基于Bert 的测试用例复用方法研究
2022-01-07万进勇史涯晴罗浩榕
万进勇,史涯晴,黄 松,罗浩榕
(陆军工程大学指挥控制工程学院,江苏南京 210001)
0 引言
随着军队现代化建设进程加快推进,越来越多的军事软件应用到军事活动中,因而对这些军事软件的质量要求越来越高。软件测试作为装备试验鉴定中的重要一环,对装备质量起到保驾护航的作用,同时也对测试效率要求越来越高。软件测试是程序的一种执行过程,是在软件生命周期中一项十分重要且复杂的工作,是软件可靠性保证的有效方法。研究表明,软件测试占用软件开发过程的大量时间,提高软件测试效率、缩短软件研制周期是软件工程领域亟待解决的问题[1]。近年来,围绕提高软件测试效率,研究者提出大量自动化测试框架与测试方法,提高了软件测试执行阶段的效率。
在测试设计阶段,如何提高测试用例设计是软件测试过程中的关键一步,测试用例复用的思想由此产生。测试用例设计是软件测试过程中的重要环节,利用历史项目的测试用例,指导新项目测试用例的设计与执行,实现测试过程中的资产复用是提高软件测试效率的重要方式。软件测试作为一项知识密集型活动,在历史测试的各阶段都会产生大量测试文本数据,通过整理提取历史测试资产库中的测试用例相关测试数据建立软件测试用例库。在此基础上通过Bert 语言模型[2]对测试用例库的数据进行处理,结合文本相似度计算实现测试用例复用,以此提高测试人员测试用例设计效率。
目前,有关测试用例的复用研究可分为以下几种类型:基于形式化建模的复用方法,使用XML、Z 语言等[3-4]方式对测试资产从不同层面建立统一规范的表述从而形成测试资产库,在此基础上使用基于关键字的检索或相似性度量的方式实现测试资产复用;基于主题词检索复用方法[5]需要构建软件测试用例的检索模型,通过模型匹配与检索算法获取测试资产库中的测试用例信息;基于需求匹配模型,通过建立测试用例与软件测试需求之间的关联性,包括建立软件需求—测试树、获取需求的向量表示并进行需求分类[6]、利用TF-IDF 词频统计方法与向量模型[7]挖掘文档标签信息进而复用测试用例文档。
通过相关文献研读,测试用例复用研究中还存在一些问题:历史测试资产包含繁杂的测试信息且存在形式各异,对测试用例采集造成挑战;测试文本数据具有很强的文本语义信息,以往通过检索的复用方式难以挖掘测试文本数据更深层的语义信息从而实现更小粒度的复用。
参考GJB/Z141 军用软件测试指南、GJB 438B 军用软件开发文档中测试用例涉及的文本信息,本文分析测试用例复用所需的测试信息,通过SQL 语言等技术对结构化与非结构化的测试用例、测试需求进行采集,形成比较标准的测试用例资产库。为了获取测试文本语义向量表示,引入自然语言处理领域中预训练语言模型,将构建的测试数据训练集输入到Bert 预训练语言模型,进行微调以更新模型参数。通过微调的模型能够获取到测试文本数据更好的语义向量表示,结合文本相似度计算实现测试用例复用。最后通过实验验证了该方法的有效性,提升了测试用例设计效率与质量。
1 软件测试用例资产库
软件测试用例复用的一个重要前提是构建一个完备且规范的测试用例库,测试用例、测试需求是软件测试资产库中的核心资产。测试团队应具备全面、协调和可持续发展的特点,构建标准化、规范化的测试资产库,用于指导今后测试设计与测试人员培训等工作。软件测试贯穿于软件开发生命周期,每个测试阶段都会输出相应文档,这就是基础的测试资产,不同测试阶段,测试的输入输出如表1 所示。软件测试资产不仅包括测试的全生命周期中输出的各种文档数据,同时也包括测试团队积累的测试经验、技能和思维,比如某类项目中的一些共性功能、同类缺陷、测试策略等。

Table 1 Assets output during testing表1 测试过程中输出的资产
本文主要通过研究测试资产实现测试用例复用,测试用例复用是软件复用中的一种类型,软件复用是为避免重复劳动、提高软件质量和生产效率的解决方案[8]。根据软件复用对象可分为两类:产品复用和流程复用,产品复用指软件开发过程中的需求规范、软件设计、测试计划、测试数据等,流程复用是使用可复用的应用生成器自动或者半自动复用开发过程并自动生成所需系统[9]。
测试用例设计是软件测试过程中的重要环节,如何利用历史项目的测试用例,指导新项目测试用例设计与执行,实现软件测试用例复用是软件测试复用的主要研究方向。在已有的一些测试资产中,测试大纲能够体现出软件需求与测试需求的关系,由于特征相似的需求具有相似的测试项,需提取测试大纲中测试需求建立测试用例资产库。由于相似测试项对应的测试用例也具有一定的相似性,通过测试需求与测试用例之间的关系完成测试用例资产库建设,作为测试用例复用的基础。
测试需求与测试用例关联最紧密,测试用例设计都是根据软件软件测试需求进行精心设计。软件测试需求明确了测试过程中待解决的问题,在建立的测试用例资产库中,测试需求应包含以下5 个属性信息:需求项名称表示为Name、所属领域信息表示为Filed Information、需求描述表示为Description、需求类型Type、测试方法Method。因此,将测试需求(TR)表示为一个五元组:TR=
测试用例是指对一项特定的软件产品进行测试任务描述,为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,用于核实是否满足某个特定软件需求。测试用例资产库中,测试用例包括7 个属性信息,测试用例名称表示为Name、测试说明表示为Description、测试类型表示为Type、测试步骤表示为Process、前置条件表示为Precondition、预期结果表示为Excepted,测试需求追踪表示为Requirement Link,因此测试用例(TC)可表示为一个七元组:TC=

Fig.1 Test case example图1 测试用例示例
测试用例是检验测试过程是否有效的重要因素,设计良好的测试用例是测试工作的关键。同时,测试用例的编写要求测试人员对产品设计及软件需求相关知识有比较清晰的认知。历史经验表明,同一领域的测试项目往往遵循相同的行业规范、标准等,而同一类型软件的使用场景、功能结构、性能要求等方面的需求存在很大相似性,因此具备了知识复用的基础,进而可以根据项目之间的软件特征信息、测试需求相似性计算实现测试用例复用。
2 测试用例复用研究
2.1 测试用例复用方法
研究表明,当两个项目存在某种相似性时,其测试需求、测试用例、潜在问题等也应存在较大相似性,因此从软件相似性角度研究测试用例复用。为了实现软件测试用例复用,首先需要设计一个结构完整并具有一定规模的测试用例资产库,并且建立测试用例与测试需求的关联关系。在设计好的测试资产库基础上,按照一定的准则采取相应的技术对软件特征、软件测试需求、软件测试用例进行处理,最终实现软件测试用例的复用。本文设计软件测试用例复用方法如图2 所示。
首先,基于原有的软件测试资产数据库抽取测试用例、测试需求相关数据,形成测试用例资产库。根据测试资产库中表单数据结构,通过SQL 语言对历史项目数据库进行操作,提取软件特征信息、测试需求、测试用例信息,并且根据需求追踪表建立测试需求与测试用例之间的关联关系,进行合理的分类、管理、维护,形成最初的测试资产库。
其次,根据软件特征信息检索筛选候选集,根据软件测试需求及测试人员输入信息计算软件信息之间的相似度,以相似度计算值作为测试用例推荐复用的参考指标。信息检索采用从上至下的策略输入软件所属领域、软件类型、测试类型、测试方法,层层递进获取测试用例复用的候选集。相似度计算功能借助于Bert 词向量模型,获取测试相关数据向量表示,并通过计算两个向量之间的距离评估它们的语义相似度。该步骤在测试资产库的基础上,利用检索与相似度计算技术,选择出了测试推荐复用的候选集。
最后,通过对测试人员输入与测试需求等数据之间的相似度值进行综合排序,选择Top-K 进行推荐,实现对测试用例复用,测试人员根据实际需求对推荐的测试数据进行修改复用,并将新的测试用例入库以便于后续模型的进一步完善。
2.2 测试文本相似度计算
2.2.1 词向量模型
本文使用Bert 系列语言模型获取软件测试数据的词向量表示作为相似度计算的基础,语言模型的发展经历了从统计语言模型到神经网络语言模型的阶段。早期的语言模型是预测某个文本序列在语言中出现的概率,并以此概率分布表示该文本序列。其中,在统计语言模型中最具代表性的就是N-gram 模型,它是一种典型的基于稀疏表示的语言模型。
2003 年,Bengio 等[10]提出了神经网络语言模型,在得到语言模型的同时也产生了副产品词向量。神经网络语言模型将词表中的单词i映射为向量函数C(i)∈Rm,以此表示单词的分布式向量表示(Distributed Feature Vectors),再通过一个函数将词向量作为输入序列(C(wt-n+1),…,C(wt-1))映射成下一个词的概率分布。随着神经网络语言模型与词向量的提出,后继研究者提出了Word2Vec、Glove、Elmo、GPT、Bert 系列等语言模型。
Word2Vec 有两种训练方法:CBOW、Skip-gram[11],通过此方法将单词表示为上下文无关的Static 词向量,因此无法解决一词多义的现象。Elmo 使用两个独立的单向Lstm实现根据上下文不同而获取不断变化的Dynamic 词向量[12]。GPT 是一个生成式的预训练模型[13],采用远远优于Lstm 的特征提取器Transformer。Bert 语言模型的文本特征抽取采用双向的Transformer 结构,可以进一步增加词向量模型泛化能力,充分描述字符级、词级、句子级之间的关系特征。
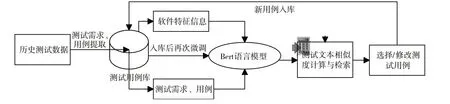
Fig.2 Test case reuse method图2 测试用例复用方法
2.2.2 相似度计算方法
本文实验采用Bert 预训练语言模型,Bert 语言模型训练可分为预训练与微调两个过程。其中,Bert 的预训练过程有两个任务,分别是:MaskedLanguageModel(MLM)、Next Sequence Prediction(NSP)。MLM 过程中使用上下文预测中心词信息获取词向量表示,NSP 通过数据学习上下句子是否是噪声以增强句子之间的关系判断能力。Bert 语言模型中适用于计算句子相似度的句子对任务结构如图3 所示。
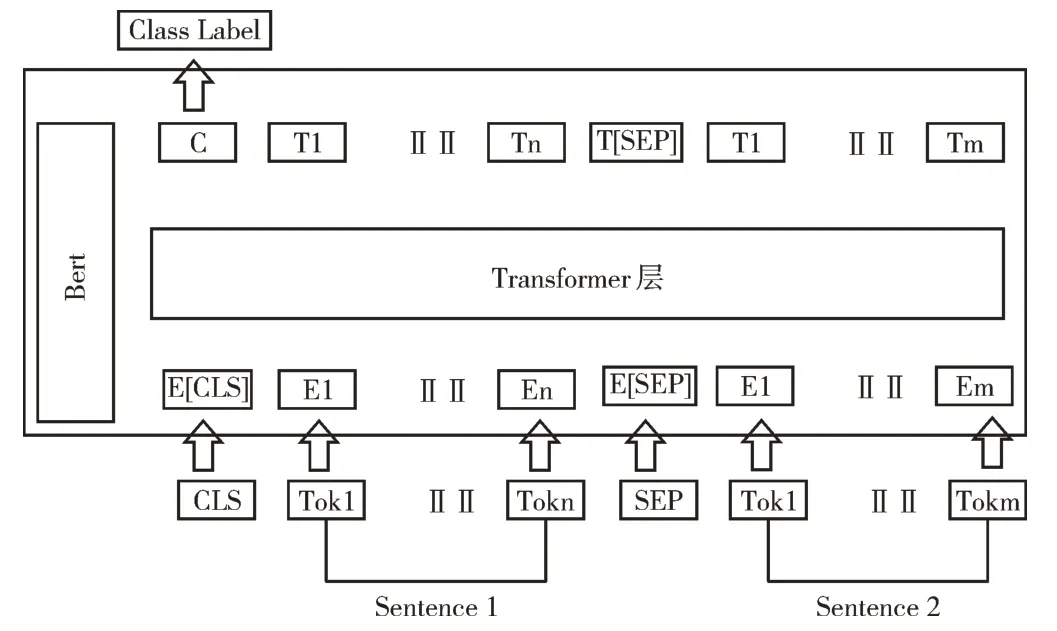
Fig.3 Bert sentence pair task structure图3 Bert 句子对任务结构
本文针对相似度计算任务,构建了针对Bert 模型进行微调的训练数据,训练集数据格式为:{Sentence1、Sentence2、Label}。Label 标签为0 和1,0 表示句子对不相关、1表示句子对相关或相似。通过收集一定数据量句子对,构造训练数据的数据处理类,针对模型进行微调操作,强化模型在测试领域的适用性。
通过Bert 微调后的语言模型可以获取到测试文本数据的向量表示,然后通过计算测试数据之间语义相似度衡量测试数据的相似程度。Bert 模型中可以将其分类任务改造成相似度计算问题,然后将CLS 对应的embedding 输入到一个sigmoid 函数表示文本向量。但此种方式学到的向量并没有多少的语义信息,不足以用作测试文本语句的向量表示,因此在获取文本向量表示后使用相似度计算的方式计算语义相似性。常用的语义相似度计算方法有欧式距离、余弦距离、杰卡德相似度、海明距离,其中选择余弦距离是最为常见的文本向量语义相似度算法。因此,本文选择余弦距离计算两个文本向量之间的夹角余弦值,其计算公式如式(1)所示。
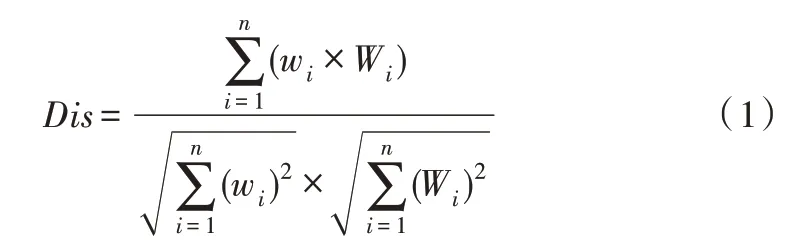
其中,Dis表示文本之间相似度计算结果,取值范围为[0,1],值越大表示相似性越高。
根据测试资产库中测试需求、测试用例与测试输入数据,本文设计测试文本数据相似度计算方法主要过程如下:
(1)根据新的测试项目输入的特征信息,利用检索技术获取历史库中符合特征的软件项目得到候选集1。
(2)在候选集1 中根据测试人员要求的测试阶段、测试需求类型、测试方法等进一步选择出候选集2。
(3)在候选集2 中,计算测试人员输入的需求名称、需求描述与候选集2 中测试数据之间的相似性,通过式(1)分别计算需求名称之间的相似性SimNa、需求描述之间的相似性SimDe、需求描述与测试说明之间的相似性SimDe-De、需求描述与预期结果之间的相似性SimDe-Pre,然后通过加权求和得到最终的相似度如式(2)所示。
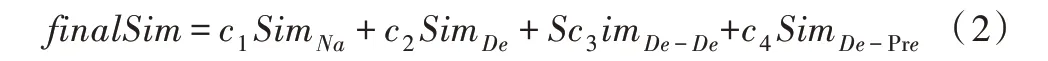
其中,参数c1、c2、c3、c44 种属性相似度所占权重,根据测试人员的经验可分别取值为0.3、0.3、0.2、0.2。
(4)利用式(2)计算并获取测试人员输入与历史数据之间的相似性,根据相似性值的大小进行排序,选择其中相似性值最高的6 条推荐给测试人员作为测试参考信息。
测试文本相似度计算过程伪代码如下:

其中,item 表示历史测试项目库,λ 表示文本属性相似度分配权值,f 表示新项目输入的软件特征,info 表示新测试输入文本数据。
3 实验结果
本次实验使用实验室积累的测试项目数据,包括几种不同类型项目包括功能测试、接口测试、性能测试在内的数千条测试用例数集。为了评价测试用例复用效果,对某信息管理系统和指挥系统两个不同类型的软件系统进行测试。测试实验过程中测试用例部分推荐信息如图4 所示。
挑选4 位新手测试人员随机分成AB 两组,A 组人员不采用测试用例复用方法、B 组人员使用测试用例复用方法,统计用例设计效率即单位时间AB 两组人员设计测试用例数以及评估测试用例质量。实验中测试用例设计效率如表2 所示,通过统计发现,相比于传统的测试用例设计,此方法测试用例设计效率提高近70%。

Fig.4 Recommended test case information图4 推荐的测试用例信息
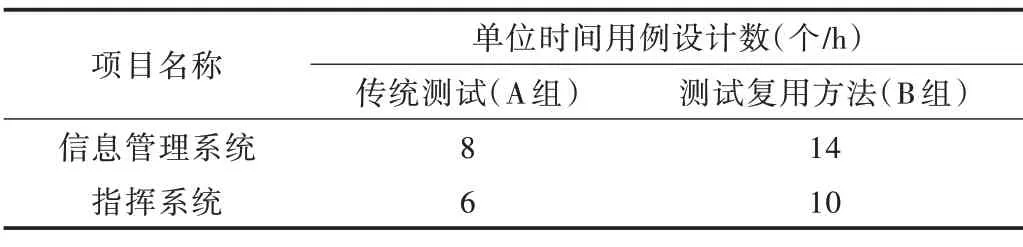
Table 2 Test case design efficiency statistics表2 测试用例设计效率统计
在测试用例复用过程中,B 组人员统计测试复用方法推荐6 条测试用例中有参考价值的用例数称之为正确推荐用例数,计算推荐复用的准确率。实验中测试用例推荐准确率如表3 所示,其中准确率计算公式如式(3)所示。

其中,N 表示测试项目需求的个数,ni表示根据每个需求推荐出的正确测试用例个数。实验结果表明,此方法的用例推荐准确率均在60%以上。

Table 3 Test case recommendation accuracy rate statistics表3 测试用例推荐准确率统计
通过两个不同类型项目对测试用例复用方法进行验证,结果表明,基于Bert 的测试用例复用方法可以提高软件测试用例设计效率。此外,通过专业测试人员对AB 两组的测试用例评估发现,B 组设计的测试用例具有更好的可理解性与可维护性,提升了测试用例质量。同时,通过B 组人员统计出的结果表明,测试用例推荐的准确率能够满足测试人员要求。
4 结语
本文将历史测试项目的测试需求、测试用例等数据进行有效组织与利用,使用测试文本数据对Bert 语言模型进行微调,获取到测试数据语义向量表示,以此计算测试文本语义相似性从而实现测试用例复用,提高了测试用例设计效率与测试用例质量。后续工作中,将采用一种孪生网络结构[14],结合Bert 系列语言模型研究相似度计算参数的最优取值以提升测试用例复用效果。同时,通过提取关键词[15]用于测试推荐,进一步提升测试用例推荐复用准确性。
