行特征提取和建模,并让算法对已有数据集进行学习和训练,进而实现对情感极性的精确获取(李科,2017)。阿尔特拉布谢等人(Altrabsheh,et al.,2015)借助机器学习算法,对数据进行特征提取和分类训练,达到对学习者的反馈进行情感分析的目的。而较机器学习而言,基于深度神经网络的情感学习方法使用多层非线性网络建模,达到对文本信息的深层挖掘及其深层特征的捕捉,实现对语义的深度探索,目前应用较多的是BERT 语言预训练模型。王艺皓等人(2021)基于BERT,构建了一种深度学习情感分析模型,以解决粗粒度和细粒度情感分析和预测问题。实验结果表明,该模型的预测效果较好。潘芳等(2021)在BERT 模型的基础上,进行增强与改进,提出RPBERT 模型,解决了原模型在做情感分析时容易过拟合的问题,还增加了情感分类层对情感进行正负极性分类与分析。此外,研究将兴趣主题挖掘与社交网络联系起来(李鹏飞,等,2019),通过构建兴趣主题相关模型,实现对用户关注内容的挖掘,从而优化个性化服务系统(刘雷,2019)。
在兴趣主题建模上,较为常用的模型是潜在狄利克雷分布主题模型 (Latent Dirichlet Allocation,LDA)。LDA 主题模型是一个无监督的机器学习方法,包含了词、主题和文档三层结构,模型运用词袋模型(刘朋,2017),把文档看作词频向量的集合,忽略其中的词汇和词组出现的先后顺序(秦永彬,等,2019)。很多学者从LDA 模型出发,结合研究需要,对模型进行改进与更新。有学者针对SPOC 论坛中的文本数据,将情感与时序、主题联合建模,提出了TEAM 模型,并结合论坛数据,发现并揭示学习者情感变化趋势及差异(Liu,et al.,2019)。高永兵和许庆端(2019)对LDA 模型进行改进,并将其应用到对微博用户的兴趣挖掘上,试图得到一个更为准确的兴趣挖掘模型。楼小帆(2017)为解决LDA 在文档生成时产生强制分配的问题,构建了Label-LDA 模型。相较于传统的LDA,Label-LDA 模型多了一层对原文档类别的人工标注与分类,完成对用户兴趣主题的提取与预测。冯新淇等(2017)在原有LDA 模型的基础上,加上微博热度排行,提出了RLDA 模型。
(二)教育文本中的行为挖掘
作为教育文本挖掘领域的研究热点,学习行为的分析与表征,对学习者分析、 课程设计与知识推送、 学习效果的评价与诊断,有着至关重要的作用(张昕禹,等,2019)。在数据源上,有学者通过分析社交网络中用户的表情和使用行为,提出了基于表情的用户交互式系统研究框架,该框架能针对用户的不同需求进行推荐(王媛,2020)。有研究针对学习者的外显或内隐学习行为,构建了网络学习空间中不同类型学习行为数据的学习分析模型,从学习者的点击偏好、认知状态、交互状态、情感倾向和关注主题等方面,对行为进行分析和可视化(赵蓉,2019)。也有从真实数据出发,对互联网中出现的“水军”行为模型和策略进行设计和研究 (Zeng,et al.,2014)。在行为分析方法上,有学者借用序列分析法,例如,赵宇环(2019)通过对在线社交平台中用户的个人数据,进行行为时序分析,探究个体的行为特点和规律,并提出概率预测模型以对个体行为进行预测。关海潮(2018)从行为序列出发,研究用户之间行为的相似度以及关联规则,从而发现和挖掘用户之间的潜在关系和异常行为。此外,科尔曼等从LDA 的视角出发,对学习者的点击流数据,包括页面访问数据进行深入探究(Coleman,et al.,2015)。
在线学习平台记录着学习者在学习过程中产生的各类行为数据,该数据既包含讨论文本数据,也包含学习者的浏览和访问记录,这些数据往往能反映学习者在特定学习过程中的真实情况。对研究学习者的学习动机、认知发展、情感态度与学习体验大有帮助。罗杨洋和韩锡斌(2021)通过对学生的在线学习行为进行聚类与特征提取,提出了一种对课程进行分类的方法,并实现机器的自动化分析和分类,为教师设计和实施个性化混合课程提供帮助。尹美贤等人(Meehyun,et al.,2021)从在线学习的日志数据中,发现了学习者观看视频时的四种行为模式:浏览、社交、资源查找与环境配置。针对教育资源与学习者实际需求之间的差距,董慧嵘(2019)从学习者的学习行为数据出发,使用评估模型对学习者的学习能力进行评估,并根据数据的不同为学习者提供不同数量的评估方法,以达到评估的高准确性。陈静(2020)则分析了学习行为对学习效果的影响,并就得出的影响因素模型建立了因果贝叶斯网络,从而理解哪些行为模式会对学习效果产生较大的影响,进而可以有计划地对较差的行为模式进行干预。
部分研究通过构建模型,来对学习者的行为进行评估和预测。如,构建B-LDA 行为主题模型,以表征用户在Twitter 上的行为模式 (Qiu,et al.,2013)。王宾杰(2021)构建了视频教学中各类行为的标签数据库和行为标签模型,并基于文本挖掘的方法,构建了教学智能评价模型,以此来对师范生的教学技能进行评价。艾谢等人(Ayse,et al.,2020)通过自主构建的互动模型,对MOOC 中学习者的学习记录和痕迹进行分析,基于此了解学习者的课堂参与情况,并对学习者未来的行为模式进行预测和推断。王亮(2021)针对学习者与教学平台提供的教学资源之间的交互行为,将关注点聚焦在交互行为的时间序列上,以构建行为预测模型。
综上,越来越多的研究把焦点放在教育文本的兴趣主题挖掘和行为分析模型的构建上,试图通过预标记的数据对模型进行训练和完善,并借助算法实现对未知学习情况的智能分析、预测与评估,以帮助其改进教学。而在兴趣主题和行为倾向的联合分析方面,SBTM 模型联合挖掘帖子的情感倾向和行为交互概率,实现了四个层次(学习者层、主题层、情感行为层和词层)的相互映射(Peng,et al.,2021)。
但情感和行为联合后,相关分布对学习成绩将产生什么样的影响,该分布又呈现怎样的演化趋势?针对这一问题,本文旨在构建兴趣主题、行为分析、时序关联的文本挖掘模型,通过模型对在线论坛中的发帖数据进行深层挖掘,探究在特定行为、特定情感中学习者的关注主题对学习成绩的影响作用,并借助发帖时间,探究论坛中各类兴趣主题和行为联合分布的演化趋势。
三、模型构建
话语分析是通过分析特定情境中的互动,探索话语中潜在的语义和关系,达到构建有意义的教学互动的目的(潘芳,等,2021)。LDA 主题模型,使用Dirichlet 分布得到文档—主题分布和主题—词分布(Li,et al.,2018),其主要思想是首先依据一定的概率,从主题向量中选取主题,然后以一定的概率,从该主题所拥有的词向量中选择词组成文档,以此来对话语进行分析。在话语情感建模中,通常是把情感作为变量放入LDA 模型,如,TEAM 模型,把情感—主题对作为一个整体,来对话语中的情感进行分析,并联合时间分析学习者的情感演化趋势(Liu,et al.,2019)。在情感和行为的联合建模上,有研究者在LDA 模型的基础上,纳入行为和情感两个因素,通过先确定主题,再确定主题所属的行为和情感的方式,挖掘话语的潜在语义(Peng,et al.,2021)。鉴于在线论坛中学习者兴趣主题和行为分析多是孤立研究的现状,本文在LDA 模型的基础上,综合学习者的情感、行为与发帖时间等多个维度,构建了融合行为—情感—主题—时间的潜在语义分析模型,即BETTM(Behavior-Emotion-Time-Topic Model),以致力于挖掘四者之间潜在的关联关系。
在BETTM 模型中,利用情感词典作为输入源,以判断帖子的情感概率,深入挖掘学习者在整个教学过程中的兴趣主题演化。行为则是借助于一定的教学行为分类规则和标准,对帖子进行行为标注和分类,以得出相应行为所占比例。在BETTM 模型中,首先按语料要求,分别从行为向量和情感向量中选择行为词和情感词,然后在二者的联合分布中选取相应主题,并在主题对应的词向量中,选择若干词语构成文档,该文档在合适的时间出现在论坛中。BETTM 模型将主题与情感、主题与行为关联,试图通过学习者所发布的帖子文本,发现其在发帖与回帖过程中潜在的情绪变化和行为类别,进而从深层次发现学习者的兴趣主题与知识建构过程。其次,BETTM 模型将主题与情感、行为、发帖时间四者关联,计算四者的联合分布概率,以探索学习者在教学活动的不同阶段所发帖子中蕴含情绪及行为类别的演化趋势。BETTM 模型如图1 所示。
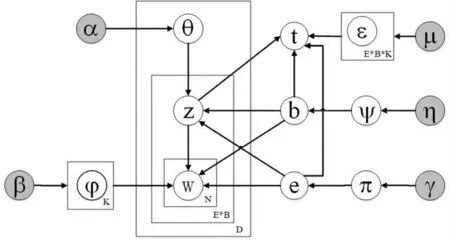
图1 BETTM 模型
在图1 中,空心圆代表未知变量,实心圆代表已知变量,有向箭头则代表条件概率,矩形框右下角为方框内各变量重复采样的次数。其中,α,β,γ,μ,η为超参数,分别代表主题向量稀疏度、 词向量稀疏度、情感词向量稀疏度、时间向量稀疏度与行为词向量稀疏度。稀疏度越高,向量密度就越低。t,w 是可观测变量,代表发帖时间与文本,而e,b,z 是隐变量,代表情感、行为与主题;N,E,B,D,K 分别是词数量、情感类别数、行为类别数、文档数量以及主题数量;θbjk表示主题—情感—行为概率分布,φbjkv表示词—情感—行为—主题概率分布,πmj表示文档—情感概率分布,ψmc表示文档—行为概率分布,εbjkh表示时间—情感—行为—主题概率分布。πmj和θbjk二者可共同表示特定群体在整个教学过程中的兴趣主题概率分布,ψmc和θbjk二者可共同表示特定群体在整个教学过程中的行为主题概率分布,而πmj和θbjk、εbjkh可表示在不同教学时间的兴趣主题概率分布。
构建好的BETTM 模型,需要采用联合概率分布和吉布斯采样,对模型进行训练与多轮迭代,公式如1-7 所示。在真实的数据集中进行测试,经过多轮迭代,模型达到收敛,得到每类兴趣主题、主题行为所占比例,以及二者联合分布随时间变化的趋势。
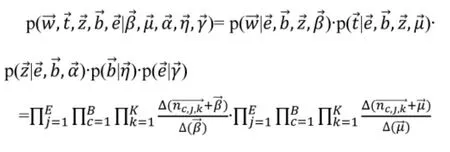
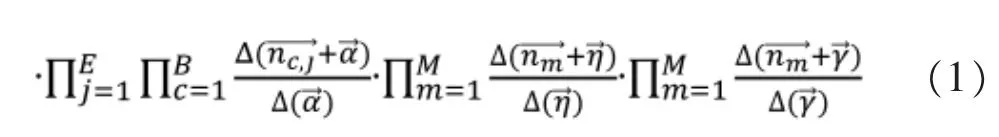
公式1 为联合分布,其中右侧各部分为:

其中,公式7 为吉布斯采样公式。概率参数:

四、实验设计
(一)研究对象
本研究基于华中地区某师范类高校开设的公共选修课《信息技术教学应用》展开。该课程旨在帮助学生了解信息技术新进展,掌握如何将信息技术应用到实际教学中。课程时长为八周,约40 天。2021年上学期,共45 名来自全校不同学院不同专业的学生选修该课程。学习任务是完成一份教学设计和开发一个多媒体课件。
课程采用协作学习的方式,学生自由分组,每组5 人,共分为9 组。各组经过组内讨论选定任务主题。数据主要是学生在QQ 群的发帖与回帖,共收集4552 条讨论贴,去除无效的帖子后,最终获得4460条有效帖子数据。本研究将学生在课程结束时所取得的成绩(作品成绩),作为学习成绩的评判标准,班级平均分为84.89,标准差为13.298。
(二)研究方法与工具
正如前述,情感分类依托情感词典。学生在互动中表现出的积极和消极情绪,对其学习兴趣和投入水平有重要影响 (Altrabsheh,et al.,2015)。研究表明,积极情绪有助于学习者取得良好的成绩(Tucker,et al.,2014),困惑和消极情绪则会对学习成绩产生负面影响(Wen,et al.,2014)。本研究以大连理工大学开发的情感词典为主,结合哈工大提供的同义词词林以及论坛中涉及的部分情感词,对词典进行修补和删减,将情感分为积极情感和消极情感两类。其中积极词汇7037 个,消极词汇4379 个,情感词典中部分关键词,如表1 所示。

表1 情感词典中部分关键词
通过构建情感词典以确定句子的情感极性分布,并应用BETTM 模型挖掘帖子中隐藏的主题分布,从而获取在不同情感分布中各类主题所占比例。本文以学习者为单位,将个人在论坛中所发全部帖子的情感分布和主题分布联合,并进行累积,获取学习者在论坛中的兴趣主题集合。将学习者—兴趣主题概率与学习者的学习成绩做多元回归分析,得到对学习成绩影响显著的兴趣主题及其回归系数。
针对在线论坛中的学习行为分类,将论坛中的发帖行为分为互动、注册、提问、观点和引用五类(Liu,et al.,2018b)。参考学习者在教学过程中存在的行为倾向(王海丽,2017),构建在线论坛中学习者行为分类表,如表2 所示。以学习者个体为单位,应用BETTM 模型挖掘帖子中隐藏的主题分布,对学习者全部帖子的主题进行行为分类,得到主题对应行为类别的概率。将主题概率与行为概率联合,得到学习者在整个教学周期中的主题行为倾向。将学习者—行为倾向占比与学习成绩之间做多元回归分析,得到对学习成绩影响显著的行为类别及相关系数。

表2 在线论坛中学习者行为分类表
接着,将学习者的行为分布与兴趣主题联合,获取在不同情感下不同主题行为的概率分布。再将联合后的概率分布与学习成绩之间做回归分析,获取对学习成绩有影响作用的联合分布类别及影响系数。
最后,探究在特定教学进程中兴趣主题和行为的联合分布的演化趋势。以10 天为单位对数据进行划分,把整个教学过程分为四个阶段,探究在不同阶段学习者兴趣主题和行为倾向的变化,以及二者的联合分布的总体特征。
五、实验结果
(一)兴趣主题对学习成绩的影响作用
数据集成之后,对数据集上的文本进行预处理和清理,去除停用词、标点符号和重复数据(Jindal,et al.,2021)。接着确定主题模型的最佳主题数。值得注意的是,困惑度(perplexity)是指模型对未知数据的泛化能力(王宾杰,2021)。值越低,泛化能力越好,模型适用性越强,其计算如公式8 所示。
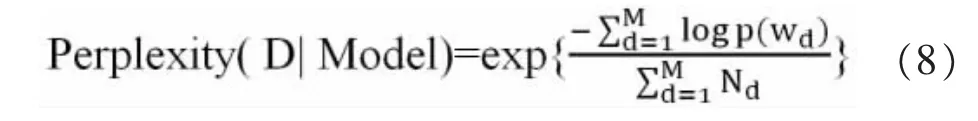
其中,M 是文档数量,Wd是文档中生成单词的概率值,Nd为学习者发布的单词数。将迭代次数设置为1000,主题数分别设置为10,20,30,40,50 时计算困惑度,最终结果显示当主题数为20 时,BETTM 模型达到最优性能。结合论坛中学习者所发帖子的特点,将兴趣主题数量定为20。计算每类兴趣主题在教学周期中的概率值并累积,作为自变量,将学习成绩作为因变量,开展多元回归分析,获取不同兴趣主题对学习成绩的影响作用。结果表明,在20 个兴趣主题集合中,有4 个主题对学习成绩有显著影响作用,它们分别是兴趣主题1、5、6 和11。对学习成绩有影响的兴趣主题,占全部主题的1/4。多元回归结果,如公式9 所示。其中y 是因变量(学习成绩),x1、x2、x3、x4代表兴趣主题1、兴趣主题5、兴趣主题6 与兴趣主题11,截距值为72.463,p<0.05。
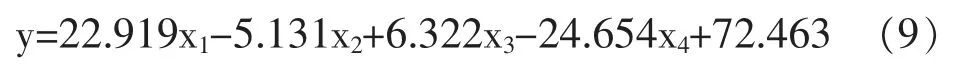
从公式9 可以看出,兴趣主题1 和6 对学习成绩有显著正向影响,而兴趣主题5 和11 对学习成绩有显著负向影响。表3 给出了兴趣主题1、5、6 和11中出现的部分关键词及其占比。结合表3 所提供的兴趣主题关键词,可以发现,兴趣主题1 和6 突出学生对相关信息资源的查找、技术的使用,以完成教学设计和多媒体课件任务,同时也很注重与组内其他成员的互动。兴趣主题5 和11 则突出个人发布对作品修改的意见、对作品的评价和对他人工作的鼓励。以上表明,关于信息和资源的查找与技术的应用,以及组内成员之间的交流互动,对学习成绩有正向影响作用,而对小组作品的评价与提出修改意见,对学习成绩有负向的影响作用。
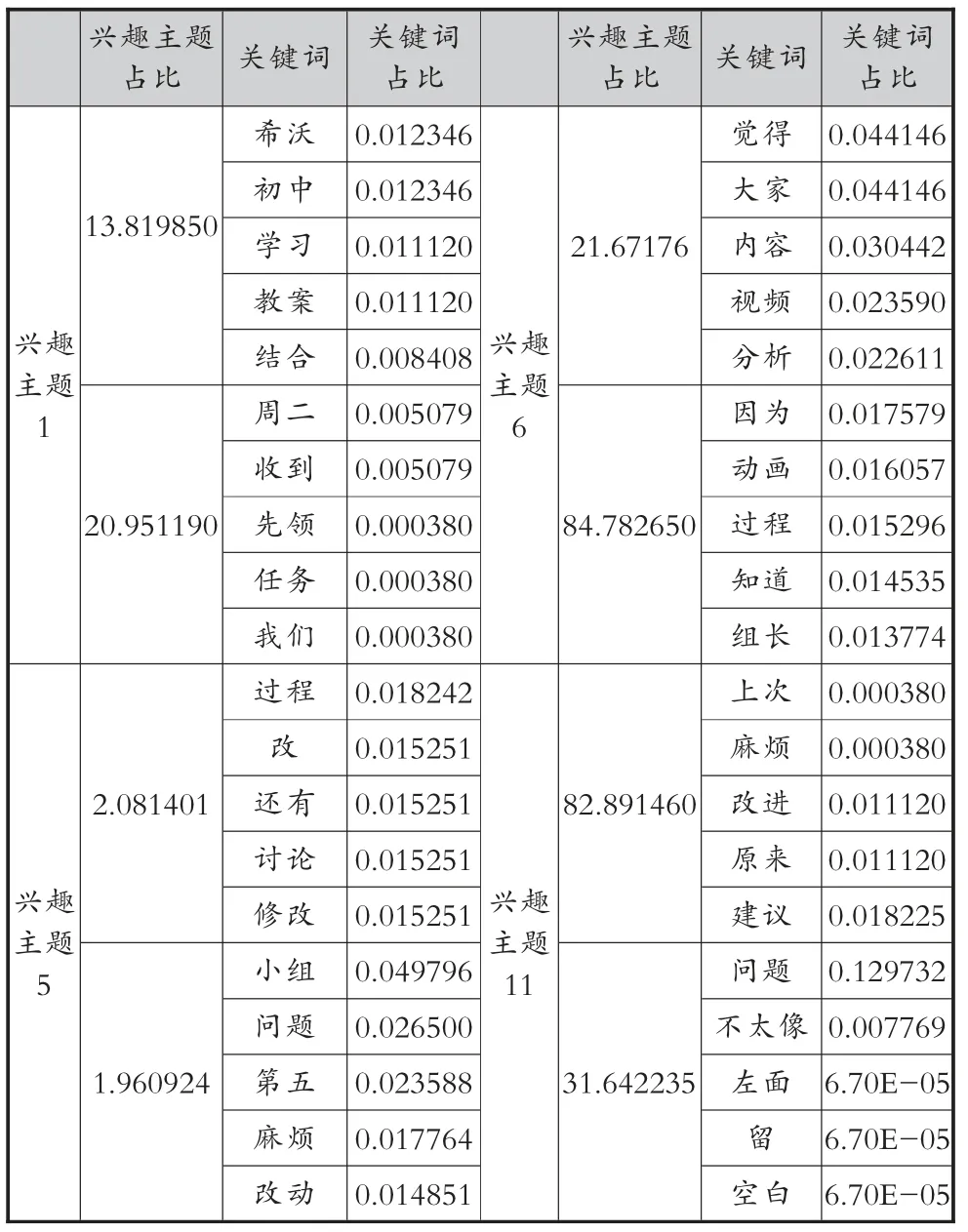
表3 兴趣主题中的关键词(部分)
(二)主题行为类别对学习成绩的影响作用
依据王海丽等(2017) 提出的网络教学行为分类,本文对45 名学生在在线论坛中所发帖子的主题进行行为归类,学生的主题行为分类及部分关键词如表4 所示。鉴于每位学生在不同教学阶段中所表现出的行为倾向会有所不同,将主题进行行为分类后的概率与主题的概率进行联合,以个人为单位,对学习成绩做回归分析。结果表明: 在6 种行为分类中,只有信息发布行为,对学习成绩有显著影响作用(p=0.024<0.05)。回归方程为:y=0.349x+90.631,其中y 为学习者的学习成绩,x 为信息发布行为。这一结果表明,学习者在完成任务的过程中,对个人观点和看法的分享与发布行为,会对其最终学习成绩产生正向影响作用,而其它五类行为对学习成绩的影响不显著。学习者无论是在教学活动初期查找资料、修改资料,还是对人员和任务进行安排和监督,又或者学习者之间进行讨论,以及对作品的评价行为等,都对学习成绩没有显著的影响。

表4 行为主题概率表
(三)兴趣主题与行为主题的联合分布对学习成绩的影响作用
通过BETTM 模型计算兴趣主题与行为主题的联合分布,试图挖掘在不同情绪下学习者所表现出的行为倾向,最后得到12 种情感—行为分类。再结合BETTM 模型中的时间序列,将学习者在整个学期中表现出来的情感,与行为倾向和所关注的主题进行联合,并将其与学习成绩关联。最终结果表明,12 种情感—行为类别,对学习成绩的影响都不显著,无论是积极情绪下的各类行为主题,还是消极情绪下的各类行为主题,都对学习者最后的学习成绩影响不大。
从图2 可以看出,在12 类情感—行为联合分布中,学习者更倾向于把关注点放在“团队成员之间的交互”,以及“对实际问题的解决”两类行为上。不管学习者个人的情绪如何,对于其他四类行为的关注,明显不如这两类行为。信息发布行为虽然对学习成绩有显著影响,但在在线论坛中学习者的信息发布行为占比较少,学习者应当更加注重对个人观点的分享与发表,这样有助于学习成绩的提升。
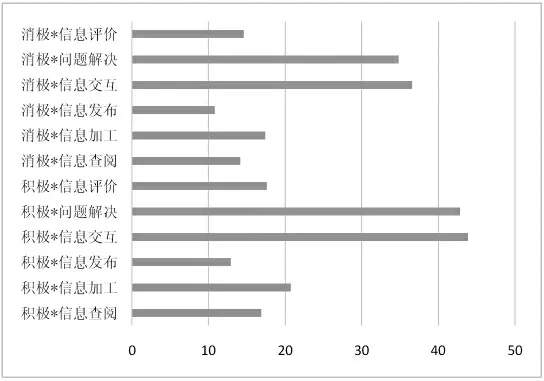
图2 情感-行为的联合分布
(四)兴趣主题与行为主题联合分布的阶段性演化趋势
本文将教学过程分成四个阶段,通过BETTM 模型,将兴趣主题和行为主题的联合分布与时间结合,计算每个阶段中学习者的12 种情感—行为分类的累积概率,结果如图3 所示。从学习者发帖数量来看,在任务初期(前10 天),学习者普遍发帖较多。从学习者的讨论内容来看,这一阶段学习者较为关注任务的安排和解决过程,学习态度都比较积极。在任务中后期(后20 天),学习者在论坛中的发帖数量呈现明显的下降趋势。
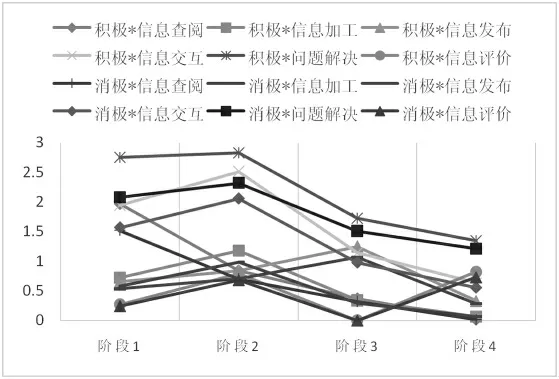
图3 学习者情感-行为主题联合分布的阶段性演化趋势
从折线图和具体的数据来看,在阶段1 中,学习者更关注于问题解决和信息查阅。因为在教学活动刚开始时,教师布置课程任务及相关规则,学生自主组建小组,学生需要对人员进行分工,以及为了完成既定目标而查找资料和文献。在阶段2 中,除了问题解决外,学习者对信息交互的兴趣也有所提升。在完成任务的同时,学习者之间逐渐熟悉,因而不再只关注于自己的任务进度,而能就选定的主题与任务完成情况进行讨论,并对他人的工作给予肯定和鼓励。在阶段3,学生的信息发布行为增加,学生对表达个人观点的兴趣增加,而这时的信息交互和问题解决行为也没有减少。在这一阶段,学习者不再局限于对他人进行鼓励和表达认可,更倾向于发表自己的观点来帮助解决问题以完成任务。在阶段4,信息发布和信息评价行为增加,结合教师在这一阶段安排的小组任务(组间互评),可以看出,学习者开始发表自己的看法与观点,并提出修改的意见与建议。
在四个阶段中,问题解决和信息交互行为都比较受重视,这说明学习者在讨论的过程中,一直对任务的安排和成员之间的交互比较看重。信息查阅行为只在任务开始的时候较多,在其他阶段没有明显优势,教师和学习者需要关注整个教学过程中资料查找的重要作用。信息交互行为虽然在教学活动前期数量较多,但在后期,学习者更倾向于发表个人观点。就信息评价行为而言,只在阶段2 和阶段4 其比例才有明显增加。结合论坛中的讨论数据发现,后期学习者更多讨论的是作品的修改和完善,以及对他组作品的评价。教师应当关注组内成员随阶段性任务安排而出现的情绪变化,尽可能调动学习者的积极情感,保证在整个讨论过程中学习者持有积极协作的态度。
六、研究结论
为了探究学习者的兴趣主题与行为主题的联合分布对学习成绩的影响作用,本文将情感、行为和时间融入LDA 主题模型,构建了BETTM 模型。在原有情感词典的基础上,进行修改和删除,以获取到适用于在线论坛帖子分析的情感极性分类标准;同时,对相关研究中提出的网络教学行为分类表进行修改,使其分类的定义和规则,适用于分析在线论坛中的行为。随后在真实场景中应用BETTM 模型,深入挖掘学习者在教学过程中潜在的兴趣主题与行为主题,并探究了二者对学习成绩的影响。
兴趣主题和行为主题分别对学习成绩的影响结果表明:(1)在兴趣主题方面,20 个兴趣主题中共有4 个主题对学习成绩作用显著,其中“相关信息和资源的查找和应用”,以及“与组内其他成员的交流和交互”等相关主题,对学习成绩有正向影响作用,而“对作品的修改和评价”主题,却起着反向影响学习成绩的作用;(2)就行为主题而言,在行为主题的6个分类里面,只有“信息发布类行为”对学习成绩有显著正向作用,而其他五类行为的影响作用都不显著。在此基础上,将兴趣主题和行为主题的联合分布作为自变量,学习成绩作为因变量,回归分析的结果表明:(3)联合后的12 个类别,即不同情绪下学习者的行为倾向,对学习成绩的作用都不显著。但从总量上看,在在线论坛中,学习者更关注于问题解决和信息交互行为,对信息发布行为的关注不够,所以学习者在参与讨论时,应注重个人观点的输出与分享。
考虑时间因素,计算四个阶段中学习者12 种情感—行为主题概率的累积值,结果表明:(1)从总量上看,学习者在前期表现更积极,发言的频次更多。但在后期,学习者的动机明显不足,发言频次陡然降低,趋势较为明显;(2)学习者在教学刚开始的时候,较为关注“资料的查找”与“成员之间的任务分工”;在第二阶段,学习者把关注点转移到“资源的加工与处理”以及“彼此之间的交流、互动”上。这一阶段还涉及到“组内成员之间的交互活动”,例如,对他人完成某个工作的鼓励与赞许。在中后期,学习者除比较积极地进行交互与问题解决外,不再局限于对他人的工作进行评价,而是积极地提出自己的观点和看法,而这都是在学习者对他人和任务的熟悉度明显增加的基础上发生。在完成任务后,因为这一阶段学习者被要求对他人的作品提出意见和建议,所以这时候学习者的评价行为增长趋势明显。
综上,本文提出的BETTM 模型,将情感、行为、时间等变量联合纳入主题模型中,基于在线论坛中发帖与回帖数据,对学习者的潜在兴趣主题与行为交互情况进行挖掘。以此来探究二者与最终学习成绩之间的关系,发现部分兴趣主题与行为对其有正向作用。而将二者联合后,发现在不同时间阶段的学习者的兴趣主题与行为有明显变化。应用该模型可以对学习者在论坛中的兴趣与行为进行挖掘,同时实现对最终学习成绩的预测。此外,当学习者出现明显的兴趣和行为偏离时,教师可以及时进行教学干预和调整,从而保证在线学习的质量。
七、思考与不足
本文将情感分析和行为分析融入LDA 主题模型,在研究学习者潜在兴趣的同时,探究其蕴含在帖子文本中的学习行为,并分析在特定教学周期中二者的联合分布对学习成绩的影响,及其所呈现出的趋势特征。研究结果表明,学习者的部分兴趣主题与交互行,为对最终学习成绩有显著正向影响,但二者联合后对学习成绩的影响不显著。结合联合后各分类的占比来看,学习者对促进学习的信息发布行为关注不够。对此,教师在教学时,需加强对在线论坛中相关行为的关注,学习者也应增加在发帖和回帖时对这类行为的投入,尽可能多地与他人共享观点,而不仅仅是关注于任务分配与彼此之间的交互。而关于兴趣主题和交互行为在时间上的变化,可能会受每个阶段中安排给学习者的任务的影响,特别是学习者的交互行为。因此,未来相关研究在进行教学设计时,可以有针对性地对各教学阶段的任务进行合理分配,以提升学习者的兴趣和激发较深层次的学习行为。
本文还存在很多不足之处。第一个不足与样本的数量有关,研究仅基于一门课程的线上论坛数据进行,学生数量有限,论坛中可研究的帖子数量也有限。而对于情感和行为的分析而言,数据量越大,结果越好(Kandhro,et al.,2019)。这一点可以借助在线课程提供的数据加以弥补,如,结合中国大学MOOC上的数据进行分析。
第二个不足与研究方法有关。在情感分析方面,当前比较流行的方法是利用深度学习挖掘情感。相比于深度学习,情感词典在最初构建时需要花费大量人力和资源,而且情感词典往往只关注单个词所表现出的情感极性,忽视了词语在上下文以及语境中的情况,因而,在使用时还会受到情境的影响。今后可以考虑使用深度学习的方法,对整个句子的情感极性进行标注,以达到对文本中隐藏情感的精准识别与分析。关于行为分类,本文参考的是网络教学行为分类表,并借助人工方法标注行为。和情感分析一样,未来研究将在行为分类的基础上,借助机器学习和深度学习的方法,实现对行为的智能标注。
第三个不足与数据来源单一有关。仅凭借文本数据来判定学习者的情感和行为,可能会存在一些遗漏,未来研究可以考虑综合学习者在论坛中登录、浏览以及回帖等日志数据,以及视频、音频数据等,尽可能使用多模态数据以提升情感和行为分类的准确性。
第四个不足与教学过程的阶段划分有关。由于课程时长和发帖量的限制,本文采用的是以10 天为一个阶段。在数据量允许的条件下,可以尝试以一周或者3 天为一个阶段,以细粒度地观察不同阶段下学习者个人的兴趣和行为变化,从而得出更精细和准确的研究结论。
总之,未来研究应考虑对不同绩效组学生的兴趣主题和行为主题进行深入比较,以探索影响在线论坛学习成绩的关键因素。比如,对学生进行分组比较,深入挖掘不同绩效组的学生,在教学的不同阶段在在线论坛中所表现的情感和行为倾向,探索其影响机制,从而为提升在线论坛教学的质量提供参考。
