自适应序列生成的建筑能耗预测①
2022-01-06陈建平傅启明1吴宏杰1悠1
王 悦, 陈建平, 傅启明1,, 吴宏杰1,, 陆 悠1,
1(苏州科技大学 电子与信息工程学院, 苏州 215009)
2(苏州科技大学 江苏省建筑智慧节能重点实验室, 苏州 215009)
3(苏州科技大学 苏州市移动网络技术与应用重点实验室, 苏州 215009)
4(珠海米枣智能科技有限公司, 珠海 519031)
可持续发展和低碳经济逐渐成为这一代人最重要的挑战之一[1].斯帕思(Jamm Gustare Spath)认为: “可持续发展就是转向更清洁、更有效的技术——尽可能接近“零排放”或“密封式”, 工艺方法——尽可能减少能源和其他自然资源的消耗”[2].因此, 如何减少能源消耗及碳排放量是实现可持续发展和低碳经济需要考虑的现实问题.据统计, 在世界能源消耗和二氧化碳排放方面, 建筑占比较高.例如, 2018年美国和欧洲的建筑业分别占能源消耗的39%和40%, 二氧化碳排放量占比则分别为38%和36%[3].建筑作为主要的能源消耗者,其中电能是主要的消耗部分.美国能源部(DOE) 2018年1月报告的最新月度电力数据表明, 商业和住宅建筑的电力消耗占美国所有发电量的77.5%[4].所以降低建筑电力能源消耗和减少建筑碳排放至关重要.建筑负荷曲线是指建筑物电力负荷随时间的变化曲线.建筑负荷曲线预测有很多作用, 如建筑节能策略诊断(识别不必要的浪费)、改善供应管理以及需求响应规划和定价[5].因此建筑负荷曲线预测对于合理减少能源消耗发挥着重要的作用.
由于建筑负荷曲线预测可以产生有用的信息并且应用范围很广, 早在20世纪60年代就已经开始了能源预测性能方法的研究[6].2015年Fonseca等人提出了一个综合模型来描述社区和城区的时空建筑能耗模式.该模型使用空间(使用地理信息系统、地理信息系统的建筑位置)和时间(h)维度分析计算了住宅、商业和工业部门的电力和温度需求[7], 然而, 在模拟时, 用户可能未提供准确详细的输入数据, 导致最终的预测性能偏差.另一方面, 数据驱动的建筑能耗预测模型不需要有关模拟建筑的详细数据, 而是从真实数据中学习并进行预测, 因此, 近年来数据驱动的能源消耗预测得到了大量的研究关注[8], 2017年方涛涛等人对于传统神经网络预测精度低的问题, 提出一种BP-Adaboost的预测算法, 该方法将多个神经网络组成为一个强预测器, 其有效提高了能耗预测精度[9].2020年邹峰等人提出一种DGQL的预测算法, 其通过将生成对抗网络与Q学习相结合以提升能耗预测精度[10].现实中短期能耗预测任务中往往已知部分前序时刻数据, 要求预测后序能耗序列值, 面对如何利用已知能耗序列提升预测精度的问题, 利用LSTM网络的解决方案效果较好.不过由于其后序能耗值与前序能耗值有相当大的关系,模型通常在前序能耗值的基础上预测后序能耗值, 如果前序能耗值误差较大, 后序能耗值在此基础上预测也会有较大误差, 因此该模型往往会由于一个预测值的误差导致后序预测值整体的误差.总之, 在建筑能耗预测研究领域, 研究者们提出各种不同的方法去预测建筑能耗以提升建筑能耗精度或者降低预测模型的使用复杂度.
本文在GAN (Generative Adversarial Networks)的基础上提出了基于强化学习的生成对抗网络(Reinforcement learning-based Generative Adversarial Networks, Re-GAN)算法, 并用于建筑节能预测问题, 以进行高精度能耗序列预测.Re-GAN算法在GAN的基础上进行改进, 用强化学习优化GAN, 即把GAN的过程描述为一个MDP过程.具体方法为: 将GAN中的生成器作为强化学习中的Agent, 将GAN中的判别器输出作为强化学习中的奖赏函数.训练时, 该算法用真实能耗序列训练网络; 预测时, 该算法可以选择通过向模型输入已知真实值作为预测值, 以提升待预测序列中之后时刻能耗预测值的准确度.模型通常将在前序能耗值的基础上预测后序能耗值, 所以如果前序能耗值误差较大,后序能耗值在此基础上预测也会有较大误差, 但由于该算法中生成器的目标是生成整体误差更小的能耗序列, 因此面对单个预测值误差对后序预测值的误差影响, 该方法可较大限度地避免误差累计.实验表明, 相较于多层感知机(MLP)、门控循环神经网络(GRU)、卷积神经网络(CNN)等模型, 本文所提出模型可以较为准确的捕捉到能耗曲线的起伏变化、有效的消除显著误差的影响, 是一种有效的建筑能耗预测方法.
1 主要模型原理
1.1 生成对抗网络
自2014年Goodfellow提出生成对抗网络GAN以来[11], 许多研究学者加入其中, 并将其主要应用于音乐、诗歌生成等方面.同时, 又在其基础上提出条件生成对抗网络(CGAN)[12]、深度卷积神经网络(DCGAN)[13]、Wasserstein生成对抗网络(WGAN)[14]、序列生成对抗网络(SeqGAN)[15]等.GAN起源于二人零和博弈: 在利益之和不变的情况下, 两个智能体互相提升自己能力以期待获得更高的利益, 当两个智能体都发现改变自己策略不能获得更多利益时, 博弈结束, 最终的结果是两个智能体的能力均有提升, 达到纳什均衡[16].
GAN的目的是在提供真实数据的情况下训练生成器和判别器, 使生成器生成更贴近真实数据分布的生成数据.GAN模型如图1所示, 其包含两个智能体:生成器Generator (生成器G)和判别器Discriminator(判别器D).

图1 生成对抗网络
生成器G负责将其随机产生的多维向量z转化为与Xreal相同数据格式的Xg数据集.Xreal数据集需要事先提供, 如: 统一格式的图片、统一格式的诗歌、统一格式的音乐等, 统一格式指的是输入电脑的数据尺寸大小, 例如将图片作为Xreal数据集, 则可统一格式为RGB模式下的64×64像素.
判别器D负责判别数据真假与否.真实数据集Xreal和生成器生成的Xg数据集共同作为判别器D的输入.假设x为Xreal或Xg数据集的一条数据, 判别器D在不知x所属数据集的情况下对其打分.打分高低依赖于判别器D判别出的x与真实数据相似程度.即x与Xreal数据集越接近, 分数越高; 否则分数较低.
生成器G的目标是使生成数据被判别器D判别为真; 而判别器D的目标是对输入数据能够进行准确分类, 即属于Xreal数据集的数据被判高分、属于Xg数据集的数据被判低分.
1.2 强化学习
强化学习(Reinforcement Learning, RL)通过与场景交互, 在动作空间中选取合适的动作去应对以获取最大的奖赏.
强化学习模型如图2所示, Agent在一定程度上能够感知环境Environment的部分状态, 感知到的状态称之为State, 此时Agent需要产生可以影响环境的动作Action, 产生动作Action之后Agent会收到由环境给与的反馈Reward.由于Agent产生了可以影响环境的动作, 因此环境产生变化, Agent会获得新的环境状态,此时又可在新状态的基础上产生新的动作以此循环与环境进行交互, 直到达到设定的结束条件即可结束交互.

图2 强化学习
由于在交互初期已设定好一个或多个与环境状态有关的目标, 此目标不断训练Agent使Agent可获取整个交互的最大奖赏.因此, 训练后的Agent不应只考虑当前单个动作的奖赏Reward, 还应考虑整体交互的奖赏和, 使得整体奖赏值最大.即Agent选取动作不仅看重当前奖赏值Reward, 更应看重长期整体的奖赏值.
2 基于强化学习的生成对抗网络能耗预测模型
将GAN网络应用于建筑能耗预测的传统模式基本为: 将大量统一格式的能耗序列作为Xreal数据集,GAN中生成器G将自身随机产生的多维向量转化成和Xreal数据集一样长度的序列, 生成器生成的能耗序列组成Xg数据集.作为GAN中的判别器, 其只能接收完整的序列数据进行判别并给出得分, 判别器接受完整的序列数据进行判别, 若分数接近于1则更偏向于认为是来自真实数据集Xreal, 若分数接近于0则更偏向于认为是来自生成器G.在不断训练后, 使得生成序列分布接近真实能耗序列分布.
由于GAN的预测输出格式是固定的完整能耗序列, 若在生成过程中已知能耗序列中部分数据x1:k={t1,t2,···,tk}(k为已知能耗数据的数量), 要求预测之后时刻能耗数据tk+1或者 {tk+1,tk+2,···,tn}(n为能耗序列的标准长度), 这种情况只是通过GAN应用到建筑能耗预测的传统模式是无法做到的, 因为模型规定的生成器G是没有输入, 生成器只是根据自己随机生成的向量去转化为统一格式且分布和真实数据相似的生成序列.所以, 面对当前序列中已有的部分时刻能耗资源,如何将其利用使预测值精度更高是该研究的出发点.
Re-GAN方法通过将强化学习与GAN相结合, 用真实能耗序列训练网络, 且可以通过向模型输入待预测序列中已知的部分前序值以提升待预测序列中之后时刻预测值的准确度.在此之前, GAN结合强化学习的方法主要运用于文本生成、音乐生成等, 如SeqGAN[15].
2.1 能耗预测模型
面对建筑能耗预测问题, 划分一个时间长度并将其时间内的能耗值数量作为建筑能耗序列的标准长度.若已知部分真实能耗序列要求预测未来能耗值, 提出了Re-GAN算法, 该方法建模如下:
(1)若将n作为序列的标准长度, 则真实能耗序列表示为:xreal={T1,T2,···,Tn},Xreal表示真实能耗数据集;
(2)则由生成器生成的序列表示为:xg={t1,t2,···,tn};Xg表示生成能耗数据集;
(3)在生成器生成能耗值的过程中, 若k代表已知能耗序列的长度, 则已知的生成能耗序列表示为:x1:k={t1,t2,···,tk},k∈ [1,n], 则完整的生成能耗序列表示为:x1:n={t1,t2,···,tn}, 易知x1:n=xg.
如图3所示, 在强化学习中Agent作为智能体决策时, 环境是当前已知的能耗序列x1:k; 接收到的状态是当前已知能耗序列x1:k, 做出的下一个动作是下一时刻的能耗预测值即tk+1(将[tmin,tmax]按照等间隔划分且间隔数自定,tk+1在其中取值); 由此可推出Agent做出选择动作tk+1以后, 环境变为x1:k+1={t1,t2,···,tk+1},返回给Agent的状态是x1:k+1, 之后Agent再选择动作tk+2, 环境又被变为x1:k+2; 直到选择最后一个动作tn时,环境变为x1:n={t1,t2,···,tn}, Agent结束与环境的交互,获得完整生成序列x1:n.此时此完整序列xg=x1:n作为生成器的输出.由于生成器需要Reward作为选择每个动作的奖赏以优化网络, 因此设定GAN中判别器的输出作为Reward.

图3 强化学习的网络结构
如图4所示, 将GAN中的生成器作为强化学习中的Agent, 将GAN中判别器的输出作为强化学习中的奖赏.由于判别器D只接受和真实序列格式一样的序列, 则Agent只有将序列生成完毕、获得完整的生成序列xg时, 判别器D才会接收xg返回给Agent相应的Reward.

图4 Re-GAN算法的网络结构
2.2 判别模型
由于GAN模型的目标函数可以表示为式(1), 原文章已证明其收敛[11].公式左边加项为判别器判别真实数据集数据的分值, 越接近于1代表判别器更认为来自于真实数据集; 公式右边加项为判别器判别生成器生成数据的分值与1的差距(D(x)∈[0,1]).训练过程分为两个步骤交替循环, 在保持生成器G不变的情况下, 优化判别器使目标函数值更大; 接下来在保证判别器D不变的情况下, 优化生成器使目标函数值更小.
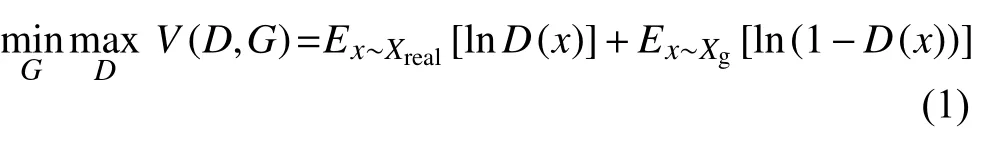
由此得出判别器D的损失函数如式(2), 当判别器对来自真实数据集的数据判别分数越高、生成数据集的数据判别分数越低时, 表明判别器判别能力越好, 同时损失函数的值也越小.判别器的具体流程如图5所示.
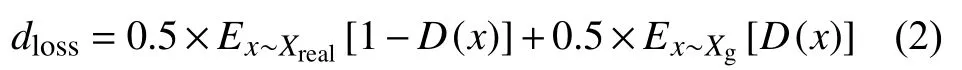

图5 Re-GAN的判别器
2.3 生成模型
根据式(2)可得出生成器的损失函数如式(3)所示, 判别器对生成的能耗数据判别分数越高, 生成器的损失函数值越小, 同时表明生成器的生成的数据更加接近真实数据.
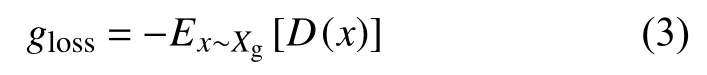
但由于生成器G的训练依赖于判别器D提供的评判分数, 如何利用强化学习训练生成器生成完整能耗序列以及如何利用判别器评判分数优化生成器,这一系列问题正是强化学习与GAN结合的难点.
由于GAN中优化生成器的方法是使损失函数更小, 即使Ex~Xg[D(x)]的值更大, 且在强化学习中要求使Agent即生成器获得的整体奖赏更大, 因此对于生成序列, 将D(x)作为整体奖赏.整体奖赏D(x)更大时, Agent的奖赏R更大, 同时使生成器gloss的损失函数更小.
由此, 若定义Gθ是网络参数为θ的生成器G, 则求的过程被转化为求的过程, 由于Rθ具有随机性(生成器和判别器均有随机性), 所以通过整体奖赏的期望值来判定Gθ的生成能力的优良, 即转化训练目标为如式(4)所示,τ=x1:n表示生成序列的一种可能性或者说生成器生成的一个完整序列, 每种τ出现的可能性依赖于θ,Gθ的期望奖赏计算方法是将生成器所有可能出现的τ的奖赏与每种τ出现的概率相乘并求和.实际训练过程中是让生成器参数不变的情况下生成M个τ, 然后求所有τ的奖赏均值.
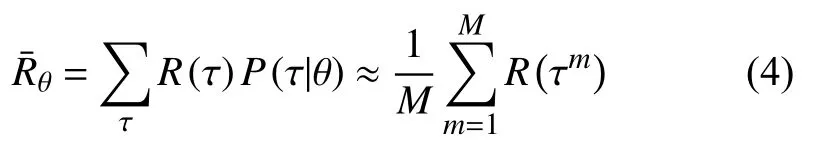
由于对生成器采用策略梯度的方法, 将更新后的参数表示为θ*, 因此,η表示为更新参数θ*的步长或学习率.则在梯度下降过程中,,其中, 学习率η为超参数, 在训练时需提前设置, 而网络参数θ的取值依赖于的求解.
此外, 由于R(τ)的取值与θ无关, 因此在式(4)的基础上求概率梯度, 得式(5).其中, 求解梯度的数值需转化为对数形式, 并将其中所有可能出现的τ的奖赏与每种τ出现的概率相乘并求和的过程转化为采样M次τ求均值的过程.其中首先求解梯度的数值转化为对数形式, 然后最后一步将其中所有可能出现的τ的奖赏与每种τ出现的概率相乘并求和的过程转化为采样M次τ求均值的过程.

如图6所示, 在已知序列x1:k的情况下生成器一步步生成每个序列点, 其中每一行生成器生成一个序列点.如图中第一行表示, 在已知序列x1:k作为State的基础上产生动作tk+1, 其选择概率是P(tk+1|x1:k,θ).此时下一个状态是确定的为x1:k+1, 相应下一个动作概率为P(tk+2|x1:k+1,θ), 直至最后一个动作概率为P(tn|x1:n-1,θ),因此实际应用时获得的是已知序列x1:k, 而训练网络则是从0开始生成序列, 因此, 此时可得式(6)和式(7).


图6 Re-GAN的生成器
如果用整体序列的奖赏R(τ)代表该序列中每一个动作的好坏稍有不妥, 故采用蒙特卡洛搜索[17]的方法,R(ti|x1:i-1)表示在x1:i-1状态下产生ti所达到的下一个状态的好坏程度.
由于下一个状态必是x1:i, 因此R(ti|x1:i-1)=R(x1:i),此时定义即在x1:i状态下采样出J个完整序列并求其奖赏均值.将R(x1:i)代入公式可得式(8), 并根据式(9)更新网络参数θ.

2.4 Re-GAN模型算法
Re-GAN算法需要预训练判别器D, 之后训练过程分为两个步骤以交替循环训练, 第一步在保持生成器G不变的情况下, 优化判别器使目标函数值更大; 接下来在保证判别器D不变的情况下, 优化生成器使目标函数值更小.由于生成器较判别器不易收敛, 所以设置训练一次判别器后再训练g_steps次生成器.下面给出详细的Re-GAN算法流程, 如算法1所示.

算法1.基于强化学习的生成对抗网络算法1.预训练判别器D;2.初始化 Gθ、Dβ的权值;3.令 θ'=θ;4.For(i=1; i<= epochs; i++){5.#训练判别器D 6.将xreal中的采样序列和生成器G的生成序列混合;7.训练判别器D以最小化dloss;8.#训练生成器G 9.For(j=1; j<=g_steps; j++){10.利用Gθ生成序列x1:n;11.For(k=1; k<= n; k++){12.利用Gθ计算R(x1:k)13.}images/BZ_164_701_1455_755_1489.png14.采用梯度下降方法利用 优化Gθ;15.θ'=θ;16.}17.}
2.5 模型分析
算法1给出模型的训练过程, 主要包括了初始化和循环训练判别器、生成器过程.其中生成器由循环神经网络实现、判别器由全连接神经网络实现.初始化生成器和判别器的超参数后进行模型训练.模型训练是一个逐步地优化过程, 在此模型中每次训练分为两步, 先训练判别器, 之后训练生成器.
通常生成器较判别器不易收敛, 所以设置训练一次判别器后再训练g_steps次生成器.训练判别器时注意需要将生成器G的参数设置为不可跟踪, 这样生成器的生成数据分布固定, 且真实数据的分布必然固定,以此才可训练判别器优化判别能力, 否则极有可能在优化判别器的同时使生成器的生成能力降低[18].
训练生成器的过程也是求 ∇R¯θ的过程, 以通过来更新生成器Gθ, 由于其中的R(x1:i)对于求梯度来说是一个系数且较难计算(每个R(x1:i)的时间复杂度为J), 所以对于序列x1:n, 先将R(x1:i)求出, 再用式(8)求梯度以优化生成器网络.
3 实验结果与分析
3.1 数据预处理
本文实验环境为Python 3.6, tensorflow-gpu 1.12,NVIDIA GFORCE GTX980, Windows 10操作系统.实验所用的数据集来自建筑数据基因组项目[19], 在共享的507栋建筑性能相关数据集中, 每栋建筑数据包括整栋建筑每小时的电表数据和各种特征元数据, 如总建筑面积、主要用途类型、天气信息和行业.本文选取其中一栋建筑唐宁街综合大楼的数据进行实验(https://platform.carbonculture.net/assets/10-downing-street/).
唐宁街综合大楼是一栋四层的一级和二级砖砌的格鲁吉亚排屋, 其中唐宁街10号分享其可持续发展数据, 以便每个人都能帮助确定新的储蓄并提出改进建议.选取其2012年1月1日至2018年12月31日共6年的数据作为本文实验中的真实数据集, 将其中2012年至2017年的数据作为训练集、2018年的数据作为测试集(能耗数据按小时采集, 每天24次).
图7展示的是2017年1月共31天的能耗数据、图8展示的是2017年1月8日至1月14日共7天的能耗数据, 横坐标是时间单位, 纵坐标是全楼用电, 用WBE (the Whole-Building Electricity)表示, 其中可以明显看出工作日与能耗之间的大致关系.

图7 2 017.1.1-2 017.1.31能耗实际值
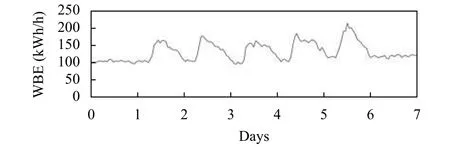
图8 2 017.1.8-2 017.1.14能耗实际值
按照所选取训练集, 将其转化为按天为单位的能耗曲线, 其行表示为该栋建筑的每一天, 列为该栋建筑一天中24小时的能耗值.首先使用LoadShape模型和相关的Python库, 通过删除总异常值和填充小间隙来清理每个仪表数据集.
本文关注基于时间序列的能耗数据变化, 且为了固定模型学习中的预测范围, 故通过每年的峰值负荷标准化建筑的日负荷曲线, 并将真实能耗数据值进行归一化处理, 处理后数据范围是[0,1].用表示单个真实能耗数据,Tmax代表年能耗数据(删除总异常值后)的最大值,Tmin代表年能耗数据(删除总异常值后)的最小值.那么归一化后的数据Tk可表示为式(10):

3.2 对比方法和评价指标
本文将Re-GAN与MLP、GRU和CNN进行比对.且不同方法对应的训练数据集均为预处理之后的训练集, 以体现实验的公平性.
选取平均绝对百分比误差MAPE和均方根误差RMSE作为评价指标, 其表达式为式(11)和式(12):

其中,n表示预测能耗序列的长度,Tk和tk分别表示每个序列点的真实能耗值和预测能耗值.MAPE范围是[0, +∞),MAPE为0表示为完美模型,MAPE越大表示预测效果越差.同时MAPE公式要求真实数据不能存在等于0的情况, 从图7可以看出能耗值不存在等于0的情况且能耗数据极小值不为0, 因此此评价标准可用.此外, 将数据去归一化处理后用RMSE评估, 这时RMSE评价标准可直观的表示预测的平均误差数值, 比如RMSE=5, 可以认为预测序列相比真实序列平均差5.MAPE和RMSE都是数值越小表示能耗预测结果越准确.
3.3 实验及结果分析
本文对唐宁街综合大楼的数据集进行训练, 将2012年-2017年的数据作为训练集, 2018年的数据作为测试集.为了研究本文Re-GAN算法的预测效果, 设置MLP、GRU、CNN几种算法作为对比.
表1为4种算法在相同训练集上的预测误差.通过表1可知, 4种算法在相同训练集上预测结果的RMSE值比较接近, 说明它们对训练集数据具有相似的数据拟合效果.而后通过检验在测试集上的预测效果比较各个算法的泛化能力.

表1 不同方法下预测的误差对比(训练集)
表2为4种算法在相同测试集上的预测误差.通过表2可知, 各个模型在测试集上的预测准确度有较大的差别, 实验选取5个星期的能耗数据进行预测, 发现MLP、GRU、CNN、Re-GAN方法最终预测结果的RMSE均值分别为5.50、4.42、4.34、2.67.Re-GAN方法较其他预测方法在MAPE上分别降低了5.91%、4.11%、3.9%; 相比于其他方法在RMSE上分别降低了51.45%、39.59%、38.48%.综合分析, Re-GAN方法在MAPE和RMSE指标上都有明显的下降, 且具有较好的泛化性能, 表明在预测过程中整体预测精度和模型性能都有较大的提升.

表2 不同方法下预测的误差对比(测试集)
分析得出, 采用GRU方法预测能耗数据在训练集上虽然有很高的训练精度, 但是在面对未学习过的数据集(测试集)时表现的效果不是很理想, 泛化能力较差.一部分原因是循环神经网络一个序列位置的输出受之前预测值的影响, 误差极有可能累计或者很有可能发生相位偏移, 从而导致预测准确度不高.采用CNN方法预测的平均绝对百分比误差和均方根误差相较于GRU均有所降低, 但预测效果仍有待提高.
Re-GAN算法从整体时间序列角度出发, 以强化学习中的奖赏为目标, 试图获得更高的总奖赏值.值得注意的是即使出现准确度较低的一个点, 下一个预测值也不会受太大的影响, 因为此时模型选取的下一个预测能耗值是为获取更高的奖赏总和, 即模型受之前单个预测值误差的影响较小.因此在面对峰值时Re-GAN算法预测效果更好.
表3为Re-GAN算法在相同测试集上不同输入量的误差对比.通过表3可知, 用Re-GAN方法输入不同数量的输入值其预测精度也会有所不同.

表3 Re-GAN方法不同输入量误差对比(测试集)
Re-GAN算法增加了利用已知真实能耗数据提升预测精度的功能.在不同已知输入序列条件下,MAPE值也有不同, 如表3所示, “8个”代表在Re-GAN方法下输入前8个小时已知值, 同理, “12个”“16个”代表在Re-GAN方法下输入前12个小时、前16个小时的已知值.因此在Re-GAN方法下输入0小时已知值、输入8个小时已知值、输入12个小时已知值和输入16个小时已知值的MAPE均值分别为6.25%、5.90%、5.70%、5.13%.可以得知: 本文算法下已知输入序列越多,MAPE误差均值越小.
总体来看, 与MLP、GRU、CNN相比, Re-GAN在MAPE和RMSE评价指标上均具有明显的下降, 同时输入已知序列更能降低预测的误差.表明在预测过程中Re-GAN方法具有更高的预测性能和稳定性, 是一种可行的建筑能耗预测方法.
为了更清晰直观的表示各算法的预测效果, 图9展示了2018年3月12日用不同方法预测能耗的对比图, 此时Re-GAN无输入数据.
根据图9可知Re-GAN算法预测的能耗序列更接近于真实能耗序列值, 预测效果较好, GRU算法在峰值处能耗值稍有延迟, MLP预测效果较差, 虽然可以预测出能耗曲线的起伏变化, 但其预测值稍低且峰值处不明显.CNN效果仅次于Re-GAN, 在能耗曲线上有偏离但起伏状态能准确地捕捉到.因此, 相较于其他模型,Re-GAN模型可以较为准确的捕捉到能耗曲线的起伏变化, 有效的消除显著误差的影响, 是一种有效的建筑能耗预测方法.
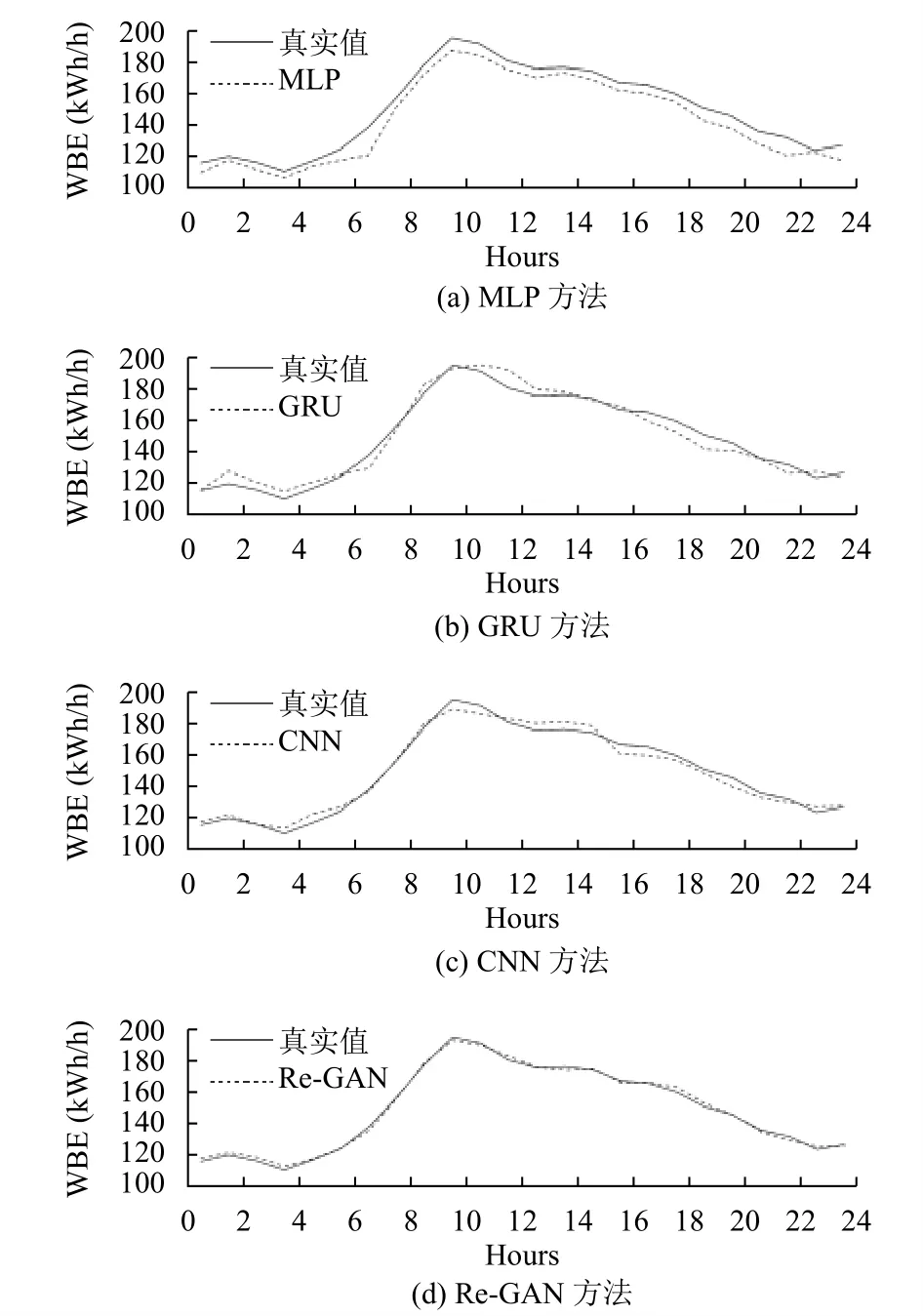
图9 不同方法下预测值与真实值的对比(2 018.3.21)
4 结束语
本文提出了一种将强化学习与GAN结合的Re-GAN算法能耗预测模型, 该模型将GAN中的生成器作为强化学习中的智能体Agent、将GAN中的判别器作为强化学习中的奖赏函数, 其中Agent每一序列点的预测目标都是使序列整体的误差更小.根据模型的特点可通过输入已知能耗数据提升预测准确度.本文将Re-GAN算法和MLP、GRU、CNN这3种方法进行对比, 提出的预测模型能够获得更小的预测误差,且随着已知能耗数据的增加预测误差更小.
本文的预测对象主要是长度较短的能耗序列, 然而, 对于较长的能耗序列, 算法存在以下两个问题:(1)收敛速度慢; (2)对计算机内存要求较高.下一步,将考虑对这些问题进行解决, 同时不断完善能耗预测模型.当前, 利用强化学习优化GAN并用于能耗预测是一个值得研究的方向, 进一步优化使其具有更强的通用性应该会获得更有价值的结果.
