基于近红外光谱分析技术测定小麦淀粉的含量
2022-01-05王晓琼向娜娜纪昌正潘子幸黎鸿彬谭会泽
王晓琼,陈 丽,向娜娜,纪昌正,潘子幸,杨 露,黎鸿彬,谭会泽,张 瑜
(温氏食品集团股份有限公司//农业部动物营养与饲料学重点实验室,广东 云浮 527400)
小麦作为饲料能量原料在畜禽饲粮中的应用十分广泛,而淀粉是小麦主要的碳水化合物成分,是畜禽所需能量的重要来源。因此,在畜禽饲粮生产中,实时监测小麦淀粉含量,对原料的择优采购及饲料精准配方起着非常重要的作用。目前,淀粉的国家标准检测方法非常复杂,步骤繁琐、耗费试剂、检测时间长,且对操作人员技术水平要求高,因此,小麦的淀粉含量往往无法做到每批次实时监测。
近红外光谱分析技术具有检测速度快、不损耗样品、对环境无污染、可多组分同时定性定量分析等优点,在农作物品质分析中应用越来越广泛[1-2]。其中在小麦上的研究与应用已有较多的报导[3-6],但到目前为止没有见到利用3种不同制样方式建立近红外小麦淀粉(干基)预测模型对比的报导。本研究旨在研究通过对比3种预处理方式建立的小麦淀粉近红外模型的预测效果及可行性,为小麦淀粉的测定提供准确可靠、便捷、经济的分析检测途径。
1 试验仪器与材料
1.1 主要试验仪器及参数设定
德国布鲁克MATRIX-I近红外分析仪:扫描范围4 000~12 000 cm-1、分辨率16 cm-1、扫描次数64次;美国鲁道夫API旋光仪:温度控制20±0.5℃、波长589 nm、样品池200 nm;莱驰ZM200超离心粉碎机:筛孔径0.5 mm;泰斯特FW135中草药粉碎机。
1.2 试验材料
本研究收集2019年生产的国内不同产地、品种的小麦颗粒,共计181个样品。
2 分析方法和步骤
2.1 制样方式
为确保湿化学检测值与扫描的样品对应,本研究中3种制样方式的样品都是使用同一份扫描杯里的样品,因此3种样品处理并不是同步进行的。具体操作为:小麦颗粒去除杂质即为颗粒原样样品,近红外扫描后使用中药粉碎机进行间歇式粉碎,共粉碎1 min,得到中药粉碎机粉碎样品,近红外扫描后从中取适量样品使用莱驰粉碎机过0.5 mm筛粉碎,得到0.5 mm粉碎样品。
2.2 湿化学值检测
由于小麦在粉碎过程中会有不同程度的水分损失,因此本研究的淀粉结果以干基计算。湿化学检测项目水分和淀粉参考方法分别为GB/T 6435—2014《饲料中水分的测定》和GB/T 20194—2018《动物饲料中淀粉含量的测定 旋光法》,检测样品均为0.5 mm筛粉碎样品。
2.3 光谱数据采集
在近红外光谱数据采集中,同一份样品不同的装样方式会使样品在扫描杯的松紧度和杯底平铺样品的均匀度不一样,导致采集的光谱会有细微的差别,因此要统一装样方式。每份小麦颗粒样品采集5张平行光谱数据,取平均光谱,中药粉碎机粉碎样品和0.5 mm粉碎样品各采集1张光谱数据。
2.4 NIR模型建立与验证
模型建立使用德国布鲁克OPUS 8.1软件,随机将光谱数据类型设置为校正光谱和测试光谱,光谱数量分别为144个和37个,分别用于建立和验证模型。模型的建立使用偏最小二乘法(PLS),采用交叉检验,剔除异常数据,使用优化功能对谱区范围、光谱预处理方法、维数等参数进行最优化的选择,建立模型,然后通过检验集检验,验证模型的精准度和可靠性,最终以交叉验证决定系数R2、交叉验证均方根误差RMSECV、检验集均方根误差RMSEP和交叉验证残留预测偏差RPD作为评价指标,进行综合评价,选择最适用的模型。
3 结果与分析
3.1 淀粉检测结果
本研究检测的181个小麦样品淀粉(干基)质量分数检测数据是61.72%~70.29%,数据具体情况如图1所示。从图中我们可以看出,小麦淀粉质量分数跨度相对较大,但样品淀粉质量分数主要集中在65%~69%,65%以下及70%以上的样品数量相对较少,在后期模型的维护中应多加入这部分样品,以提高模型的预测效果。

图1 小麦样品淀粉(干基)质量分数及相应样品个数
3.2 模型的建立与验证
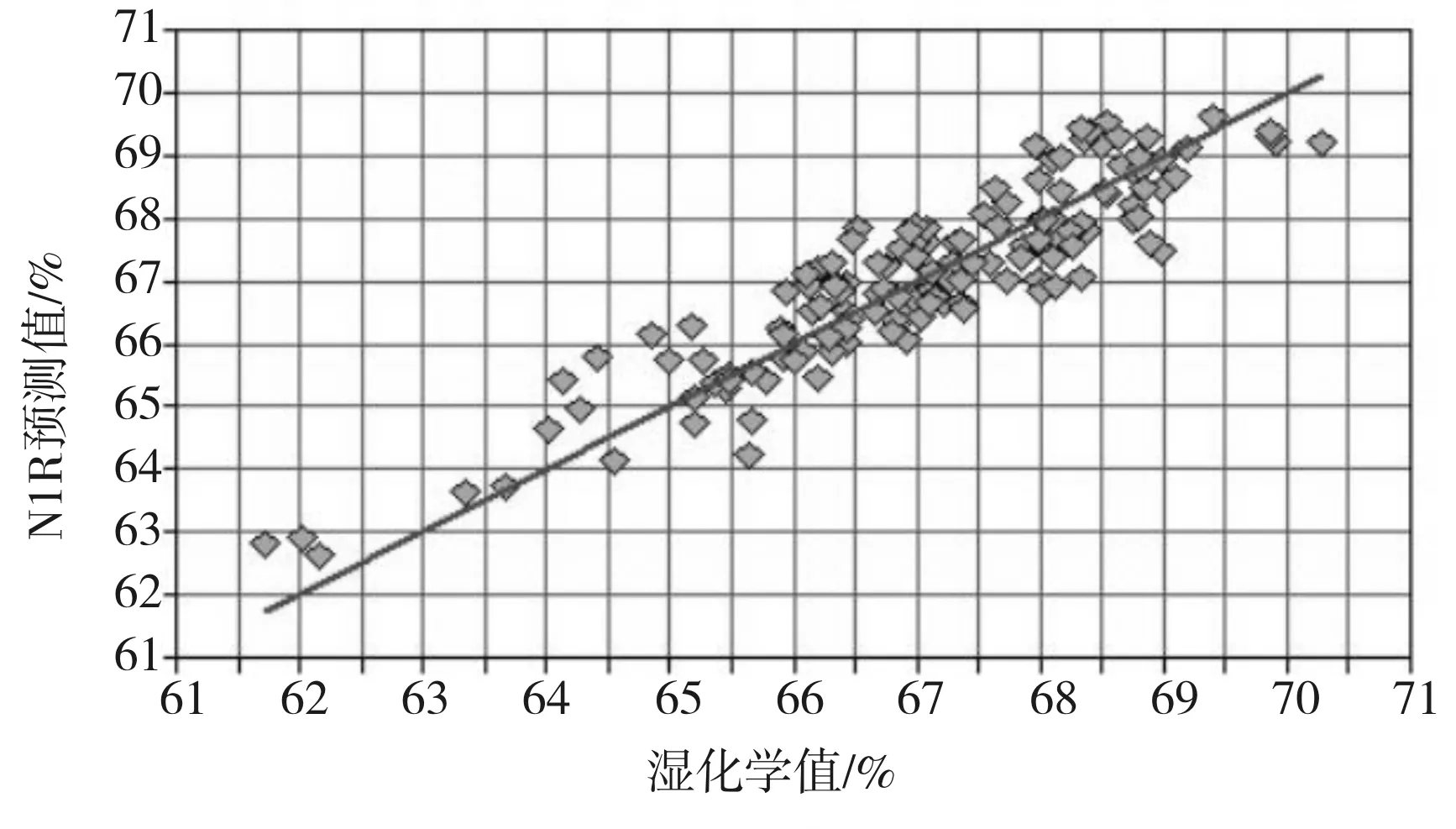
通过OPUS 8.1软件,对得到的湿化学值和光谱数据进行模型建立,3种样品处理方式建立的模型参数如表1所示。3个模型校正样品集和验证样品集的预测情况见图2~图7。

表1 小麦3种处理方式建立的模型相关参数
注:R282.38,RMSECV0.649,RPD2.38,偏移-0.010 6。

注:R287.68,RMSECV 0.534,RPD 2.85,偏移-0.006 97。

注:R290.37,RMSEP0.509,RPD3.23,偏移-0.022。

注:R286.16,RMSECV 0.568,RPD 2.69,偏移-0.001 76。

注:R292.87,RMSEP 0.467,RPD 3.8,偏移-0.077。
由表1可见,3个模型的R2均大于0.8,说明函数模型拟合度较好,样品数据间相关性较强;RMSECV均低于0.7,表示模型的预测误差相对较小;2
由图2~图7可见,预测值与化学值的吻合度较高,模型效果较好。随机选择的盲样比较有代表性,数值从低到高都有涉及到,通过盲样验证证明3种不同预处理方式建立的小麦淀粉NIR模型的预测结果准确度都比较高。
4 结论
小麦可以使用颗粒原样、中药粉碎机粉碎和0.5 mm过筛粉碎3种样品状态建立淀粉(干基)近红外预测模型,且3种模型均能满足日常检测需求,其中颗粒原样不需要制样,检测更便捷,但模型预测准确度不如粉碎模型,其中0.5 mm粉碎建立的模型预测更精准。对于预测结果精准度要求较高的,可以选择粉碎制样,但粉碎制样在实际应用中,如果使用0.5 mm过筛,则粉碎仪器成本相对中药粉碎机要高十至上百倍,对于子公司较多的大型饲料企业,整体成本会比较高,而且制样过程较耗时繁琐。因此,可以参考本研究,使用中药粉碎机制样进行模型的建立与应用。本研究中小麦代表性样品还相对较少,尤其是淀粉(干基)质量分数65%~69%的样品,在模型后期的应用中应继续进行优化,以提高模型的预测能力与稳健性。
