基于3D点云语义地图表征的智能车定位*
2022-01-08朱云涛胡钊政吴华伟
朱云涛 李 飞 胡钊政▲ 吴华伟
(1.武汉理工大学智能交通系统研究中心 武汉 430063;2.武汉理工大学重庆研究院 重庆401120;3.湖北文理学院汽车与交通工程学院 湖北 襄阳 441053)
0 引 言
近些年,“汽车智能化”越来越受到学术界和工业界的关注,其中的高精度定位技术[1]是智能车技术的基础和核心。激光雷达[2]由于有探测精准、信息量丰富、抗干扰性强等优点,被广泛应用在智能车定位领域。
基于激光雷达的定位主要分为激光SLAM[3](simultaneous localization and mapping)和地图定位[4]2种。Zhang等[5]提出实时建立三维点云地图并基于地图矫正位姿的方法,但该方法在线建图较耗时且随运动距离增长会产生累积误差。K.Koide等[6]同时融合GPS,惯性测量单元和激光雷达进行实时建图和定位,引入了闭环优化策略大大改善了累积误差和定位高程差问题,但实际中闭环检测和优化非常困难。而地图定位由于地图离线采集、精度高等优点,目前已经被广泛应用于工程实践和生活当中。
语义地图是通过语义分割建立的地图。S.Thrun等[7]利用投影网格中点的高度差分割地面,D.Zermas等[8]对分段的地面点云分别利用RANSAC分割地面;彭泽民等[9]提取标准图片与待识别图片的垂直、水平方位的灰度分布,通过计算Pearson相关系数识别交通标志牌;李游[10]对体素化后的数据进行垂直连续性分析,同时结合自适应圆柱模型的方法分割杆状物。这些单一方法都存在欠分割和使用场景单一的缺点。
利用语义地图[11]对智能车定位意义重大。R.Dube等[12]将分割的语义目标直接匹配实现场景识别,但分割目标包括车辆等静态物体,影响后续定位。Liu等[13]利用语义地图中各语义目标的拓扑关联信息实现场景识别,但单一的拓扑信息不能很好地表征场景。Chen等[14]使用深度学习剔除动态语义目标以实现静态语义地图的构建和智能车定位,但深度学习方法存在参数多、训练量大的缺点。基于地图的智能车定位分为节点级定位和度量级定位2个部分,本文主要研究基于地图的节点级定位。
本文提出了1种基于3D点云语义地图表征的智能车定位方法,分为语义分割、地图表征、定位3个部分。分割的语义目标由地面、交通标志牌、杆状物组成;地图表征模型由一系列位置节点组成,各位置节点由语义编码和高精度全局位置共同表征,其中语义编码的生成先后经过语义俯视投影、带权有向图生成、语义路生成和语义路编码4个过程,高精度全局位置由高精度惯导的数据表征;定位时,首先利用地图节点的全局位置进行GPS粗定位,然后采用语义编码渐进匹配的策略完成节点级定位,最后完成整个智能车定位过程。
1 本文算法
1.1 系统概述
图1为系统流程图,系统共分为3个模块。

图1 系统流程图Fig.1 Flow of the system
1)语义分割。首先,对点云预处理和规则化实现地面点云分割;然后,基于反射强度和形状特征实现交通标志牌的筛选;最后,利用基于对象分析的方法分割杆状物。
2)地图表征。利用语义编码对地图节点作语义表征,利用组合惯导采集的高精度GPS对地图节点作全局位置表征,再由一系列位置节点组成语义地图表征模型。
3)定位。在语义地图表征模型建立后,通过GPS粗定位确定待定位节点在地图中的大致范围,语义编码渐进匹配确定与当前车辆位置相距最近的表征模型的节点。
1.2 基于三维激光点云的语义分割
地面点占据整个点云的绝大部分,对分割影响较大,需要在分割其他物体前剔除;交通标志牌和杆状物是道路场景的典型静态特征,其形状规则且特征显著,分别代表了场景的水平维度特征和竖直维度特征;因此本文选择这三者作为语义分割对象。
1.2.1 基于俯仰角评估的地面分割
对规则化后的点云作俯仰角评估实现地面点云分割,见图2。先通过条件滤波截取设定范围内的点云,再用统计滤波器去除离群点,再对点云规则化,即求出任意1个点的行和列下标,则点Pi(xi,yi,zi)的垂直角θvi和水平角θhi分别为
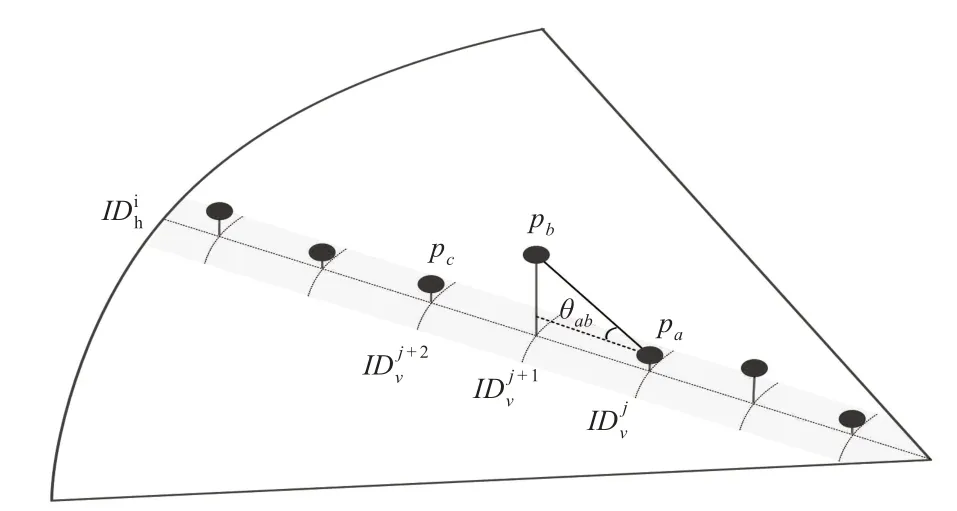
图2 俯仰角评估示意图Fig.2 Schematic of pitch angle evaluation
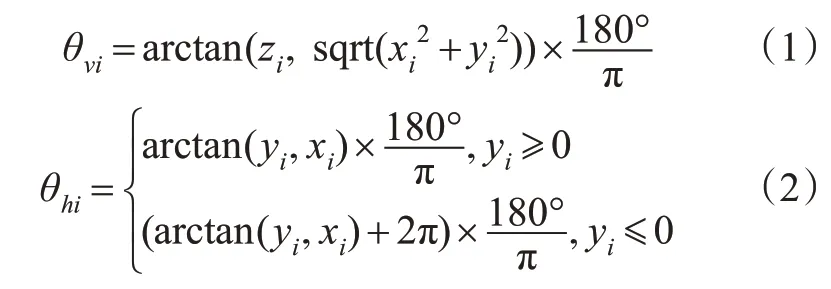
式中:(xi,yi,zi)为点云p中第i个点云pi的坐标;sqrt()为平方根函数;arctan()为仅正切函数。
点P(xi,yi,zi)的水平序号IDh为
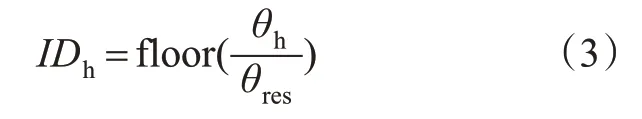
式中:θres为激光雷达的垂直角分辨率;θh为激光点云的水平角;floor()为向下取整函数。
分别连接相同水平序号的相邻2个点,即点Pa(xa,ya,za)和其上面1个点Pb(xb,yb,zb),则其的俯仰角θab为
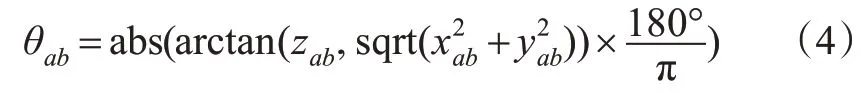
式中:abs()为绝对值函数;xab,yab和zab分别为对应方向的坐标。由于实际中城市道路斜面坡度很小,本文设置俯仰角阈值为10°,若满足θab≤θmax,则认为pb属于地面点云。
1.2.2 基于反射强度和形状特征的交通标志牌分割
利用反射强度和形状特征从地面分割后的剩余点云中继续分割交通标志牌。设置强度阈值对点云粗分割,将点云分割为大强度点云和小强度点云。基于强度对交通标志牌作粗分割的具体的效果见图3。

图3 交通标志牌粗分割Fig.3 Coarse segmentation of traffic signs
大强度点云包含绝大多数明显的交通标志牌,对其欧式聚类,再对各聚类点云基于3种先验信息构建多级滤波器完成精确分割,多级滤波器中设置点云数量阈值Nmin,高度阈值Hmin,高度差阈值Hdiff,当聚类Ci同时满足
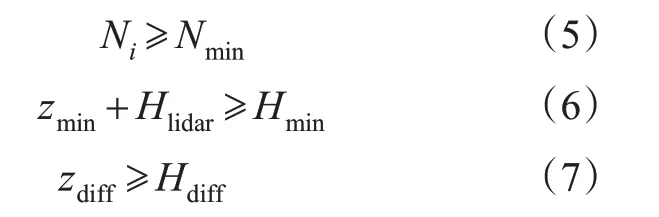
则该聚类Ci为最终分割的交通标志牌。
小强度点云可能包含背面朝向激光雷达的交通标志牌,以下对小强度点云实施精分割,精分割最终效果见图4。舍弃高度Hi<Hmin的点,以去除灌木丛等干扰物,再利用PCA(principal component analysis)算法求出对应的特征值λ1,λ2和λ3以描述点云的形态特征,设λ1≥λ2≥λ3,D为空间维度,则有以下关系。
图4 交通标志牌精分割Fig.4 Precise segmentation of traffic signs

由于道路上的交通标志牌附着在杆状物体上,其点云集具有平面维度特征,因此若检测到某点云点集的空间维度D=2,则表明其可能含有交通标志牌。其次再通过点的曲率特征,定义某帧点云中某1个点pi的曲率为
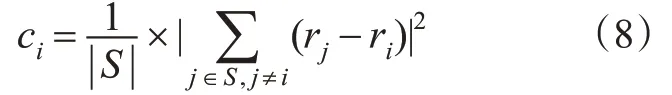
式中:|S|为点集S中的点云数量,S为与pi在同1条激光线束上的点集,且S表示的点集均匀分布在pi的两侧;ri为点云pi与激光坐标系原点间的欧式距离;rj为S中另1个点云pj与激光坐标系原点间的欧式距离;计算出某1个点的曲率后,设置曲率阈值cth,当满足ci<cth则该点为平面上的点云。最终利用上述基于先验信息的多级滤波器筛选出交通标志牌。
综合对大强度点云的分割结果和对小强度点云的分割结果,可准确提取整个场景中的交通标志牌。
1.2.3 基于对象分析的杆状语义目标分割
利用基于对象分析的方法从地面分割、交通标志牌分割后的剩余点云中分割杆状目标,其主要包括杆状交通设施和树干。
对滤除地面和交通标志牌后的剩余点云欧式聚类生成点簇对象集合,该对象集合中存在仅包含单个物体的点簇对象和可能包含杆状物的混合点簇对象。通过最小外包盒和迭代最小割结合的方法从混合对象中初步分割杆状物,生成所有点簇对象的最小外包盒并设置筛选条件。

式中:st,Smin,zt,Hmin分别为最小外包盒在水平面上的俯视投影面积、面积阈值、最小外包盒高度、高度阈值。将满足该条件的对象称为混合点云对象,其次利用迭代最小割法[15]从中分割杆状目标。
欧式聚类和迭代最小割后,杆状目标被分割成一个个独立的点簇对象。鉴于杆状物竖直方向的半径变化均匀且高度较高,本小节剔除大于一定高度的点簇对象后,用切片生长法从剩余点簇对象中分割出杆状物,见图5,步骤如下。

图5 切片生长法分割Fig.5 Segmentation of slice growth
1)将点簇对象沿竖直方向均匀横切形成若干切片,计算各切片的对角线长度di。
2)从下往上依次比较两两相邻切片的对角线长度差Ddiff和长度差阈值dt,若Ddiff<dt则连接切片并进行切片增长生成增长切片。
3)设置阈值ds和Hs,按顺序计算各增长切片对角线长度d和垂直高度H,若d<ds且H>Hs,若最终保留的增长切片数不为0,则为杆状目标。
1.3 面向智能车的点云语义地图表征
对智能车道路场景做地图表征,表征过程见图6,该模型由一系列地图节点组成,各地图节点由语义编码和高精度全局位置组成,全局位置表示为通用横墨卡托(universal transverse mercator,UTM)坐标。

图6 点云语义地图模型Fig.6 Semantic map modeling from point clouds
1.3.1 地图节点的语义表征
首先生成语义编码:以语义目标的整体点云质心代替实际物体,将分割的交通标志牌和杆状语义目标作俯视投影得到语义俯视投影图,见图7。
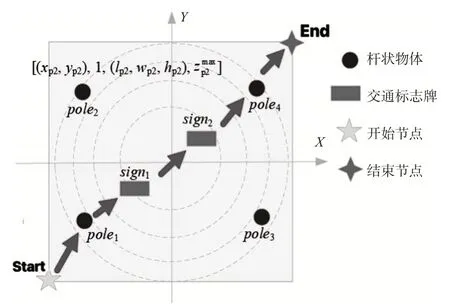
图7 语义俯视投影图Fig.7 Semantic overhead projection
本文规定俯视图左下角为起点,右上角为终点,从起点重复遍历各类目标至终点结束,生成的带权有向图见图8,语义目标间的权值以欧式距离表示。
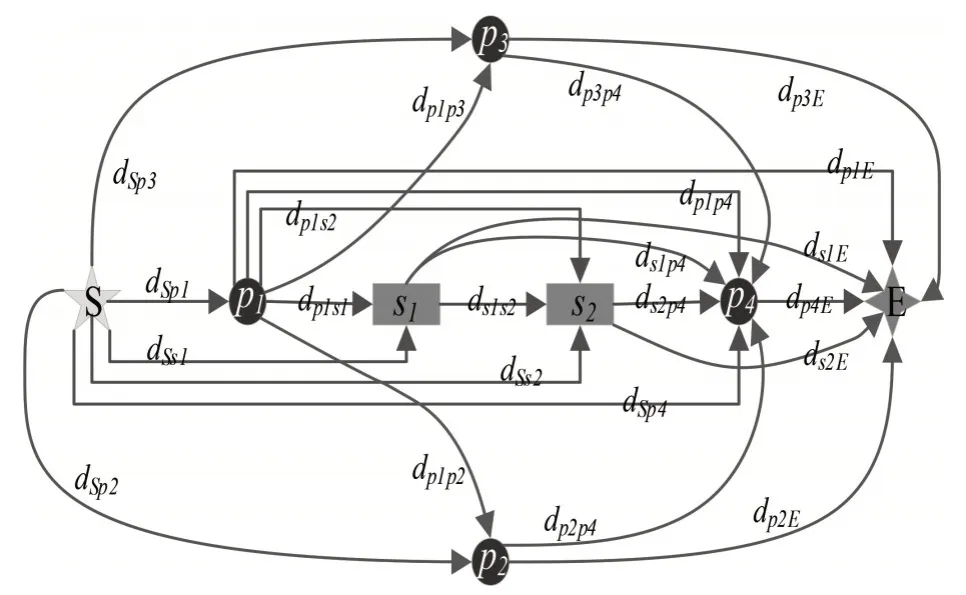
图8 语义带权有向图Fig.8 Semantically weighted digraph
记录下每条路径下的所有信息,包括目标节点序列、目标节点间距离、目标最小外包盒尺寸以及目标离地高度,生成1条语义路。式(11)表示从起点S经过dsp1距离遍历到杆状目标,再经过dp1s1遍历到交通标志牌,再经过ds1E距离到达终点E。
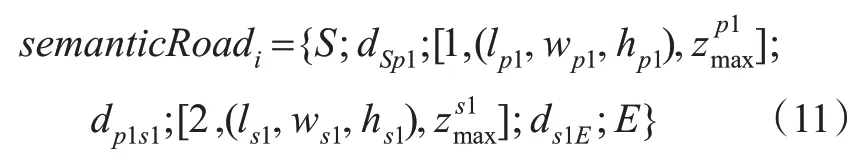
式中:lp1,wp1,hp1,zp1max分别为最小外包盒的长、宽、高和离地高度;p和s分别为杆和交通标志牌;1和2分别为杆和交通标志牌,最终所有语义路构成该场景的场景语义编码,见图9。
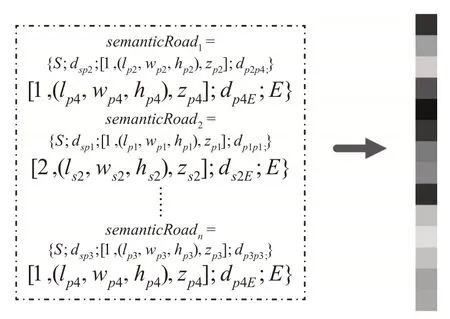
图9 场景语义编码Fig.9 Scene semantic coding
1.3.2 地图节点的全局位置表征
利用组合惯导结合实时动态(real-time kinematic,RTK)载波相位差分技术采集高精度的GPS信息,由于智能车行驶的道路环境可以简化为二维平面,UTM坐标系统使用基于网格的方法将地球的球面经纬度坐标转换成平面直角坐标,因此将节点的高精度GPS坐标投影到UTM平面坐标系中,即通用横轴墨卡托投影系统,以高精度UTM坐标表征地图节点的全局位置。
1.4 基于语义表征模型的智能车定位
本文以道路场景的地图模型为基础,将智能车定位分为粗定位和节点级定位。定位时只需要激光雷达和普通的GPS设备。
粗定位时,主要利用普通GPS缩小定位范围,即根据待定位节点的GPS信息转换成的UTM信息,从地图表征模型的地图节点中确定与当前待定位节点最相近的几个地图节点,该过程通过比较节点间的UTM坐标的欧式距离完成,最后得到节点候选集,粗定位过程见图10。
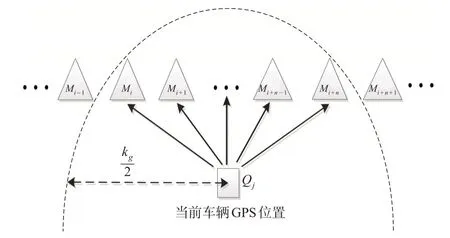
图10 GPS粗定位Fig.10 GPS coarse positioning
节点级定位时,通过不同节点对应的语义编码之间的匹配实现,以编码中的语义路匹配数量表征节点间的匹配度,从节点候选集中选出和当前待定位节点匹配度最高的地图节点,节点级定位见图11。设semanticRoadj为待定位节点中的某条语义路,MSR={semanticRoadMi|i=1,2,…,n}为GPS粗定位后节点候选集中某个节点包含的语义路集合,待定位节点和候选节点间的语义路匹配依次按以下规则。
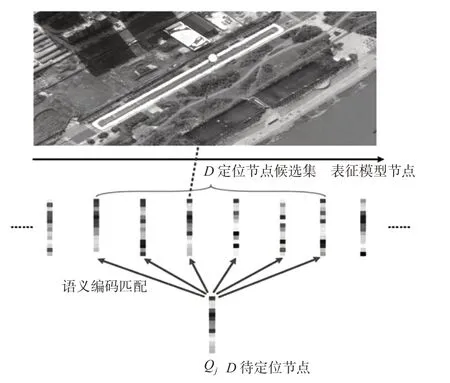
图11 节点级定位Fig.11 Node-level Localization
1)目标种类序列匹配。设semanticRoadj的目标种类序列为S12121E,若MSR中存在某语义路序列与其相同则匹配成功。
2)最小外包盒和离地高度匹配。若语义路间对应种类的语义目标符合以下条件则匹配成功。
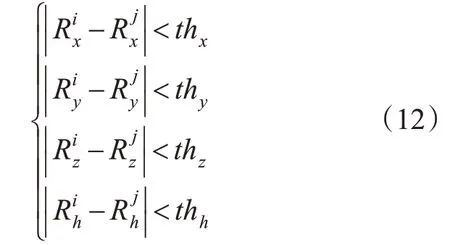
3)路径权值匹配。设2个语义路集合的路径权值集合为{di|i=1,2,…,N}和{dj|j=1,2,…,N},若满足以下条件称匹配成功。
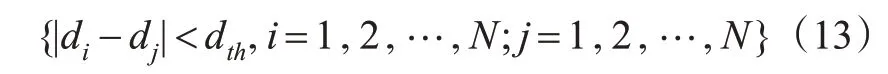
式中:dth为路径间的权重阈值;N为路径总数,通常经过以上3个步骤可以确定出1条与semanticRoadj匹配上的语义路。
4)匹配唯一性检验。当semanticRoadj与MSR中多条语义路匹配时,此步确定出匹配度最高的语义路,设和分别为语义路中第m对杆状物的距离和第n对交通标志牌间的距离,D为2条语义路的最终距离,则有
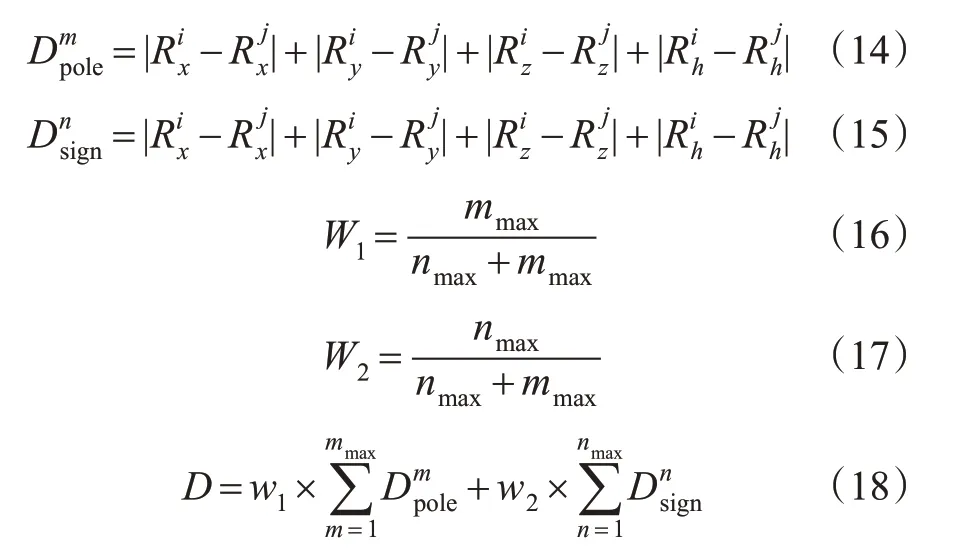
2 实验与分析
实验平台为搭载激光雷达和组合惯导的比亚迪E5智能车,见图12(a),其上搭载的激光雷达和组合惯导系统的安装位置见图12(b)。实验数据集由智能车以20~40 km/h的速度行驶在武汉市临江大道上采集,雷达和惯导采集节点的频率均为10 Hz且时间已同步,相邻节点间距约0.5 m,实验共采集3组数据集,总长度为3 576 m,覆盖面积为47 628 m2,各数据集采集场景见图12,其中:①数据集1闭环采集路线的总长度为792 m,地图占用空间50.4 MB,共1 175个数据节点;②数据集2闭环采集路线的总长度为1 087 m,地图占用空间91.2 MB,共1 987个数据节点;③数据集3闭环采集路线3的总长度为1 697 m,地图占用空间168.3 MB,共3 077个数据节点。

图12 实验平台和数据集路线Fig.12 Experimental platform and data set route
2.1 多语义目标分割的实验
为充分验证多语义目标分割算法的准确性,在3个数据集上分别对地面、交通标志牌和杆状物的分割算法做实验验证。
2.1.1 地面语义分割
以改进的RANSAC算法[16]为对比算法,取每次拟合的最优模型为最终模型,由于地面在激光雷达下方,只需对垂直角度小于0°的点云作地面分割,本文算法和RANSAC效果对比见图13。
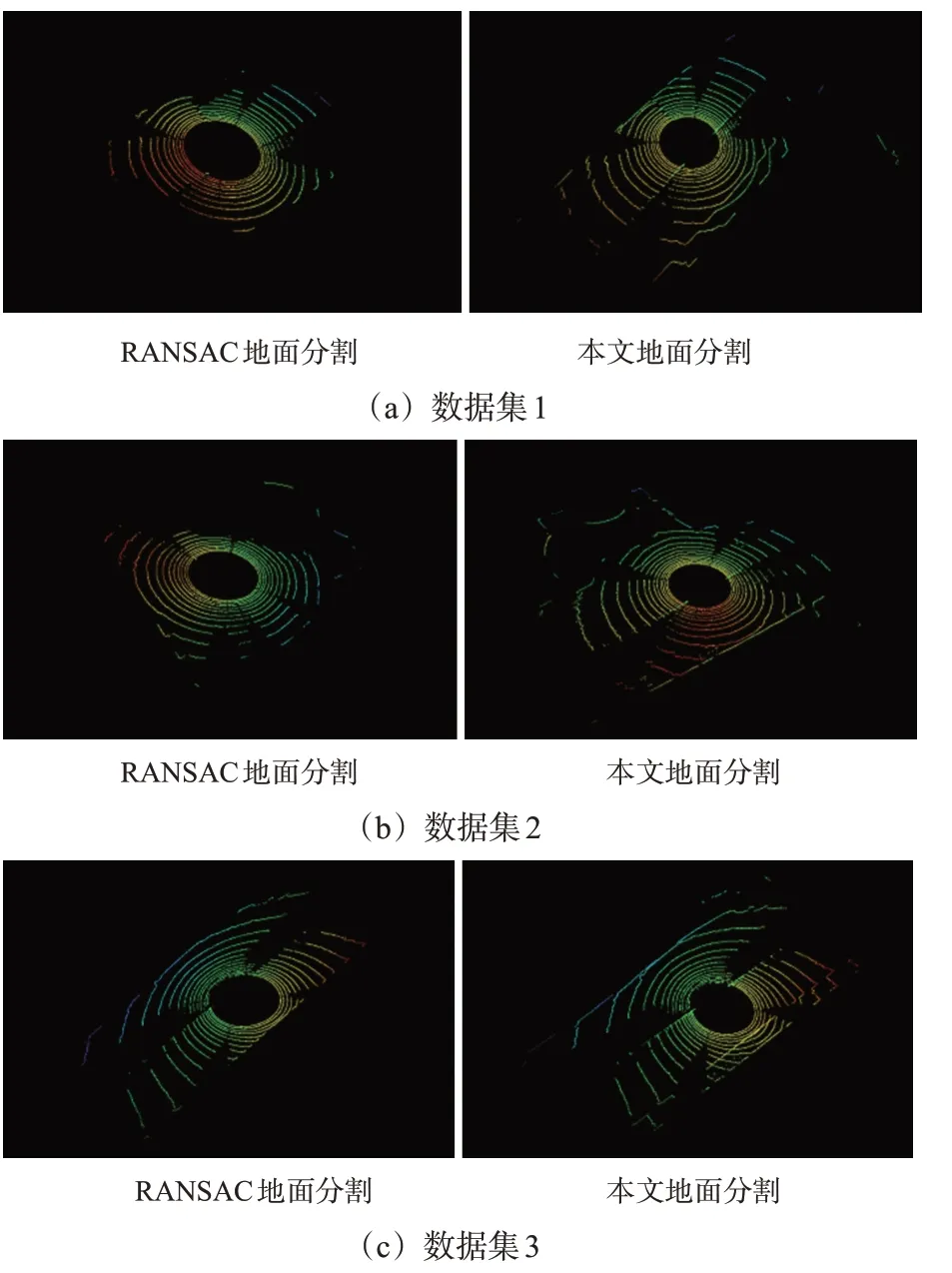
图13 节点的地面分割结果Fig.13 Ground segmentation result of a node
从结果可以看出,用RANSAC会出现欠分割等缺点,可能会使漏检的地面点影响后续语义目标的分割,而本文方法剔除地面充分,计算过程简单。
2.1.2 交通标志牌语义分割
通过人工标注的方式统计到数据集1,2,3中分别包含交通标志牌的个数为26,42,57,以构建真值系统,设立精确度(precision)和完整度(complete)这2个量化指标来评价交通标志牌的提取结果,计算见式(19)~(20)。
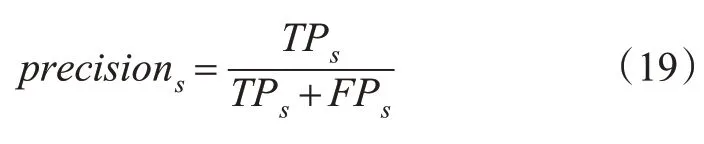

式中:TPs和FPs分别为检测出的正确交通标志牌数量、错误交通标志牌数量;FNs为没有检测出来的交通标志牌数量。对于某1块交通标志牌,在所有包含它的所有数据节点中,若交通标志牌都能被正确检测出,则TPs加1;若在某1个节点中其他物体被错误检测为交通标志牌,则FPs加1;若该交通标志牌在某1个节点中未能被成功检测出,则FNs加1。
算法实验效果见图14,以文献[17]所用的交通标志牌的检测分割算法作为实验对比的算法,对比实验结果见表1~3。
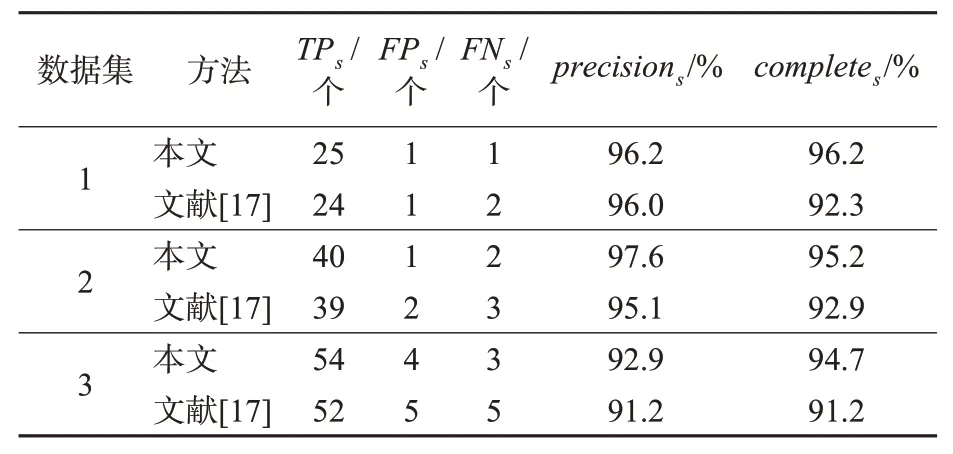
表1 数据集1~3交通标志牌语义分割对比Tab.1 Comparative experiment results of data set 1~3

图14 节点的交通标志牌分割结果Fig.14 Traffic-sign segmentation of a node
由表可知:本文方法在数据集1~3中的分割精确度分别为96.2%,97.6%,92.9%,完整度分别为96.2%,95.2%,94.7%,相较于文献[17]的方法,本文方法精确度分别提高了0.2%,2.5%,1.7%;完整度分别提高了3.9%,2.3%,3.5%。从整体实验结果来看,本文交通标志牌检测方法优于文献[17]的方法,分割效果更好。
2.1.3 杆状语义分割
通过人工标注的方式统计到数据集1~3中分别包含的杆状语义的个数为132,213,326,以此构建真值系统。同样,以2.1.2中的指标来评价杆状语义的提取结果,以下标p代表杆状语义。
实验效果见图15,以文献[18]所用的杆状物检测算法作为对比算法,最终的对比实验结果见表2。
由表2可知:本文方法在数据集1,2,3中的精确度分别为97.7%,97.6%,96.6%,完整度分别为96.2%,94.8%,96.2%,相比较于文献[18]方法,本文方法分割的精确度分别提高0.9%,1.7%,2.3%。完整度分别提高6.1%,7.0%,9.4%。从整体的实验结果来看,本文方法的精确度和完整度更高,更适用于道路场景的三维激光点云的杆状语义目标分割。
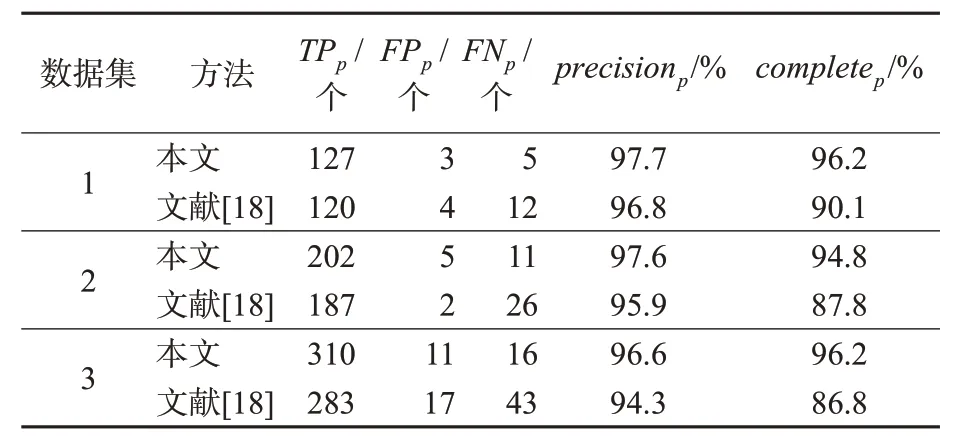
表2 数据集1~3杆状语义分割对比Tab.2 Comparative experiment results of data set 1~3
至此,所有语义目标分割结束,最终分割效果见图15。

图15 节点的杆状语义分割结果Fig.15 Pole-shaped object segmentation result of a node
2.2 点云语义地图表征
根据数据节点的位置序列,依次将数据集1~3分为奇数序列节点集和偶数序列节点集,其中奇数节点集和偶数节点集分别用于地图表征模型的构建和定位,数据集1~3分别包含的奇数序列数据节点个数分别为588,994,1 539,本文分别为3组数据集构建了3套语义表征模型,其表征模型的地图节点全局位置轨迹见图16。
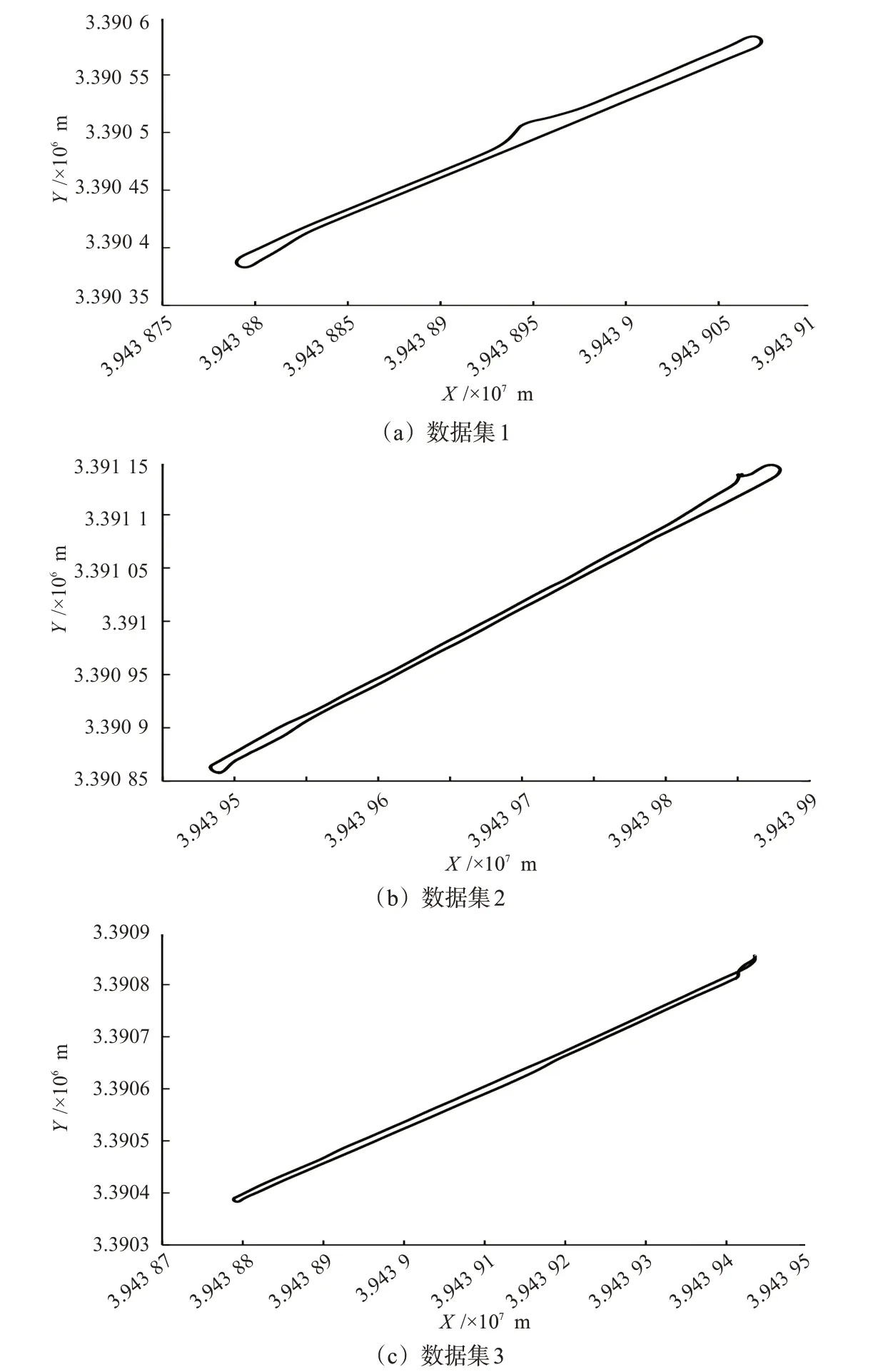
图16 地图节点全局位置轨迹Fig.16 Global positional trajectory of map nodes
2.3 基于地图表征模型的智能车定位
偶数序列节点集用于智能车定位,数据集1,2,3分别包含的偶数序列数据节点个数为587,993,1 538。在GPS粗定位时,将GPS转换成UTM坐标后计算待定位节点的UTM和地图模型中各节点UTM的欧式距离,由于普通GPS的定位误差约为10 m,因此将欧式距离小于5 m的所有节点作为粗定位结果,一般包含10个节点,得到的相邻节点间距约1 m。节点级定位时,从粗定位结果中选择语义编码匹配度最高的1个节点作为节点定位结果。本文以文献[19]中的方法作为定位的对比算法,最终得到了在数据集1~3中的定位对比实验结果,见表3。

表3 数据集1~3定位精度对比Tab.3 Comparative experiment results of data set 1~3
由表3可知:数据集1,2,3中本文定位算法准确率分别为98.5%,97.6%,97.8%;相较于文献[19],本文方法在以上3个数据集中准确率分别提高25.1%,30.2%,26.2%。
从实验结果可以看出,本文提出的基于3D点云语义地图表征的智能车定位方法的最近节点定位准确率高、鲁棒性强。
3 结束语
针对智能车定位时节点定位准确率低、地图存在动态物体等问题,本文提出了1种基于3D点云语义地图表征的智能车定位方法:①提出了3种鲁棒性强、精度高的语义分割算法:基于俯仰角评估的地面分割、基于反射强度和形状特性的交通标志牌分割、基于对象分析的杆状语义分割;②提出了新颖的智能车节点定位方法,该方法先后经过语义投影、生成带权有向图、生成语义路和构造语义编码等步骤,以语义信息表征场景信息,同时和全局位置共同表征语义地图的各地图节点,最终基于该语义模型实现了鲁棒性强、精度高的节点级定位。
此外,本文的研究工作也存在一些不足之处,如:①语义分割的目标种类不是很丰富,下一步考虑增加语义分割的目标种类;②在场景过于相似之处,本文得到的语义编码也会大致相同,下一步考虑优化编码方法,增强场景语义编码的独特性。
