一种噪声容错弱监督矩阵补全的生存分析方法
2022-01-13林腾涛陈兴国
陈 蕾 邵 楷 林腾涛 陈兴国
作为现代统计学的一个重要分支,生存分析旨在建模某个感兴趣事件的发生时间.这些感兴趣事件通常包括临床治疗中患者的生存时间[1]、机械系统中故障的发生时间[2]以及客户行为分析中用户的购买时间[3]等.当前,训练数据缺乏和数据质量不高是生存分析研究面临的两个重要挑战.一方面,由于数据采集的代价高昂,收集到的样本数量往往偏少(这一点在医学领域表现尤为突出),如果再考虑到一些应用领域实例所具有的内在高维特性,那么生存分析问题往往就是一个典型的高维小样本问题.另一方面,由于观测周期有限以及研究对象失访等原因,收集到的数据中还不可避免地存在一些删失实例,也就是说这些实例的感兴趣事件没有在观测周期内发生或者由于跟踪轨迹失效等原因未被观测到.特别地,为描述方便,对于那些已经观察到感兴趣事件发生的实例,本文将其感兴趣事件的发生时间称为生存时间,相应的实例称为未删失实例.而对于其他未观察到感兴趣事件发生的实例,本文将该实例所耗的观测时间称为删失时间,相应的实例称为删失实例.通常右删失是实际应用中最常见的情形,即删失实例的实际生存时间大于或者等于删失时间.因此,不失一般性,本文将生存分析的研究对象限定为右删失实例.
传统的回归分析模型通常只能将未删失实例作为训练数据,而未删失实例数量的明显不足很容易导致模型的过拟合,而另一方面删失实例的合理利用则有助于改善生存分析模型的泛化性能.因此,一般不采用传统的回归模型来处理生存分析问题.Cox 比例风险模型[4]和参数删失回归模型[5]是生存分析中两类应用最为广泛的模型.但是,这两类方法均存在较为严重的缺陷,所以预测效果并不是很理想.具体地,Cox 模型是建立在比例风险假设上的生存分析模型,其假设实例之间的风险比是常数.因此导致所有实例的生存曲线将呈现相似的形状.显然,这种假设在实际应用中是过于严格的,并且如果数据中存在具有相同生存时间的实例时,Cox模型还需使用一些近似的方法来处理数据,这有可能会带来导入偏差(Inducing bias).另一方面,参数删失回归模型的预测性能高度依赖于生存时间分布假设的选取.然而,在实际应用中,存在很多影响感兴趣事件发生的因素,因此很难选择出一个合适的理论分布.
近年来,随着机器学习理论在各个领域的出色表现,研究人员开始引入机器学习方法来研究生存分析问题.相较于传统的生存分析模型,机器学习能够从有限的数据中学习到更多的信息,例如数据特征的分布规律及实例特征的抽象表示,同时还具有出色的函数拟合能力.尤其是机器学习中的多任务学习方法[6],能够帮助模型学习到多个任务之间的共享判别特征,从而提高模型的泛化能力,降低新实例的预测错误率.例如,Li 等[7]创新性地将生存分析问题建模成预测各个时间间隔生存状态的多任务问题,并通过对所设计的线性预测器施加ℓ2,1范数正则化,不仅可以筛选出具有跨任务判别能力的共享特征,还可以缓解高维小样本问题所带来的过拟合缺陷,他们所提出的MTLSA/ MTLSA.V2模型在生存分析问题上取得了很好的效果.但是,这些多任务学习方法依然存在一些缺陷,即这些模型均未考虑到数据中可能存在的复杂噪声所带来的影响.
为了克服上述缺陷,本文提出一类噪声容错弱监督直推式矩阵补全模型(Weakly supervised transductive matrix completion,WSTMC)来预测删失实例和新实例的生存时间.具体地,基于实例特征潜在的低秩属性,本文首先将生存分析问题建模为一类多任务直推式矩阵补全(Multi-task transductive matrix completion,MTMC)模型[8].受益于直推式学习机制,该模型不仅可以利用删失实例作为有限训练样本(非删失实例)的有效补充,而且可以在训练阶段同时探索测试样本和训练样本的特征分布,从而提高模型在测试样本上的泛化能力.其次,为了克服MTMC 模型的噪声敏感性,本文引入混合高斯分布(Mixture of Gaussians distribution,MoG)来拟合实际应用中的未知噪声类型,其动机在于MoG 理论上可以拟合任意连续分布[9].进一步,为了缓解实际应用中高维小样本所带来的过拟合缺陷,我们设计了一类新颖的多任务直推式特征选择机制,以期所提出的模型能在去噪后的特征空间自适应地选择出跨任务的共享判别特征,从而进一步增强模型的泛化能力.同时,我们还引入了相邻时间间隔生存状态的先验时序稳定性来指导模型生成软类别标记.此外,我们也设计了一类拟期望最大化迭代优化算法来求解所提出的WSTMC 模型.针对该模型所涉及的多个超参数,我们采用了贝叶斯优化方法来自适应地进行选择.最后,5 个真实数据集上的实验结果验证了所提出的WSTMC 模型优于当前广泛使用的4 类18 种生存分析方法.
本文结构安排如下:第1 节对相关工作进行讨论;第2 节介绍一些数学基础及矩阵补全预备知识;第3 节为本文主要部分,详细阐述了所提出的噪声容错弱监督直推式矩阵补全(WSTMC)模型及相应的优化算法;第4 节是实验部分,首先介绍了实验数据集和所采用的性能评价指标,接着阐述了实验方法和对比模型,最后分析了实验结果;第5 节对本文研究内容进行了总结与展望.
1 相关工作
现有的生存分析方法大致可分为如下几类:1) Cox 比例风险模型;2)参数删失回归模型;3)线性模型;4)多任务学习模型.其中,Cox 比例风险模型是生存分析中应用最为广泛的模型之一.在统计和数据挖掘领域,该模型吸引了众多研究人员的关注与兴趣.近年来,由于各种数据采集和数据分析技术的发展,高维数据在各类实际应用包括生存分析领域频繁出现,例如医学领域中微阵列基因表达数据往往包含数千维特征.为了缓解高维数据带来的过拟合问题,研究人员在传统的Cox 模型中加入各种正则化项来帮助模型选择合适的特征以降低特征维度,从而提出了LASSO-COX (Least absolute shrinkage and selection operator Cox)模型[10]、EN-COX (Elastic-net Cox)模型[11]和KEN-COX(Kernel elastic-net Cox)模型[12].它们分别在传统模型中加入了ℓ1范数正则化项、弹性网正则化项和核化的弹性网正则化项.这种方式扩展了Cox 比例风险模型的应用场景,但并没有解决该模型中比例风险假设在实际应用中过于严苛而可能带来的欠拟合问题.参数删失回归模型是生存分析中另一类常用的重要模型[5,13-15].该模型假设实例的生存时间或者对数生存时间满足某种特殊的数据分布.其中较常见的假设包括指数分布、威布尔分布(Weibull distribution)、对数(Logistic)分布和极值分布[13]等.此外,一些线性模型还进一步假设生存时间或对数生存时间与特征之间存在线性关联关系.这类线性模型可以被看成一类特殊的参数删失回归模型.例如,结合高斯分布的Tobit[14]模型以及引入Kaplan-Meier 估计的Buckley-James 回归模型[15].在实际应用中,如何选择出合适的分布限制了参数删失回归模型进一步提高生存分析的预测效果.
近年来,为了松弛传统统计模型中所依赖的严苛假设,即比例风险假设和生存时间分布假设等,一些研究人员开始采用机器学习领域的多任务学习模型来研究生存分析问题.例如,Li 等[7]提出了一种ℓ2,1范数正则化的多任务学习模型MTLSA/MTLSA.V2,该模型利用ℓ2,1范数来共享任务之间的相关性,同时解决高维小样本数据带来的过拟合问题;此外还在模型中加入了相邻时间间隔内生存状态稳定的先验条件来约束模型生成标记.但是,该方法仅仅预设数据分布包含单一类型的高斯噪声,忽略了特征矩阵中可能存在的未知复杂噪声类型,因此存在一定程度的噪声敏感性缺陷.受现有模型尤其是近年来多任务学习生存分析模型的启发,本文提出了一种噪声容错的弱监督多任务学习(WSTMC)模型来处理生存分析问题.相较于以往的模型,所提出的WSTMC 模型不仅有效利用了特征矩阵的内在低秩属性,还能够通过所引入的MoG 噪声模型来平滑数据分布中存在的复杂噪声.此外,不同于传统的多任务学习方法,我们还在去噪后的特征空间引入了多任务直推式特征选择机制,帮助模型选择出跨任务共享的判别特征,这在一定程度上有利于 缓解高维小样本数据固有的过拟合问题.
2 预备知识
2.1 数学基础
定义1.瘦型奇异值分解[16].设矩阵X是一个秩为r的m×d维矩阵,则存在两个单位正交矩阵U ∈Rm×r和V∈Rd×r, 以及对角阵 Σ=diag{σi|1≤i ≤r},其中奇异值σ1≥σ2≥···≥σr>0 且满足

式(1)称为矩阵X的瘦型奇异值分解.
定义2.矩阵范数[16].设秩为r的矩阵X ∈Rm×d存在如式(1)所示的瘦型奇异值分解,则
1)矩阵X的核范数定义为

2)矩阵X的Frobenius 范数定义为

3)矩阵X的ℓ2,1范数定义为

定义3.近邻算子[17].设F(X)为矩阵X的实值凸函数,则对于任意矩阵M及τ>0, 函数F(X)的近邻算子定义为

定义4.阈值收缩算子[17].假设τ>0, 阈值收缩算子 proxτ‖X‖(M)定义为

其中,Sτ(M)定义为

其中,sign(·)为符号函数.
定义5.核范数近邻算子[17].设秩为r的矩阵M的奇异值分解为UΣVT, 对任意的τ>0, 核范数近邻算子 proxτ‖X‖*(M)定义为

定义6.ℓ2,1范数近邻算子[18].对于矩阵M ∈Rm×d和任意的τ>0,其相应的ℓ2,1范数近邻算子proxτ‖X‖2,1(M)定义为

其中,Jτ(M)定义为
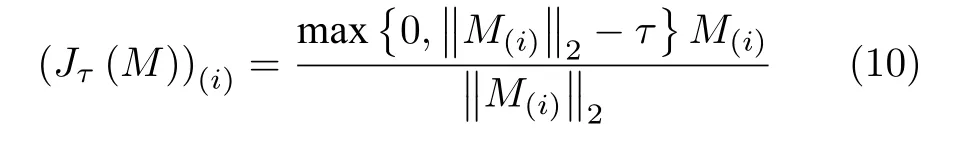
其中,i=1,2,···,m,M(i)表示矩阵M的第i行,‖·‖2表示向量的ℓ2范数.
定理1.近邻前向后向分裂(Proximal forward backward splitting,PFBS)算法[18].假设F1,F2是两个下半连续的凸函数,F2在 Rm×d中可微且对某个常数β>0具有β-Lipschitz 连续梯度,即||∇F2(U)-∇F2(V)||F≤β||U-V||F, 则凸优化问题
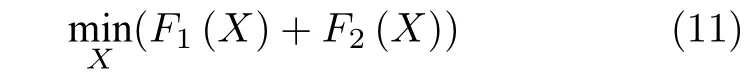
有如下性质:
1) 如果F1+F2是强制的,即lim‖X‖F→+∞(F1(X)+F2(X))=+∞,则该凸优化问题至少存在一个解;
2) 如果F1+F2是严格凸的,则该凸优化问题至多存在一个解;
3) 如果F1和F2满足上述两个条件,则凸优化问题存在唯一解,且对于任意的初始值X0以及0<δ <2/β用如下方法生成的迭代序列Xk+1收敛到凸优化问题的唯一解

2.2 矩阵补全
矩阵补全可视为压缩感知理论[19-21]从一维向量空间向二维矩阵空间的一种自然推广,旨在研究如何在数据不完整的情形下对数据的缺失信息进行填补.标准的矩阵补全问题可以建模为如下形式的秩最小化约束优化模型[22]:
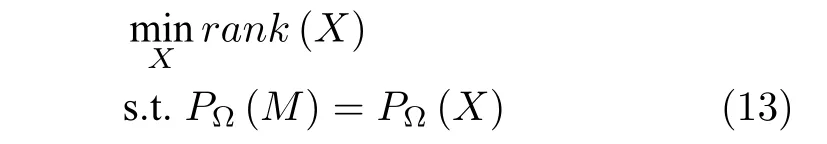
其中,X为待补全的目标矩阵,M为部分元素已知的采样矩阵,Ω 表示采样元素的索引集合,PΩ(·)为正交投影算子,表示当 (i,j)∈Ω时,Mij为采样元素,即

Fazel[23]证明了矩阵核范数是秩函数在矩阵谱范数意义下单位球上的最佳凸逼近.因此,类似于压缩感知理论中常用的将向量ℓ0范数松弛为向量ℓ1范数的技巧,为了使标准的矩阵补全问题易于求解,一个自然的想法就是利用凸核范数代替非凸秩函数,也就是将原先的秩最小化问题松弛为如下形式的核范数最小化模型[22]:
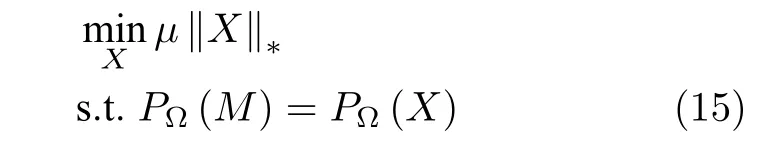
然而,尽管标准的矩阵补全理论在数据表示、信息重建以及图像恢复等领域取得了较大成功,但是仍然无法解决弱监督情形下的多标记分类问题.为此,Goldberg 等[8]于2010 年提出了一类新颖的多任务直推式矩阵补全(MTMC)模型并将其成功应用于多标记图像分类问题.这类MTMC 模型主要建立在两个假设之上.首先,假设包含m个d维样本的特征矩阵X和t个任务的任务矩阵Y ∈{0,1,?}m×t之间存在线性依赖关系,也就是说,存在隐含的权重矩阵W0∈Rd×t使得Y=XW0. 其次,假设特征矩阵X满足内在低秩属性.基于上述假设,容易推断出特征-任务堆叠矩阵 [X,Y] 也满足低秩性.因此标准的MTMC 模型可建模如下:
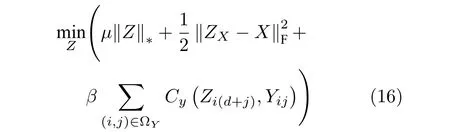
其中,Z=[ZX,ZY] 表示待求解的特征-任务堆叠矩阵,ZX表示待求解的去噪特征子矩阵,ZY表示待求解的软标记子矩阵,ΩY表示任务矩阵Y中已知标记的索引集合,Cy(·)表示标记损失函数(通常为logistic 损失函数或平方损失函数).
3 面向生存分析的WSTMC模型
3.1 问题阐述
在生存分析问题中,对于第i个实例,如果该实例未删失,则可以观察到它的生存时间S_time(i),反之,可以得到该实例的删失时间C_time(i).为了方便表达,定义观察时间O_time(i)如下:

其中,δi∈{0,1}表示删失状态指示符,δi=1 表示该实例为删失实例,δi=0 表示该实例为未删失实例.通常,可以采用三元组 (xi,O_time(i),δi)来表示生存分析问题中的实例,其中下标i表示实例编号.
本文目标是通过合理建模特征xi和生存时间S_time(i)之间的关系,从而能够依据实例特征,准确预测该实例的生存时间.然而,由于存在删失数据,传统的分类和回归方法并不适合生存分析问题.受Li 等[7]的启发,为了更好地利用删失实例,本文将生存分析问题建模为多任务学习模型.具体地,先将连续的时间进行离散化,也就是将整个研究周期离散化为若干个相等的时间间隔,通过考察各个时间间隔上实例的生存状态从而间接得到整个研究周期内实例的生存状态.由此每个实例(xi,O_time(i),δi) 可转换为三元组 (xi,O_num(i),δi),其中O_num(i)表示第i个实例的观察时间所对应的时间间隔数.此外,第i个实例在第j个时间间隔上的生存状态用Yij∈Y来表示.如果在该时间间隔内感兴趣事件未发生则Yij=1, 已发生则Yij=0, 状态未知则使用“?”表示.通过上述方式,生存分析问题转化为了多任务学习问题,预测每个时间间隔上的生存状态就是一个学习任务.值得注意的是,对于每个数据集选择最大的O_num(i)作为多任务学习的任务总数t.图1 图示了如何将生存分析问题表述为弱监督多任务学习问题.从图1 可以看出,对于第i个实例,如果实例是未删失的,则任务矩阵Y中相应行的生存状态从开始到第O_num(i)个时间间隔都记为“1”,之后都记为“0”.如果实例是删失的,则任务矩阵Y中相应行的生存状态从开始到第O_num(i)个时间间隔都记为“1”,之后都记为“?”.

图1 生存分析问题建模为弱监督多任务学习问题的图示Fig.1 Illustration of formulating the survival analysis problem as a weakly supervised multi-task learning problem
综上所述,可以通过先将生存分析问题阐述为弱监督多任务问题,然后引入交叉熵损失函数将其建模为如下形式的改进MTMC 模型

3.2 建模
然而,直接将生存分析问题阐述为上述多任务直推式矩阵补全(MTMC)问题仍然存在以下几点不足:1)噪声容错性差.MTMC 模型采用Frobenius 范数拟合特征噪声,已有研究表明Frobenius 范数是高斯分布的最佳逼近[21],然而生存分析数据所面临的噪声通常并不是单一的高斯分布且其实际分布类型也往往是未知的[24].2)高维小样本过拟合.在实际的生存分析问题中,由于研究代价高昂和观测时间的限制,能收集到的观测实例往往数量偏少.而受益于数据收集和检测技术的发展,所能获取的实例特征则越来越丰富,这加剧了高维小样本问题所带来的模型过拟合风险.3)先验信息融合性不强.MTMC 模型忽略了数据固有的先验信息,在生存分析问题中,相邻时间间隔内生存状态存在时序稳定性,这种先验时序信息的合理融合通常能有效提升模型的预测性能.
为此,针对噪声容错性差的缺陷,我们考虑引入MoG 模型来拟合一般的未知复杂噪声,其动机来源于已有研究表明MoG 分布能在理论上逼近任意连续分布,这种噪声建模思想已经在一些典型的机器学习及计算机视觉任务中得到了很好的应用[24-25].具体地,不妨假设特征矩阵中的每一个元素均由两部分组成,即
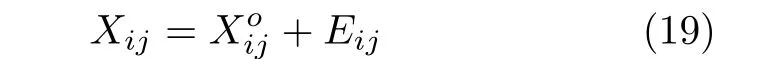
其中,Xij,分别表示第i个样本的第j个观测特征、真实潜在特征及相应的噪声.假设噪声Eij服从独立的同MoG 分布,即

进一步可得到log 似然函数
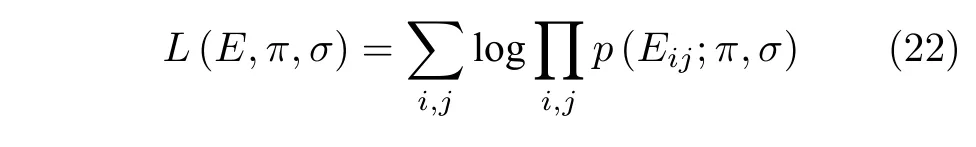
我们的目标是通过最大化该log 似然函数解析出特征矩阵X中存在的未知复杂噪声.为此,结合式(18),易得到如下所示的噪声容错MTMC 模型
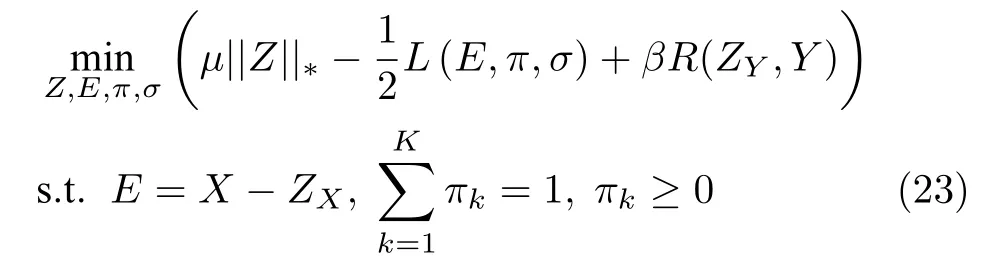
其次,针对实际应用中高维小样本所带来的过拟合缺陷,我们设计了一种新颖的多任务直推式特征选择机制来自适应地选择跨任务之间的共享判别特征,从而一定程度上降低原始高维样本的特征维度,进而缓解模型的过拟合缺陷.为此,首先考虑将MTMC 模型中关于实例特征与标记之间的隐式线性依赖假设ZY=ZXW以正则化项的形式显式加入目标函数(23),即

其中,W∈Rd×t表示显式的线性预测器.然后,继续考虑在上述模型(24)的基础上引入如下的多任务直推式特征选择机制

其中,||W||2,1项用来约束线性预测器W保持行稀疏,从而学习到跨任务之间的共享判别特征.特别地,我们注意到这里采用的特征选择明显区别于一般的特征选择机制,一方面我们是在去噪特征空间中实施特征选择,另一方面所有的实例(包括删失实例、未删失实例以及测试实例)均参与了特征选择.
最后,针对先验信息融合性不强的缺陷,进一步考虑引入如下的Toeplitz 矩阵S∈Rt×(t-1)并以生成正则化项的形式来诱导软标记矩阵ZY的

为此,最终构建出噪声容错弱监督直推式矩阵补全(WSTMC)模型为
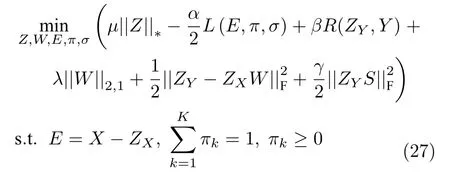
3.3 优化
由于所提出的WSTMC 模型涉及到最大似然估计项L(E,π,σ)的求解,受到期望最大化方法(Experimental maximization,EM)的启发,我们也考虑引入隐含变量来表征噪声Eij是否属于混合高斯分布的第k个分量,从而得到完全数据的log 似然函数

然后,采用EM 方法的思想求解所提出的WSTMC 模型,为此,我们令θ=(Z,W,E,π,σ),首先通过E 步求出隐含变量hijk的期望rijk(这里rijk表示在当前模型参数下第 (i,j)个观测数据Eij来自第k个分量的概率,也即分量k对观测数据Eij的响应度):
E-step (求解rijk).


此时,可采用交替求解方法,因此有:
M-step1 (求解πk).

M-step2 (求解).

M-step3 (求解Z,W).

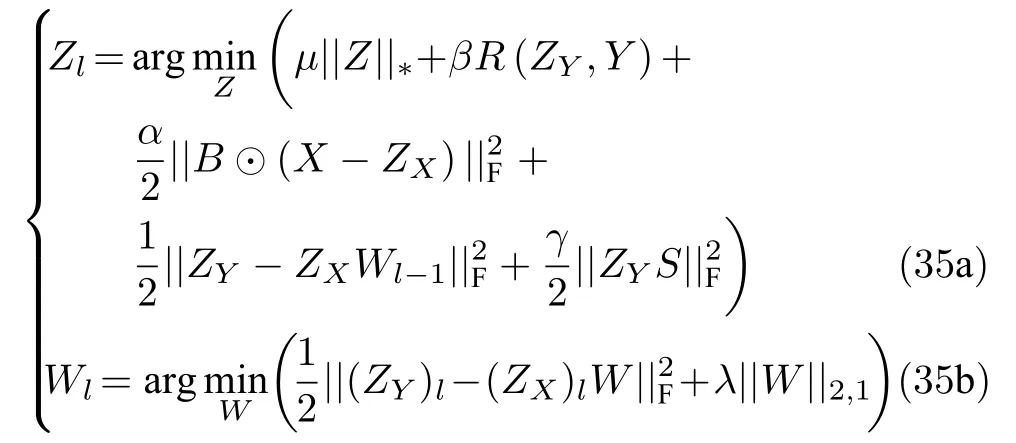
具体地,对于变量Z,根据定理1 可由如下方式求解:
M-step3.1 (求解Z).

对于变量W,同样根据定理1 可由如下方式求解:
M-step3.2 (求解W).


基于上述分析,所提出的求解WSTMC 模型的拟期望最大化优化算法可概述为算法1.

3.4 时间复杂度分析
求解WSTMC 模型的算法1 是一个迭代优化算法,迭代过程由E-step 和M-step 组成.假设算法1 的外循环迭代次数为NEM, 简单分析可知Estep 更新rijk所需的时间复杂度为 O(Kmd);基于E-step 的计算结果更新M-step 的π,σ所需的时间复杂度均为 O(Kmd);基于r和σ计算中间变量矩阵B所需的时间复杂度为 O(Kmd);接下来,在更新M-step 的Z,W时又涉及到两个需要迭代求解的子问题(35a)和(35b),此时不妨假设求解这两个子问题的内部循环迭代次数为NBPL, 那么对于Mstep 的子问题(35a),求解Z的时间复杂度为O(mdt+m(d+t)min{m,(d+t)}),对于M-step 的另一个子问题(35b),求解W的时间复杂度则为O(mdt+md2).综上可知,算法1 的时间复杂度为O(NEM(Kmd+NBPL(m(d+t)min{m,(d+t)}+mdt+md2))).为简单起见,考虑到实际问题中样本的特征维度d通常大于任务个数t,所以求解模型WSTMC的算法时间复杂度可以简化为O(NEMNBPL(m2d+md2)).在本文第4 节的实验部分,我们比较了WSTMC 模型和其他6 种同属于多任务学习范型的生存分析模型,对于这6 种相关模型的详细介绍及实验结果参见第4.4 节及第4.5 节.表1 给出了WSTMC 及其他6 种相关模型的时间复杂度(为简单起见,这里给出的时间复杂度均假设样本的特征维度d大于任务个数t).从表1 可以看出,相较于其他6 种多任务学习方法,本文所提出的WSTMC模型具有最高的算法时间复杂度.然而,实验中发现,每一步并不需要求出子问题的精确解,实际上,只需更新Z与W各一次得到子问题的一个近似解,已足以使算法最终获得与精确求解子问题时相当的模型性能.

表1 WSTMC 及其他相关模型的时间复杂度比较Table 1 Time complexity comparison of the proposed WSTMC and the other related models
4 实验
在本节中,首先介绍实验数据集和评价指标,然后介绍所采用的实验方法和生存分析比较模型,最后报告实验结果并展开实验分析.
4.1 实验数据集
本文使用了5 个公开的癌症生存分析数据集,具体包括:NSBCD (Norwegian/Stanford Breast Cancer Data)[29]、DBCD (Dutch Breast Cancer Data)[30]、Lung (Gene Expression Profiles of Lung Adenocarcinoma)[31]、DLBCL (Diffuse Large BCell Lymphoma)[32]和 MCL (Mantle Cell Lymphoma)[33]数据集.这些数据集可以分别从http://user.it.uu.se/~liuya 610/download.html 和http://llmpp.nih.gov/MCL/下载.表2 概述了这些数据集的相关信息,其中“#Instances”列表示数据集所包含的实例数(包括删失实例和未删失实例),“#Features”列表示相应数据集中实例的特征数,“ #Censored”列表示数据集中所含的删失实例数,“#Labels”列表示每个数据集对应的任务个数(即所划分的时间间隔数,其中NSBCD 和Lung 数据集以“月”作为时间间隔单位;DBCD、MCL 和DLBCL 数据集以“年”作为时间间隔单位).此外,为了表明所采用的数据集是否为高维小样本问题,我们还在“#Ratios”列记录了每个数据集中实例数与特征数之间的比例,通常认为当样本个数比特征维数低一个数量级时即为高维小样本问题,按照这个标准,容易发现表2 中后四个数据集都属于高维小样本问题.

表2 实验所用数据集概述Table 2 Details of datasets used in this study
4.2 评价指标
由于数据集中存在删失数据,传统回归模型常用的评价指标在生存分析中并不适用.类似于文献[7],本文也选用了C-index 和Weighted average AUC 两个指标来评估生存分析性能.其中Cindex 指标侧重评估模型在所有任务上的整体回归性能,而Weighted average AUC 指标则注重评估模型在各个任务上的平均分类性能.两个指标的具体定义如下:
1) C-index:该指标旨在通过考虑不同事件的相对风险来评估预测值和实际值之间的差异.例如,考虑一对二元组变量()和(),其中表示第i个实例的预测存活时间,Oi表示第i个实例的观察时间.首先定义一致性概率为

根据定义,对于可以直接预测生存时间的模型来说,C-index 指标计算如下:

其中,I(·)为指示函数.对于多任务类型的生存分析模型,可以通过判断事件是否发生(以设定阈值的方式)从而计算出生存时间.由于阈值的选取具有主观性,因此根据Li 等[7]的建议,多任务模型中Cindex 可以通过如下方式计算:

其中,Si表示第i个实例在所有任务上评分之和,即

2) Weighted average AUC:该指标旨在评估模型的整体分类性能,即评估模型能否准确预测出实例在某时间间隔上的生存状态.将1 当做事件未发生的标记,0 当做事件已发生的标记,则每个时间段就可以看成一个分类任务,整个任务矩阵就相当于t组分类任务.具体地,Weighted average AUC指标可以定义如下:
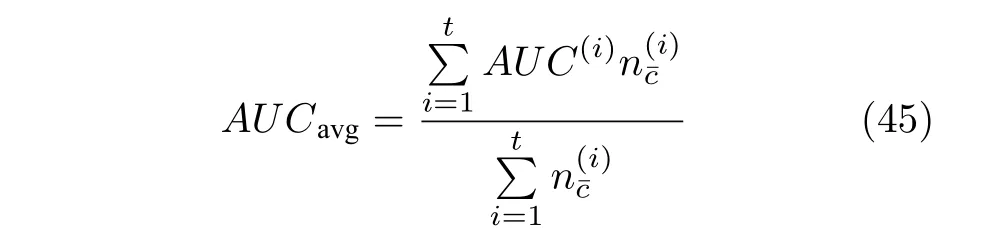
其中,AUC(i)表示第i个任务的AUC 值,表示第i个任务上已知生存状态的实例数目.
4.3 实验方法
为了确定所提出的WSTMC 模型的最佳参数(γ,β,λ,μ,α,c,K),本文采用交叉验证的方式来评估实验结果.具体来说,对于实例数目超过150 的生存数据集,我们采用5 折交叉验证,其他的数据集则采用3 折交叉验证.为了公平起见,其他对比方法均采用上述的交叉验证方式.
另一方面,传统上一般使用网格搜索来寻找合适的参数,但对于本文所提出的WSTMC 模型来说,这将非常耗时.因此,需要一种更加有效的超参数选择策略.本文采用了基于贝叶斯优化[34]的自动调参方法来选择最佳的超参数.该方法可以帮助模型选择出具有更高概率提升预测效果的超参数.具体来说,贝叶斯优化假设存在一个未知的函数ψ=CV_WSTMC(P),其中P∈R7表示一个超参数向量,ψ表示WSTMC 模型对于每组输入的参数向量进行交叉验证后取得的预测结果.显然,最终目的是寻找这个函数的最大值以及对应的超参数向量.首先,贝叶斯优化假设未知函数的结果是通过高斯过程(Gaussian processes,GP)采样得到的.因此,可以基于历史记录(先前的超参数值及其相应的交叉验证的预测结果)计算出超参数的后验概率分布.然后,重复迭代下面3 个步骤,直到满足停止标准(迭代到最大次数,或者连续10 次迭代ψ值都无法得到提升).
步骤1.根据最大化采集函数选择出下一个最具有“潜力”的评估点(超参数);
步骤2.根据选择出的参数评估未知函数的预测值;
步骤3.将当前的记录加入到历史记录中,并更新高斯过程.值得注意的是,本文没有选择PI(Probability of improvement)作为采集函数,而是使用EI (Expected improvement)作为采集函数来选择下一次试验的超参数.虽然PI 策略能够选择相对当前预测结果提升概率最大的评估点,但它仅仅反映了提升的概率,并没有反映提升量的大小.与之相比,EI 策略两者都能考虑到,还能进一步处理局部和全局之间的关系[35].此外,协方差函数也存在很多种选择方案[34].本文采用了自动相关性确定(Automatic relevance determination,ARD)作为高斯过程的协方差函数[36],它有助于有效地识别并去除参数向量中不相关的维度.
4.4 对比模型
为了验证所提出的WSTMC 模型的有效性,我们将其与18 种广泛使用的生存分析模型进行了比较.这些模型可归纳为如下4 类:基于Cox 的模型、参数删失回归模型、线性模型和基于多任务的模型.表3 概述了这18 种比较模型和所提出的WSTMC 模型的相关特点,主要从噪声容错机制、直推式学习机制、时序稳定性机制、特征选择机制和多任务学习机制等5 个方面进行了比较.具体地,对于Cox 模型,我们选择了传统Cox 模型,LASSOCOX 模型[10],EN-Cox 模型[11],Cox-ℓ2,1模型和Cox-Trace 模型[37].对于参数模型,选择了4 种基于不同分布假设的模型,即Weibull、Logistic、Log-logistic 和Log-Gaussian.此外,还与3 种线性模型进行了比较,包括普通的最小二乘(Ordinary least square,OLS)模型[38]、Tobit 模型[14]和RWRSS(Regularized weighted residual sum-of-squares) 模型[35].对于基于多任务的模型,选择了Multi-LASSO模型、Multi-ℓ2,1模型[27]、MTMC 模型[8]、MTLSA/MTLSA.V2[7]模型和NLMC[28]模型.值得注意的是,OLS 模型、Multi-LASSO 模型和Multi-ℓ2,1模型均无法处理删失实例.因此,它们只能基于未删失实例进行学习.为公平起见,比较模型所涉及的所有参数均采用了和WSTMC 模型相同的交叉验证 策略和参数调整方法.

表3 对比模型的特征比较Table 3 Comparison of characteristics for the competing models
4.5 实验结果
首先,采用C-index 指标来评估生存分析模型整体回归性能.表4 报告了不同方法在5 种真实数据集上的实验结果.对于每种数据集,我们用粗体将最优C-index 值突出显示,也同时用粗体加下划线标示出第二优和第三优的C-index 值.从表4 可以看到,WSTMC 模型在所有数据集上均取得了最好的结果.此外,分析实验结果还可以发现排名前三的结果大多是由基于多任务学习的模型所获得,这表明通过将原始的生存分析问题转化为预测各个时间间隔内生存状态的多任务学习问题,可以有效利用任务之间共享的判别特征来提高预测性能.同时,我们也注意到MTLSA 和MTLSA.V2 模型的性能明显优于Multi-Lasso 和Multi-l2,1,这反映出能够在训练阶段利用所有实例(删失实例和未删失实例)的模型比只能够利用单一的未删失实例的模型效果更好.除此之外,对比WSTMC 模型以及MTMC 和NLMC 模型,由于后两种矩阵补全模型无法自适应地选择出跨任务共享的判别特征,也没能利用时序稳定性这一先验知识,所以效果始终差于我们所提出的模型.另外,我们也发现,相较于MTLSA 和MTLSA.V2 模型,WSTMC 模型引入混合高斯分布来拟合数据分布中未知的复杂噪声,有利于消除噪声对特征选择的影响,从而进一步降低了预测错误率.
接着,我们采用Weighted average AUC 指标来评估生存分析模型在各个任务中的平均分类性能.表5 报告了不同方法在5 种真实数据集上的实验结果.同样地,对于每种数据集,最佳结果使用粗体突出显示,其他前两名的结果使用粗体加下划线突出显示.从表5 可以看出,我们的模型除了在DLBCL 数据集上效果略差外,在其他数据集上始终优于其他对比方法.综合表4 和表5 的实验结果,我们可以看到参数删失回归模型在两个评价指标中都没有取得任何前三名的结果.这表明常用的数据分布无法满足实际需求,也就是说难以选择出合适的理论分布来建模实际问题.相比之下,Cox-l2,1模型、MTLSA 模型、MTMC 模型和WSTMC 模型都在两个评价指标中获得过前三名.一方面,这验证了l2,1范数和直推式学习机制有利于缓解高维小样本带来的过拟合问题.另一方面,也证实了相较于传统的生存分析模型,多任务学习方法,尤其是有效地利用了先验时序稳定机制的多任务学习方法能够很好地解决生存分析问题.

表4 所提出的WSTMC 模型和其他比较模型在C-index 指标上的性能比较(标准差)Table 4 Comparison of the WSTMC and competing models using C-index (standard deviations)

表5 所提出的WSTMC 模型和其他比较模型在Weighted average AUC 指标上的性能比较(标准差)Table 5 Comparison of the WSTMC and competing models using Weighted average AUC (standard deviations)
4.6 消融实验
进一步,为了验证WSTMC 模型中MoG 噪声容错机制、多任务直推式特征选择机制以及时序稳定性机制的有效性,我们也比较了3 种WSTMC的消融模型,即:未引入MoG 噪声容错机制的WSTMC-nM 模型、未引入多任务直推式特征选择机制的WSTMC-nF 模型和未引入时序稳定性机制的WSTMC-nT 模型.具体地,我们通过禁用WSTMC 模型中MoG 噪声容错机制、多任务直推式特征选择机制及时序稳定性机制中的任意一种来验证这些机制在模型中所起到的实际效果,表6 报告了两种评价指标C-index 和Weighted average AUC 上5 种相关模型MTMC、WSTMC-nM、WSTMC-nT、WSTMC-nF 以及WSTMC 的性能.实验结果表明:1)相比于传统的MTMC 模型,三种消融模型WSTMC-nM、WSTMC-nF 和WSTMC-nT 在两种评价指标C-index 和Weighted average AUC 上都无一例外地优于MTMC,这表明引入MoG 噪声容错机制、多任务直推式特征选择机制以及时序稳定性机制是有助于提高传统MTMC 模型性能的;2)相比于同时引入3 种机制的WSTMC 模型,消融模型WSTMC-nM、WSTMCnF 和WSTMC-nT 在两种评价指标C-index 和Weighted average AUC 上性能均弱于WSTMC,进一步验证了3 种机制的同时引入优于任意两种机制的组合引入,从而实验上表明我们所提出的WSTMC 模型中3 种机制的引入是合理有效的.

表6 在两种评价指标C-index 和Weighted average AUC 上的消融性实验性能比较(标准差)Table 6 Comparison of the ablation experiments using C-index and Weighted average AUC (standard deviations)

表6 在两种评价指标C-index 和Weighted average AUC 上的消融性实验性能比较(标准差) (续表)Table 6 Comparison of the ablation experiments using C-index and Weighted average AUC(standard deviations) (continued)
5 总结与讨论
针对生存分析领域通常面临的高维小样本和噪声敏感问题,本文提出了一类新颖的噪声容错弱监督直推式矩阵补全(WSTMC)模型.首先将原始的生存分析问题建模成一类传统的多任务直推式矩阵补全(MTMC)模型,然后引入高斯混合分布来拟合数据中未知的复杂噪声.同时为了缓解高维小样本所带来的过拟合缺陷,我们还设计了一类适用于去噪特征空间的多任务直推式特征选择机制,以期筛选出跨任务共享的判别特征,从而提高模型的泛化性能.相较于传统的MTMC 模型,我们提出的WSTMC 模型一定程度上克服了MTMC 模型噪声容错性差、泛化性能不足以及先验信息融合性不强的缺陷.最后,多个真实数据集上的实验结果证实了所提出的WSTMC 模型优于其他广泛使用的生存分析方法.
然而,我们的方法也仍然存在改进的空间,比如无论是传统的MTMC 模型还是我们的WSTMC 模型都是基于实例特征与实例标记的线性依赖假设,这种假设与实际情形未必相符,如果能将我们的模型推广至非线性假设情形,将极有可能提升生存分析的预测性能.我们将在后续研究中尝试采用核化的方法来放宽已有模型的线性依赖假设,并同时尝试引入其他类型的非线性依赖实现机制.
