基于IIGA-BP神经网络的钢材销售预测模型①
2022-01-06陈永当曹坤煜
陈永当,曹坤煜
1(西安工程大学 机电工程学院,西安 710600)
2(西安市现代智能纺织装备重点实验室,西安 710600)
随着企业市场化进程的不断推进,企业间的竞争压力及销售市场的不稳定程度与日俱增.如何合理、准确预测产品的市场需求,已成为现代企业控制产能,有效规避经营风险,实现精准营销的重要举措[1].因此销售预测是现代企业经营管理中不可或缺的环节,预测的准确性也直接关系到企业生产经营的成败.为准确预测企业在未来时间内的销售量,国内外学者再度掀起了对预测模型的研究.
近年来,国内外学者针对预测模型进行了大量研究,并相继提出了神经网络、极限学习、机器学习、时间序列模型等销售预测方法[2-4].神经网络因其具有强大的自适应学习能力和较好的非线性拟合能力,而被广泛应用于销售预测模型的构建[5].其中,最具代表性的BP神经网络(BP Neural Network,BPNN)因其完备的理论体系已逐渐成为学者们关注的重点.如:吴正佳等[6]针对备货型企业的销售情况,利用BPNN强大的学习和存贮信息的能力,建立了基于BPNN的销售预测模型.Qin等[7]通过选取网络类型在制定网络参数优化机制的基础上,提出了BPNN销售预测模型.高文等[8]采用logsig激励函数,在对影响因素数据收集与降维处理的基础上,建立了基于BPNN的预测模型.Bibaudalves等[9]以数据的季节性与价值性为导向,提出了一种采用月平均值具有最佳结构的神经网络销售预测模型.但由于易陷入局部极值和对初始网络权重敏感性强等问题是BPNN难以避免的不足,对此,学者们提出了许多优化BPNN的有效方法.如:查刘根等[10]利用免疫算法优化BPNN的初始权值和阈值,提出了基于免疫遗传算法的BPNN预测方法.郑建刚等[11]提出了一种改进的免疫遗传算法,扩大了BPNN模型中权值的搜索空间,提高了BPNN的学习效率和精度.Cheng等[12]提出了一种基于自适应免疫遗传算法优化BPNN的网络流量预测新方法.朱玉等[13]提出一种基于IGA的BP网络应用于煤与瓦斯的突出强度预测.Yang等[14]采用免疫遗传算法优化BPNN的权值,建立了用电量增长率的神经网络预测模型.张浩等[15]提出了一种自适应免疫遗传算法优化的BP神经网络用于粮食产量预测研究.Wang[16]运用免疫遗传算法优化神经网络,进行电力负荷预测.Yun等[17]提出了一种基于父辈免疫遗传算法的碳钎维性能预测神经网络模型.王华强等[18]将用免疫遗传算法全局寻优和BP网络局部寻优相结合提出了IGA-BP网络模型并应用于高炉铁水硅含量的预测.Huang[19]将免疫遗传算法与小波神经网络相结合,实现了对离心式压缩机性能的预测.付传秀等[20]将免疫遗传算法与BP神经网络相融合,对中国区域经济协调发展水平进行预测.这些采用免疫遗传算法优化BPNN的研究,在一定程度上解决了BPNN的不足,但由于免疫遗传算法自身存在着早熟收敛和种群质量低下等问题.因此只有在进一步改进优化的基础上才能更好的解决BPNN的预测问题.
综上所述,BPNN虽然在销售预测方面取得较好的效果.但由于传统BPNN利用梯度下降原理对网络参数进行调节,存在收敛速度慢、易陷入局部最优的缺点,且该算法初始权值和阈值的随机选取致使神经元缺乏调节能力,基于此本文提出了改进免疫遗传算法与传统BP神经网络模型于一体的有效的神经网络销售预测模型.利用改进的免疫遗传算法(Improved Immune Genetic Algorithm,IIGA)中特有的种群初始化方式、抗体浓度调节机制及交叉算子、变异算子自适应调节策略解决免疫遗传算法(Immune Genetic Algorithm,IGA)的早熟收敛问题,进而初始化BPNN各连接层的权值和阈值,改善网络参数随机性导致BP神经网络输出不稳定和易陷入局部极值的缺点,从而提高算法的收敛速度和模型的预测精度.
1 改进免疫遗传算法优化BP神经网络设计
1.1 BP神经网络
BP神经网络是含有一个或多个隐含层的多层前馈神经网络,其较强的非线性拟合能力是解决不确定性问题的数学模型.它采用逆向传播算法基于梯度下降原理以监督学习的方式实现模式识别和函数逼近功能,是目前应用最为广泛的神经网络[21].最为典型的3层神经网络结构,可以实现任何函数输入到输出分布式并行信息处理的高度非线性映射,通过数据信息的正向传递和误差的反向传播按一定的规则不断调整权值阈值,修正网络误差,直至输出误差或训练次数满足预定条件,如图1.该网络结构具有一个隐含层,输入节点数为xm,输出节点数为yn;wij、wjk分别为各连接层间的权值向量;θj、ςk分别为隐含层与输出层的阈值向量.
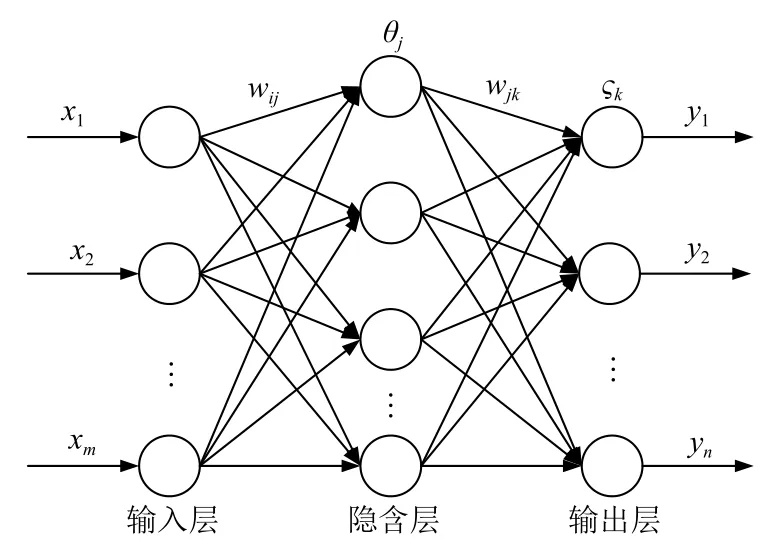
图1 BP神经网络结构图
1.2 改进免疫遗传算法优化BP神经网络原理
免疫遗传算法是一种模拟生物免疫原理和遗传进化过程的新型进化优化算法,是具有免疫功能的遗传算法.通过在免疫算子中加入遗传算子,兼顾搜索速度与搜索能力的同时,又避免了遗传算法的退化现象及早熟收敛问题.它将需要优化的参数编码形成串联群体,通过免疫遗传进化操作,将种群进化到更好的搜索空间,使种群中的个体达到最优[22].免疫遗传算法较为突出的寻优能力和种群多样性保持机制,正好弥补BP神经网络的不足,但标准免疫遗传算法在处理复杂优化问题上仍存在收敛速度慢和局部极值问题.因此,考虑改进免疫遗传算法对BP神经网络进行优化.
本文采用改进免疫遗传算法从以下3个方面优化BP神经网络:
(1)确定网络拓扑结构
(2)优化BP神经网络初始权值和阈值
以种群中最优抗体的适应度为导向利用免疫遗传算法寻优,得到全局适应度最高的一组网络参数即为初始权值和阈值.
(3)仿真预测
将得到的初始权值和阈值,回代BP网络在训练期间再次局部寻优,获得最优权值阈值,进而实现最佳预测输出.
1.3 改进免疫遗传算法优化BP神经网络过程
先对免疫遗传算法的种群初始化方式、抗体浓度的调节机制及交叉算子、变异算子的自适应调节策略进行改进.用改进的免疫遗传算法以种群中最优抗体的适应度值为导向进行全局寻优,定位最优解的参数空间,再用BP算法的局部寻优能力通过Bayesian函数对网络权值和阈值进行精调,使网络输出值逐步逼近期望值,最后经过反归一化得到预测值.采用改进免疫遗传算法优化BP神经网络算法流程,如图2.
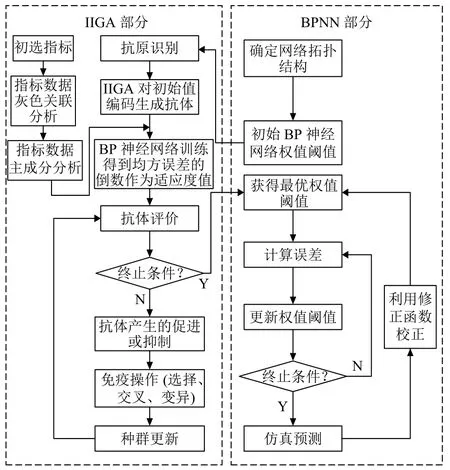
图2 改进免疫遗传算法优化BP神经网络算法流程图
具体步骤如下:
(1)确定网络拓扑结构
(2)抗原识别
抗原对应问题的目标函数即网络预测的均方误差最小.


(3)产生初始抗体
为避免初始权值阈值随机化,计算效率较低的弊端,在保证种群多样性的同时加快算法收敛速度.本文先采用Nguyen-Widrow方法[23]产生70%初始种群;剩余30%,采用多次进化随机生成的方法,在每次生成的抗体群中只保留部分适应度较高的抗体,并将抗体群中适应度较弱的抗体,在下次进化过程中进行替代,以此为循环,直至达到随机生成的种群规模.
Nguyen-Widrow方法:

式中,w为权值矩阵,θ为阈值矩阵;s、r分别为网络隐含层节点数与输入指标的维数;rand(s,r)为s行r列的均匀分布的随机数矩阵;I(s,l)为s行r列的全1矩阵;normr(J)为J矩阵的标准化归一矩阵.
(4)抗体编码
本文采用实数编码方式对神经网络初始连接权值及阈值编码,得到随机分布的基因码串,每一个基因码串,对应一组权值阈值.
抗体编码长度为:

式中,n、m、l分别为输入层、隐含层及输出层节点数.
(5)亲和度计算
① 抗体与抗原之间的亲和度
抗体与抗原间的亲和度大小是决定抗体优劣的评判标准,以训练数据均方误差的倒数作为免疫遗传算法的原始亲和度函数即适应度函数.
适应度函数为:

为了防止进化初期,初始抗体群中的特殊抗体误导种群的发展方向.本文采用线性调整策略,对适应度函数进行调整[24].

式中,fmax、fmin分别为当代种群中最大与最小的适应度值;f为当前抗体的适应度值;f′为修正后抗体适应度值; β为调节系数.
② 抗体与抗体之间的亲和度
本文采用欧几里得距离作为衡量抗体间相似度的重要指标.抗体v={v1,v2,···,vn}与抗体r={r1,r2,···,rn}之间的欧氏距离[25]为:

亲和度为:

抗体浓度为:


(6)基于浓度的种群调节



(7)免疫操作
① 克隆选择
按照精英保留与轮盘赌相结合的策略进行克隆选择操作.在每次更新记忆库时,先将适应度较高的抗体进行保存,再按照式(10)计算出选择概率大小将种群中优秀的抗体存入记忆库.
② 自适应交叉与变异
为了使算法的交叉与变异概率能够根据种群中抗体适应度高低和算法进化代数进行自适应调整,则需对交叉和变异概率进行参数设计.

式中,f′为待交叉抗体的最大适应度值; fmax为当前种群的最大适应度值; favg为当前种群的平均适应度值;fmin为当前种群的最小适应度值; f为待变异抗体的适应度值; t为算法当前的进化代数; T为算法的总进化代数; Pc、Pm分别为交叉与变异概率的初始值.
(8)网络初始权值和阈值的确定
以种群中最优抗体的适应度为导向循环进行评价、选择、交叉、变异等操作,直到达到设定的进化代数,选择适应度最高的一组网络参数即为初始权值和阈值.
(9)仿真预测
取得初始权值、阈值后,利用BP算法进行学习,不断调整,直至满足既定的网络误差或达到最大进化代数,得到最优权值和阈值,并实现预测输出.
2 钢材销售预测模型的建立
2.1 钢材销售主要影响因素识别
钢材的销售状况受各种复杂因素的影响,以某钢铁企业的历史销售数据为例,从影响钢材销售量的众多因素中选取国内生产总值(X1)、钢材出口量(x2)、钢材进口量(X3)、房地产开发投资(X4)、金属切削机床产量(X5)、拖拉机产量(X6)、全社会固定资产投资(X7)、车辆产量(x8)、全国建筑业总产值(x9)作为初选指标.9个影响因素数据选自1994-2018年《中国统计年鉴》[26],如表1.

表1 某钢铁企业钢材销售量及影响因素数据
2.2 灰色关联分析
灰色关联分析是一种通过权衡同一坐标系中各因素序列曲线的相似程度,来判断系统中因素间的关联性.它对样本容量以及样本间规律性无特别要求,具有计算量小,精度高的特点,是研究少样本、贫信息分析和预测领域的新方法[27].本文主要采用灰色因素关联分析法对钢材销售量的主要影响因素进行识别,找出各输入因素与输出量之间的关联程度,从而提取出影响输出指标的主控因素.
具体步骤如下:
(1)确定参考序列和比较序列
根据研究需要,以表1中1994-2018年的钢材销量作为因变量Y,并记参考序列为Y={y(k)|k=1,2,···,n};钢材销售的9个影响因素分别作为自变量组,9组比较序列为xi={xi(k)|k=1,2,···,n},i=1,2,···,m.
(2)数据的无量纲化
为避免数量级差别过大而导致预测误差较大的情况,在对数据计算前需要进行无量纲化处理.本文采用均值转换法,以消除不同数据间的量纲差异.计算公式为:

(3)计算各因素与钢材销售量的关系系数

式中,Δi(k)=|y(k)−xi(k)|; ρ为分辨系数,一般取0-1.
(4)计算各因素与钢材销售量的关联度

将上述过程基于Matlab 2018a平台编写计算程序,分辨系数 ρ设定为0.5,则灰色关联分析结果,如表2.

表2 各影响因素与钢材销售量灰色关联度表

2.3 主成分分析
由表1可知原数据为多维数据,由于数据间的耦合性导致并不是所有的数据都对钢材的销售量有很高的贡献率.如果直接将使用灰色关联分析选定的指标作为预测模型的输入节点,由于实验数据的复杂和冗余,网络的性能及模型的预测精度势必会受到影响[28].为此本文选用主成分分析法对灰色关联分析选定的指标进行降维处理,确定输入指标,以减小变量间的耦合关系,保留对预测结果有价值的数据.
具体步骤如下:
(1)建立相关矩阵R
假设输入原始数据集为X,每个样本对应P个影响因素,即X=(X1,X2,···,XP).则相关系数矩阵为:


(3)确定主成分个数m(m 一般来说当累计贡献率达到75%-95%时,对应的前m个主成分就能够包含原始数据集的绝大多数的信息.方差贡献率和累计方差贡献率为: (4)计算主成分得分 式中,fbv=αv1xb1+αv2xb2+···+αvpxbp,b=1,2,···,n,v=1,2,···,m. 将上述过程基于Matlab 2018a平台编写计算程序,使用princomp函数,得出各指标因素的贡献率,如表3. 表3 影响因素的特征值及其方差贡献率 由表3可知,前3个主成分已包含了全部影响因素95%以上的信息.故选取前3个主成分代替原灰色关联分析选定的因素作为最终的输入指标.各主成分的得分值,如表4. 表4 主成分得分表 为全面验证算法性能,以某钢铁企业钢材销售量数据集为例进行验证.将主成分分析得到3个主成分的得分作为新样本,在已有钢材销售量统计的25条数据中,随机抽取18条作为仿真训练集,剩余7条作为仿真验证集,用于验证误差.算法程序是在Matlab 2018a的基础上实现,在处理器为Intel(R)Core(TM)i5-5200U CPU,RAM为4 GB,运行环境为Windows 10(64位)的个人计算机上进行仿真测试.BP神经网络隐含层传递函数采用tansig函数; 输出层传递函数采用purlin函数; 训练函数采用trainlm函数; 激活函数采用Sigmoid函数. 隐含层节点数的确定,通常先用经验公式来计算节点范围,再进行BP神经网络试算,确定准确的节点数. 式中,q、m、n分别为隐含层、输入层及输出层的节点个数; a为调节因子一般取1-10.通过不断增加隐含层节点数,以网络输出误差最小为标准,获取最佳隐含层节点数.经过反复调整,当隐含层节点数为10时,输出误差最小,网络拓扑结构为8-10-1. 实验参数设置,如表5、表6. 表5 BP神经网络参数设置 表6 免疫遗传算法参数设置 IGA模型与IIGA模型的适应度函数进化曲线,如图3. 由图3可知,改进的免疫遗传算法模型进化54代以后,优化结果的适应度函数值逐渐趋于稳定,约为2.2961,表明每个个体都在最优解附近.免疫遗传算法模型适应度函数值从76代之后逐渐稳定在1.7294左右,且进化后期曲线有振荡现象发生.表明改进的免疫遗传算法模型在优化网络参数的效果上要好于经典的免疫遗传算法模型. 图3 适应度函数进化曲线图 目标误差为10-4时,BP、IGA-BP、IIGA-BP三种网络模型训练误差曲线,如图4. 由图4可知,IIGA-BP算法,训练前期收敛速率最快,曲线最陡峭,在第5代左右摆脱局部最优解后,又快速进入稳定状态,这与本文的交叉算子、变异算子的自适应设计有关.而且,IIGA-BP神经网络经过23次进化后达到目标误差,IGA-BP神经网络经过65次进化后达到目标误差,而BP神经网络经过100次进化后训练误差收敛于6.253×10-3陷入局部最优且无法逃逸.可见,采用改进免疫遗传算法优化的BP神经网络,在提高网络的收敛速度,降低BP网络陷入局部极值的可能上具有很强的优越性. 图4 3种网络模型训练误差曲线图 为进一步比较3种模型的性能差异,验证预测模型的准确性、适用性,对BP、IGA-BP、IIGA-BP神经网络进行仿真实验,独立运行20次得到如图5、图6的仿真结果. 图5 3种网络模型预测输出对比图 图6 3种网络模型预测相对误差对比图 由图5、图6可知,BP神经网络模型和IGABP神经网络模型预测离散度和误差波动幅度都较大;IIGA-BP神经网络模型预测离散度较小,误差基本保持在[-0.25,0.25]之间,预测效果更稳定,预测精度大幅度提高. 为了更直观地显示3种模型的预测精度,采用平均绝对百分比误差(MAPE)、均方根误差(RMSE)和纳什效率系数(NSE),进一步评价3种网络模型的误差指标. 3种模型的预测值与真实值对比如表7所示.3种网络模型预测精度对比,如表8. 表7 3种网络模型预测值与真实值对比(万吨) 由表8可知,IIGA-BP神经网络模型的MAPE为0.1372相对于BP神经网络模型预测精度提高了23.82%,也优于IGA-BP神经网络模型的预测精度.与另两种模型相比IIGA-BP神经网络模型的RMSE值最小,模型的误差小,泛化能力强.IIGA-BP神经网络模型的NSE为0.9909相比其它两种模型,本模型具有更好的非线性拟合能力,预测的稳定性更高. 表8 3种网络模型预测精度对比 本文针对BP神经网络在销售预测中的不足.提出了一种改进免疫遗传算法优化BP神经网络的销售预测模型.改进的免疫遗传算法提出了新的种群初始化方式、抗体浓度的调节机制及交叉算子、变异算子自适应策略的设计方法,保证了种群多样性,提高了算法的收敛能力和寻优能力.利用改进的免疫遗传算法扩大BP网络的权值搜索空间,获得最优权值和阈值,改善了BP网络易陷入局部极值的缺点.最后通过构建IIGA神经网络钢材销售预测模型并与BP、IGA-BP神经网络预测模型进行横向测评,实验表明改进免疫遗传算法优化后的BP神经网络具有较强的拟合能力和泛化能力,在提高模型预测精度和收敛速度的同时,也简化了网络结构,降低了进化代数,预测输出的稳定性较好.但由于网络的训练数据较少,网络训练不完善,导致模型预测精度不是太高.如需深入研究,可进一步扩大训练数据集,加强模型的学习效果,提高预测精度.



3 仿真实验
3.1 实验环境及参数设置



3.2 网络性能分析

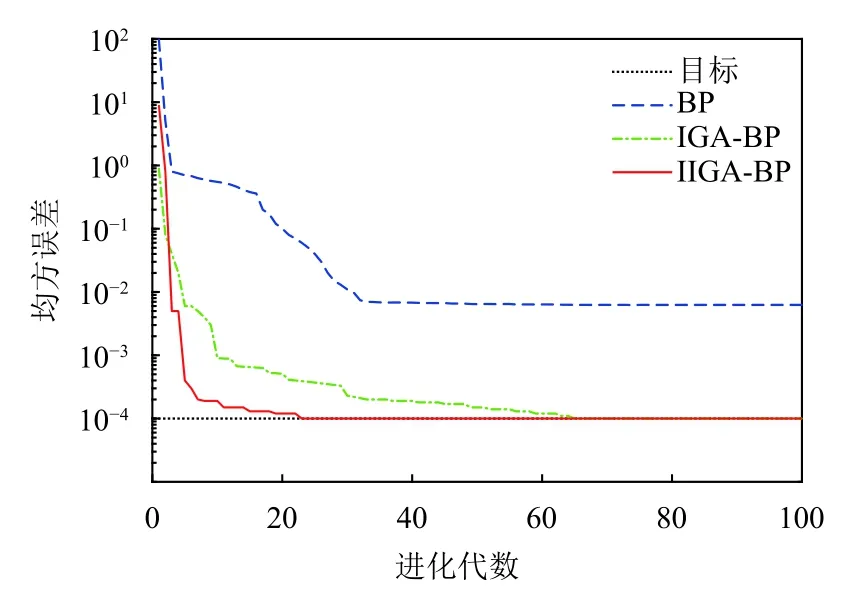
3.3 算法模型预测精度分析






4 结论
