需求驱动的云平台产品关键设计特征识别方法
2022-01-06苏兆婧余隋怀初建杰于明玖黄悦欣
苏兆婧 ,余隋怀 ,初建杰 ,于明玖,宫 静,黄悦欣
(西北工业大学 工业设计与人机工效工信部重点实验室,陕西 西安 710072)
0 引言
服务化和信息化是当前设计制造业发展的两大趋势[1-2],云设计服务平台在为用户带来大量服务的同时,也产生了服务与用户需求的匹配问题:对于一些来自于传统行业的用户来说,让其清楚地描述需求并不是一件容易的事情。用户只会为设计师提供一个他们心中的“美好愿景”,或简单实现方法。对于设计师而言,这种单纯依靠对用户提交材料进行需求提取与分析的方法,显然不能对所有需求进行精确定位。因此,如何获取用户潜在需求,利用平台中的海量资源和服务,为用户提供所需的满意设计服务,是目前云设计制造平台亟待解决的关键问题。
目前,国内外学者对需求驱动的设计特征识别进行了卓有成效的研究,宫华萍等[3]提出一种结合层次分析法、逼近理想解排序多属性决策法和犹豫二元语义变量的改进质量功能展开(Quality Function Deployment, QFD)模型,以评价用户需求与质量特性的关系。张付英等[4]集成层次性分析法和卡诺模型提出了面向产品可持续设计的关键模块识别方法。WU等[5]将模糊Kano模型与模糊层次分析法(Fuzzy Analytic Hierarchy Process, FAHP)相结合,用于在产品设计过程中确定用户吸引力因素的优先级。PEDERSEN等[6]使用田口质量损失函数提供一种早期需求获取方式,将获得的量化用户需求信息转化为对设计团队有用的信息。LIVERANI等[7]将QFD和六西格玛(Design For Six Sigma, DFSS)应用于多功能风扇的创新设计中,用于识别在增材设计中与客户需求有关的技术响应。
随着近年计算机技术的蓬勃发展,也出现了一些从客户评论中提取用户需求的模型,如李玉博[8]利用文本挖掘技术中基于词频-逆文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法抽取用户在线评论的关键词,对采集到的用户需求信息进行识别和表达,以实现用户需求信息向产品功能特征的转化。ANH等[9]利用TextRank算法,从在线客户评论中提取用户需求,并将其表示为适合设计师的形式。用户自然语言描述的文本信息通常不可避免地存在一些不规范的描述或歧义,为进一步精确提取自然语言描述中所包含的有用信息,文献[10]利用双向长短时记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)神经网络层的输出,即每一个标签的预测分值作为条件随机场(Conditional Random Fields,CRF)建立有监督的命名实体识别(Named Entity Recognition,NER)模型,从而快速并较为准确地对自然语言描述中的特定领域信息进行提取,对用户文本的智能化分析与挖掘起着重要作用。
综上所述,需求驱动的设计特征识别技术大致分为两大类:针对特定产品的用户需求获取方式[11-12]和利用计算机技术从文本信息中挖掘产品用户需求的方式[13-15]。当今世界已处于知识经济时代,全球以电子方式存储的数据信息正在飞速增长,传统需求获取方式例如QFD和DFSS[16]虽然能够提供较为精准的结果,但其时效性不足,无法对这些数据进行及时、有效的分析处理。近年,利用自然语言处理(Natural Language Processing,NLP)技术从产品评论中挖掘信息引起了人们的广泛关注。基于TF-IDF和TextRank等无监督的文本挖掘算法虽然能够自动地从文本中进行关键词提取,但由于其未经算法训练,提取出的结果包含过多噪声,因此需要人工二次处理。有监督的NER训练模型能够较好地解决这一问题。目前,许多学者在生物、医学领域命名实体识别领域展开了一些研究[17-19],设计领域命名实体的识别尚未得到关注。
众多云设计交易平台、电商平台等提供了庞大的语料库,为设计领域中文NER提供了庞大的数据支持。因此,本研究尝试通过建立中文NER模型来对用户最为关注的设计特征进行自动识别,这也是NER任务在设计领域的第一次尝试。在庞大的语料库支撑下,经算法训练,能够在用户提交的非结构化文本数据中自动为设计师捕获有效设计信息。同时,由于特征选择算法能够从高维数据中识别关键特征,本研究利用智能算法构建产品隐性设计特征发现系统,从而避免在产品设计过程中的重心偏置、关键设计特征遗漏等现象。
1 问题描述与模型构建
显性产品设计特征是指用户易于察觉、易于表述的最为明显的关键设计特征。本研究从用户反馈和产品描述出发,以基于转换器的双向编码表征(Bidirectional Encoder Representations from Transformers,BERT)预训练语言模型[20]为基础,建立softmax输出层,通过训练特定领域中文NER模型,实现从用户非结构化文本中为设计师自动获取简洁、具体的显性产品设计特征的目的。
隐性产品设计特征是指用户不易察觉,但对其最终满意度产生一定影响的产品关键设计特征。针对设计特征高维度、设计特征之间冗余性强的特点,提出一种知识迁移思想,本研究将特征选择算法随机Lasso[21]引入问题研究中,构造产品关键隐性设计特征识别模型。
1.1 基于BERT的显性设计特征识别方法
1.1.1 BERT网络架构
BERT是一种基于微调的多层双向Transformer编码器,由多个Transformer层叠加组成[20]。不同于以往基于循环神经网络(Recurrent Neural Network,RNN)的Seq2Seq模型框架,Transformer在编码器和解码器中大量使用了多头自注意力机制(Multi-headed self-attention),同时借鉴了残差网络[22]结构,将输入值与输出值相结合,如图1所示[23]。多头自注意力机制计算如式(1)~式(3)所示:
(1)
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)Wo,
(2)
(3)
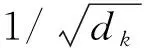
1.1.2 输入特征处理
BERT的输入是一个线性序列,支持单句文本和句对文本,句首用符号[CLS]表示,句尾用符号[SEP]表示,如果是句对,句子之间添加符号[SEP],如图2所示。输入特征由词嵌入(token embedding)、段嵌入(segment embedding)和位置嵌入(position embedding)三部分组成,分别表示单词信息、句子信息和位置信息。
1.1.3 预训练
BERT采用遮蔽语言模型(Masked Language Model, MLM)和“下一句预测”(Next Sentence Prediction, NSP)两种策略,以用于模型预训练。MLM是指在训练时从输入语料上随机遮蔽掉一些单词,然后通过上下文预测该单词。相比传统从左到右的语言模型只能单向预测目标函数,MLM可以从任意方向预测被掩盖的单词,从而可以预训练深度双向Transformer。在确定要遮蔽掉的单词之后,80%的时候会直接替换为[Mask],10%的时候将其替换为其他任意单词,10%的时候会保留原始样貌。

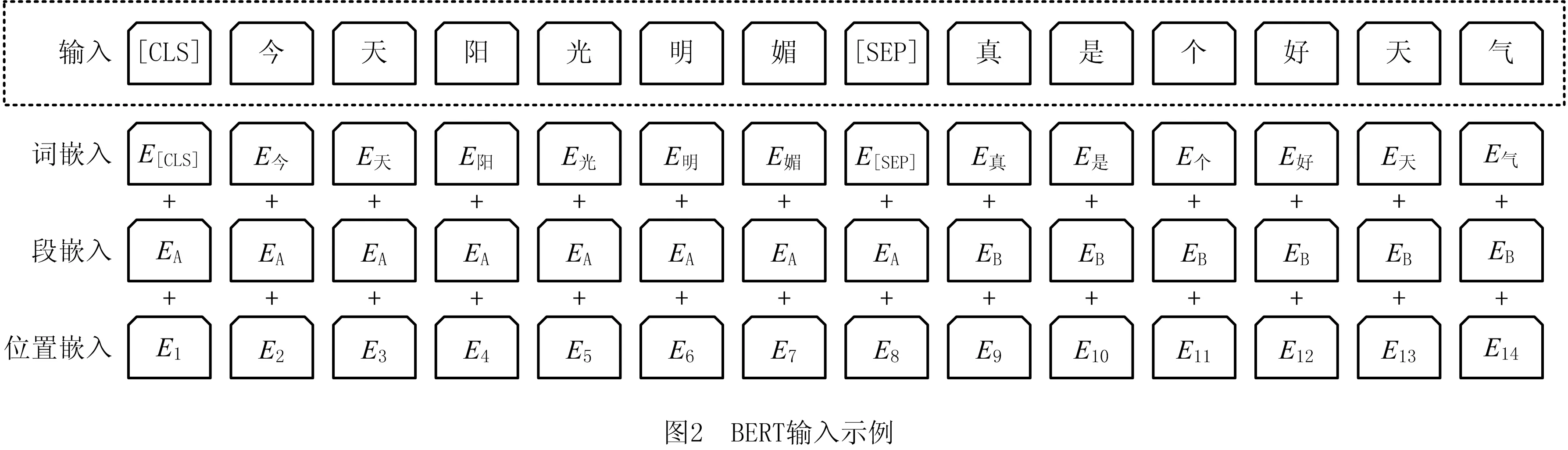
NSP的任务是判断句子B是否是句子A的下文。若是,则输出“是下一句”,否则输出“不是下一句”。训练数据的生成方式是从平行语料库中随机抽取连续的两句话,其中50%的句子对中,句子B是句子A的下文,即符合上下句关系,另外50%的句子B是随机从预料中提取的,它们不符合上下句关系。该关系保存在图2中的[CLS]符号中。
1.1.4 任务微调
在海量单预料上训练完BERT之后,便可以将其应用到NLP的各个任务中,只需在BERT的基础上添加一个输出层便可完成对特定任务的微调。对于本研究中的NER任务,判断一个句子中的单词是不是产品名称、产品结构、功能属性、外观属性或是非命名实体,系统接收标记好的文本序列,在每个时间片输出一个概率,最后通过Softmax预测单词或短语的实体类别。
1.1.5 评价指标
对NER系统的发展来说,系统的全面评估必不可少,许多系统被要求根据其标注文本的能力来对系统进行排序。实验评价指标体系由准确率(Precision)、召回率(Recall)以及综合评价指标F1值(F1Measure)构成[24]。
1.2 基于随机Lasso的隐性设计特征识别方法
随机Lasso算法突破了Lasso算法的一个重要局限:它只能选择一组高度相关的重要变量中的一个或几个,其他系数都压缩为0。随机Lasso算法最终选出高度相关变量中的大部分,甚至全部。利用随机Lasso进行特征选择主要分为两步,在每个步骤中,Bootstrap法产生的每一个Bootstrap 样本能够产生与从相同分布中生成的数据集相类似的扰动,具体地:
(1)计算所有系数的重要性度量
步骤1利用Bootstrap方法,从原始训练数据集中有放回地抽取B个样本量为n的样本。
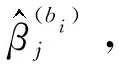
步骤3依照式(4)计算特征Xi的重要性度量Ij,其中j∈{1,2,…,p},Cj为特征Xi在B个Bootstrap样本中被选取的次数。
(4)
(2)特征选择
步骤4与步骤1相同,从原始训练数据集中有放回地抽取B个样本量为n的Bootstrap样本。

(5)
2 实验验证
本研究基于Python编程语言,分两个模块进行:①设计领域中文NER模块,即产品显性设计特征识别模块,以Pytorch作为深度学习框架;②特征选择模块,即产品隐性设计特征识别模块,该模块运用机器学习库Scikit-learn编程实现。
2.1 数据准备及其预处理
无论是对于深度学习任务还是机器学习任务,实验数据集准备是其基础条件[25]。
2.1.1 工业设计NER语料库构建
在工业设计领域NER语料库的构建过程中,使用了轻量级爬虫框架Scrapy,在某电商网站上爬取销量在前的热门产品评论。利用Scrapy框架爬取产品评论的整体流程如图3所示。

Scrapy框架包括引擎、调度器、下载器、爬虫、项目管道、下载器中间件、爬虫中间件、调度中间件。其中:引擎用来控制整个系统的数据处理流程,并进行事务处理的触发;调度器用来接收引擎发来的请求,压入队列中,并在引擎再次请求的时候返回;下载器用于下载网页内容,并将网页内容返回给爬虫(Spider);爬虫用于从特定网页中提取自己需要的信息;项目管道负责数据的存储和过滤;下载器中间件位于Scrapy引擎和下载器之间的框架,处理Scrapy引擎与下载器之间的请求及响应;爬虫中间件介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出;调度中间件介于Scrapy引擎和爬虫之间的框架,用于处理蜘蛛的响应输入和请求输出。
本实验以4种产品为例,爬取并初步构建产品领域中文NER语料库共243 958字,将其中的209 079字划分为训练集,18 453字划分为验证集,16 426字为测试集,部分原始语料如图4所示,语料库基本信息如表1所示。


表1 产品领域命名实体识别语料库基本信息
根据对语料库的初步观察和分析,结合领域专家知识以及主流领域文献[26-27]中名实体类别的数目。本文定义了以下5种产品领域命名实体类别:产品名称、产品结构、功能属性、外观属性以及非命名实体。实体分类及示例如表2所示。

表2 产品领域命名实体分类
语料库的标注问题是NER任务需要解决的第一个问题。需要对一个序列的每一个元素标注一个标签。一般来说,一个序列指的是一个句子,而一个元素指的是句子中的一个词。目前较为流行的方法有BIO、BIOES、BMES等,本研究采用BIO标注方法,即将每个元素标注为“B-X”、“I-X”或者“O”。其中:“B-X”表示该元素所在的片段属于X类型并且该元素在该片段的开头,“I-X”表示该元素所在的片段属于X类型并且该元素在该片段的中间位置,“O”表示不属于任何类型。本研究采用的标签集如表3所示。
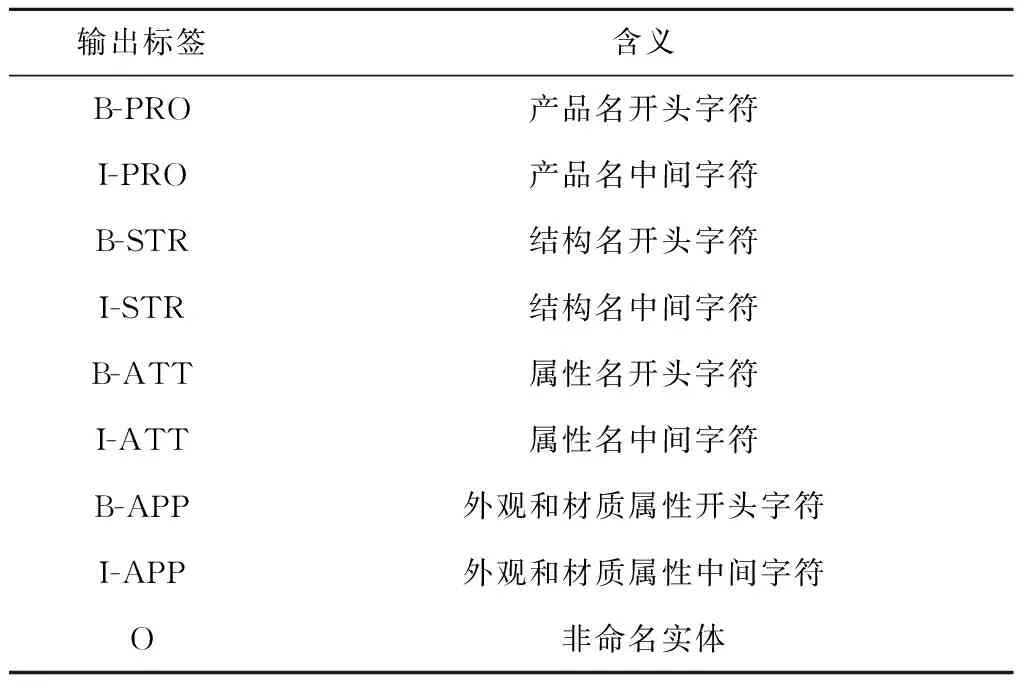
表3 标签集
所有语料均由人工独立标注完成,工作量大,耗时较久,因此数据规模并不是很大。在标注过程中,借助了一款轻量级文本标注工具:YEDDA[28]的帮助来加快标注速度,语料标注过程如图5所示。
通过编写脚本进行语料格式转换,标注后以及最终得到语料数据集的具体形式如图6所示。表4详细记录了Design-NER数据集的详细信息。
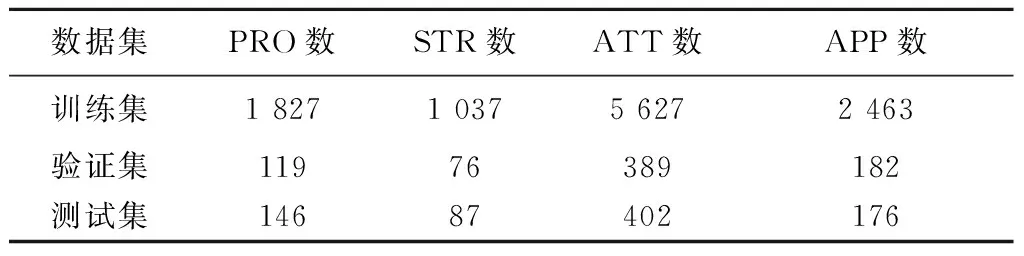
表4 Design-NER数据集


2.1.2 产品设计特征数据集构建
为有效识别设计师和用户不易察觉,但影响产品用户满意度的关键隐性设计特征,避免在产品设计过程中的重心偏置、关键设计特征遗漏等现象。本研究以吹风机产品为例,构建其产品设计特征数据集,特征选择数据集共涉及23款热门产品的29个设计特征,部分产品及其特征如表5所示。
如表5所示,搜集到的数据存在部分缺失现象,且数据类型存在非数值型变量。在机器学习和数据挖掘中所得到的数据,几乎不可能是完美的,很多特征对建模来说意义非凡,因此,经常出现重要的特征缺失值很多,但又不能直接舍弃特征字段的情况。此外,大多数算法只能够处理数值型数据,不能处理文字,故需将数据进行编码,即将文字型转换为数值型变量。将数据格式转换为CSV格式后,需要对获得的数据进行多步预处理操作,预处理步骤如图7所示。

表5 产品设计特征数据集

本研究使用众数来填补过热保护变量,使用均值填补重量和电源线长两项变量。此外,在机器学习中,大多数算法只能处理数值型数据,因此,必须对数据进行编码,即将文字型数据转换为数值型。数据集中智能功能、按钮排布方式等属于名义变量,不同变量取值间相互独立,不存在数值关系,不能计算,故无法简单地将其按照有序变量的[0,1]编码方式对其进行编码,即有智能功能编码为0,无智能功能编码为1。诸如此类的名义变量,只有使用独热(One-Hot)编码,将特征转换为哑变量的方式来处理,才能尽量向算法传达最准确的信息,如图8所示。

2.2 实验过程及结果验证
2.2.1 基于BERT的设计领域命名实体识别
进行模型训练时,需根据实际要求将训练集、验证集、测试集数据分别放入指定位置,并在数据集配置文件中加入个人数据集描述配置。实验开发环境为Ubuntu16.04,基于Titan X GPU进行模型训练。综合考虑样本数量和硬件情况,同时为了防止模型过拟合,采用了早期停止训练策略,在进行多次参数调整后,网络参数确定如表6所示。
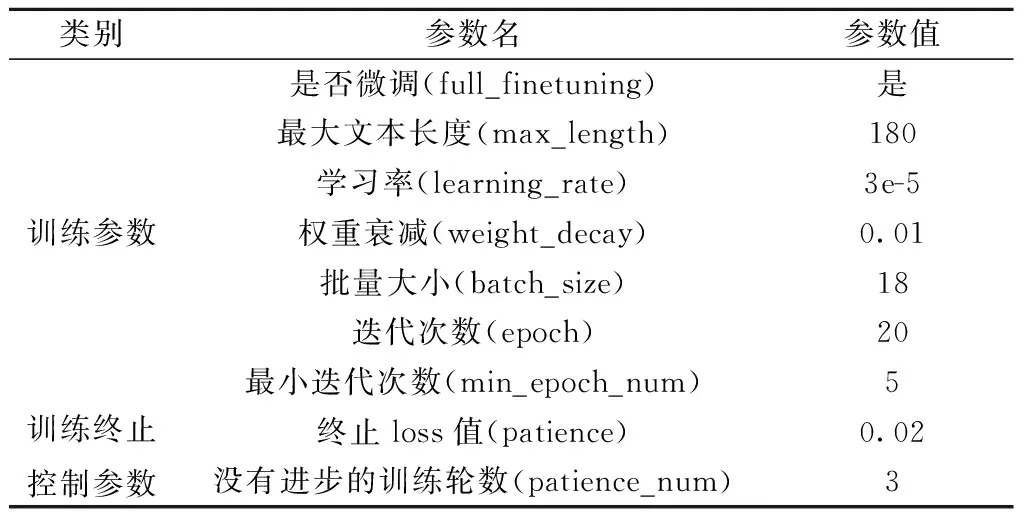
表6 网络参数设置
迭代11次后,模型在验证集中的F1分数已经3次没有呈现上升趋势,同时在验证集上的loss值为0.02,即达到训练终止条件。此时,在训练集、验证集、测试集上均可以实现较好的性能,其精确率、召回率、F1分数如表7所示。

表7 实验结果
模型在线测试的结果如图9所示。由图可知,该模型能够在云服务平台订单量较大,用户语言较繁琐时自动地从非结构化语言文本中识别出用户的显性设计需求,实时地转换为产品类别、结构、功能属性、外观和材质等设计语言,进一步提升需求与服务的匹配效率。

2.2.2 基于随机Lasso的产品关键隐性设计特征识别
对于产品关键隐性设计特征识别模块,本研究提出一种知识迁移思想,利用网络平台海量数据来识别用户不易察觉但能够对其满意度产生一定影响的产品设计特征,该模块实验软件配置如表8所示。

表8 实验软件配置
综合考虑评价得分与销量,将标签定义为Label=10[Score-int(Score)]+1e-5salesvolume,经特征选择算法随机Lasso运算,得到各设计特征及其重要度权重如表9所示。
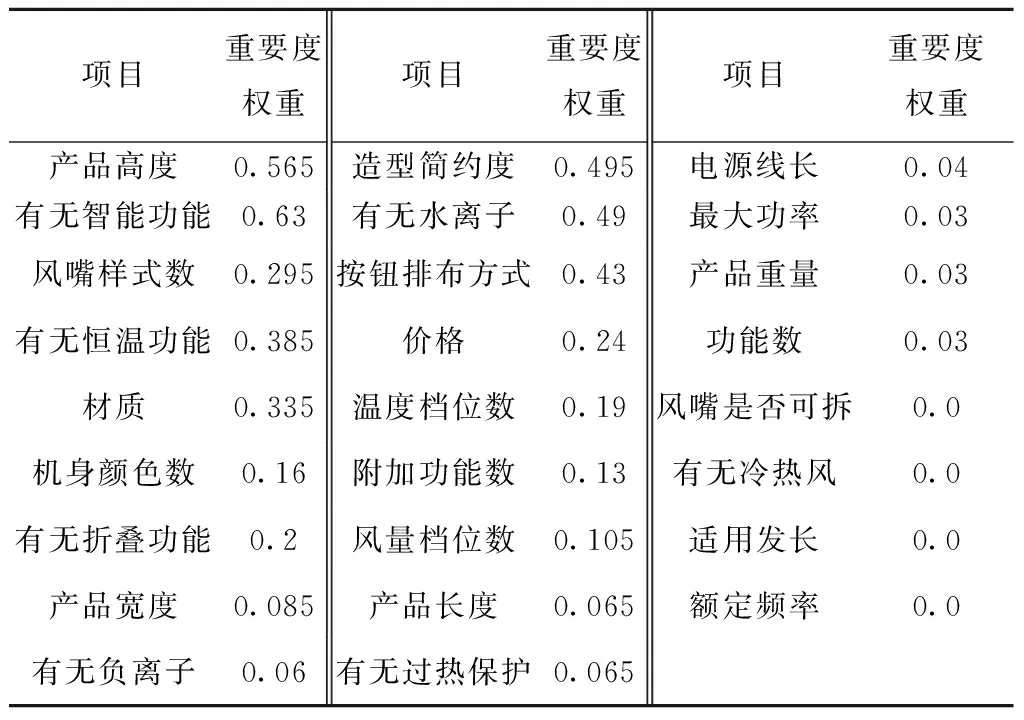
表9 特征及其重要度权重
由表9可知,在本研究所采用的吹风机示例中,影响其销量及用户满意度的关键产品设计特征为:产品高度、有无智能功能、造型简约度、有无水离子功能等。由此可见,普通用户所能表达的信息量有限,在这种情况下,运用知识迁移思想,对其需求进一步补充尤为重要。在当前大数据环境下,利用智能算法构建产品关键隐性设计特征发现系统,考虑设计特征的先后主次、设计成本和效率的问题,有助于设计人员在设计过程中关注关键设计参数和信息,并根据它们与产品功能、用户满意度的密切关系,快速获得设计方案。
3 讨论
为检验BERT 模型对传统词向量表示方法的提升效果,基于原始数据集进行Bi-LSTM+CRF与BERT模型的对比实验,实验结果如表10所示。可以看出,对比无迁移的Bi-LSTM+CRF模型,使用BERT 预训练模型进行知识迁移的方法,F1值整体提高了2.93%。该模型将自然语言编码成字嵌入、词嵌入和位置嵌入,同时输入基于Transformer结构构造的双向编码器网络,充分考虑上下文信息对实体的影响,能够满足产品领域命名实体识别任务的一般需求。

表10 对比实验结果
同时,采用Lasso算法构建产品关键隐性设计特征识别模型,在相同参数取值下,重要度权重除产品最大功率,产品长度、宽度、重量、造型简约度、价格外,其余系数均被压缩为零。相较于Lasso算法,所提方法能够为设计者提供更为详细的产品设计特征重要度权重参数。因此,能够在设计过程中根据成本等客观条件的限制灵活考虑设计特征的数量及其重要度。在客观条件允许的情况下,尽可能地减小设计结果与用户满意之间的偏差。
此外,本研究也存在一定的局限性与可提升空间。作为基于智能算法构建的产品关键设计特征识别系统的第一次探索性尝试,受人力等资源的限制,本研究仅以代表性家电产品为例进行挖掘。经实验证明,本文所提研究方法可行。因此,在人力、财力、时间等条件充裕的情况下,尽可能地增加研究样本数量使其涵盖更为广泛的产品种类能够使本文的研究更具说服力,这同时也是后续研究的关注点之一。
4 结束语
本文提出一种基于BERT和随机Lasso的产品关键设计特征识别方法。以特定领域命名实体识别任务的形式实现了产品关键显性设计特征的自动获取,这将推动自然语言处理技术在处理设计领域文本的发展,实现机器代替设计师从用户反馈数据中抽取关键设计特征的工作。同时,提出知识迁移思想,借助大数据的优势,利用智能算法构建产品关键隐性设计特征发现系统,为今后的研究提供了新思路。未来将考虑增加研究样本数量,使其能够涵盖更为广泛的产品种类,以及知识抽取的其他两个方面:实体关系抽取(Relation Extraction,RE)和属性抽取(Attribute Extraction,AE)。
