半监督学习在语义分割算法中的应用
2022-01-07赵汉家于莲芝
赵汉家,于莲芝
(上海理工大学光电信息与计算机工程学院,上海 200093)
0 引言
语义分割是四大基本计算机视觉任务(分类、定位、检测、分割)之一,其目标是预测每个像素的语义标签。过去几年语义分割研究取得了很大进展,部分原因是收集了大量丰富的经过人工标注的高质量数据。然而,逐像素标注需要花费大量时间和高昂的成本,例如在Cityscapes 数据集中的一幅图像,标记所有像素需要一个多小时[1]。截至目前,语义分割数据集只有数万张经过人工标注的图片,比其他计算机视觉领域的数据集小几个数量级[2]。所以对于语义分割而言,缺少的不是数据,而是标注。
近年来,人们在有限的标注数据集上不断创新网络架构,包括采用注意力机制等,取得了一定成效[3]。本文从克服标注数据集不充足的角度出发,采用半监督学习方法提升模型精度。在充分利用人工标注数据的基础上,挖掘未标记数据的潜能,使模型具有更好的可伸缩性以及更优秀的泛化能力。
本文使用的训练框架如图1 所示。首先,在人工标注的数据集上训练模型,挑选精度最高的模型作为标注生成模型,通过标注生成模型为大量未标注数据生成伪标签;其次,通过设置不同置信度阈值过滤伪标签数据带来的噪声,并对所有伪标签数据进行标签平滑,生成软标签,减少伪标签中错误的标注数据对网络训练的影响;最后,将人工标注数据与软标签数据以一定比例进行混合训练,提高模型的鲁棒性,增强模型对新数据的泛化能力。该训练框架最大的优点是具有可推广性,不管采用什么样的网络框架,都可使用本文的训练框架继续获得一定的提升。
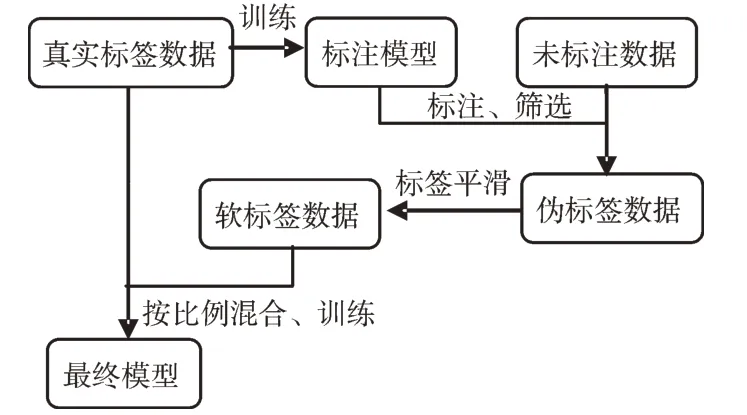
Fig.1 Structure of training framework图1 训练框架结构
理论上伪标签数据会成倍地扩大训练集规模,从而增加训练的计算成本。分割模型训练需要输入高分辨率的图像,对显存要求很高。本文采用逐步增加训练图像分辨率的方法,使得在训练过程中占用更少的显存,从而提高每一批次的训练样本数量,降低计算成本、提高训练效率,而不会影响最终的模型性能。
本文的贡献总结如下:①提出一种可在正确处理噪声的前提下,以较高质量生成像素级伪标签的方法;②提出一种可通过逐步增加图像分辨率来加快训练速度,同时又不会损失训练精度的方法;③本文进行了大量实验,对以上两种方法进行了广泛评估,以证明其在场景分割数据集上的有效性。
1 相关技术与方法
这一章节主要介绍与本文背景相关的语义分割和半监督学习方法最新进展。
1.1 语义分割
语义分割是一种逐像素分类的图像分割算法,该方法会对图像中的每个像素进行分类,图2 为一个具体案例。

Fig.2 Input image and output image after semantic segmentation图2 输入图像与经过语义分割后的输出图像
自从2014 年完全卷积网络(Fully Convolutional Networks for Semantic Segmentation)实现了像素级语义分割算法端到端的训练后[4],语义分割在网络架构方面取得了重大进展,例如使用空洞卷积层(Dilated Convolutions)[5]扩大卷积核感受野的DeepLab 系列[6-8]以及尝试不同规模的池化操作捕获上下信息的PSPNet 网络[9]等,可发现最近的主要工作都集中于设计更有效的网络结构以及更好地理解上下文语义上。
本文的侧重点不同于以上研究,通过探索充分利用未标注数据的方法提升模型泛化效果。本文方法不受限于网络架构的发展,具有很强的可推广性,无论网络如何改进、结构如何优化,都可通过本文方法提升模型性能及泛化效果。
1.2 半监督学习
近年来,半监督学习方法在图像分类领域得到了广泛应用。通过使用大量未标记数据,在ImageNet 大赛上取得了很好的效果[10]。针对半监督语义分割的研究也有很多,如使用对抗学习[11]、自我训练[12]等方法提升半监督学习的学习效果等。但这些方法没有从根本上解决数据缺少精确标记的问题,很难在基准数据集上实现较好的分割效果。
本文方法不同于传统的半监督学习方法,通过训练一个标注模型生成标签,目的是充分利用未标记数据获得更好的模型性能。该方法更加通用、简单,在不使用对抗学习方法或特殊设计的损失函数的前提下,可获得较好性能。
2 算法分析与设计
上一章介绍了本文使用标签生成方法的大概流程。针对生成的大量伪标签,本文提出一种标签平滑方法生成软标签,用来解决类别不均衡以及噪声标签导致的标注混淆问题。接下来,由于训练集数量大幅增加,本文又提出加速训练的方法。在扩大的数据集上能将模型训练速度提高2 倍左右,并且模型性能不会明显下降,泛化能力得到加强。
2.1 使用模型标注数据
相较于全监督学习,半监督学习有诸多先天不足,比如其标注不会像人工标注那么精确。人们对如何将半监督学习应用于语义分割领域进行了大量研究,发现半监督学习依然很难击败全监督学习。但半监督学习的优点在于拥有大量数据,因此本文提出一种标签生成方法,为大量没有标签的数据生成伪标签,通过使用少量人工标注的数据和大量没有经过人工标注的数据来提高语义分割模型的精确度和鲁棒性,可极大地减少人们的标记工作。
2.1.1 标签生成模型训练
通过对数据集的观察,可发现许多目标在整幅图像中的占比只有百分之一甚至千分之一,图像中正样本与负样本的比例约为1∶100,在部分图像中该比例会扩大到1 000,因而会影响模型对小目标的收敛效果。此外,还存在简单易学习的样本和困难学习样本。对于容易学习的样本,模型可以很轻松地预测正确,只要将大量容易学习的样本正确进行分类,Loss 即可减少很多,导致模型不怎么顾及困难学习样本。
故考虑使用Focal Loss[13]解决这一问题:
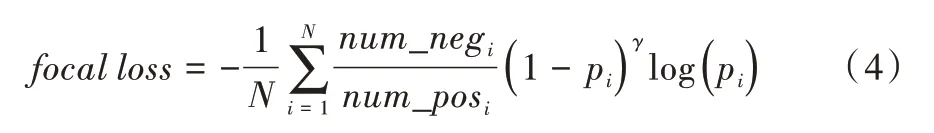
其中,num_neg 代表负样本数量,num_pos 代表正样本数量。可以看出,如果正样本数量过多,参数α整体会减小,反之参数α会增大。通过调节参数可为不同样本赋予不同权重,从而消除类别不平衡问题。参数γ通常设置为2,假设预测一个正样本的置信度为0.95,这是一个容易学习的样本,Loss 直接减少为原来的(1-pi)γ倍,为1/400,从而使模型更专注于困难学习样本。
此外,还加入一些专门为语义分割设计的一些训练技巧,使标签生成模型尽可能精确,具体细节将在实验部分详细说明。
2.1.2 伪标签生成
使用标签生成模型在大量未标记图像上生成伪标签,通过置信度筛选出可信标签。如果直接采用单一高置信度卡阈值筛选标签,会忽略低置信度的标签,但对于数量少的类别(行人、自行车等)将很吃亏,其置信度往往只有0.7 左右,会被单一阈值直接全部过滤掉,而且该阈值很难确定。通过设置不同的置信度阈值过滤数据,只要一幅图像大多数像素点都有确定的标签,即可拿来训练。
理论上来说,标签生成模型效果越好,生成的伪标签则会越精确。如图3 所示,第一张是原图,第二张是伪标签可视化图像,第三张是粗糙标注的可视化图像,可看出生成的伪标签质量已接近人工标注水平,而且比粗糙标注的标签精细很多。

Fig.3 Pseudo label visualization图3 伪标签可视化
2.2 处理伪标签带来的问题
伪标签的加入带来一系列问题,其中最主要的问题有两个:
(1)尽管伪标签质量已经很高,但还是会产生少量噪声样本,从而导致标注混淆。因为语义分割是一个逐像素预测的问题,每一个预测错误的像素点都是一个噪声样本,最终会影响模型训练效果。
(2)类别不均衡问题不容忽视。类别的偏差会随着伪标签的加入逐步放大。例如,在原始的Cityscapes 训练集中,“道路”类别的像素数量是“摩托车”类别的300 倍,但伪标签加入后会使该比例扩大到数千倍,通过Focal Loss 平衡不同样本间的数量差异已不能满足要求。如何处理类别不平衡问题对于该部分的语义分割训练是至关重要的。
针对问题(1),除需要在制作伪标签时选择高置信度的标签外,还采用平滑标签的方法,控制伪标签的平滑程度,缓解伪标签中错误数据对网络训练的影响。
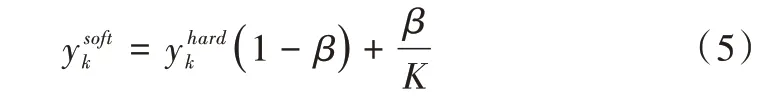
其中,K为样本总类别数,β用于控制标签平滑程度。通过式(5)可将硬标签转化为软标签。
针对问题(2),降低每个训练批次中伪标签所占比例,对于少量样本类别,随机选取该类别像素占比在0.5 以上的图像进行数据扩充,以减少样本不均衡的影响。
经过以上处理,可较好地解决伪标签带来的噪声问题以及类别不均衡问题,用真实标注数据集和软标签数据集训练最后的模型。
本文方法的优点在于训练标签生成模型使用的模型框架与最终训练使用的模型框架不必完全相同,也即是说,通过生成模型生成的伪标签数据可应用于不同训练框架中,具有通用性。
2.3 加速训练方法
当准备好数据集并处理完标签噪声后,即可正式开始训练。由于图像尺寸很大(例如768*768),语义分割训练需要庞大的计算资源。受限于GPU 的显存空间,只能使用很小的批次进行训练(具体数量取决于网络结构)。即使使用多GPU 并行训练也需要几天时间才能完成训练任务。现将数据集扩充到2~5 倍左右,训练所需时间会更长。
显然,训练速度变缓的主要原因是图像分辨率过大,每一批次只能放入较少图像。如果通过降低图像分辨率来增加每一批次的训练图像数量,一定会影响最后的模型精度。因为语义分割是在密集的像素上进行预测,分辨率下降定会导致全局上下文信息的丢失,用减少训练时间换取模型精度的下降是不值得的。因此,本文设计了一个可逐步增加图像分辨率的训练方法,在较小的分辨率图像到较大的分辨率图像之间进行迭代训练,让网络从分辨率较低的图像开始学习,逐步精细,最后达到全分辨率。通过调整训练图像的分辨率,可有效缩短训练时间。
如图4 所示,训练由粗糙的图像逐步过渡到精细的图像,在保证精确度的前提下加速训练。在训练初期使用最小尺寸为256*256 的图像,在后面的训练中逐步增加图像尺寸,每隔20 个训练周期增加一次图像分辨率(在这20 个周期内图像分辨率不会变化),逐步增加到384、512、640、768,最后是800。

Fig.4 Relationship between image resolution and number of iterations图4 图像分辨率与迭代次数关系
最终的实验结果表明,在分割精度保持不变的情况下,可将训练速度加快2 倍。该加速训练的方法也可推广到其他训练框架上,适合任何大规模数据集的语义分割训练。
3 实验结果与分析
3.1 实验数据集
本文实验使用Cityscapes 数据集,Cityscapes 拥有5 000张经过人工标注的城市环境中的驾驶场景图像,其中训练集图像2 975 张,验证集图像500 张,测试集图像1 525 张。数据集具有19 个类别密集像素标注的语义标签及背景层。除5 000 张高质量像素级标注的图像外,还包含20 000 张粗略标注的图像。Cityscapes 数据集共有fine 和coarse 两套评测标准,前者只使用5 000 张精细标注的图像,后者在5 000 张精细标注的图像基础上增加20 000 张粗糙标注的图像。本文将使用20 000 张图像的粗略标注数据作对比实验。
3.2 训练细节
利 用DeepLabV3+[8]作为网络架构,分别采用ResNet_V2_101[14]、ResNeXt_50[15]作为网络主干,使用SGD优化器进行实验。采用学习率逐渐衰减的学习策略,更新方式采用“poly”学习规则[3]:

其中,power=0.9,初始学习率为0.007,衰退率为0.999 7。批归一化处理的批处理大小为16,加速训练后在最小的图像尺寸下可达到64。
本文也进行了数据增强,在训练时进行水平翻转、对比度拉伸、高斯模糊及色彩抖动等,同时采用Focal Loss 损失函数。
3.3 评估方法
对于所有的实验,统一采用MIoU(Mean Intersection over Union)的度量方式。传统意义上的IoU 为:

在语义分割问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation),在每个类上计算IoU 之后再取平均。计算公式如下:

3.4 模型简化对比实验
根据奥卡姆剃刀法则,如果简单和复杂方法能达到一样的效果,则简单方法更可靠。简化测试实验的目的是检验新加入的方法是否有效。
第一组实验只使用2 975 张具有精确标注的图像作为训练集。该实验的目的有两个:一是建立模型效果的基准线,二是训练标注模型。建立基准线是为了给后面的实验提供参照物,相当于一个基础模型,可以此为基准判断模型的改进是否有效。训练标注模型是为了之后为粗糙标注数据生成精细标注。基础模型网络框架采用Deep-LabV3+,并使用Focal Loss 损失函数。为增强实验的可靠性,网络主干分别采用ResNet101、ResNeXt50 作对比实验,挑选精度高的主干训练标注模型。为保证实验不具有偶然性,所有实验都以相同的参数配置运行3 次,然后对结果取平均值。第一组实验结果如表1 所示,可看出用ResNeXt50 作为主干网络的模型精确度更高,故后面实验都选用ResNeXt50 作为主干网络。

Table 1 Comparison of accuracy of different backbone networks表1 不同主干网络精度对比
第二组实验使用的训练集在第一组采用的2 975 张精确标注的图像基础上,还包括20 000 张粗略标记的图像。为更好地探索伪标签的作用,本文设计了如下实验步骤:忽略20 000 张粗糙标注图像的标签,将其视为没有标签的数据,通过模型生成伪标签,并经过筛选及标签平滑处理得到软标签。为更好地发掘伪标签在模型训练中的作用,本文采用逐渐提高伪标签数据在训练集中所占比例的方法。
先从软标签数据中取出3 000 张图片,保证与真实标注数据的数量对等,即软标签数据与真实标签数据之比为1∶1,然后放在一起进行训练。为更好地验证该方法的有效性,从粗糙标记的数据中也取出同等数量的图像与真实标注数据放在一起训练作对比实验。最后实验结果发现,相比于基础模型,加入粗糙标注数据训练后的模型精确度略有提升,而加入软标签数据训练的模型精确度有较明显的提升(0.7%左右),具体实验结果如表2 所示。

Table 2 Comparison of experimental results between rough label data and soft label data表2 粗糙标注数据与软标签数据实验结果对比
以上实验结果可表明本文方法在语义分割训练中是有效的。为更好地探索该方法的潜力,将软标签数据与真实标签数据的比例逐步扩大到2∶1、3∶1、4∶1,对应的软标签数量分别为6 000、9 000、12 000。在每种情况下,依然与同等比例粗糙标注数据的训练结果作对比,实验结果如表3 所示。不同比例精度趋势图如图5 所示。
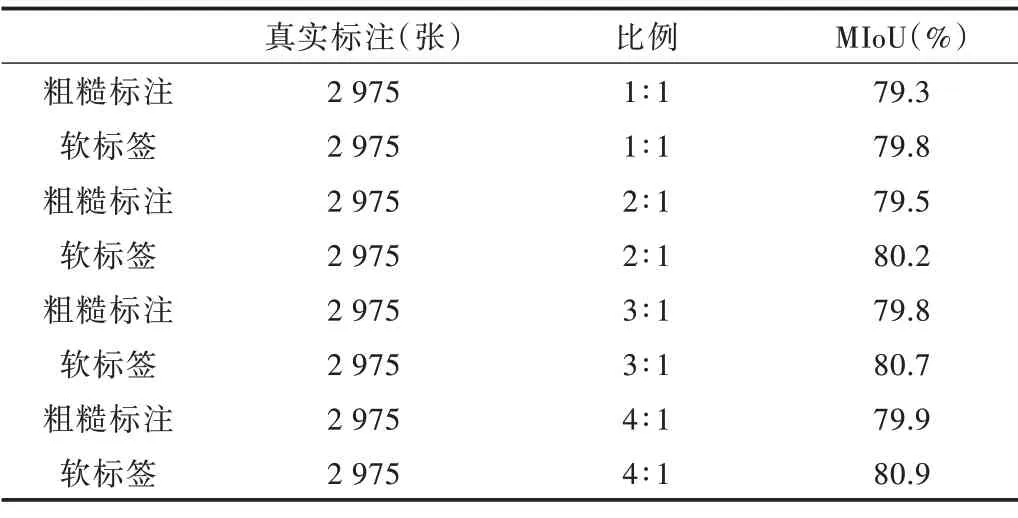
Table 3 Comparison of training results of soft label data with different proportions表3 不同比例软标签数据训练结果对比

Fig.5 Accuracy trend graph of different proportions图5 不同比例精度趋势图
可看出随着加入训练的软标签数量的增加,模型的精确度逐步提升,在4∶1 时达到最高精度80.9%,相比基础模型以及采用粗糙标注数据参与训练的模型都有了较为明显的提升。
3.5 加速训练实验
当训练数据达到15 000 左右时,该计算量十分巨大,故考虑进行加速训练。由3.4 节可以看到,当软标签数据与真实标注数据之间的比例为4∶1 时可得到最佳分割结果,所以加速实验采用该比例。按照2.3 节介绍的加速训练方法,可在精确度损失很小的前提下,训练速度达到加速前的1.9 倍左右。相比训练速度的大幅提升,精确度下降0.3%是可以接受的。

Table 4 Comparison of accelerated training results表4 加速训练结果对比
4 结语
本文提出一个可在正确处理噪声的前提下,以较高质量生成像素级伪标签的方法,并进行了大量实验对该方法进行广泛评估,以表明其在语义分割上的有效性。提出一种可通过逐步增加图像分辨率来加快训练速度,同时又不会明显降低模型精度的方法。
本文方法的优势是具有可推广性,具体表现在:可使用任何网络框架训练生成模型;生成的伪标签数据可应用于任何网络框架下;加速训练方法可应用于任何大规模数据集的语义分割训练中。
