基于Maximin方法的异质性数据分位数回归模型研究
2022-01-10黄聪聪
蔡 超 黄聪聪
(山东工商学院 统计学院,山东 烟台 264005)
一、引言
Fan J和Han F等(2014)[1]认为大数据除了具有海量化这一重要特征之外,异质性也是大数据的重要特征,即大数据通常由具有多个来源的数据组合而成,不同来源的数据呈现不同的影响模式。譬如在空气质量研究中,影响空气质量的气象因素影响模式在不同季节存在差异。如果在建立空气质量影响因素模型时忽略上述异质性影响,可能会导致模型估计出现错误。特别是当多个来源的数据混合在一起无法分离时,建模和估计都具有一定难度。因此,研究具有多个来源的异质性数据的建模问题有重要的理论意义和实践价值。
针对具有多个来源的异质性数据的建模研究,PinheiroJ C和Bates DM(2001)[2]提出了混合效应模型,假定变量的回归系数为常系数,通过引入可加形式的固定和随机效应来刻画数据的异质性。但有研究表明上述假定过于严格,往往与现实不符。因此,Hastie T和Tibshirani R(1993)[3]、Zhang W 和 Fan J(1999)[4]、Cai Z和Fan J等(2000)[5]等提出了变系数模型,假定模型中的参数与变量之间具有函数关系,数据的异质性通过这种函数关系来刻画。但变系数模型过多的待估参数会损失自由度。鉴于上述问题,Lin CC和 NgS(2014)[6]、Su L和Shi Z等(2016)[7]提出了组异质性回归模型,通过对不同来源的数据设定不同的回归系数刻画数据的异质性。马双鸽和王小燕等(2015)[8]、斯介生和李扬等(2017)[9]、方匡南和赵梦峦(2018)[10]提出了整合分析模型,通过融合不同来源数据,同时求解多个不同来源数据的回归模型。然而,上述模型复杂性高,计算量很大。Meinshausen N 和 Bü hlmnn P(2015)[11]提出了均值回归的Maximin估计,即最大化所有来源数据最小的可解释方差。这个模型本质上是寻找一个简单模型来提取不同来源数据的共同属性,保证整个数据集上都有很好的预测精度。Rothenhausler D和Meinshausen N等(2016)[12]理论证明了均值回归Maximin估计的渐近性质,并给出了其置信区间。秦磊和夏传信等(2018)[13]将Maximin估计推广到广义线性模型,并且利用模拟数据和应用研究说明了这种方法具有较好的预测效果。
Meinshausen N 和 Bü hlmnn P(2015)[11]的研究工作是建立在均值框架下,仅能预测响应变量的条件均值,无法揭示响应变量条件分布的变化规律。Koenker R和Bassett G(1978)[14]提出的分位数回归模型,不仅能够获得响应变量关于给定解释变量的多个条件分位数,而且能够不受异方差的限制,得到更加稳健的结果。因此,本文将Maximin估计推广到分位数回归模型,构建异质性数据的分位数回归估计方法:分位数回归的Maximin估计(Maximin Estimator of Quantile Regression,Maximin QR),给出了其数学表示、参数估计、模型检验与预测方法,并通过数值模拟检验Maximin QR方法的预测效果,最后将其应用于北京地区PM2.5的条件密度预测研究。
二、模型与方法
(一)模型表示


(二)参数估计


(三)系数检验


(四)模型预测

三、数值模拟
本节检验Maximin QR方法的实际表现,并将其与传统分位数回归方法(以下简称Classical QR)、传统的均值回归方法(以下简称Classical MR)和Meinshausen N和 Bü hlmnn P(2015)[11]提出的 Maximin MR 方法进行对比,数值模拟在R中编程实现。
(一)数据生成
考虑误差项为独立同分布的模型:
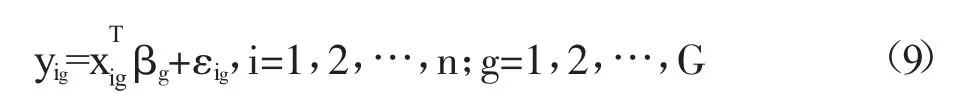
和误差项为非独立同分布的模型

式中,ng=104,xig∈ i5由标准正态分布生成,xig,1为 xig的第一个元素。设置随机误差项εig三种不同的分布:N(0,1)、t(3)和χ2(3)。
在误差项的不同分布情形下,数据有8种来源,即G=8,回归系数的取值如表1所示。由表1可知,异质性通过对不同来源数据设置不同的回归系数来刻画,而且每组来源数据具有共同结构 β0=(1,0,0,0,0)T。为检验Maximin QR方法的预测效果,选取前5组来源数据作为样本内数据进行估计,后3组来源数据作为样本外数据进行预测。这样,样本外数据会含有样本内数据中的某些结构,同时含有样本内数据中没有的结构。

表1 回归系数取值
(二)评价指标
选取平均绝对误差(Mean Absolute Deviations,MAD)和分位数平均绝对误差(Quantile Average Absolute Error,QAAE)来评价模型不同分位点处的预测能力,其定义如下:

(三)结果比较
图1报告了在不同误差分布情形下Classical QR和Maximin QR方法预测误差MAD的箱线图(由于各分位点的结果类似,因此只报告了τ=0.5时的结果)。为了方便对比,Classical MR和Maximin MR方法预测误差的箱线图也列在图1中。图2报告了在不同误差分布情形下Classical QR和Maximin QR方法预测误差QAAE的箱线图(由于QAAE依赖于分位点τ,因此Classical MR和Maximin MR方法无法计算QAAE的值)。需要说明的是,预测误差均是基于100次重复生成的数据集计算获得的,图1和图2中的散点是100次重复试验的预测误差。

图1 预测误差MAD的箱线图

图2 预测误差QAAE的箱线图
由图1和图2可知:第一,在不同误差分布情形下,4种方法的预测结果表现基本相同,这表明数值模拟的结果是稳定的。第二,在各分位点处,相对于Classical QR方法,Maximin QR具有较好的预测结果,表现为更低的MAD和QAAE值,因此可以认为Maximin QR方法在预测上更具优势。第三,与Maximin MR方法相比,中位点处的Maximin QR方法预测的MAD值都低于Maximin MR方法的预测值,意味着Maximin QR方法比Maximin MR方法更能得到准确的预测结果。此外,当误差项为非对称分布或异方差时,Maximin QR方法与Maximin MR方法预测误差的差异更为明显,这一结论表明,Maximin QR方法在误差项为非对称分布或异方差时的预测能力更具优势。
四、应用研究
(一)数据选取与描述
PM2.5(细悬浮颗粒物)是雾霾天气的主要成因。它不仅能够形成雾霾,影响大气能见度,而且因其颗粒小能携带有毒有害物质,进入人体会影响身体健康。PM2.5一般受到污染物本地排放和气象条件的影响,深入研究各种因素与PM2.5之间的关系有助于理解PM2.5分布的特点和揭示PM2.5聚集和消散过程背后的规律。由于秋冬季节是雾霾高发期,而且冬季是北方地区的供暖时期,燃煤污染更易引发雾霾天气。因此,可以认为各因素对PM2.5的影响模式在每个月份都不一致,即不同月份的数据具有不同的来源,整个数据集是异质性的。如果将所有数据进行合并分析,会忽略各月份数据的差异性;如果分月份单独建模分析,则会忽略各月份数据的关联性。基于此,本文考虑数据集间的关联性和异质性,运用Maximin QR方法进行估计,并进行条件密度预测。
以加州大学欧文分校机器学习资源库(UCI Machine Learning Repository)中的北京PM2.5数据集为研究对象(关于数据集更详细的信息请见Liang X和Zou T等(2015)[16]),寻求PM2.5与影响因素之间的关系。剔除缺失值后该数据集包含41757个观测值,以日为单位记录了2010年1月1日至2014年12月31日的PM2.5、露点温度、温度、气压、风速、每小时降雪量、每小时降水量、是否西北风、是否东南风、是否东北风等10个变量。数据的描述统计结果如表2所示。由表2知,PM2.5的偏度系数大于0且峰度系数大于0,说明PM2.5为右偏尖峰分布,表明运用均值回归模型分析各因素对PM2.5的影响并不奏效,需要利用分位数回归模型研究各因素与PM2.5之间的关系。

表2 北京PM2.5数据集描述统计
(二)模型预测比较
为了验证Maximin QR方法的预测性能,在北京PM2.5数据集上随机抽取9个月的数据作为样本内数据进行估计,其余3个月的数据作为样本外数据进行预测,以上过程重复试验100次。表3报告了100次重复试验的平均预测误差,图3报告了100次重复试验预测误差的箱线图。由表3和图3可知,在各分位点处,Maximin QR方法的预测误差最小,且在中分点处小于Maximin MR方法的预测误差。综合来看,Maximin QR方法的预测效果优于传统的分位数回归方法和Maximin MR方法。

表3 北京PM2.5数据集的平均预测误差
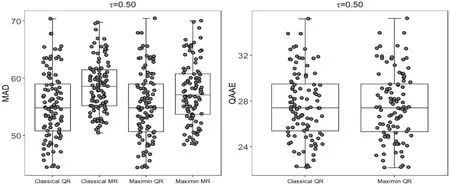
图3 北京PM2.5数据集预测误差的箱线图
(三)模型估计结果
对全部数据进行Maximin QR估计,估计结果如表4所示。为方便对比,Maximin MR估计的结果也列在表4中。由表4的估计结果可得到如下结论:
1.露点温度对PM2.5的增加有显著影响,且随着分位点的提高,系数值不断增大。这说明露点温度对PM2.5具有聚集作用,而且PM2.5越高时,露点温度使PM2.5聚集的作用越强。这主要由于PM2.5越高越能吸附更多的水汽和颗粒物,而露点温度增加更使PM2.5聚集,从而形成恶性循环。
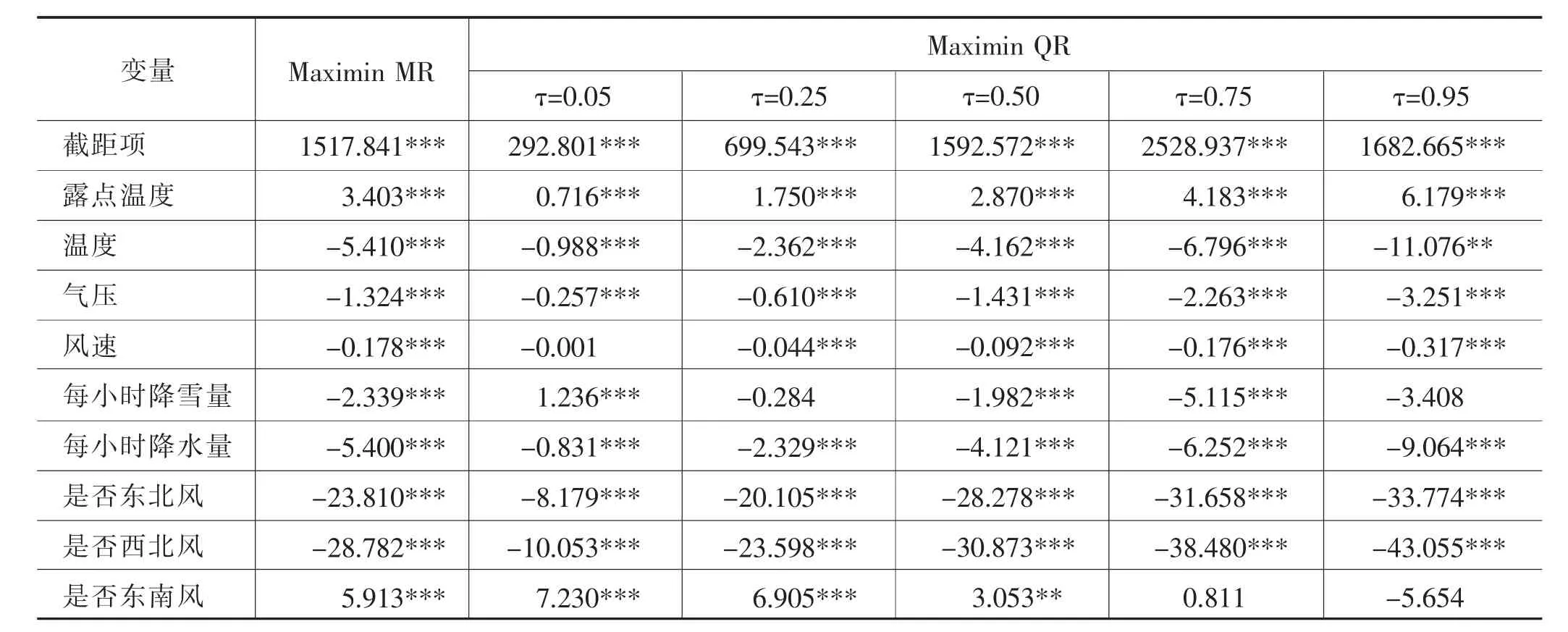
表4 系数估计结果
2.温度、气压、风速、每小时降雪量和每小时降雨量对PM2.5的减少有显著影响,且随着分位点的提高,系数值不断减小。这表明温度、气压、风速、每小时降雪量和每小时降雨量等气象因素增加时,会使PM2.5消散,且PM2.5越高时,这些气象因素使PM2.5消散的越多。这主要由于PM2.5越高越有较多的颗粒物聚集在一起,这些气象因素就消散得越多。
3.东北风和西北风对PM2.5具有负向影响,且随着分位点的提高,系数值不断减小。而东南风对PM2.5具有正向影响,且随着分位点的提高,系数值不断减小。这意味着北风使PM2.5有下降趋势,而南风使PM2.5有上升趋势。这主要是由于北京以北是太行山脉和燕山山脉,污染工业较少,北风带来的是相对洁净的空气;而北京的东南方向,广泛分布着消耗大量煤炭的重工业企业,东南风会把北京以南的污染物传送到北京。
(四)条件密度预测
首先,分位点在0.01和0.99之间每隔0.01连续取值,共设置99个分位点;其次,选取全部数据利用Maximin QR方法估计99个分位点处的回归系数;最后,分别选取一个解释变量的较低水平(低)、中等水平(中)和较高水平(高)(如果解释变量是离散变量,则选取0(否)和1(是)),其他解释变量取值不变,连续变量取其均值,离散变量取其众数,计算PM2.5在各分位点处的条件分位数预测值,进而讨论PM2.5的条件密度变化。各个解释变量不同水平的具体取值见表5。图4给出了9个解释变量分别变化时PM2.5的条件密度预测与条件均值预测,其中基于Maximin QR方法的条件密度预测用曲线表示,基于Maximin MR方法的条件均值预测用垂线表示。表5报告了PM2.5条件密度预测的描述统计量:均值、标准差、偏度和峰度。为便于比较,条件均值预测的结果也列于表5中。由表5可知,第一,基于Maximin MR方法的预测只能给出响应变量的一个条件均值水平预测结果,而基于Maximin QR方法的预测能够得到响应变量整个条件分布情况,能够获取更为全面的信息;第二,PM2.5条件密度预测的偏度都大于0,即都呈现右偏状态,表明预测的PM2.5存在非对称性;第三,PM2.5条件密度预测的峰度都大于0,即预测的PM2.5呈尖峰分布,表明PM2.5的预测值较为密集地分布在众数的周围,预测其众数可能更为准确。

表5 条件密度预测的描述统计

图4 PM2.5的条件密度预测
由图4可知,当露点温度增加时,条件密度曲线向右移动,散布逐渐变大,这表明露点温度对PM2.5具有正向影响,即露点温度越高,PM2.5越大;当温度、气压、风速、每小时降雪量和每小时降雨量分别增加时,条件密度曲线向左移动,散布逐渐变小,这表明温度、气压、风速、每小时降雪量和每小时降雨量对PM2.5具有负向影响且逐渐向其中心值集中,即这些天气因素增大时,PM2.5会降低。当东北风和西北风从无到有时,条件密度曲线向左移动,散布逐渐变小,而当东南风从无到有时,条件密度曲线向右移动,散布逐渐变大,这意味着北风使北京的PM2.5有下降趋势,而南风使PM2.5有上升趋势。条件均值预测结果也印证了各因素对PM2.5的上述影响,但远没有条件密度预测提供的信息丰富。
五、结论与启示
针对具有多个来源的异质性数据,本文提出了分位数回归的Maximin估计方法,并给出了其数学表示、参数估计、模型检验与预测方法。它的基本思想是最大化所有来源数据的最小可解释残差,构建一个简单的共性模型,以减少数据来源较多而呈现的复杂性。数值模拟的结果显示:Maximin QR方法与传统的分位数回归方法和Maximin MR方法相比,更能获得精确的预测结果,证明了该估计方法的正确性和有效性。最后,将Maximin QR方法应用于北京PM2.5数据集,研究各因素对PM2.5的影响,并在此基础上给出PM2.5的条件密度预测,结果表明:Maximin QR方法不仅能够比传统分位数回归方法和Maximin MR方法更好地预测PM2.5,而且通过条件密度预测曲线可知,PM2.5的条件分布呈右偏尖峰分布,预测其众数可能比预测其均值更为有效。针对PM2.5条件密度预测所呈现的分布特征,地方政府可以根据气象因素的不同水平准确预测PM2.5的未来走向,制定和调整本地空气质量治理政策。
本文提出的方法适用于数据来源已知的情况,但当数据来源有多个且未知时,本文提出的方法将不再适用。在未来的研究过程中,可以考虑将本文的估计方法延伸到数据来源未知的异质性数据。例如,首先用交叉验证等准则确定数据来源的组数,然后,按照无放回抽样将数据平分为G组,最后,分组后的数据按照数据来源已知的方式进行处理。
