图像半自动标注研究与微服务系统设计
2022-01-06郑宗超陈雷放刘一鸣
郑宗超,陈雷放,刘一鸣,时 斌,魏 伟
(1.中国石油大学(华东)计算机科学与技术学院,山东青岛 266520;2.青岛农业大学理学与信息科学学院,山东 青岛 266109;3.华北电力大学(保定)电气与电子工程学院,河北 保定 071003;4.青岛海尔空调电子有限公司,山东青岛 266100;5.青岛海尔智能技术研发有限公司,山东青岛 266100)
人工智能正在改变着人类的生活,作为人工智能的一个应用方向,机器视觉[1]也发挥着重要的作用。机器视觉系统往往需要大量标注好的图像作为训练数据进行训练来达到对图像的识别效果。传统的图像标注工具如LabelMe、精灵标注助手等不支持自动或半自动标注以及分工式标注,标注效率有待提升。因此文中提出通过图像分割[2]算法进行半自动图像标注,针对图像标注过程的耗时操作对标注过程进行相应优化,并设计出基于微服务[3]的众包式图像标注系统,以达到高效率标注图像数据的目的。综合考虑图像分割效率和适用性,系统选择基于图论的经典图像分割算法GrabCut[4]作为交互式图像标注算法的基础,结合系统图像标注任务划分以及标注过程操作简化设计,以提高图像的标注速度和精度。基于微服务架构设计标注系统,以方便系统各模块的充分解耦,提高系统的鲁棒性及可维护性。
1 交互式图像半自动标注实现
1.1 图像标注模式优化
传统图像自动或半自动标注方法一般包含两个关键步骤,首先根据图像特征对应的文本关键词训练分类器,对待标注图像进行标注时,通过相应的图像分割算法分割目标实例,经过特定处理后转化为向量输入到分类器打标签,这样就完成了待标注图像与相对文本关键词的对应,标注流程如图1 所示。该方法的缺点是对于待标注图像集,需根据已知文本关键词建立分类器,对于未知类别的图像目标实例不能进行自动标注。而大数据环境下,图像中目标实例包含大量的关键词,并且通常情况下图像中存在多个不同子区域,而不同子区域对应不同的文本关键词,这就使得依赖于分类器的图像标注系统在多数情况下并不适用。

图1 标注流程
考虑到传统半自动标注系统[5-6]标注模式的不足,文中设计了一种通用标注模式,不需要事先训练相应的分类器,并且避免了受限于几种确定的关键词。如图2 所示,基于一个标签集(由图像集中每张图像对应的全部类别标签组成),系统根据用户输入的全部关键词建立标定组,每个标定组只标定一类目标,所有标定组的标签合并成标签集,标签集包含了图像集中全部实例及关键词的对应关系。这样设计使系统具有较好的伸缩性,各类标签经用户一次输入,在系统自动打标签功能支持下标注过程无需人工指定标签,可以满足各种关键词的标注,而不需要训练分类器,也避免了受限于分类器的能力。由此图像自动标注过程可以转化为图像分割过程。基于该设计模式,图像标注的关键在于图像分割算法的选择,算法效果决定了标注结果的优劣。

图2 分组标注模式
1.2 基于GrabCut的交互式标注实现
基于提出的标注模式,可以将图像标注的问题看作交互式图像分割的问题进行处理。在计算机视觉领域,图像分割一直是其中一个重要的课题。所谓图像分割就是把图像通过某些特征划分成不同的子区域,其中每个子区域的像素表现出较高的相关性,如图像中目标与背景的分割。二十世纪后期以来,大量的研究人员在该领域做了大量的工作,也建立了一系列理论和方法,其中经典的GrabCut 算法是一种基于图论的图像分割方法,能够以用户选择的区域为前提进行目标的像素级分割。该算法基于图像像素点、给定的前景终端节点S 及背景终端节点T建立带有权值的无向图,转换过程如图3 所示。
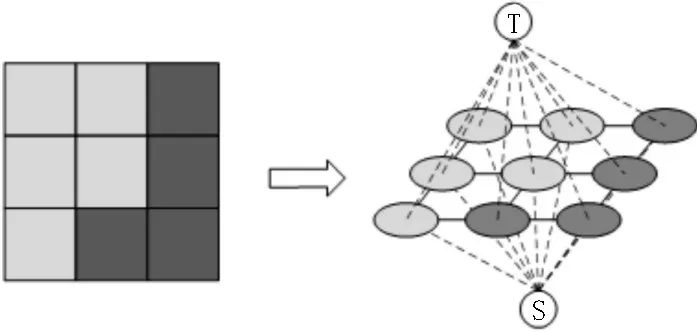
图3 图像转带权无向图
无向图G=<V,E>包含两种边,一种是普通像素之间的边n-links,另一种是每个像素与人为假设的两个终端节点之间的边t-links,以像素为节点和以上两种边建立图像的带权无向图后,根据Boy-kov和Kolmogorov 提出的max-flow/min-cut 算法[7]就可以获得s-t 图的最小割,算法通过求解图的最小割将像素点划分成属于前景和背景的两个不相交区域,图的最小割通过最小化能量函数求解。
GrabCut 算法通过使用一个包含K个高斯分量的GMM 混合高斯模型[8]对图像目标和背景进行建模,图像采用RGB 颜色空间。对于图像中的一个像素,其必然来自目标GMM 或者背景GMM 的高斯分量。于是有向量:
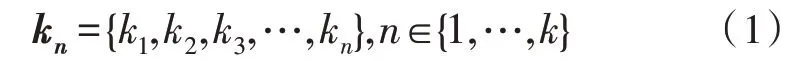
式(1)中,kn代表第n个像素对应的高斯分量。图像的Gibbs 能量表示为:

U代表区域项,V表示边界项。区域项表示像素被归为目标或者背景的惩罚,由像素属于目标或背景的概率负对数累加得到,而图像属于目标或者背景的概率由混合高斯密度模型给出,由此得到区域项的表达式:

其中,描述GMM 的3 个参数:高斯分量的权重、每个高斯分量的均值以及协方差矩阵都需要通过学习得到。学习得到以上3 个参数后,就可以通过将像素向量代入目标和背景GMM 得出像素输入目标或者背景的概率值,由此能够确定区域项U。边界项V的定义如式(4)所示:
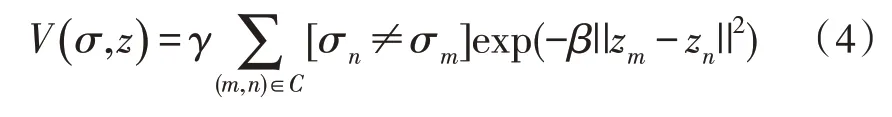
边界项V表示相邻像素间不连续的惩罚。如果相邻两个像素的差别较大,那么它们分别属于目标和背景的概率就比较大;如果差别较小,那么它们同属于目标或者背景的概率则较大。建立起图像的Gibbs 能量函数后,接下来通过选定一个包含目标的区域作为初始的目标区域,区域内像素标签为1,即为可能的目标像素;框外的像素为初始的背景区域,区域内像素标签为0,即为背景像素。经过人为划分目标及背景后,通过K-means[9]算法将属于目标和背景的像素划分为K类,即GMM 中的K个高斯模型,通过这K个像素集合初始化每个高斯模型的未知参数,从而估计出目标和背景的GMM;得到目标和背景的预估GMM 后,通过迭代最小化Gibbs 能量函数不断优化GMM 的参数,直到找到图的能量最小割,而最小割将图像中目标与背景划分成不同的区域就完成了目标的分割。
1.3 基于关键点的目标区域选择
手动添加目标边界框是一个非常耗时的操作,目前流行的标注工具如LabelMe、精灵标注助手等在框选目标时都采用矩形框的方式,用户操作时要进行包括点击想象中的目标边界、拖拽形成矩形区域、调整区域几个操作,这种方式造成了不必要的时间和人力消耗。通过手动拖拽形成的矩形区域往往不能紧密贴合目标,从而影响训练效果。于是采用通过4 个关键点自动生成矩形框的方式取代拖拽生成,极大地简化了用户操作,并且能够使标注的区域更紧密地贴合目标。
如图4 所示,首先需要用户指定目标上的最左、最右、最上及最下4 个点,然后通过计算得到矩形框的位置(即左上角坐标)以及宽度和高度,再将选中的图像区域输入作为GrabCut 的目标区域,获得对目标的像素级分割。

图4 基于关键点的目标提取
由于目标的4 个顶点很容易识别,相比拖拽形成矩形框不需要用户对目标位置进行判断,也无需多次调整,所以该方式有效地缩短了手工标注时间。除目标位置外,关键点还提供目标上的4 个点,因此计算得到的矩形区域能紧密贴合目标,从而为后续GrabCut 的图像分割提供了更好的初始条件。
选取Pascal VOC 2012 数据集中的500 张图片,对其中500 个人物目标进行标注,获得表1 所示的实验数据。

表1 关键点目标获取耗时测试
实验数据表明,基于关键点获取目标边框的方法相比直接拖拽形成边框在准确度以及标注耗时两个方面都取得了更好的效果。
1.4 图像标注流程设计
基于文中图像标注模式设计,结合半自动图像标注操作,具体标注流程如图5 所示。

图5 图像标注流程
2 系统设计
2.1 总体设计
文中提出的图像数据集管理标注一体化平台提供图像集托管、众包式分工标注以及标签集的下载支持,另外提供用户管理、国际化等支撑功能。根据功能的不同,将系统划分为图像集管理模块、标签集管理模块、图像存储模块、数据导入导出代理、半自动标定代理、标注算法模块、用户及授权服务模块。系统架构如图6 所示。
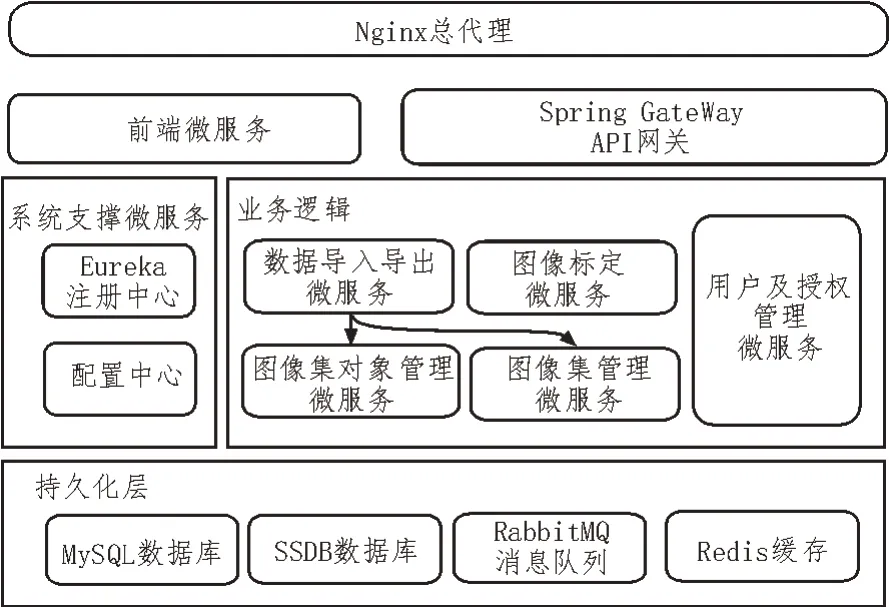
图6 标注系统架构
2.2 详细设计
系统采用微服务架构,将主要功能模块划分成单个微服务,前后端分离,运用服务注册与发现[10-11]机制实现服务间调用,并通过服务网关[12]提供服务的唯一入口,保障了系统安全。
2.2.1 服务注册与发现
系统选择Spring Cloud[13]作为微服务框架,采用Eureka 作为服务发现组件。微服务系统的服务注册与发现机制主要包含3 个组成部分:服务注册中心、服务提供者和服务消费者。具体实现方式如下。
服务注册中心微服务需引入Eureka 相关依赖,基于注解使该服务作为注册中心生效,通过配置服务端口号和注册中心地址,使各微服务注册到该注册中心上。当某个服务调用其他微服务时便可以通过注册中心发现并调用其他微服务。项目引入依赖spring-cloud-starter-netflix-eureka-server,并在启动类上添加@EnableEurekaServer 注解,然后配置注册中心,在appliaction.yml 中添加如下配置:

服务提供者微服务的实现需引入的依赖是spring-cloud-starter-netflix-eureka-client,然后进行相关配置,将服务本身暴露给其他服务,从而实现接口调用。appliaction.yml 配置如下:

服务消费者配置方式与服务提供者相同。
2.2.2 API网关
微服务架构的应用被拆分成一定粒度的微服务,单体应用客户端的请求被负载均衡器分发到多个相同后端实例中的一个,如果将后端服务全部暴露,势必引发多种问题。服务网关为微服务应用提供一个唯一的入口,请求通过服务网关微服务分发到后端具体的微服务上,保障了后端服务的安全性。系统采用Spring Cloud Gateway 实现服务统一入口,基本实现原理如图7 所示。
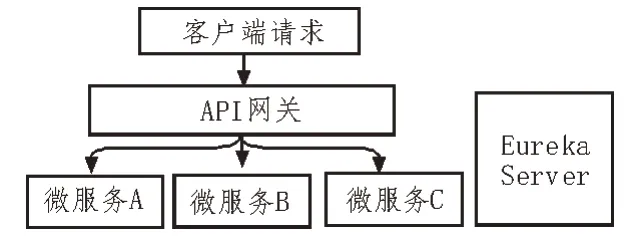
图7 API网关基本实现原理
每个微服务注册到服务发现Eureka Server 上,API 网关通过配置完成前端请求的路由转发,将请求转发至后端对应的服务上。以用户管理微服务为例,单个服务提供者的API 网关路由配置如下代码示例所示,可根据此配置方式配置多个微服务路由。

2.2.3 系统后端接口测试
项目采用了前后端分离设计,前端采用Vue.js[14]框架结合桩服务器Mock-Server 与后端并行开发。开发中使用Postman 进行接口的测试,Postman 内嵌了OAuth2[15-16]的认证模型,通过配置可实现一系列共用认证服务的API 同时获得登录认证的功能。
2.3 系统功能测试
以图像训练数据集制作流程为例,首先需要将图像导入,上传完图像集压缩包后后端转入异步解压处理流程。上传成功后可以根据导入的图像集创建标签集,标签集可以包含多个类别,每一类划分为一个标定组。标定组可划分成多个标定任务分配给指定用户。每个被分配任务的用户将得到一个由一组图像和指定类别组成的标定任务。任务分配时可指定任务所有者以及必须完成的期限。
在用户的标定任务页面可以看到相应的标定任务列表。标定任务管理页面如图8 所示。
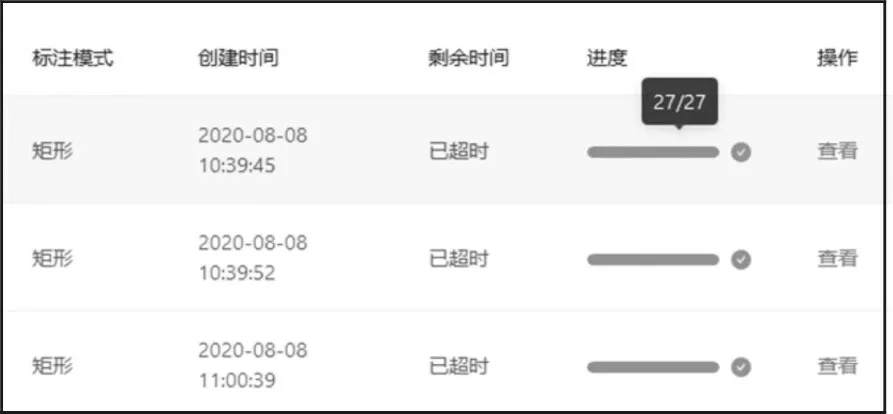
图8 标定任务管理页面
由标注任务列表可进入相应任务的标注操作页面,如图9所示。用户只需根据提示标注指定目标,而无需手动添加标签。考虑到在复杂场景下图像前景与背景的模糊界限会导致分割结果精度的下降,图像标注页面提供了手动图像标注的完整操作流程,用户可通过拖拽进行多边形标签的形状调整以及通过双击进行标签删除,另外可通过滚轮缩放和移动图像。

图9 图像标注界面
系统半自动标注效果如图10所示,用户通过指定目标的4 个关键点,然后系统自动计算出目标所在最小矩形框,矩形框作为图像分割算法的输入,经图像分割获取指定类别的目标轮廓,并自动添加类别标签。

图10 图像半自动标注效果
标注过程中发起任务的用户能够查看各用户的标注进度与当前已标注图像的标签统计信息。待每个标定组所划分的各标定任务标注完成后由系统合并多类标签得到完整标签集。任务发起者可以在标签集详情页保存相应的标签集压缩包至本地。以VOC XML格式为例,最终导出的标签集如图11所示。

图11 标签集
3 系统标注测试
为测试系统标注效果,找5 名测试人员基于Pascal VOC 2012 数据集随机选取的2 000 张图像进行测试。每张图像标注一个实例。首先让测试人员使用常见传统标注工具进行标注,然后让测试人员用系统进行半自动标注,实验结果如表2 所示。

表2 系统标注效果测试
实验产生了几种不同标注方式的实验数据,包括IoU 均值、IoU >0.7%、总耗时及单张耗时。结果表明,在使用提出的半自动标注系统进行标注时,在标注速度上有了大幅度提升。从IoU 指标来看,生成的标签相对手动标注不会造成精度的降低。经系统实际测试表明,在实际使用中,可以以算法标注为主,手动调整为辅,可以使标注更加精确,并且节省大量的时间和人为操作。总体来说,系统的半自动标注大幅度提升了图像数据集的标注效率和质量。
4 结论
在机器视觉系统训练中,以人工标注的方式进行图像训练数据集的标注是非常耗时耗力的一项工作。在某些要求标注精度较高的情况下,一张图片可能耗费一个人几十分钟的时间,如此一来,数据集标注的成本可想而知。因此,文中调研了图像标注的实际需求,结合图像分割算法,设计了一种半自动图像标注系统,经实际测试,设计的系统大幅度降低了图像标注的人力成本和时间成本,在计算机视觉领域具有较高的应用价值。
