基于Revit二次开发的BIM+WebGIS融合应用研究
2022-01-07胡夏恺陈俊涛杨聃朱悦林
胡夏恺,陈俊涛,杨聃,朱悦林
(1. 武汉大学水资源与水电工程科学国家重点实验室,湖北武汉,430072;2. 武汉大学水工岩石力学教育部重点实验室,湖北武汉,430072;3. 国网浙江省电力有限公司紧水滩水力发电厂,浙江丽水,323000)
建筑信息模型(building information modeling,BIM)已被广泛应用于建筑领域。近年来,随着HTML5和WebGL等互联网技术的快速发展,BIM与地理信息系统(geographic information system,GIS)的跨界融合成为新的趋势,高精度的BIM 模型已经成为3D WebGIS中重要的数据来源之一[1]。
BIM 是基于建筑、工程项目而开发的全生命周期管理工具,描述的是建筑内部的微观信息;GIS服务于地理空间行业,描述的是大尺度的宏观环境[2]。BIM 有助于扩大地理信息系统的作用范围,使其向建筑内部发展,GIS可用于管理BIM无法处理的环境数据,两者相辅相成。BIM与GIS的技术融合有效地促进了学科交叉发展,是城市精细化、智慧化管理的基础[3]。吴敦等[4]基于BIM 和GIS技术提出城市轨道交通的信息全生命周期管理系统;潘飞等[5]针对基于3D WebGIS的土木水利工程BIM集成和管理进行了研究;纪蓉等[6]开发了基于BIM+GIS的智慧管廊监测管控运维一体化平台,实现了环境监测管理、安防监控管理、资产与运维管理、大数据统计分析等功能。然而,BIM+WebGIS技术在实际应用过程中还存在以下问题。
1) BIM 和GIS 所处的行业和服务对象不同,导致二者的模型存在差异。例如,在空间特征方面,BIM模型采用局部坐标系,GIS模型采用地球坐标系;在模型信息方面,BIM 模型除了几何和外观信息外,还包含了大量的语义信息。因此,BIM模型无法直接接入WebGIS平台,需要进行模型转换,同时保存BIM模型中的语义信息。
2) WebGIS 采用的WebGL 技术在浏览器端通过本地客户端显卡、内存资源进行图形渲染时,受到网络宽带和服务器性能的限制,高精度、大体量的模型在网络传输与渲染方面的效率低,影响了用户的使用体验。
一些商业软件(如FME 和IFCExplorer 等)中嵌入了能将BIM数据转换为GIS数据的工具[7],但仅限于较低细节层次的模型转换,对于多层次细节(level of details, LOD)对应的划分关系模糊,且与语义信息的耦合程度不高;汤圣君等[8−9]提出将IFC标准数据模型向CityGML 格式转换的方案,并通过语义映射使BIM模型在GIS平台中得到了应用,但CityGML 在网络传输时存在标签冗余、浏览器解析渲染过程复杂等问题;徐敬海等[10−11]提出了将IFC 数据转换为3D Tiles 格式的方案,并实现了语义信息的重现,但在格式转换过程中需要借助OBJ格式作为中介,而且由于该方案缺少对BIM 模型体量的优化处理、空间数据索引结构的设计以及层次细节划分,在模型的加载和渲染方面存在不足。
针对上述问题,本文以BIM 模型的数据转换和空间数据的动态调度为研究内容,提出一种基于Revit 二次开发的解决方案,以期在实现数据转换的同时加快模型的传输速度,提高渲染效率,推进BIM与WebGIS融合应用的深入发展。
1 研究工具
本文以Revit 建立的BIM 模型为源模型数据,将3D Tiles 作为目标数据格式,通过Revit 二次开发工具自行设计和开发数据转换接口,在无需IFC和OBJ 等中间格式的情况下实现模型数据格式的转换。下面对Revit 二次开发工具和3D Tiles 数据格式进行简要介绍。
1.1 Revit 二次开发
Revit 具有完整的应用程序编程接口(application program interface,API),开发人员可以通过API 对Revit 的功能进行扩展。Revit API 可用VisualBasic.NET、C#以及C++/CLI 等任何与.NET兼容的编程语言进行编程。本文使用C#语言在Visual Studio平台下对Revit进行功能扩展。
Revit 提供2 种方式来扩展其功能:1)创建外部命令(IExternal Command),这种方式使用时必须在外部命令中继承IExternalCommand 接口,并重载接口内的抽象函数Execute 来实现接口功能。2)添加外部应用(IExternal Application),这种方式需要在外部应用中继承IExternalApplication 接口,并重新加载其中2 个抽象函数即OnShutup 和OnShutdown 的编译代码来实现程序的开发[12]。本文通过调用外部命令的方式进行模型轻量化的二次开发,在Visual Studio 平台使用C#编程生成动态链接库(dll)文件后,通过Autodesk 公司提供的AddinManager插件加载dll文件实现对Revit的功能扩展。
1.2 3D Tiles数据格式
3D Tiles 是一种开放式数据规范[13],是在图形语言交换格式(GL transmission format,glTF)基础上结合空间数据结构和层次结构细节级别(HLOD)后得到的数据格式。3D Tiles将三维数据以分块、分层的形式进行组织,减轻了浏览器和CPU的负担,从而实现了大量地理3D数据的流式传输和海量渲染,成为WebGL框架下Cesium[14]平台的专用格式。3D Tiles 数据集(TileSet)是由一系列瓦片(tile)组成的树状结构,其数据格式及组成如图1所示。
图1 中,asset 定义了3D Tiles 的版本号;properties 包含了模型中的功能属性;geometricError是一个非负数,用于计算屏幕空间误差,决定该TileSet是否被渲染;root存储着真正的瓦片(Tile)数据。Tile 中包括:1)boundingVolume,为Tile 的最小包围体;2) geometricError,为一个非负数,决定该Tile 是否被渲染;3)refine,定义了Tile 的切换方式;4) content,指向真正的渲染数据,数据类型分为批量三维模型(b3dm)、实例三维模型(i3dm)、点云模型(pnts)以及复合模型(cmpt),其中b3dm 和i3dm 是数据格式转换中常用的2 种数据类型;5)children,存储了当前节点的所有子节点信息。

图1 3D Tiles文件结构Fig.1 3D Tiles file structure
1.3 glTF数据格式
glTF 是一种3D 图形数据格式标准[15],其组成如图2所示。

图2 glTF文件结构Fig.2 glTF file structure
在glTF 数据格式中,采取文本(JSON)与二进制块(bin)相结合的方式进行数据存储。对于内存较小的数据,选择JSON格式,其结构紧凑且易于解析;对于几何信息、动画等大型数据,则采用bin格式以减小文件内存。由于JSON和bin的数据结构都与WebGL 接口一致,无需解析和处理,这种数据格式非常适用于3D内容在Web端的加载和渲染。
2 研究框架
本文设计的程序框架主要由模型轻量化处理、数据格式转换以及数据动态调度组成,如图3所示。

图3 程序框架Fig.3 Program framework
首先将轻量化处理后的BIM 模型进行数据转换,将几何与外观信息存储为glTF 文件,将对应的语义信息存入JSON 文本,并在此基础上构建b3dm类型的三维瓦片;然后,在不同LOD瓦片基础上设计自适应八叉树空间索引结构,实现层次结构细节的划分;最后,通过添加视锥体剔除算法实现数据的动态调度,并将其转换为3D Tiles目标格式。
2.1 模型轻量化处理
模型轻量化处理是指在不损失模型真实性的前提下,通过算法减少模型体量,其中几何信息是模型信息的重要组成部分,决定模型文件占据的内存空间,对模型的几何信息进行简化,可以极大程度地缩减模型体量,加快模型的传输速度。因此,本文将从模型中存在的大量重复构件以及构成几何实体的网格信息两个方面入手,进行模型的轻量化操作,主要内容包括:模型重构、重复构件简化以及网格信息简化。
2.1.1 模型重构
BIM 模型由大量的建筑、结构及装饰构件组成,将模型作为整体进行格式转换会导致构件细节信息的丢失,因此需要将模型进行拆分。Revit中提供了一种“族”的分类概念[16],族代表了属性设置相同而数值可能不同的一类图元的集合,如图4所示。但这样的分类方法忽略了构件几何参数的差异,考虑到后续过程中重复构件简化的需要,本文在族的基础上,自行设定并添加了一个形状分类参数,借此完成更细层次的模型重构,流程如图5所示。

图4 “族”示意图Fig.4 Family diagram
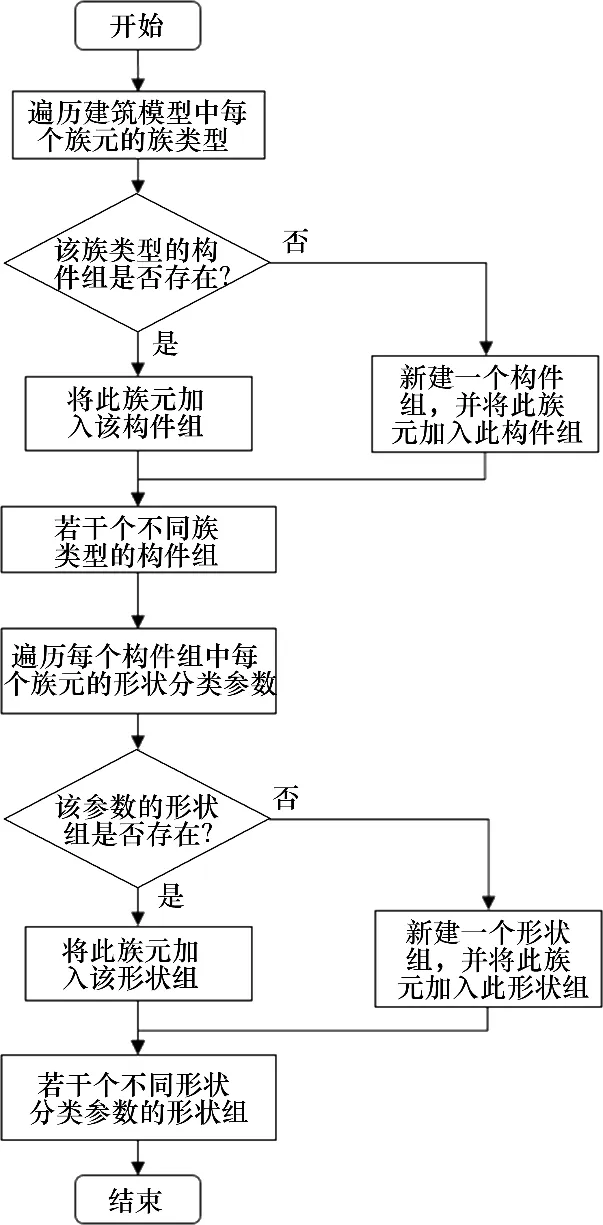
图5 模型重构流程图Fig.5 Flow chart of model reconstruction
在模型重构的过程中,首先对模型中的所有构件进行遍历,根据其族类型进行第1次分组;然后对每个组内的族实例再次进行遍历,根据其形状分类参数进行第2次分组。这样就将整体模型拆分成了若干个几何和语义信息完全相同且仅有所处空间位置不同的构件组。
2.1.2 重复构件简化
完成模型重构后,每个构件组内的族实例具有相同的几何和语义信息,仅所处的空间位置不同。若对这些族实例的数据分别进行存储,则会造成存储空间的浪费。因此,在每个构件组中选取1个参照例,导出其网格信息(mesh)并记录位置(x0,y0,z0),组内其他族实例则引用参照例的网格信息,并根据自身的形心位置(x1,y1,z1)和旋转矩阵T3×3计算其与参照例之间的空间关系。重复构件简化的流程如图6所示。

图6 重复构件简化流程Fig.6 Simplified flow chart of repeated components
在glTF中,平移通过一个行向量表示:
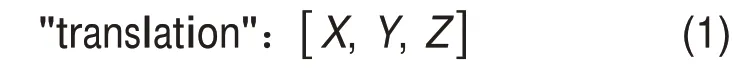
其中,X=x1-x0,表示X轴方向的位移;Y=y1-y0,表示Y轴方向的位移;Z=z1-z0,表示Z轴方向的位移。
旋转通过四元数表示:

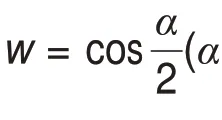
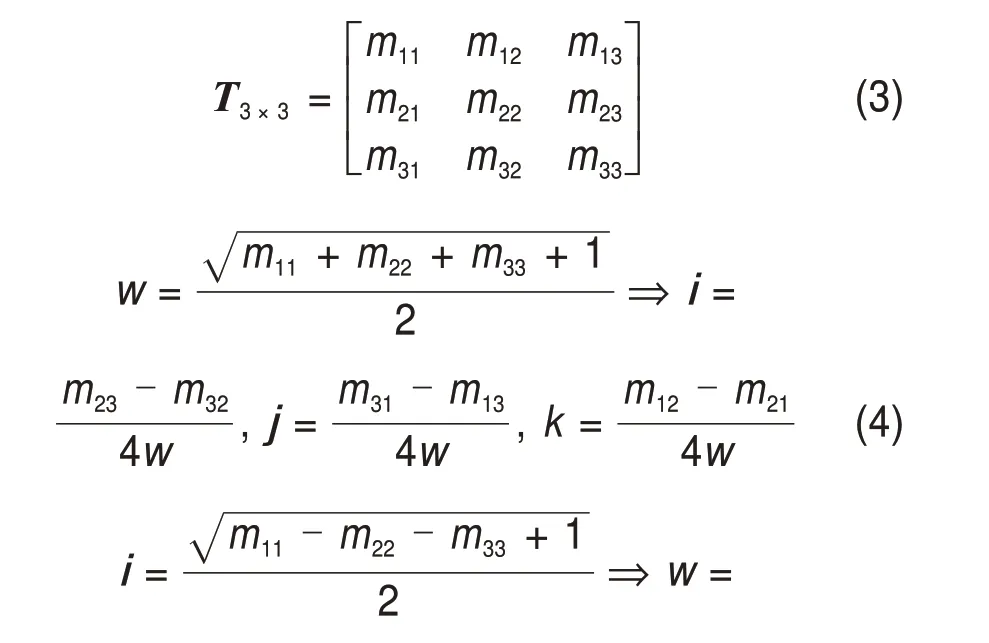

2.1.3 网格信息简化
模型的几何信息存储在三角面片网格(mesh)中,复杂的BIM 模型往往需要百万级的三角网格刻画模型特征,如此庞大的数据量对于模型在Web端的传输和渲染都是巨大的挑战。因此,本文使用Revit API提供的基于二次误差测度的Garland边折叠算法[17]对三角面片网格进行简化。
定义顶点v=[vx vy vz1]T折叠到新顶点-v的误差Δ(v)为

式中:p=[a b c d]T,其中,ax+by+cz+d=0,且有a2+b2+c2= 1;Kp为p的基本误差;Pv为与v相关联的平面的集合。


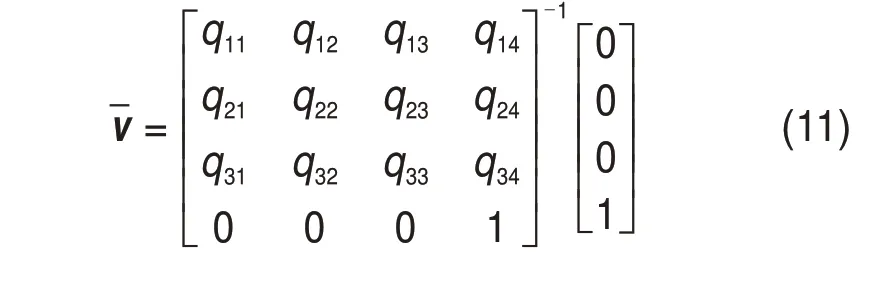
式中:Qep1和Qep2分别为vep1和vep2的二次误差测度矩阵。

边折叠算法简化后的模型网格分布均匀,同时可根据需要决定模型的细节层次,得到不同精细程度的模型,如图7所示。

图7 网格信息简化效果Fig.7 Simplified rendering of grid information
2.2 文件格式转换
为实现BIM 模型到3D Tiles 目标格式的转换,需要制作b3dm瓦片文件,其数据结构如图8所示。
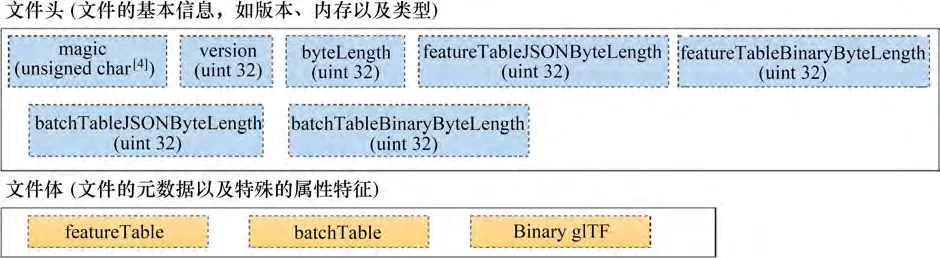
图8 b3dm数据结构Fig.8 Data structure of b3dm
b3dm 文件由文件头和文件体构成,文件头(header)记录了文件类型、版本、内存等信息,文件体(body)包括特征表(featureTable)、批量表(batchTable)以及二进制glTF,它们分别记录了文件中的模型个数、语义信息以及几何数据。其中文件体的构建是核心部分,主要包括数据向glTF格式的转换以及语义映射。
2.2.1 glTF格式转换
glTF 由JSON 文本、bin 文件以及纹理贴图PNG 或JPG 文件3 个部分组成,其中JSON 文本是glTF 的关键,相当于检索目录,WebGL 通过搜索文本中的属性字段,可以读取相应的内容或数据存储的位置信息,其基础结构如图9所示。
图9 JSON文本结构Fig.9 JSON text structure
在转换过程中,首先组织JSON 文本,由于glTF 坐标系和Revit 坐标系以及3D Tiles 所使用的WGS84地球坐标系存在差异(如图10所示),因此,需要在节点(root)中添加一个用于坐标系变换的矩阵,先将glTF中的坐标系沿X轴正向旋转90°,再将其转换为WGS84坐标系。转换矩阵可由式(13)~(18)得到:

图10 坐标系对比Fig.10 Comparison of coordinate systems


式中:(xO,yO,zO)为模型局部坐标系原点在WGS-84 坐标系中的位置,由模型设置所处的经纬度决定;RX,RY和RZ分别为坐标轴X,Y,Z对应的自旋矩阵;θX,θY和θZ分别为旋转矢量与坐标轴X,Y,Z之间的夹角。
在完成坐标系转换之后,依次在mesh(网格)中定义重现模型所需的属性及其访问顺序,如顶点坐标、法线向量、索引、材质等;在accessor(访问器)中定义数据类型、数量以及所在的缓存块;在bufferView(缓存块)中定义数据在缓存中的字节偏移量、字节长度等;在buffer(缓存)中定义二进制(bin)文件路径以及文件的字节长度;在material(材质)中定义材质的颜色和透明度;在texture(纹理)中定义sampler(采样器)和source(图片资源),并在image(图像)中定义材质贴图的路径信息。
JSON 文本组织完成后,按照网格(mesh)中定义的属性及访问顺序将对应的模型数据导出到定义的二进制(bin)文件中,将材质贴图导出到定义的贴图路径,从而完成了几何、外观数据到glTF的转换。
2.2.2 语义映射
为了构建完整的三维瓦片b3dm,需要将得到的glTF 文件二进制化,写入b3dm 文件的Binary glTF 数据块中,并将导出的存储模型的数量和语义信息以JSON 文本的形式分别写入文件的featureTable与batchTable数据块中。同时,为实现语义信息与模型实体的映射,需要在glTF 的mesh模块中添加“_BATCHID”属性,指定其在accessor中的访问顺序;在属性设定上,保证其数量和数据类型分别与顶点坐标的数量和数据索引的数据类型相同,从而可通过交互操作查看模型对应的语义信息。
2.3 数据动态调度
高精度的海量三维模型在网络端的传输和渲染效率受网络宽带以及服务器的存储、显示等性能限制。LOD 技术是场景中流畅加载海量数据的有效解决方案,尤其是动态LOD 技术,其可以在实时绘制的同时动态调取所需的瓦片数据,且在各个层级细节间的变化尺度合适,实现了模型的平滑过渡,但缺点是计算量大且复杂,在对海量数据进行调度时渲染效率较低[18]。因此,本文设计了自适应的八叉树空间索引结构,结合轻量化处理后得到的不同LOD 的三维瓦片,实现层次结构细节级别的划分,并在此基础上添加视锥体剔除算法,减少动态渲染过程中的瓦片数量,从而降低数据冗余度、减少内存浪费,提高运行效率。
2.3.1 自适应八叉树索引结构
在动态地理信息应用场合,人们常采用LOD和四叉树结构进行大规模的地图模型调度,但BIM 模型不同于三维地理模型,其模型构件之间的位置关系更加复杂,仅仅使用二维的四叉树算法无法很好解决三维立体空间的模型问题[19]。传统的四叉树与八叉树空间索引结构如图11所示。
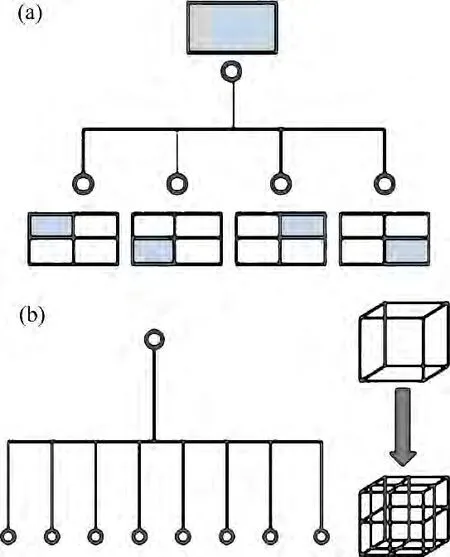
图11 四叉树与八叉树索引结构示意图Fig.11 Schematic diagrams of quadtree and octree structure
本文采用八叉树结构作为空间索引结构的基础,为了避免模型被子空间边界所分割,设计边界可变的自适应八叉树结构,算法如下。
1)初始化根节点。获取场景中包含所有模型在内的最小包围体(取为六面体包围盒,其3 个边与Revit中坐标系的3个坐标轴分别平行),并导出LOD1模型与之一起构成根节点的三维瓦片。
2)划分子空间并调整边界。首先,将上一节点的包围体划分为8 个体积相同的子包围体,然后,分别查看其中的模型是否被边界切割。若存在切割,则将该子包围体的边界向外延伸至完全涵盖其中的模型;若不存在切割,则将该子包围体向内收缩至刚好涵盖其中的模型,这样既保证了包围体内模型的完整性,又减少了空白空间占据的内存容量,同时允许包围盒之间出现交叉和重叠,使用起来更加灵活方便。最后,调整边界后,将各子包围体内的模型根据上一节点模型的LOD等级加一后导出,生成该节点的三维瓦片。
3)判断当前节点层次。设置判定条件:若包围体内的模型构件数量小于预定义的最小包纳容量或者模型LOD等级为5,则为叶节点,结束整个流程;否则,继续划分包围体。
4)待所有的叶节点及其三维瓦片导出,即完成了整个自适应八叉树索引结构的构建。
2.3.2 视锥体剔除算法
通过自适应的八叉树索引结构,可以实现不同层次结构下不同LOD 模型的快速加载。在此基础上,添加视锥体剔除算法来控制相机视点及视角的变化,并根据节点三维瓦片的位置与几何误差来确定是否将其加入渲染的序列,从而进一步提高场景渲染的效率[20]。其算法设计原理如下。
视锥体剔除算法是指剔除不在视锥作用范围内的模型,即不加载边界体与视锥之间没有交集的瓦片数据,如图12所示。
图12 中,O1为瓦片包围体盒的中心,(xT,yT)为点O1的坐标,RT为包围体的近似半径(六面体为体对角线的一半),θ为视锥体的角度,H为视锥体边界与O1点的最短距离,可由式(19)推出。

图12 视锥体剔除示意图Fig.12 Diagram of view frustum culling
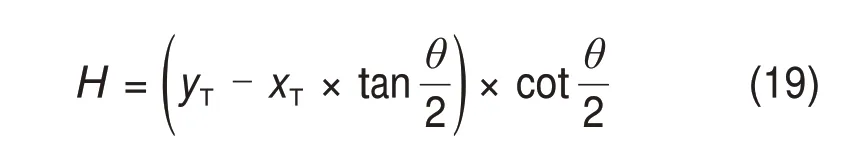
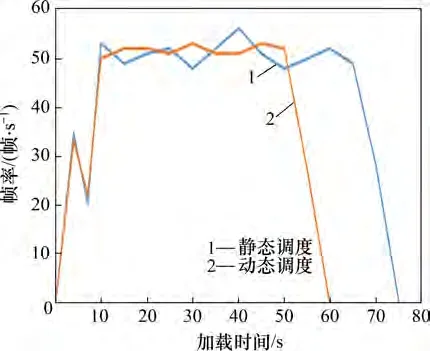
将H与RT进行比较,若H 对处于视锥体之内的模型,根据其距离相机视点的位置决定加载的三维瓦片的分辨率,距离视点越近,需要的瓦片分辨率越高,即模型的LOD 等级越高;距离视点越远,需要的瓦片分辨率越低,即模型的LOD 等级越低。在运行时,通过瓦片的几何误差计算屏幕空间误差,如图13所示。 图13 屏幕空间误差示意图Fig.13 Diagram of screen space error 图13中,r为几何误差,d为视点到远截面AE的距离,h为屏幕高度,e为屏幕空间误差。e和r的几何关系如下: 由式(20)可求得屏幕空间误差e。将e与设定阈值ε相比较,若e>ε,则加载下一级的瓦片替换当前的瓦片;否则,保留当前的瓦片。 本文以浙江省某特高压变电站为例,验证本文提出的BIM+WebGIS 融合应用方案的可行性。首先通过Revit建立BIM模型,如图14所示。模型构件如表1所示。 图14 变电站BIM模型Fig.14 Substation BIM model 表1 模型构件Table 1 Model components 通过外部命令调用程序接口,首先对模型进行轻量化处理,将模型几何、语义信息分别存储为glTF 与JSON 文本格式,得到的glTF 模型可使用3D 查看器或通过Web 端使用Cesium 进行查看,不同LOD模型的局部细节如图15所示,模型体积对比如表2所示。 表2 模型体积对比Table 2 Model volume comparison 图15 不同LOD模型局部细节Fig.15 glTF model with different LOD 从图15 及表2 可以看出,轻量化处理在保留模型几何与材质特征的同时产生了较好的简化效果,尤其是模型体量缩减明显,这有助于加快其在网络端的传输速度。 在此基础上将glTF与JSON文本结合,通过添加语义映射完成b3dm三维瓦片的构建,并可通过点击模型查询模型语义信息(如图16 所示),实现BIM模型向WebGIS模型的转换,同时保留、重现BIM模型中的关键语义信息。 图16 模型信息查询Fig.16 Query of model information 在完成三维瓦片构建的基础上,结合自适应八叉树结构、HLOD与视锥体剔除算法,动态调度瓦片数据,并将其与静态调度的加载、渲染效率进行对比,对比结果如图17所示。 图17 模型加载效率对比Fig.17 Comparison of model loading efficiency 从图17 可以看出动态调度下的模型在加载时稳定性更高,所需加载时间也更短;若是在模型数据量更加庞大或者服务器性能并不理想的情况下,则在加载稳定性和所需时间上的差距会进一步扩大,因此,动态调度可以有效提高数据的加载及渲染效率。 1) 通过Revit API 设计转换接口,无需借助IFC和OBJ等格式作为中间转换格式,即可实现从BIM模型到WebGIS模型(3D Tiles数据格式)的直接转换。 2) 针对BIM 模型复杂度高、体量大的特点,提出了基于去除重复构件和简化网格信息的轻量化处理方案。 3)设计了自适应的八叉树索引结构,并结合HLOD和视锥体剔除算法实现对海量模型数据的动态调度,提高了模型的加载和渲染效率,减少了内存。 4)实例验证表明本文所提方案中的3D Tiles模型可以通过Cesium 直接加载使用,同时可以查询模型的语义属性信息;另外,轻量化处理大幅缩减了模型体量,加快了其在网络端的传输速度;动态调度有效地提高了模型的渲染效率,减轻了服务器的负担,成功实现了BIM与WebGIS的融合应用。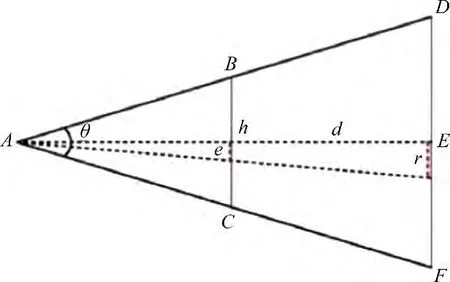

3 实例验证





4 结论
