XAI 在反洗钱领域的探索与应用
2022-01-05中银金科闫玲玲
文/ 中银金科 闫玲玲

在大数据时代背景下,机器学习相关技术的应用正全面渗透到金融行业当中。与传统的统计模型相比,机器学习模型具有更好的预测表现能力。然而,随着需要处理的数据规模越来越大,机器学习模型的复杂度也逐渐增加,这就为模型的可解释性带来了巨大的挑战,用户只能看到模型结果,无法了解模型做出决策的原因和过程。反洗钱场景的特殊性在于它属于强监管领域,工作人员在进行可疑交易上报时,必须给出详细的判断依据,从而确保决策的合理性,因此模型的可解释性就显得尤为重要。为了提高机器学习模型的可解释性,建立用户与决策模型之间的信任关系,更好地推动复杂机器学习模型在反洗钱领域的应用,中银金科在可解释机器学习(XAI)领域进行了初步探索。
可解释机器学习相关概念
可解释性是指我们具有足够的可以理解的信息来解决某个问题,可解释的机器学习是指我们能够对输入的特征和最终预测结果之间的关系进行定性理解,即每个预测结果都具备相应的决策依据。例如金融风控领域的评分卡模型,通过客户最终得分来决定他能否通过贷款申请,同时通过不同特征项的得分给出判决依据。
通常情况下,模型的复杂程度与模型的准确度相关联,同时又与模型的可解释性相对立。线性回归、逻辑回归、决策树等结构简单的机器学习模型往往具有较强的可解释性,我们可以针对模型进行归因分析,从而确保决策的合理性,但学习能力有限,准确率不高;而集成树模型、神经网络等复杂的机器学习模型具有较强的拟合能力,在许多目标任务中取得了良好的性能,但由于模型参数量大、工作机制复杂、透明性低,因而可解释性又相对较差,无法说明从输入到输出之间的因果关系。决策者使用复杂的黑盒模型时,由于缺乏模型解释信息,无法判别模型结果合理性,所以导致很难将模型应用到某些实际工作场景,大大降低了模型的实际效益。
可解释机器学习的分类
(1)根据可解释性方法的作用阶段,可以分为内在可解释性和事后可解释性。
·内在可解释性:通过训练结构简单、可解释性好的模型或将可解释性结合到具体的模型结构中使模型本身具备可解释能力。
·事后可解释性:通过开发可解释性技术解释已训练好的机器学习模型。
(2)根据可解释性方法的使用范围,可以分为全局可解释性和局部可解释性。
·全局可解释性:解释整个模型的预测行为,旨在帮助人们理解复杂模型背后的整体逻辑以及内部的工作机制。
·局部可解释性:解释单个实例的预测行为,旨在帮助人们理解机器学习模型针对每一个输入样本的决策过程和决策依据。
(3)根据可解释方法与模型的匹配关系,可以分为特定于模型的解释和模型无关的解释。
· 特定于模型的解释:意味着所使用的解释方法必须应用到特定的模型体系结构中。
·模型无关的解释:意味着解释方法与所用模型无关联。
可解释机器学习的常用方法
为了提高机器学习模型的可解释性,建立用户与模型之间的信任关系,近年来机器学习领域的学者对可解释机器学习方法进行了广泛且深入的研究。其中,决策树主要是根据特征分裂前后的信息增益变化来衡量特征的重要性;GLM(广义线性模型)和GAM(广义加性模型)都是对线性模型的扩展,其核心是将模型结果看作特征效应的总和;Rulefit 训练M 个基分类器,生成规则,然后对规则加惩罚项进行线性拟合;ALE 根据条件分布得到在特定特征值时,预测值在局部范围内的平均变化;PDP 和ICE 考察某项特征的不同取值对模型输出值的影响;Permutation Importance 随机重排或打乱样本中的特定一列数据,通过模型预测准确率的变化来判断特征的重要程度;LIME 的核心思想是对于每条样本,寻找一个更容易解释的代理模型解释原模型。SHAP 的概念源于博弈论,核心思想是计算特征对模型输出的边际贡献。

可解释方法的选择
由于不同的可解释方法解决问题的角度和侧重点不同,中银金科结合具体的工程化实施过程,对可解释方法的选择过程进行了系统的归纳和科学的总结,如下图所示。
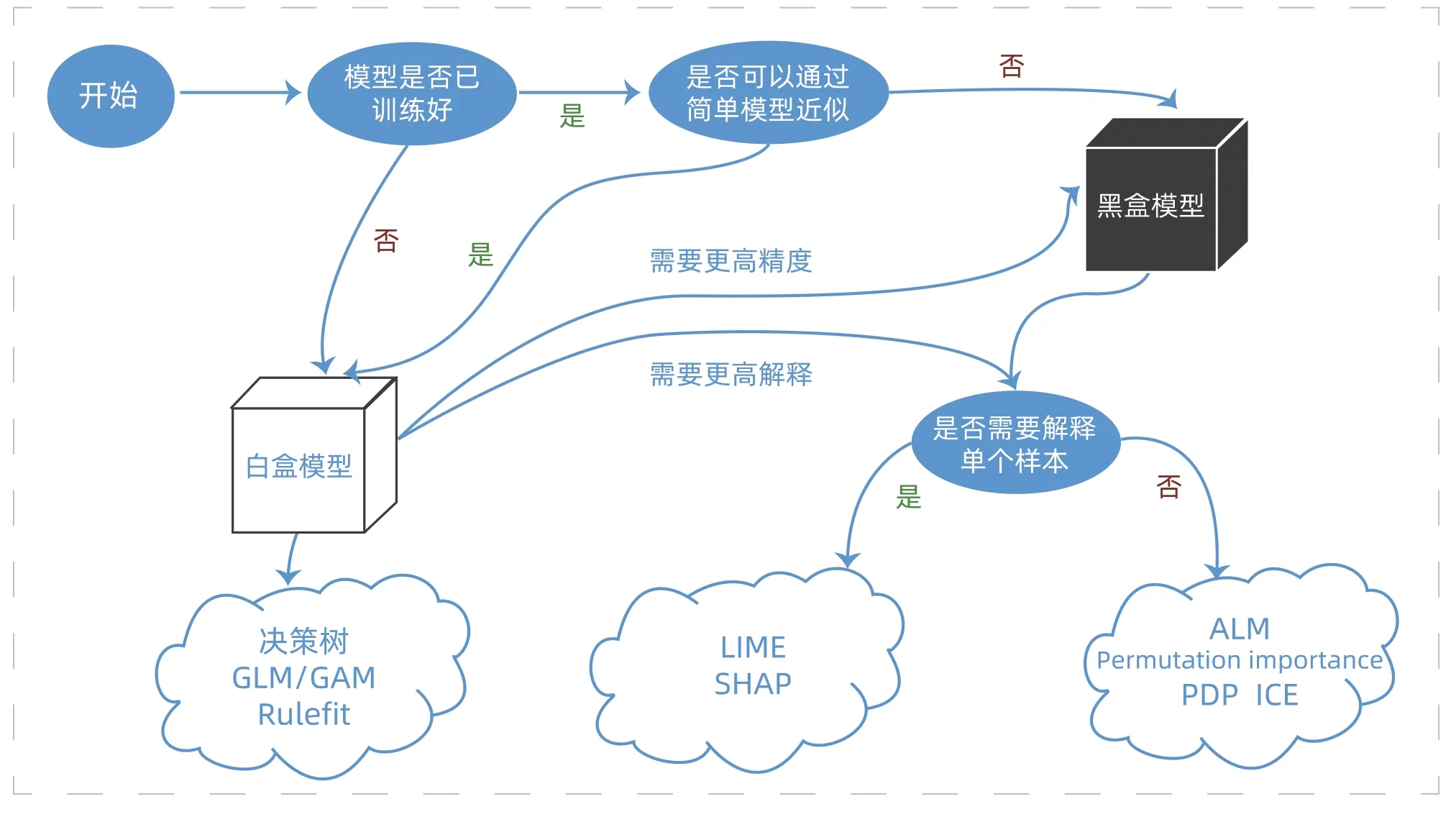
可解释机器学习应用案例
本次探索选取的应用场景为反洗钱可疑交易监测场景,我们的任务是通过构建机器学习模型找出潜在的高洗钱评分案例,辅助一线工作人员进行可疑案例筛查。该场景要求工作人员甄别可疑案例时,不仅要保持较高的准确性,而且要给出每一个可疑案例的详细判断依据。传统反洗钱领域建模的痛点在于,无法兼顾模型的准确性和可解释程度。如果选择逻辑回归等传统机器学习算法,使用者可以很清晰地看到每个客户的评分构成,但精度往往不尽如人意;而如果选择预测精度较高的“黑盒”模型,那么可解释程度又会大大下降。
目前该领域的常规做法是,模型构建完毕后,给出每个客户的可疑度评分,再由甄别人员按照可疑度由高到低进行人工复核,撰写可疑案例报告。这种做法不仅造成了大量人力资源浪费,而且没有充分体现出机器学习模型的辅助作用。基于以上痛点,中银金科借助可解释机器学习方法,在保证模型预测结果精度的基础上,给出该结果的可读性理由,使得用户能够理解模型做出决策的内在逻辑,同时根据用户需求自动生成可疑客户报送信息,真正做到利用机器学习模型减少一线人员的工作量,提升甄别工作效率。整体流程如下图所示。

我们选取分别来自客户的基础信息、交易信息、补充信息以及可疑案例信息四个维度的数据,经过数据清洗后整合成客户宽表;根据数据探查情况,结合专家经验构建特征工程;综合比较MLP、XGBoost、SVM 等多种机器学习算法,我们发现XGBoost 实现的梯度提升树能够提供最佳的准确率;XGBoost的局限性在于它仅能给出全局的特征重要性度量,而反洗钱场景还需要我们对模型给出局部解释,即针对每个客户交易案例进行可疑度归因分析,给出可疑度评分的预测依据。
基于以上考虑,我们结合上一节总结的可解释方法选择策略,最终选取SHAP 方法对模型的预测结果进行解释。SHAP的优点在于表达直观且理论完备,兼顾了全局解释、局部解释和特征的交互作用。
主要解释过程包括以下四个部分:
(1)构建解释器:输入XGBoost 模型参数,构建一个解释器。SHAP 支持很多类型的解释器,我们选取适用于树模型的treeshap。
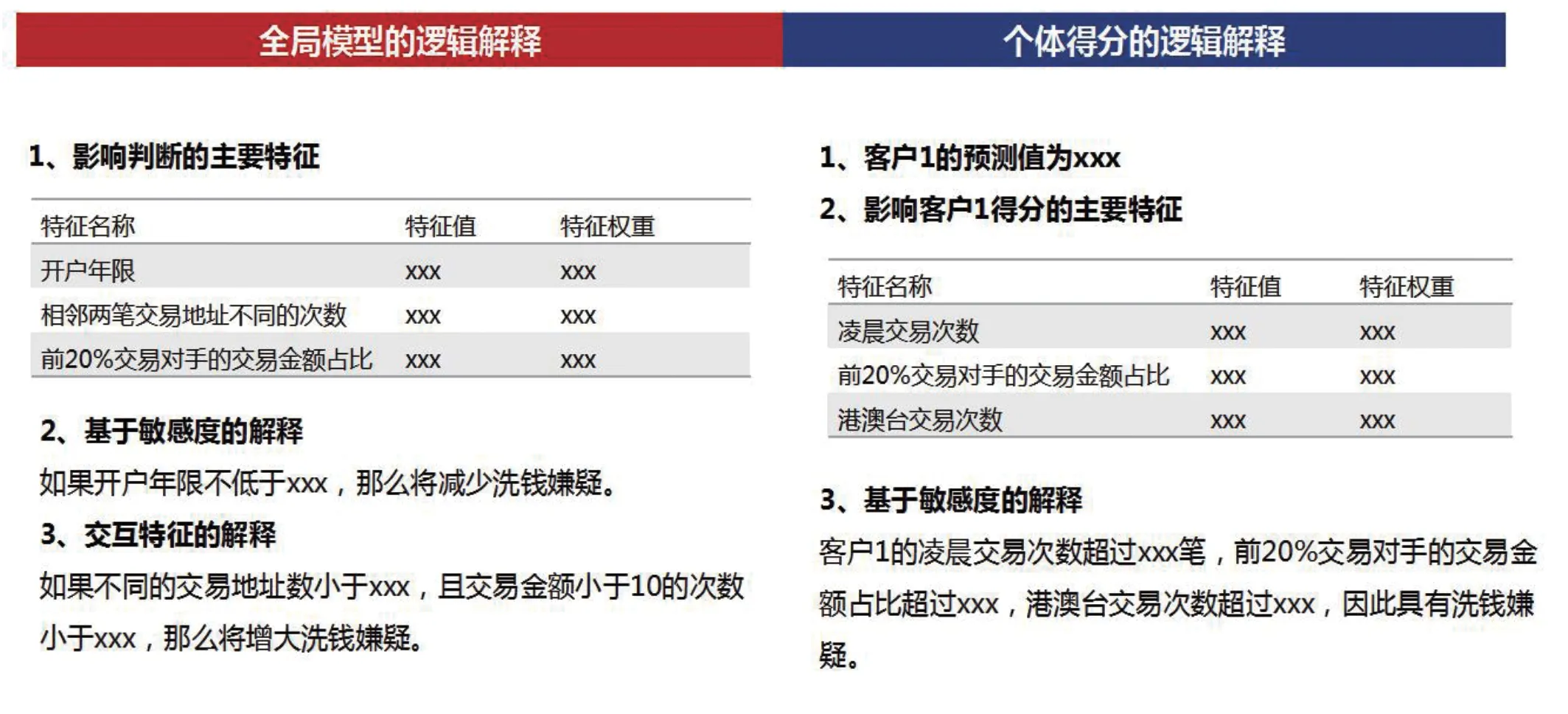
(2)局部解释:选择一条客户数据输入至解释器,计算每个特征对该客户评分结果的贡献度,即shap value,shap value 的绝对值大小代表该特征对客户评分结果的影响程度。
(3)全局解释:取每个特征的shap value 绝对值的平均值作为该特征的重要性。
(4)生成可疑交易识别报告:根据业务经验,将量化结果转化成符合业务逻辑的语言,提升模型的可解释程度,输出可解释报告,辅助业务人员完成案例描述,样例如下。
可解释机器学习是各行各业都在关注的重要课题,模型使用者对模型的安全感、信赖感、认同度都取决于模型的透明性和可理解性,尤其是在智能金融领域,模型的可解释性尤为迫切和重要。
本文列举了可解释机器学习的常用方法,对可解释方法的选择过程进行了系统的归纳和科学的总结,形成了一套通用的方法论,同时针对反洗钱场景选择合适的可解释方法进行案例应用,旨在为复杂机器学习模型在强监管领域的落地和应用提供一些思路,同时为国内使用人工智能技术的未来监管政策打好知识和实践基础。
尽管可解释机器学习的相关研究已经取得了一系列可观的成果,但该研究领域仍处于萌芽阶段,仍然还有很多关键性的问题有待探索,例如缺乏一个用于评估解释方法的科学评估体系。中银金科也将继续在可解释机器学习领域进行积极的探索,为推动机器学习可解释性研究的进一步发展和应用提供一定帮助。
