基于方向条件的循环一致性生成对抗网络
2022-01-08李锡超
李锡超,李 念
(1.武汉邮电科学研究院,湖北武汉 430070;2.南京烽火天地通信发展有限公司,江苏 南京 210019)
生成对抗网络[1](Generative Adversarial Network,GAN)已延伸到图像、视频、自然语言[2]、语音[3]等领域。GAN 直接进行采样学习分布规律,使得生成数据可以逼近真实数据。由于GAN 生成数据没有针对性的指导和约束条件,因此原始GAN 生成的图像是随机的。条件生成对抗网络[4](Conditions GAN,CGAN)在原始GAN 的基础上加入了对生成器的约束条件,使得生成的数据变得可控。
图像翻译指在图像源域和目标域建立映射关系,在保留源域内容的情况下,将图像转换成目标图像的风格而不改变源域图像的内容。CGAN 解决了图像生成的约束问题,为后来的各种图像翻译网络提供了思路。配对的图像翻译网络Pix2pix[5]是一种基于CGAN 的有监督模型,利用配对数据集进行训练,使图像翻译的质量和稳定性都得到了大幅提升。循环一致性对抗生成网络[6](Cycle-Consistent GAN,CycleGAN)是基于机器翻译中对偶的思想[7],将非配对的训练数据用于图像翻译,取得了不错的效果,这很大程度上解决了图像翻译中配对数据获取困难的问题。但CycleGAN 存在收敛慢、参数量大的问题。
针对配对数据获取困难,且现有非配对方法训练缓慢、参数量大的问题,该文基于CycleGAN 中构建对偶任务的思想和CGAN 的条件约束思想,设计了新的基于方向条件非对称的生成网络和条件对偶任务,同时引入同一映射损失[8]用以约束图像内容,引入感知损失[9]保证图像主体细节在变换前后的稳定性。在与CycleGAN 的对比实验中,生成和重建图像质量以及训练速度都有所提升,采用了非对称设计的网络结构,使得网络参数大幅减少。
1 相关工作
1.1 对偶学习
对偶学习(Dual Learning)是一种半监督[10]的学习方式,它通过对称的两个学习任务互相反馈,可以从未标注的数据中学习。能够有效利用中间过程产生的伪标签,甚至在某种程度上可以把对偶学习看作是在把未标注的数据当作标签数据使用。因此对偶学习可以有效利用未标注的数据,使得对没有标注的数据进行训练成为可能。
对偶学习最初用于有效利用机器翻译中的单语数据,显著降低对平行双语数据的要求。CycleGAN 和DualGAN[11]将对偶学习应用到图像翻译领域。循环一致性的思想基于对偶,被应用于不同领域,如在视觉跟踪中加强前后一致性,在机器翻译中通过反向翻译验证结果并进行无监督机器翻译。
1.2 生成对抗网络
GAN 通过零和博弈的对抗过程来生成模型,在网络中同时训练两个模型:一个是用来捕获数据分布的生成模型,另一个是用来判别数据来自训练数据还是生成数据的判断模型。在竞争对抗过程中,生成模型不是为了训练得到与特定图像的最小距离,而是为了骗过判别模型,这使得模型能够以无监督的方式学习。
CGAN 扩展了GAN,使得生成对抗网络能够根据一些额外的条件信息(比如类别标签)来调整生成器和判别器,使得定向图像生成和图像转换成为可能。Pix2pix 基于CGAN 进行一系列改进,抛弃了传统算法[12]手工建模、需要大量专家知识和设计复杂的损失函数,提出了一个用于解决各类图像翻译问题的统一框架。
1.3 非配对的图像翻译方法
Pix2pix 要求数据必须是有标签的配对输入,现实碰到的数据更多是非配对、没有标签的,这使得非配对图像翻译没有办法开展。CycleGAN 基于对偶学习的思想,通过循环一致性损失和对偶网络保持图像结构的前后一致,实现了从非配对的图像中学习映射。
2 基于方向矩阵的循环一致性生成对抗网络
2.1 基于条件的对偶学习网络
CycleGAN 形成一组对偶学习关系需要两组相同且对称的生成器和判别器。结合CGAN 对于图像生成具有方向性和指导性的特性,文中提出基于方向向量的条件对偶学习结构,如图1 所示。
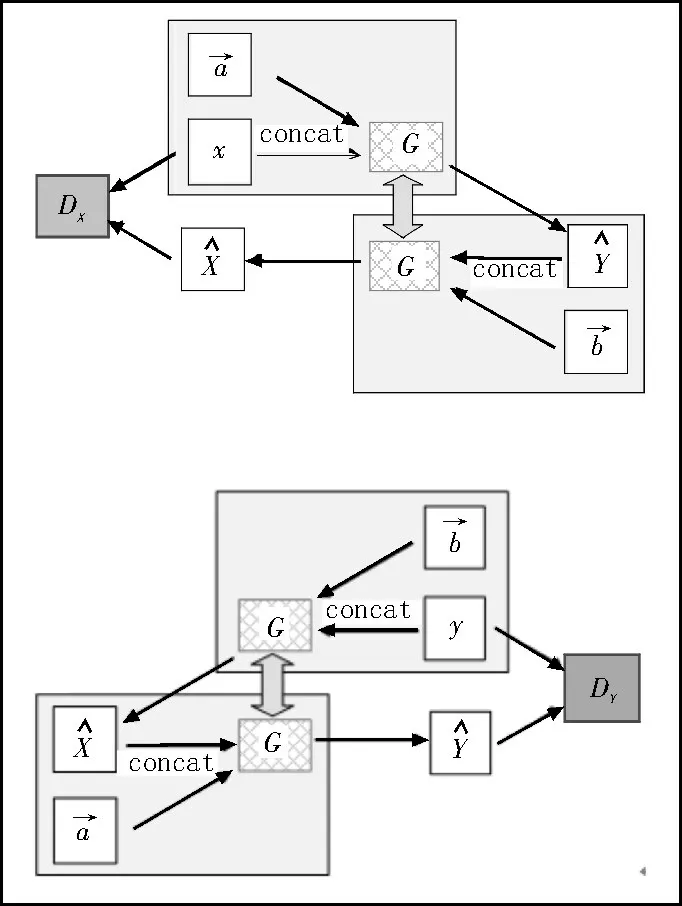
图1 基于方向条件的对偶学习任务
2.2 生成器网络结构
2.2.1 生成器结构
生成器主要结构如图2 所示,包括编码器、转换器、解码器。其中编码器用于提取源域图像的特征,转换器用于完成风格特征的转换,解码器用于生成转换之后的图像,使其具有源域的内容和目标域的风格。

图2 生成器主要结构
生成器网络使用了U 型结构,将ResNet[13]中跳层连接的残差结构改为更灵活的残差模块(Residule_block)。
改进的生成器结构如图3 所示。对于256×256分辨率的图像,编码器部分采用多层卷积层+实例正则化+ReLU 激活函数,获取源域图像特征编码;转换器部分使用9 个残差模块,特征层跳跃连接,可以较好地结合前一层的特征,完成图像风格从源域到目标域的翻译;解码器部分利用反卷积层从高维度特征向量中还原出低级特征,使生成图像的风格更接近目标域风格。

图3 基于方向条件的生成器结构
经过编码、转码和解码过程之后生成的图像在损失函数的约束下就可以在理论上完成图像风格从源域到目标域的迁移。
2.2.2 实例正则化
图像翻译中的生成结果主要依赖于某个图像实例,而一般的批量正则化(Batch Normalization)则是对每个批次的图像进行标准化,更注重数据分布的一致,所以批量正则化不适合图像翻译中对生成图像进行标准化。在图像翻译中使用实例正则化(Instance Normalization)不仅可以加快模型收敛速度,而且可以使每个图像实例保持相互独立。因此,在生成网络的标准化过程中该文采用了实例正则化。
2.3 判别器网络
判别器的网络结构如图4 所示。它用来区分输入的样本来自真实数据还是生成器生成的数据,其判别作用会激励生成器生成更加接近目标域的数据。在具体结构设计上,卷积网络的输出特征参考PatchGAN[6]结构,源域图像经过5 次卷积和实例正则化,最终得到一个32×32×1 的输出特征向量,而不是将一维输出作为分类依据。特征向量的每一个维度,代表源域图像中的一个感受野,保证了生成图像和源域图像的语义相似性。
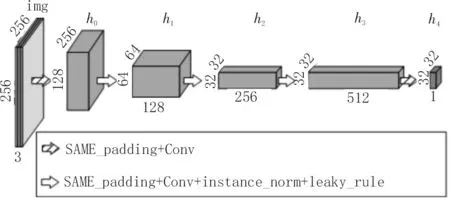
图4 判别器的网络结构
2.4 循环一致性对抗网络
2.4.1 对抗损失
GAN 一般由生成模型和判别模型组成,生成模型的目的是学习数据的分布规律,生成逼近真实数据的图像;判别模型尽可能区分给定的图像是否来自真实数据。在不断地对抗训练中,两个模型的能力都会变强,最终达到稳态平衡。在原始GAN 中,需要优化的目标函数如式(1)所示:
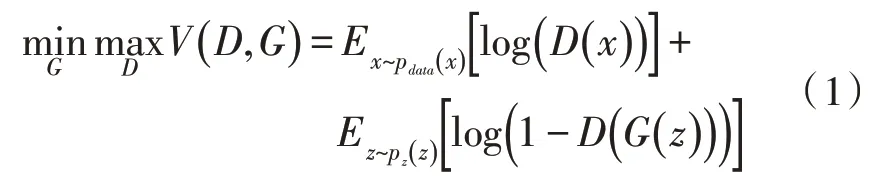
为学习数据pdata(x),定义了一个先验输入噪声变量pz(z),然后将数据空间映射表示为G(z),其中G为生成模型。定义了判别模型D,其中D(x)表示x来自真实数据而不是由生成模型生成的数据的概率。
在这个目标函数中,先优化D再优化G,拆解之后如下:
1)优化判别模型D,目标函数表示如式(2)所示:
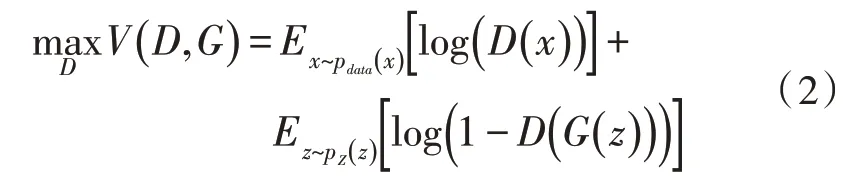
优化判别模型D时与生成模型无关。根据函数变化规律,在优化过程中,上式第一项中的x来自真实样本的判别结果的概率D(x)越接近于1 越好;对于来自生成模型从噪声z中生成的假样本G(z),需要使优化的判别结果D(G(z))越接近于0 越好。
2)优化生成模型G,目标函数表示如式(3)所示:
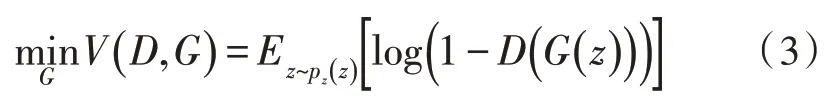
优化生成模型时,与真实样本x无关。这时只有来自噪声z生成的假样本G(z),生成器的优化目标是使假样本G(z)的判别结果的概率D(G(z))越接近于1 越好。如此,为了使总的优化目标的损失函数表达一致,故表示为1-D(G(z))的形式,这样就成了开始表示形式的目标函数了。
对于x→y映射的对抗损失函数如式(4)所示:
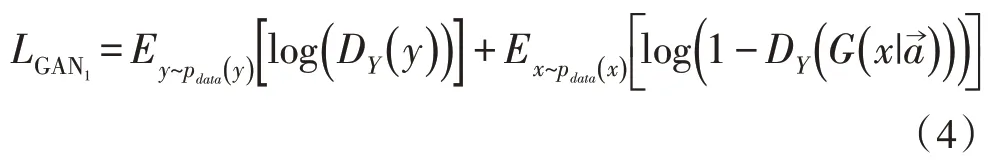
对于y→x映射的对抗损失函数如式(5)所示:
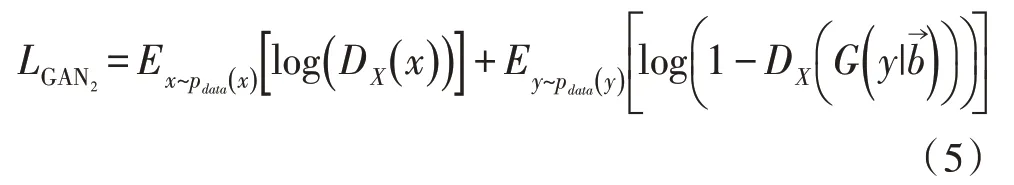
2.4.2 循环一致性损失
对抗训练能够从理论上学习到生成器G的映射,产生与目标域相同分布的输出。但在非配对数据训练中,当网络容量足够大的时候,会将相同的图像映射到目标域中任意随机的图像上,其中任何一个学习都可以产生与目标分布匹配的输出。因此,仅使用对抗损失,不能保证学习的函数能将单个的输入xi映射到期望的输出yi。为了进一步减少可能的映射空间,映射函数必须是循环一致的。对于源域X中的每一张图像x,图像经过循环转换网络之后,可以还原出源域图像x。将称为循环一致性。同样的,有。因此定义了循环一致性损失,如式(6)所示:
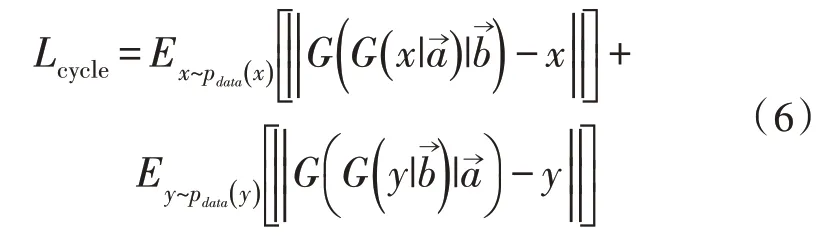
循环一致性损失能够保证输入和生成的输出为一对一的映射关系。
重建的图像与输入的图像匹配的映射关系如图5 所示。

图5 重建图像与输入图像的映射关系
2.4.3 同一映射损失和感知损失
由于不同数据集上对于图像翻译的要求不同,仅依赖对抗损失和循环一致损失,不足以满足图像翻译的要求,因此加入同一映射损失用以约束在原图上的改动。对于生成器定义如式(7)所示:
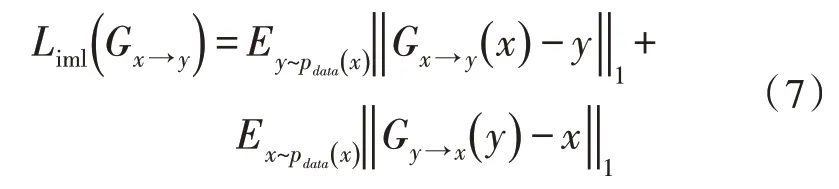
文献[8]利用感知损失来增强图像细节,故引入感知损失Lpl,使生成的图像在映射出目标域风格的同时保留细节,不产生模糊。感知损失定义如式(8)所示:
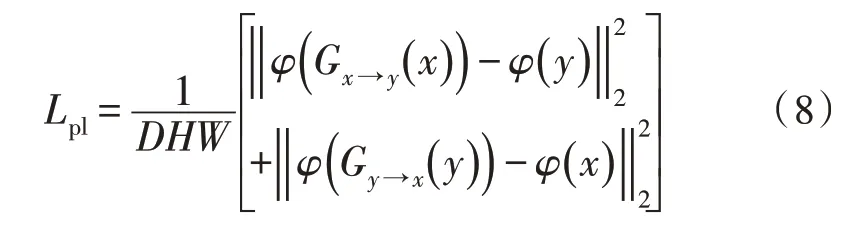
其中,φ为特征提取函数,一般使用VGG16或者VGG19 来提取。D、W和H分别表示特征的深度、宽度和高度。文中使用了VGG16 预训练模型的深度特征向量计算感知损失,各部分系数比例如式(9)所示:

这样整个网络的损失函数如式(10)所示:
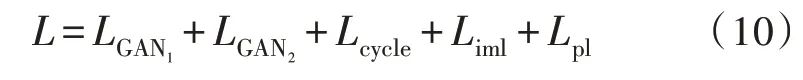
3 实验结果与分析
3.1 实验数据集和实验设置
为验证改进网络能否在非配对数据上完成图像翻译的任务,以及为对比改进网络与基准CycleGAN网络的性能,选择相同数据集分别进行300 次迭代训练。
这里使用的人像风格数据为Face2Sketch(以下简称F2S),数据集样本如图6 所示。为了构造逼真的人脸数据集,通过混合网络爬虫获取的证件照,基于StyleGAN[14]生成脱敏数据,并进行对齐和使用PortraitNet[15]去除背景(如图6 第1 行)。非配对的黑白人像风格数据由APDrawingGAN[16]生成(如图6 第2 行)。形成的训练数据包含2 000 张彩色脱敏证件图片和2 000 张非配对关系的人像风格图片。

图6 实验数据集样本数据
3.2 实验结果
分别用CycleGAN、该文方法但仅使用对抗损失+循环一致性损失(以下简称该文方法(1))、该文改进的方法结合感知损失和同一损失并对参数进行调整(以下简称该文方法(2)),进行图像翻译和重建实验,实验结果如图7 所示。其中,第一行为分别用3 种方法进行图像翻译生成的实验结果;第三行为由生成图像进行重建的结果。

图7 图像翻译与重建结果比较
从实验结果对比可以发现,在同样的实验条件下,采用CycleGAN 和该文方法(1)的细节表现较差(生成人像眼睛模糊、背景颜色失真)。该文方法(2)可以更好地完成从源域到目标风格域的转换,同时能够在重建源域时生成相似度更高、图像质量更高的重建结果。
为了量化具体的提升,在相同实验条件下,进行了300 次迭代。使用SSIM(结构相似性)和PSNR(图像信噪比)图像质量指标进行评价。比较结果如表1所示,其中a→b 为翻译生成结果,b→a 为重建结果。
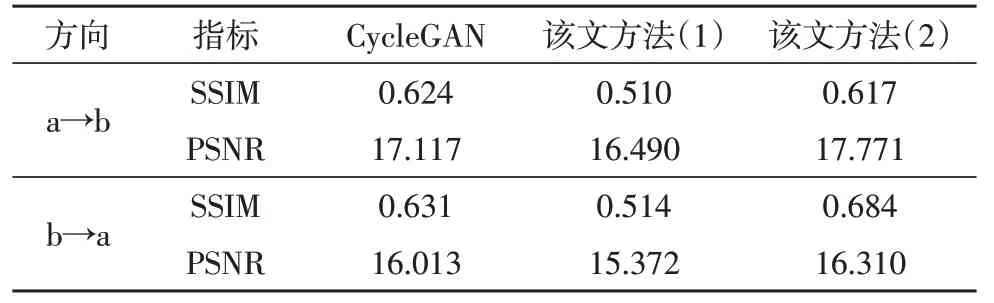
表1 实验结果质量评估
该文改进网络对比CycleGAN,3 种方法的生成损失收敛对比如图8 所示,该文方法(2)下降速度更快,最终平稳值更小,表明对应网络的方法速度越快生成质量越好。
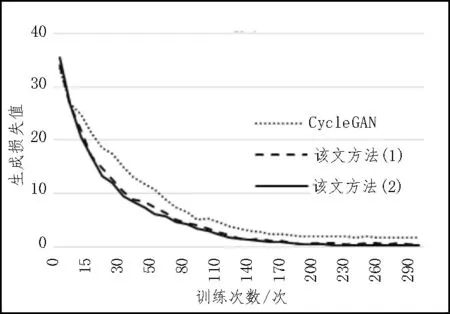
图8 3种方法的生成损失收敛对比
文中所提方法在进行图像翻译时,与CycleGAN方法相比,在Inception Score 获得更高得分。同样进行300 次迭代,计算衡量图像清晰度的Inception Score 结果,该文方法(1)可以在F2S 数据上获得更高的得分。并且由于设计了非对称结构的生成器,可以在不同方向条件下共享网络参数,因此网路参数由CycleGAN 的约112 M 减少为约74 M,参数量下降34%。3 种方法的Inception Score 和网络参数量对比如表2 所示。

表2 Inception Score和参数量对比
4 结论
该文研究了图像翻译的发展,针对现有非配对图像翻译方法CycleGAN 进行改进,在图像生成的编码和解码过程中使用基于方向条件的方法代替原有的循环对偶网络,减少了36%的参数量,降低了计算量;设计了共享参数的非对称生成器,通过添加感知损失和同一性损失,提高了图像生成质量,获得了更加相似的重建结果。实验表明,所提网络能够加快生成器的训练速度,获得了更小的稳定收敛,图像翻译结果保留更多的细节,重建结果与源域图像具有更高的相似度。和CycleGAN 相比,文中提出的改进网络在相同数据集上的表现更好,在SSIM、PSNR 和Inception Score 上获得了更好的评估参数,观察结果表明,也获得了更好的图像质量。
