基于知识蒸馏的特定知识学习
2022-01-05戴朝霞曹堉栋朱光明沈沛意
戴朝霞,曹堉栋,朱光明,3,沈沛意,3,徐 旭,4,梅 林,4,张 亮,3*
(1.中国电子科技集团公司第三十研究所,成都 610041;2.西安电子科技大学计算机科学与技术学院,西安 710071;3.西安市智能软件工程重点实验室,西安 710071;4.公安部第三研究所,上海 200031)
(∗通信作者电子邮箱liangzhang@xidian.edu.cn)
0 引言
不论是现实生活还是工业现场,嵌入式设备随处可见,为使深度卷积神经网络运行在这些资源紧缺设备上,模型压缩应运而生。目前主流的模型压缩方法主要分为四类:低秩分解、参数量化、模型剪枝和知识蒸馏。
一般情况下,网络模型训练完成后,卷积核存在低秩特性,因此需要去除冗余参数。常用低秩分解[1-5]方法多使用奇异值分解(Singular Value Decomposition,SVD)来对卷积核进行分解,从而达到模型压缩效果。低秩分解一定程度压缩了网络模型,但其实现复杂,难以大规模推广。参数量化方法通过减少模型参数的存储位数达到模型压缩的效果,以减少多余的存储资源的消耗。Vanhoucke 等[6]和Gupta 等[7]分别采用8 bit 和16 bit 大小存储模型参数,且保证准确率基本不受影响。参数量化方法多适用于小型网络的压缩,对于大型网络会导致准确率大幅下降。
研究表明,训练好的神经网络中存在着大量的冗余结构,这些结构会导致网络模型过拟合问题,降低泛化能力,对网络性能造成影响。模型剪枝[8-12]算法就是通过裁剪这些冗余结构来压缩模型大小且适当地提升网络性能。模型剪枝算法分为非结构化剪枝和结构化剪枝两大类,非结构化剪枝直接对参数权重作置零操作,而结构化剪枝对网络结构整体作裁剪操作。知识蒸馏是模型压缩中最具特色的一种压缩方式,它首先训练好分类性能强大的大型网络,称之为教师网络;再通过蒸馏过程指导训练小型网络,称之为学生网络。该方法得到的学生网络能够代替教师网络部署到工业现场,最终达到模型压缩的效果。
传统知识蒸馏算法中教师网络和学生网络执行的任务一致,本文侧重于学生网络在特定类别分类领域的分类效果,最终目的是得到网络规模小但特定类分类性能等于甚至超过教师网络的分类网络。
本文的主要工作包括:
1)基于知识蒸馏提出新的特定知识学习概念,并结合注意力特征迁移蒸馏算法,提出仅使用特定数据训练的特定知识学习基础算法;
2)在特定知识学习基础算法上引入抑制背景类知识的蒸馏策略;调整网络抑制位置,仅在高层作抑制操作,得到蒸馏过程中特定知识含量更高的学生网络;
3)使用常规数据集CIFAR-100,设置多组对照实验,结合有先验信息的评估方式,验证本文所提特定知识学习算法在特定类别分类领域的优越性。
1 相关工作
知识蒸馏的概念自Hinton 等[13]提出后,各种新的蒸馏算法层出不穷。纵览所有知识蒸馏算法,几乎都围绕着知识的定义以及传递知识的方式来提出研究的创新点。针对这两个研究重点,本文将概述已有的表现不俗的知识蒸馏算法。
Hinton 等最早提出知识蒸馏的概念,并确立了蒸馏过程中教师-学生的框架。该方法不仅利用原始的标签信息,同时也结合了教师网络产生的预测概率,而预测概率就是该方法传递的知识。在此基础上,Romero 等[14]不仅仅使用教师网络的预测概率,同时还利用了教师网络的中间层特征图。该方法强制让学生网络模仿教师网络中间层特征图信息,一定程度上增加了知识传递的含量但是却导致了过正则化问题,使得网络难以收敛。为解决蒸馏过程中的强约束问题,Zagoruyko 等[15]引入注意力机制,该方法仅让学生网络模仿教师网络中间层的注意力特征图,有效地提升了学生网络的分类性能。
除了直接利用教师网络的输出信息或者中间层信息外,其他蒸馏算法对传递的知识作了全新的定义。Yim 等[16]提出学生网络学习教师网络模型层与层之间的映射关系,这种映射关系可以解释为解决问题的思路,即授人以鱼不如授人以渔的哲学思想。Heo 等[17]提出学习教师网络的边界分布更有利于提升学生网络的分类性能,通过最大化边界误差,使得学生网络分类效果明显提升。Zhang 等[18]提出了互相学习蒸馏算法,该方法脱离了教师-学生模式的约束,通过两网络互相并行训练学习共同提升网络的分类能力。
传统知识蒸馏中教师网络将所有的知识传递给学生网络,一定程度上提升了网络的全分类性能,但在特定类别分类任务上提升效果并不明显。本文提出的特定知识学习算法,将有效地提升学生网络在特定类别分类领域的分类准确率,使其成为该领域的专家网络,且保证网络规模足够小,便于工业现场的部署。该算法训练得到的学生网络完全契合工业现场场景单一、分类数目少的特点,对未来网络模型在工业领域的部署有一定的启发作用,具有非常重要的实用价值和意义。
2 传统知识蒸馏和特定知识学习
本章将详细介绍传统知识蒸馏和特定知识学习之间的联系和区别,并且指明特定知识学习最显著的三个特点。
传统知识蒸馏的初衷是让学生网络替代教师网络,以达到模型压缩的效果。为了追求较大的压缩比,学生网络规模通常远小于教师网络。当执行简单分类任务时,学生网络通常表现不错,但对于复杂的分类任务,由于参数规模的差异,学生网络的性能终究不会超过教师网络。根本原因是层数少的学生网络卷积层对图像特征的提取和理解能力不强,无法全部消化掉教师网络指导的知识特征。
针对此种情况,减小学生网络的分类任务复杂度,即只执行特定类别的任务分类,使其能专注特定类别领域的分类。在知识蒸馏框架中,只允许学生网络学习一些特定知识,并使其完全消化这部分知识,目的是使学生网络执行特定类别的分类任务时,效果将优于普通学生网络甚至教师网络。综上所述,本文提出特定知识学习,将教师网络的部分或者特定种类的图像特征知识传递给学生网络,使学生成为该特定知识领域的专家网络。
相对于传统知识蒸馏算法,特定知识学习着重强调特定二字。首先学生网络执行特定的分类任务,其必须是教师网络分类任务的子集。通常认为教师网络是一个功能强大的大型网络,其功能泛而不专;特定知识学习后的学生网络功能更加专一,不考虑学生网络对其他类别的分类性能,只验证学生网络对特定类别的分类能力,这便是任务上的特定。
其次在蒸馏过程中,为避免其他无关类别知识干扰,特意让学生网络只接受教师网络特定类别的知识。这样做的目的有:1)学生网络规模小而精,只学习特定知识使得学生网络能够使用更多神经元参与特定类的分类,不必为其他无关知识分担精力;2)教师网络是一个复杂综合的网络,其学习到的知识是丰富的,在训练教师网络的过程中,训练数据集包含了丰富种类的图片,在网络底层能够学习到种类和数量更多的基础特征,因此教师网络在网络中间层能够学习到更丰富的内容,且该部分知识具有泛化性,这是一个学生网络单独训练不可能获得的知识。
最后实现特定知识学习的方式是让学生网络只使用特定类别数据训练网络。
如图1 所示,为特定知识学习简图,正如上文中所述,特定知识学习与传统知识蒸馏之间存在着明显的不同,即特定知识学习有着特定的数据集、执行特定任务并且在蒸馏过程中传递特定知识。
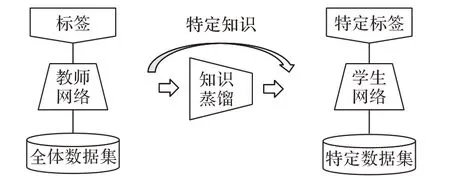
图1 特定知识学习示意图Fig.1 Schematic diagram of specific knowledge learning
3 注意力特征迁移蒸馏算法
在介绍特定知识学习算法之前,本章首先介绍注意力特征迁移蒸馏算法,本文所提算法皆基于该蒸馏算法,理解该算法便于阅读后文内容。
研究表明,人类在图像认知时,会选择性地关注到完整信息的某一部分,忽略其他不重要的信息,这种信息处理方式大大提高了人类认知图片的效率。受此启发,Zagoruyko 等将此种机制引入到知识蒸馏中,并将注意力特征图当作学生网络需要学习的知识。他提出让学生网络中间层对应地学习教师网络中间层生成的注意力特征图,以保证学生网络中间层特征图和教师网络相似。实验结果表明,这种方式是科学、正确的,在大多数情况下,注意力特征迁移算法的蒸馏效果要优于其他蒸馏算法。注意力特征迁移蒸馏算法架构如图2 所示,其中AM 表示注意力特征图(Attention Map)。由图2 可知,学生网络架构和教师网络结构需要类似,图中网络结构有三处的注意力特征图是一一对应的。
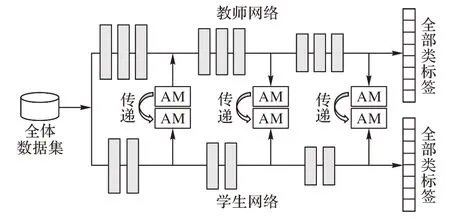
图2 注意力特征迁移结构Fig.2 Attention feature transfer structure
注意力特征迁移蒸馏算法损失函数由两部分组成:类概率损失和蒸馏损失,如式(1)、(2)所示:
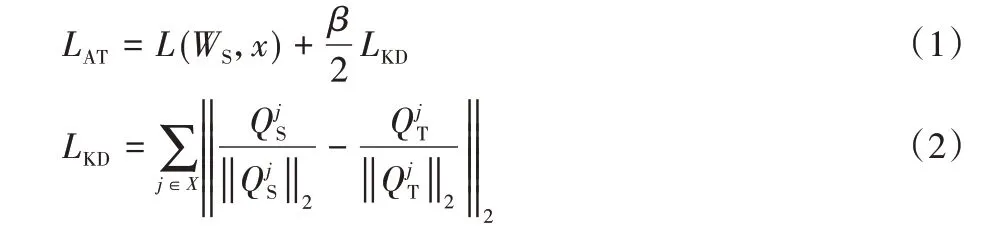
其中:L代表损失函数,L(WS,x)代表学生网络的类概率损失,LKD代表蒸馏损失;X为教师网络和学生网络中间层对应的集合,分别代表X集合中第j对学生网络和教师网络的注意力特征图;β是蒸馏损失权重,用来约束蒸馏损失对整个损失的影响。
为了获得更好的知识传递效果,注意力特征图的定义并不唯一,不同定义适用于不同的场景,供实验人员根据实验结果选择特征图定义。特征图定义公式如式(3)~(5)所示,A代表网络中间层的激活响应图,其大小通常为W×H×C,其中W和H分别代表图像的宽和高,C代表通道数量。本文实验中选用是第2个公式,此时p=2。
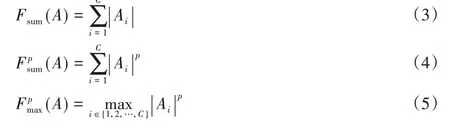
4 基于注意力迁移的特定知识学习算法
前两章介绍了特定知识学习的概念和传统注意力特征迁移蒸馏算法,本章将重点介绍基于注意力特征迁移的三种特定知识学习算法,并表述其网络架构和损失函数。
4.1 基础算法
为提升学生网络在特定类别任务的分类性能,仅使用特定类别数据集去指导训练学生网络。为叙述方便,本文将该算法称为AT_Specific,其整体网络架构如图3所示。如图3中左侧所示,将训练学生网络的数据集作预处理,将全部数据集中无关类别的数据剔除,只留下特定类别的图像数据。通过此方式,大大减弱了其他无关类别对特定类别分类任务的影响。当只使用特定类别数据训练学生网络时,蒸馏过程中也仅传递特定类别的相关知识,网络中间层模仿到的注意力特征图也是教师网络中特定类别样本的注意力特征图,所以通过知识蒸馏学生网络学习到了教师网络中传递的特定知识。观察图3 右侧,教师网络是一个全分类的分类网络,学生网络仅仅分类特定类别,这是特定知识学习算法中教师网络和学生网络之间的一个重要区别。

图3 特定知识学习基础算法结构Fig.3 AT_Specific structure
4.2 背景类知识抑制算法
在特定知识学习框架中,教师网络是一个全分类网络,训练教师网络时,使用的数据集是全体数据集,并未经过特定类别的分组处理。因此教师网络中不仅仅包含了特定类别的知识信息,还包含了其他非特定类别的图像特征。教师网络中丰富的图像特征有利有弊,好处是指导的学生网络有着不错泛化能力,在分类全部类别时有不错的分类性能;坏处是仅针对分类特定类别的任务时,其他无关类别的特征信息会造成干扰,影响分类效果。基于以上分析,本文认为在特定知识学习中,削弱甚至剔除蒸馏过程中的其他无关类别的特征知识很有必要。
将背景类的概念引申到特定知识学习中来,如果将全部类别数据当成一张图像,特定类别当成前置物体,而其他类别当成一种背景类,对于特定类别的提纯可能会有帮助。基于上述猜想,本文将全体数据集做预处理,全体数据将分为两大类:特定类数据集和背景类数据集。特定类数据集为本文要检测的特定类别数据集合,而背景类数据集为所有其他的非特定类数据。本文将该算法称为AT_Background,整体算法框架如图4 所示。图4 左侧显示全体数据集经预处理后生成了特定类数据和背景类数据。同时,在图4 右侧只有一个背景类标签,将所有原先的无关类别全部分类为背景类。这样改进的好处有两点:其一是通过整合所有无关类别,并将这些类别统称为背景类的操作,避免了人为选取不同非特定类导致性能差距较大的结果;其二是在蒸馏过程中,由于网络的中间特征图被抑制后,对网络输出影响较大,因此将其他无关类别统一为同一背景类标签是有必要且合理的。
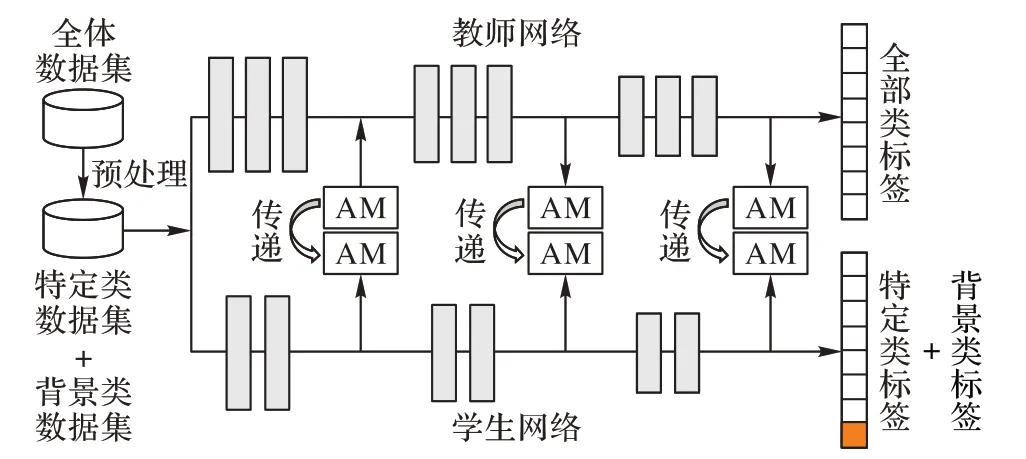
图4 背景类知识抑制算法结构Fig.4 AT_Background structure
中间传递过程中既包含学习特定类知识,又包含抑制非特定类知识,具体内部细节如图5 所示。图5 蒸馏模块中显示,当学生网络获取到特定类样本时,直接去模仿教师网络对应层的注意力特征图;当学生网络获取到背景类样本时,将教师网络的注意力特征图置零,通过学习零特征图达到抑制背景类知识的目的,其损失函数表达式如式(6)。

图5 背景类知识抑制算法内部蒸馏细节Fig.5 Internal distillation details of AT_Background
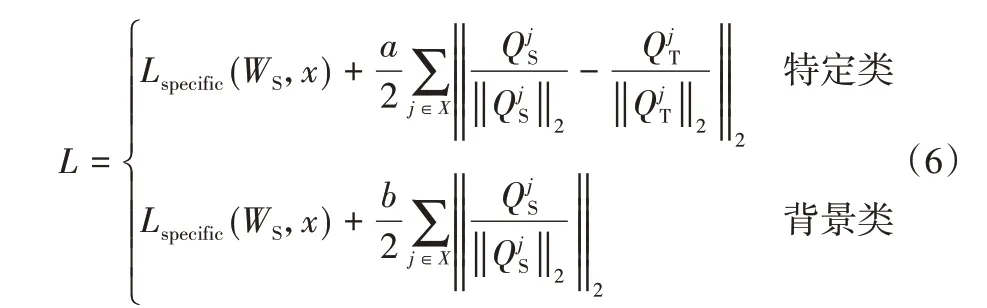
其中:L代表损失函数,Lspecific(WS,x)代表学生网络的特定类类概率损失;X为教师网络和学生网络中间层对应的集合,和分别代表X集合中第j对学生网络和教师网络的注意力特征图;a和b参数分别代表特定类损失和非特定类损失占总损失的权重。对于特定类,学生网络注意力特征图和教师网络注意力特征图越相似,其损失越低;对于非特定类,直接抑制学生网络的注意力特征图,使其激活值趋向0。最终结果使得学生网络更好地学习到教师网络特定类知识且对于非特定类敏感程度降低,减少非特定类图像特征的干扰,提升分类性能。
4.3 网络高层背景类知识抑制算法
根据神经网络可视化研究,网络底层通常是线条、曲线等基础的图像特征,高层才慢慢细分成与任务种类相关的图像特征。AT_Background 算法中在网络低层和中层作抑制操作多有不妥。因此,本文提出仅在网络高层作抑制操作的AT_Background_High 算法,该算法网络整体架构和损失函数和之前类似,在此不再赘述。
5 实验与结果
本章将使用本文提出的特定知识学习算法在CIFAR-100数据集上执行特定类别分类任务,并分别与教师网络、无知识蒸馏、有知识蒸馏学生网络比较20 个特定任务的分类准确率Acc(Accuracy)均值、精确率Pre(Precision)均值、召回率Re(Recall)均值以及F1(F1-Measure)均值。
5.1 度量标准
评判网络模型分类性能的常用指标Accuracy、Precision、Recall 和F1-Measure 多用于二分类任务中,计算公式如式(7)~(10)。依据数据集特性,本文实验中每一个特定分类任务为多分类,须将多分类转化为二分类。
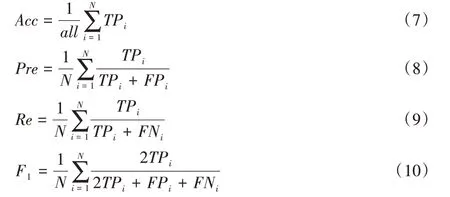
其中:all表示分类的总体样本数;N表示多分类任务中的分类数;TPi表示分类网络将图像正确地预测成第i类的样本数;FPi表示分类网络将图像错误地预测成第i类的样本数;FNi表示分类网络将图像错误地预测成非第i类的样本数。
为更好地评估分类网络的特定类别分类性能,依据数据集构成,每次都会评估20 个特定类别任务,并求其均值来体现分类网络的特定类别分类性能。
由前文可知,学生网络执行的任务通常是教师网络执行分类任务的子集,由于存在分类数目不一致,最终预测结果时教师网络由于不知道样本粗标签信息导致评分下降。例如一个5分类的分类网络随机分类正确的概率为20%,而一个100分类的分类网络随机分类正确的概率为1%,如果直接进行不同分类数目的分类网络结果对比,显然是不正确的。为公平起见,在评估全分类网络的特定类别分类性能时,提前告知预测标签范围,以保证全分类网络和特定分类网络之间的信息对等。本文实验评估都是在有先验信息的评估方式下进行。
5.2 数据集
本文选用CIFAR-100 作实验数据集。CIFAR-100 数据集是极其常用的分类数据集,包含60 000 万张训练和测试集数据。该数据集中包含100 类图像,类别与类别之间不存在交叉,完全互斥。
CIFAR-100 数据集有个独特特点:对于每一张图像,有粗粒度和细粒度两个标签,例如对于一张蜜蜂图片,其细粒度标签为bee,粗粒度标签为insects。通过两种标签,使CIFAR-100 数据更具有结构层次性。其中,CIFAR-100 数据集有20种粗粒度标签,每个粗粒度对应5种细粒度标签。
结合本文研究内容,利用CIFAR-100的结构特性,将分类一个粗粒度标签中的5 个细粒度标签作为一个特定类别分类任务。本文的主要目的就是提升学生网络在特定类别分类任务的分类性能,因此最终将对比20 个特定类别分类指标的均值。
5.3 实验结果
进行了多组对照实验来验证本文所提出的特定知识学习算法在特定类别分类领域的有效性和优越性。
首先选取编号为1 的特定分类任务结果来观察,并列出了教师网络、无知识蒸馏学生网络100 分类(StudentFS-100)、无知识蒸馏学生网络5 分类(StudentFS-5)以及结合了传统注意力特征迁移蒸馏算法(AT)学生网络的4 个指标,如表1 前四行所示。对比发现教师网络由于存在参数规模大的优势,在特定分类领域依旧表现良好,高于StudentFS-100、StudentFS-5 和AT 学生网络。对比结合传统的AT 蒸馏算法后,分类性能上确实比无知识蒸馏学生网络要高,对于StudentFS-5 准确率提升了2.20 个百分点(84.60% vs 82.40%),而对于StudentFS-100 甚至性能降低了0.60 个百分点(84.60% vs 85.20%),可见传统知识蒸馏算法在分类特定任务时的局限性。
表1 后三行代表本文提出的三种特定知识学习算法,AT_Specific 算法对比StudentFS-5 有2.8 个百分点(85.20%vs 82.40%)的性能提升,比AT 算法提升明显,验证了特定知识学习算法的有效性。为提升蒸馏过程中特定知识含量,本文又加入了抑制背景类知识的策略,实验结果显示效果提升明显,AT_Background_High 算法达到了最优,准确率均值超过StudentFS-100 网络分类性能3.6 个百分点(88.80% vs 85.20%);比传统知识蒸馏AT 算法提升了4.2 个百分点(88.80%vs 84.60%);甚至超过了规模比其大超过6 倍(7.4×106vs 1.2×106)的教师网络的分类性能,提升了0.8 个百分点(88.80%vs 88.00%)。

表1 CIFAR-100上特定分类任务1的实验结果Tab.1 Experimental results of specific category task 1 on CIFAR-100
在特定任务1 中,实验结果表明特定知识学习在特定任务分类上的优越性,为了更直观地表现本文所提算法在不同特定任务上的性能表现,本文绘制准确率柱状图,如图6 所示。图中分别对比了无知识蒸馏StudentFS-100、无知识蒸馏StudentFS-5、有知识蒸馏AT、三种特定知识学习算法以及教师网络的20个特定类别分类准确率。由图6可以看到绝大部分特定任务中特定知识学习算法都有着不错的提升,尤其对于任务编号14 的特定分类任务这种准确率低、分类难度大的任务,准确率提升较为明显。这说明特定知识学习更适用于分类难度相对较大的特定类任务,让学生网络集中精力学习该特定类抽象特征的策略是有效的。观察图中算法结果对比,特定知识学习算法中,绝大多数情况下AT_Background_High算法表现更好。最终的结果也验证了通过抑制其他无关类别即背景类知识以及仅在网络高层作抑制操作的正确性。

图6 七种网络在20个特定类别任务的准确率柱状图Fig.6 Histogram of accuracy of 7 networks in 20 specific category tasks
6 结语
本文结合知识蒸馏,首次提出特定知识学习,旨在提升分类网络特定类别分类性能。在此基础上,提出三种特定知识学习算法,并结合抑制背景类知识蒸馏策略以及仅高层作抑制的调整,有效地提升了分类网络在特定类别领域的分类性能。大量对照实验的结果表明,本文提出的特定知识学习算法对于网络在特定类别分类领域的分类效果有着明显提升,最优结果甚至超越了规模超其6 倍的教师网络性能。特定知识学习非常契合工业场景,本文所提算法具有一定的实用性和重要意义。
