基于协同过滤算法的职业教育学习平台个性化课程推荐模型研究
2022-01-15黄韵欣刘晋泽章艺云李骁
黄韵欣 刘晋泽 章艺云 李骁
[摘 要] 随着信息技术的发展和在线教育的展开,人们逐渐从信息匮乏的时代走入了信息过载的时代,如何将海量课程资源与用户需求进行匹配成为一大难题。面向职业教育学习平台,研究基于协同过滤算法的个性化课程推荐模型,分别提出基于用户的推荐模型UserCF和基于对象的推荐模型ItemCF,并引入多进程思想优化模型训练效率。其研究成果应用在某职业教育学习平台,取得较好的效果。
[关 键 词] 推荐系统;职业教育;个性化学习
[中图分类号] G642 [文献标志码] A [文章编号] 2096-0603(2022)03-0154-03
一、研究背景
在信息技术和互联网飞速发展的背景下,大数据时代已然来临,信息过载问题普遍存在,尤其是在教育、电商、医疗、金融等领域。随着职业教育全面推开,在线职业教育模式兴起,课程建设知识体系日渐丰富。目前,某职业教育网络服务平台已上线课程万余门,如何从海量资源中选择感兴趣的课程对学习者来说是一种挑战。课程推荐技术,为学习者提供了一种解决方案。
某职业教育业务平台当前采用基于数据统计的课程推荐方法,依据选课人次对平台课程进行排序,将大多数平台用户感兴趣的课程作为推荐项,即热门选课排行榜。这种传统的推荐方法有其优点:(1)课程质量有保证,课程内容和授课方式为大多数人所接受;(2)能解决冷启动问题,对于没有学习记录的平台,新用户能给出较好的课程推荐结果。同时也存在一些不足:(1)易导致长尾分布现象的出现,用户选课集中在少数热门课程。(2)不能拓宽用户知识面,所推荐课程集中在部分领域。(3)推荐方案缺乏个性化,所有用户将无差别得到相同的推荐结果。
本文基于协同过滤的基本思想提出两种个性化课程推荐方案,分别为基于用户的推荐模型UserCF和基于对象的推荐模型ItemCF;采用多进程方案优化训练时间,提高模型训练效率;在某职业教育网络学习平台上部署算法模块,实现针对平台活跃用户的个性化、智能化课程推荐功能。
二、相关工作
1995年,美国人工智能协会上首次提出了“个性化推荐”的概念,最初应用在个性化导航系统Web Watcher上[1]。20世纪90年代开始,推荐算法的研究开始蓬勃发展。当前主流的推荐算法大致可归类为基于内容推荐、协同过滤推荐、基于规则推荐、基于效用推荐和基于知识推荐五大类[2]。
然而现有成熟的推荐方案不能直接应用于本平台:(1)受限于服务平台硬件条件,需要较轻的负载。(2)考虑到信息的保密性和应用领域的特殊性,不能直接采用现有商业云服务。
三、系统方案
(一)总体架构
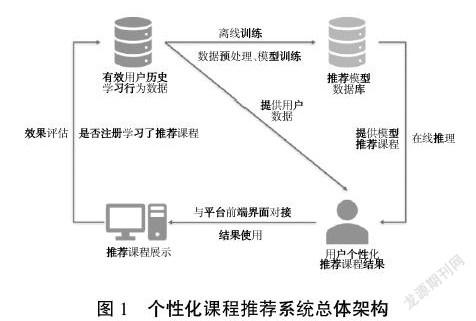
基于协同过滤的基本思想分别设计基于用户的推荐模型UserCF和基于对象的推荐模型ItemCF。个性化课程推荐模型的总体架构如图1所示,由离线训练、在线推理、结果使用和效果评估四个功能模块组成。
(二)离线训练
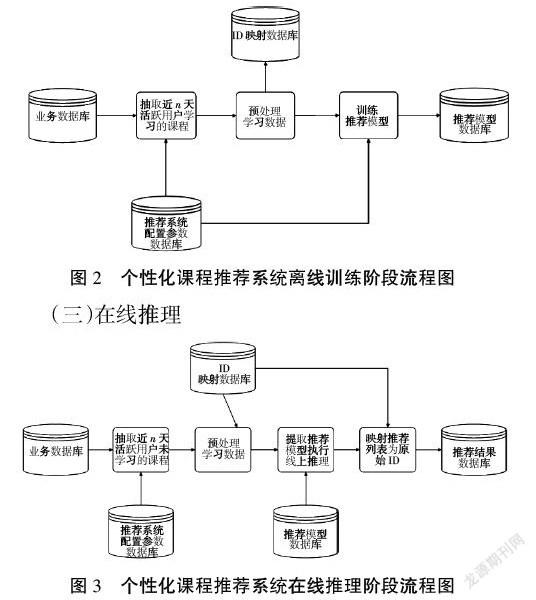
(1)从服务平台业务数据库中抽取近n天平台活跃用户的课程学习行为数据,作为推荐模型的训练数据。(2)采用基于协同过滤算法的基本思想,分别训练基于用户的推荐模型UserCF和基于对象的推荐模型ItemCF,并存储在推荐模型数据库中。(3)设置单独的数据库,用来存储推荐系统配置参数。
(三)在线推理
图3展示了个性化课程推荐系统在线推理阶段的具体流程。(1)从平台业务数据库中抽取近n天的活跃用户学习课程行为数据。(2)读取推荐系统配置参数数据库,取出协同过滤算法的主要参数,包括K近邻个数、推荐课程个数等。(3)对采集到的学习数据进行预处理,主要包括:基于离线训练阶段生成的ID映射数据库对数据做ID映射、生成CSV表格数据。(4)从推荐模型数据库中提取推荐模型,针对目标用户启动模型执行线上推理。(5)基于ID映射数据库,将推荐列表的课程ID映射为原始的课程ID。(6)将原始课程ID的推荐列表存入推荐结果数据库,读取推荐结果数据库中的推荐列表进行平台前端展示。
(四)结果使用
本阶段的主要功能是基于活跃用户的ID,从推荐结果数据库中取出推荐模型为其推荐的原始课程ID列表,并以图形化的形式展示在相应用户的平台页面。
(五)效果评估
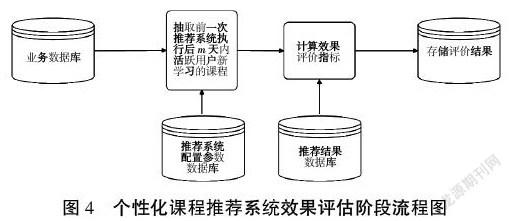
图4为个性化课程推荐系统效果评估阶段的具体流程。(1)从平台业务数据库中抽取前一次推荐系统执行后m天内活跃用户新学习的课程。(2)读取推荐系统配置参数数据库,取出协同过滤算法的主要参数,包括K近邻个数、推荐课程个数等。(3)从推荐结果数据库中取出推荐的课程列表,比较推荐结果和用户实际学习的课程,计算效果评价指标。(4)存储此次效果评价指标的值,并且系统通过统计用户是否注册学习了向他推荐的课程作为推荐效果的反馈。
四、实验与分析
(一)数据准备
从平台抽取近90天活跃用户的课程学习数据,得到的数据统计特征如下:
所有用户的选课数直方图如图5所示,其中横坐标代表用户的活跃度K,纵坐标代表活跃度为K的用户总数。直观地看到平台的用户选课行为是符合长尾分布的。
(二)参数设置
为了保证所设计的机器学习算法具有最优性能,对协同过滤算法进行调参,重点关注最近邻参数K的不同取值对于算法的性能效果影响。选用选课数据子集,其中用户数为4901,课程数为2024;选取K值为10、50、100、200,对基于对象的协同过滤算法测评四个指标以及计算耗时。
对比发现,当K值取100的时候,四项测评指标的值呈现出的效果最好,且耗时最短,因此基于K取100部署最优的协同过滤算法在平台上。
(三)实验结果
以单机单进程的训练集、测试集为数据输入,分别运行单机单进程的基于用户的协同过滤算法和基于对象的协同过滤算法,得到计算耗时以及召回率、准确率、覆盖率和平均流行度四项测评指标值,如表3所示。
引入多进程思想,优化单机单进程版本为单机多进程形式,模型效率如表4所示。
(四)结果分析
从实验结果可以得出以下结论:
(1)对比《推荐系统实验》[3]中实验的测评指标值,两个算法的实现效果都比较好。(2)基于对象的协同过滤算法的四项测评值均优于基于用户的协同过滤算法的测评值。原因不难发现:ItemCF适用于对象数明显小于用户数的场合,也适用于长尾物品丰富、用户个性化需求强烈的领域,而平台的数据正好是符合上述特征的。ItemCF算法的实时性好,能够利用用户的历史行为给用户做推荐解释,可以令用户比较信服,相较于UserCF而言是最好的选择。(3)基于物品的协同过滤算法的耗时明显大于基于用户的协同过滤算法,且基于用户的协同过滤算法的耗时也并不乐观。引入多进程的思想,优化单机单进程代码为单机多进程的形式,可以看到時间明显减少,多进程实验效果显著。
五、总结
个性化、智能化是发展在线教育的要素,本文研究基于协同过滤思想的个性化智能推荐系统,并采用多进程思想优化模型训练效率。其研究成果集成在某职业教育学习平台,应用结果表明,用户对推荐结果满意度较高。
参考文献:
[1]赵守香,唐胡鑫,熊海涛,等.大数据分析与应用[M].北京:航空工业出版社,2015-12.
[2]杨旭,汤海京,丁刚毅.数据科学导论[M].2版.北京:北京理工大学出版社,2017-01.
[3]项亮.推荐系统实践[M].北京:人民邮电出版社,2012-06.
◎编辑 鲁翠红