面向图书馆基于用户画像的个性化推荐研究
2022-01-07李玲
李 玲
(中国人民大学 信息学院,北京 100872)
0 引言
随着越来越多的数据在互联网中产生,互联网从原来数据匮乏的时代进入了大数据时代[1]。为了更好地满足用户的信息需求,不少学者提出了搜索技术,如Google、百度等。然而,搜索技术在使用时存在一定的局限性。首先,搜索引擎必须获取用户主动键入的关键词进而对关键词进行检索;其次,搜索技术无法对用户的自身特性进行充分考虑;最后,搜索引擎返回的信息往往较多,从而无法对用户感兴趣的信息进行快速读取。针对搜索技术的局限性,推荐系统应运而生[2]。推荐系统不需要用户输入关键词即可利用用户的访问信息将用户可能感兴趣的内容主动推荐给用户[3]。
近几年,基于用户画像的研究逐渐增加。陈泽宇等[4]将LDA 主题模型运用于用户查询历史关键词中,通过查询对应的主题分布,最大概率地将主题对应的词扩展到原始特征空间,进而丰富用户特征并利用SVM 对用户的基本属性进行分类,从而构建用户画像;赖建华等[5]运用容忍度测算、突变测算、差值测算与峰值测算方法,发现并分析用户的异常访问行为,进而构建用户行为画像,使得系统可以实时并准确地对用户的异常行为进行响应;李仁德[6]将司机评分数据作为区块链的基础依据,基于司机画像设计智能合约机制,解决了司机绩效考核中的去中心化问题;周静等[7]基于用户画像的属性偏好与时间因子设计一种服装推荐算法,使得用户潜在兴趣的挖掘效率更高;窦维萌等[8]基于用户画像提出一种DB-CF 个性化音乐推荐算法,从而为用户带来更好的用户体验;关菲等[9]通过对用户行为的权重进行重新分配,并将用户行为数据按照时间顺序重新分配权重,提出一种基于用户画像的个性化文献推荐算法,进一步为用户提供精准推荐服务;胡朝举等[10]基于用户画像数据对用户进行模糊聚类,然后在聚类簇内运用协同过滤算法为用户完成项目推荐;岳强等[11]针对用户评论中的emoji 表情提炼用户情感偏好,提出一种情感偏好矩阵的ItemCF 算法,相比于经典推荐算法而言,该算法在准确率和召回率上分别提高0.02、0.03。
同时,高校信息化建设的快速发展使得“互联网+校园”遍布校园的每一个角落[12-14]。王欣等[15]通过将图书馆个性化推送服务与知识聚合进行分析,从而为科研学者提供更强的专业知识;李艳等[16]基于大数据挖掘对高校图书馆的个性化服务研究进行分析,设计基于高校图书馆特点的体系架构模型与业务分析流程,为构建图书馆个性化服务提供技术支撑并为高校提供决策依据;刘海鸥等[17]对基于大数据深度画像的个性化学习精准服务进行研究,从而满足学习者的多粒度个性化需求;钱蔚蔚等[18]给出图书馆信息服务功能性用户体验量化的实验效果,从而提升图书馆网站的用户体验;康存辉等[19]基于大数据对图书馆精准服务进行研究,实现图书馆大数据建设与服务双赢。
然而,网络中的冗余数据会使用户在数据的动态性方面变得无所适从[20],如读者在面对自己比较模糊或者无法采用简单的词语对其想使用的关键词进行定义时,则无法获得精确的书籍信息,从而影响读者对系统的使用频率,进而降低系统的使用性[21]。针对此问题,本文在已有研究的基础上,通过对智慧校园中的数据进行预处理,进而构建读者的用户画像,然后通过用户画像构建个性化推荐框架,从而更好地为校园中的读者提供个性化服务。
1 协同过滤推荐
协同过滤推荐算法作为推荐系统中的常用算法可以在不需要了解大量用户和商品信息的情况下,利用用户对商品的评分或者用户的其他行为为用户推荐个性化服务[22]。协同过滤推荐算法主要分为基于用户和基于项目(商品)的协同过滤推荐算法。本文主要介绍基于用户的协同过滤推荐算法。
基于用户的协同过滤推荐算法采用与目标用户相似的用户评分为目标用户进行推荐。例如,目标用户u和用户v相似,则称用户v为目标用户u的一个近邻。假设与目标用户u相似的近邻个数为k,采用N(u)表示与目标用户u相似的k个近邻[23]。这里,假设只有N(u)中对项目i作了评分的用户才能够用于预测目标用户u对i的预测评分,因此,选用k个与用户u兴趣相似且对项目i作了评分的用户代替原来设定的k近邻,记为Ni(u),则目标用户u对项目i的预测评分可用如下形式表示:

式(1)中,用户v对项目i的评分可用rvi表示。sim(u,v)为用户之间的相似度,定义如下:

其中,Iuv代表用户u和用户v同时评分的项目,代表用户u对系统中所有项目的平均评分,代表用户v对系统中所有项目的平均评分,rui和rvi分别代表用户u和用户v对项目i的评分。
应用上述计算方法可以将用户u对项目集合中的各项目进行评分,然后通过排序算法对各项评分进行排序,进而选出排名靠前的n个项目为用户进行推荐,继而完成基于用户的协同过滤推荐服务。
2 面向图书馆基于用户画像的个性化推荐框架
本文在校园基础系统和基础数据的基础上,通过对已有数据作预处理,然后建立用户画像,进而构建个性化推荐框架,整体结构框架如图1 所示。可以看出,面向图书馆的基于用户画像的个性化推荐框架主要包括3 个部分:数据获取与预处理、用户画像构建、个性化推荐服务。
2.1 数据获取与预处理
数据获取及预处理是该个性化推荐框架的基础,也是提供个性化推荐服务的数据来源。原始数据分别来自学校的教务系统、研究生系统、档案馆、就业处以及图书馆系统等。对原始数据进行数据清洗,包括对该数据进行数据采样和样本过滤。一般通过随机采样、固定比例采样的方法对原始数据进行采样,并按照训练模型需要,对采样后的数据设定其样本权重。同时,结合训练模型对采样后的样本数据进行过滤。必要时针对数据中的异常点进行检测,常用的检测方法有聚类算法、最近邻算法等。可通过使用基于密度的异常点检测算法进行检测,如LOF(Local Outlier Factor)算法。
根据以上方法得到过滤后的样本数据,然后对这些样本数据进行特征处理。特征处理方法一般包括对特征进行归一化和离散化,以及对特征进行特征降维和特征选择等。在实际的数据特征中,可能会遇到特征值因取值范围过大而导致最终模型效果偏离预期。因此,为了对不同范围的特征进行平衡取值,本文采用归一化方法对特征进行处理,进而将特征值归一化到[0,1]区间,从而更好地训练模型。一般可以通过函数归一化、排序归一化、局部最大最小值归一化等对数据进行归一化处理。同时,为了对数据中的连续值进行离散化处理,需要采用等值或者等量的方法对具有连续值的特征进行划分。如针对读者年龄的划分,可将10-20 岁的离散值设置为1,年龄为20-30 的离散值设置为2 等。同时针对较稀疏的数据集,可以通过单独表示、取众数或者平均值等对其空值特征进行填充。在特征降维的方法选择上,可以通过主成分分析或者奇异值矩阵分解等对特征进行降维。针对特征选取,可以通过方差选择法、相关系数法、卡方检验、互信息等方法进行选择。如运用方差选择法时,先计算各特征的方差,然后根据阈值设置,选择大于阈值的特征即可。
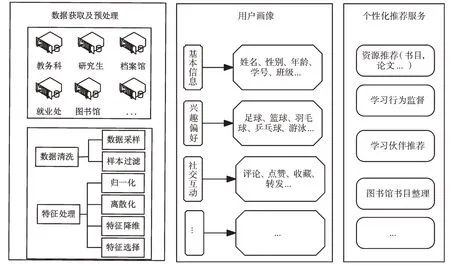
Fig.1 Personalized recommendation framework based on user portrait图1 基于用户画像的个性化推荐框架
2.2 用户画像生成
通过对原始数据进行数据获取和数据预处理,将筛选后的特征数据建立用户画像。首先,通过用户的基本信息、兴趣偏好、社交互动等构建用户的个性化特征标签,然后运用基于关联规则的学习方法,对用户的标签进行聚合学习,从而生成更加全面和立体的用户画像模型。为了生成多维的用户画像,将高校中学生群体的基本信息、兴趣偏好信息以及社交互动信息等进行结合,从而获得用户的个性化特征标签,如下所示:

其中,User_Info表示用户基本信息,主要包括姓名、性别、年龄、班级、学号等信息;User_Inte表示用户兴趣偏好信息,包含有篮球、音乐、阅读等;User_Social表示用户社交互动信息,分别为收藏、转发、喜欢等信息,如下所示:

2.3 个性化推荐框架构建
通过从各子系统中获取原始数据,对原始数据进行数据预处理,然后运用预处理的数据构建用户画像模型,基于用户画像,运用基于用户的协同过滤推荐算法为用户提供个性化服务,即可完成个性化推荐框架整体构建。
3 个性化推荐应用
3.1 个性化资源推荐
在用户画像建立的基础上,运用基于用户的协同过滤推荐算法为用户推荐个性化资源,包括其感兴趣的书籍、期刊等,如图2 所示。
从图2 可知,通过对各子系统的数据进行数据获取及预处理,即将原始数据通过数据预处理步骤,将用户画像的个性化标签进行特征向量化处理;然后运用基于用户的协同过滤推荐算法为用户获取用户的近邻,计算用户对其所推荐项目的预测评分,进而运用排序算法对所推荐的项目进行重排列,从而选择目标用户对预测评分较高的n本书籍作为对目标用户的推荐列表,最终完成对用户的个性化资源推荐。
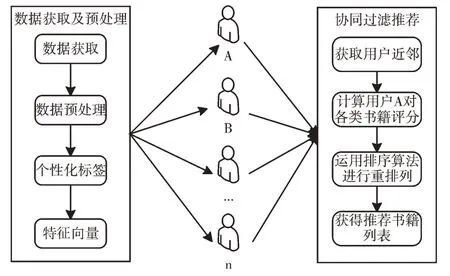
Fig.2 Personalized resource recommendation图2 个性化资源推荐
3.2 个性化学习行为监督
随着高校阅读资源的不断增加,可能会出现资源供需不平衡的问题,从而导致用户缺乏对学习的有效监督,学习行为监督的减少导致用户学习效率降低。因此,为了更好地利用阅读资源,提高用户学习效率,可以为用户提供个性化行为监督,进而保证当用户在学习行为中出现消极现象时,能够及时提醒用户完成学习目标,从而提高学习效率和质量,如图3 所示。
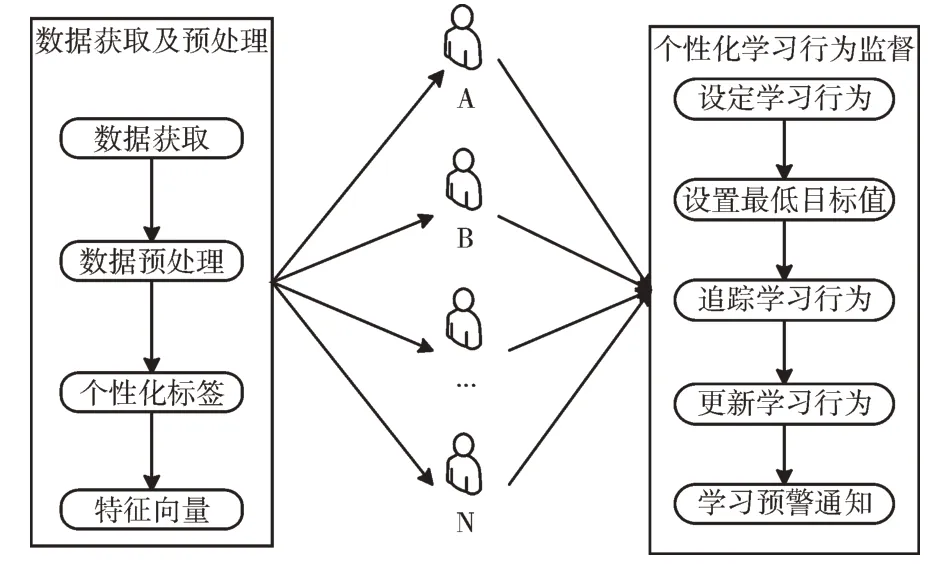
Fig.3 Personalized learning behavior supervision图3 个性化学习行为监督
从图3 可知,个性化学习行为监督主要包括数据获取及预处理、用户画像和个性化行为监督3 个部分。通过将原始各系统的数据作预处理并将用户的个性化标签进行特征向量化处理,从而对用户的学习行为特征进行设定,如通过用户去图书馆的行为,可将其连续7 天不去图书馆的行为作为最低的通知阈值,进而追踪用户的学习行为并对其进行更新,从而给出及时的学习预警通知,督促用户更好地进行监督和管理。
3.3 个性化学习伙伴推荐
互联网学习资源的不断增加使用户在学习过程中不可避免地会遇到许多问题,如自主学习方式可能会使用户在学习过程中产生学习孤独感,进而导致学习热情和学习效率降低。而通过个性化推荐框架的精准服务,可以为用户推荐与其具有共同学习背景及共同学习兴趣的用户进行学习,或者建立共享社区供用户讨论,进而提高用户的学习积极性和学习效率,如图4 所示。
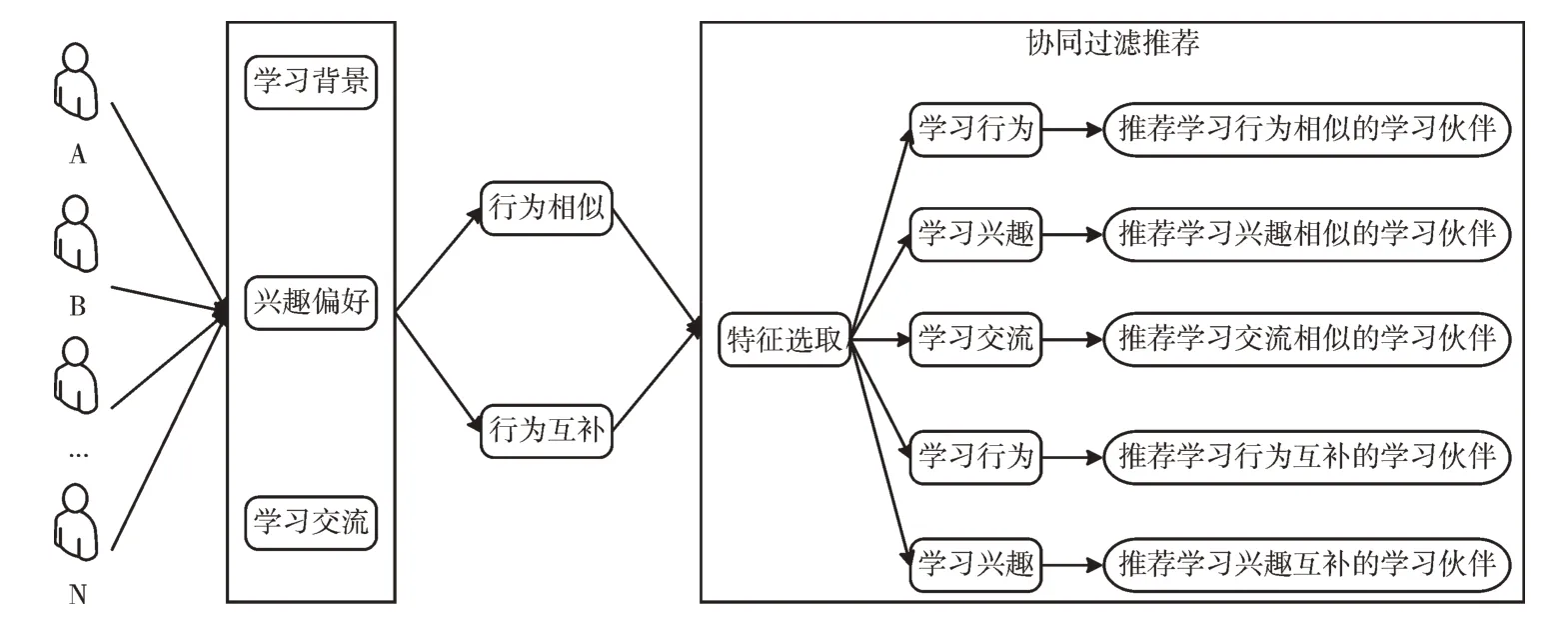
Fig.4 Personalized learning partner recommendation图4 个性化学习伙伴推荐
从图4 可知,个性化学习伙伴推荐主要包括对学习行为相似和互补的学习伙伴推荐。通过提取用户画像中的学习背景、兴趣偏好、学习交流等个性化标签信息,为用户推荐学习行为相似和学习行为互补的伙伴。在此基础上,根据用户学习兴趣,运用协同过滤推荐算法为用户推荐兴趣相似和互补的学习伙伴,进而完成个性化学习伙伴推荐。
3.4 图书馆书目管理
根据上述个性化推荐框架,为用户提供个性化学习资源、学习伙伴,并对其学习行为进行监督。鉴于此,可以针对图书馆中的图书摆放位置及其他资源进行管理,如用户在阅读计算机书籍时,可能会需要数学理论支撑,此种情况下,图书管理员可以将这两类书籍放置于相邻位置,从而减少读者查找书籍的时间,进而提高读者学习效率,同时减少图书馆维护成本。如用户在学习交流中一般有3 个学习伙伴参与,因此在座位设置上,可让3 个座位在一起且处于安静位置以供用户更好地进行学习交流。
基于上述描述,借助个性化推荐框架,不仅可以完成学习资源推荐、学习行为监督以及学习伙伴推荐,从而提高用户学习效率,而且可以通过该框架提高图书馆资源管理效率,节省图书馆运营成本。
此外,可以通过用户使用该推荐系统为用户反馈用户年度画像,如用户喜欢阅读的书籍类型、用户是否经常借用研讨室,以及与该用户同时借用同一类型书籍的用户信息,或者用户对图书馆馆员的评价信息等。
4 实验设计与分析
4.1 问卷设计
对面向图书馆基于用户画像的个性化推荐框架进行研究,并作实际测试。在测试中,主要以个性化推荐系统中的4 种主要推荐功能为主。因此,在问卷设计上主要包括3 个部分:①研究概要介绍和问卷说明;②调查对象基本信息,包含性别、年龄、教育程度、使用图书馆系统、专业等选项;③调查对象对图书馆推荐系统中各子功能的真实使用感受,并将其进行量化评价,如将非常好、好、一般、不好、非常不好量化为5、4、3、2、1 分,从而将其对该个性化推荐系统的好感程度一一展现出来。
4.2 数据样本
本次实验对象以高校本科生和研究生为主,运用随机抽样方法进行选择,最后选出5 000 名学生作为此次测试的调查对象并回收全部问卷。同时,针对图书馆的书目管理推荐功能,对图书馆中管理员的使用体验进行总结。
4.3 实验结果与分析
通过对5 000 份调查问卷的结果进行统计,结果如图5所示。
从图5 可知,个性化资源推荐相较于个性化行为监督及个性化学习伙伴在用户体验中更具优势。其中,个性化资源推荐在90 分以上的人数占总测试人数的82%以上。同时,个性化行为监督和个性化学习伙伴推荐在90 分以上的人数也达到总测试人数的70%以上。如果以80 分为系统的推荐衡量标准,则此次测试各推荐功能可达86%以上。实验测试中,也有分值偏低的情况出现,这与调查用户的基本信息有直接关系,如此类用户一般不使用图书馆系统,也不参与学校相关活动等。
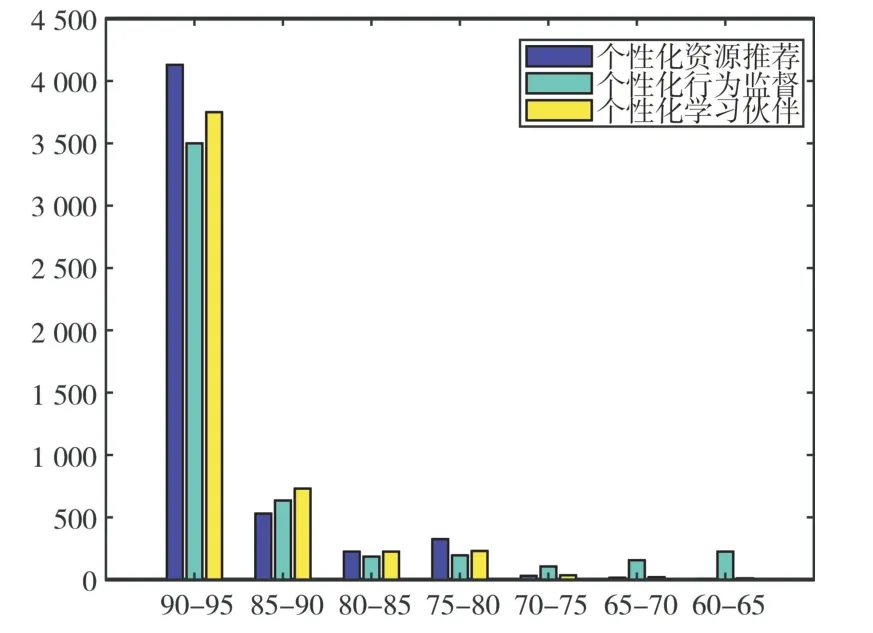
Fig.5 Statistical comparison of each recommendation service图5 各推荐功能统计比较
通过提取5 000 名读者的用户画像,可以得到不同用户对书籍类型的喜欢程度,如图6 所示。可以看出,调查对象中喜欢小说、IT 书籍以及散文的用户居多,悬疑和经济次之,喜欢科幻、历史和心理学的用户较少。而在小说、历史、经济和其他书籍类型的用户中,男生和女生基本上相同。对于社科类书籍,女生读者更多;而对于IT 书籍,则男生读者更多。
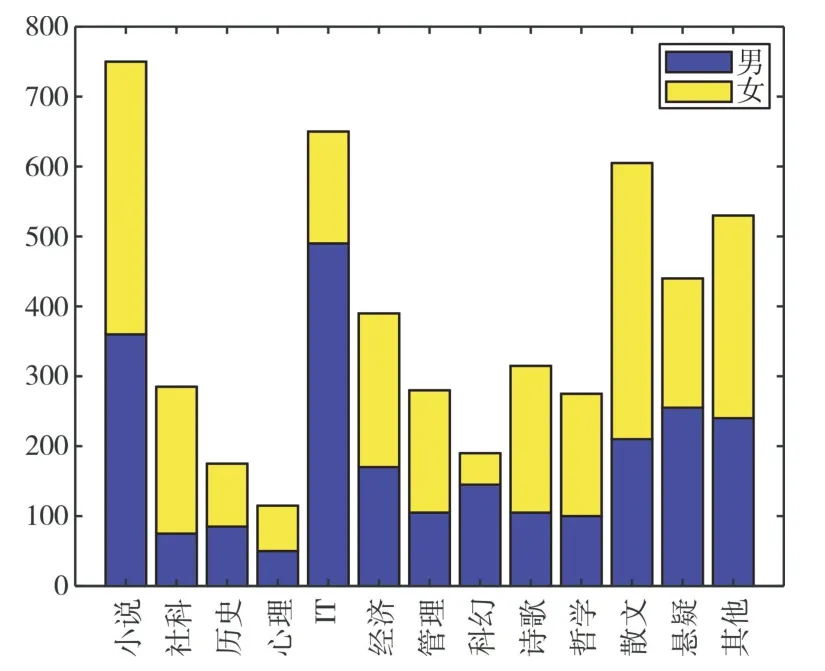
Fig.6 Evaluation of books by different users图6 不同用户对书籍的喜欢程度
不仅如此,对未使用个性化推荐框架时用户对图书馆中各基础设施的使用情况进行统计,如图7 所示。其中,经典服务代表图书馆未采用推荐服务,单一推荐代表只使用图书馆中的用户数据构建用户画像并进行推荐,个性化推荐框架将校园中其他子系统下的用户数据进行整合,进而构建用户画像为用户提供个性化推荐服务。纵坐标轴表示样本对不同服务的评分统计情况,书目管理主要以图书馆中的馆员为样本进行统计。
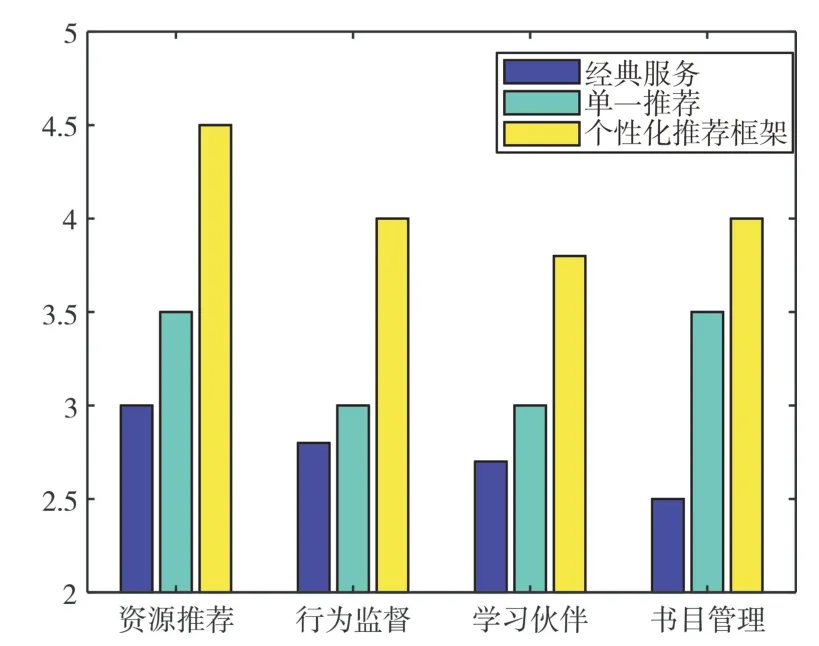
Fig.7 Comparison of different recommendations图7 不同推荐比较
从图7 可知,随着推荐框架中用户数据集的多样性增加,推荐服务更受好评,相比较经典服务而言,通过使用个性化推荐框架,用户的满意度平均提升了48.23%,相较于只使用单一推荐而言,用户的满意度平均提升了25.6%。
同时,对图书馆中的书目管理推荐服务进行了测试和统计,通过统计图书馆中馆员的评价信息,对其进行整理如表1 所示。

Table 1 Evaluation information of librarians表1 图书馆馆员评价信息
从表1 可知,馆员对个性化推荐系统的评价信息以书籍管理、图书馆资源配置、人员配置为主,通过使用个性化推荐系统,使得图书馆在书籍管理、设备使用和人员安排上更加有效,减少了对应的成本投入。
5 结语
随着阅读资源的与日增长,如何在众多阅读资源中为用户推荐更好的个性化服务尤为重要。本文将智慧校园中的各子系统进行融合,从而获取用户原始数据,通过对该原始数据进行预处理从而构建用户画像,进而为用户提供个性化服务。需要指出的是,本研究在协同过滤推荐算法选择上采取的是基于用户的协同过滤推荐算法,在后续个性化推荐服务使用中,可以选择优化过的推荐算法为用户进行推荐,进而提高推荐效率。
