基于视觉特征去噪和DOM树的网页信息提取方法
2022-01-04陈壮葛斌
陈壮, 葛斌
安徽理工大学计算机科学与工程学院, 安徽 淮南 232001
0 引言
信息块是由网页的主要内容块组成.非信息块诸如导航菜单、底部的联系人信息以及广告等,都是噪声信息.要想提高信息提取的性能,必须要去除这些噪声信息,并快速准确地对网页进行分割,从而获得组成块并对其进行准确的提取.
在网页信息提取方面,文献[1,2]使用基于统计的网页信息提取方法,主要根据网页中信息的分布情况来决定提取的内容.缺点是当网页中字符较少时,会导致提取错误的信息.文献[3,4]使用基于网页分割的信息提取方法,利用网页中的一些特征对网页进行分割,再从分割块中选取包含网页信息的块并提取网页信息.缺点是信息块内容字符数较少,而噪声信息较多时,提取的块可能出错.文献[5]提出了一种使用自然语言处理技术提取信息的方法.缺点是未充分利用以文本格式编写的注释.文献[6]通过使用字符串方法和其他信息快速提取内容,而无需创建DOM树.文献[7]实现了对复杂网页中数据记录的提取.缺点是对于一些复杂的网页,该方法去除噪声信息的效果不是太理想.文献[8]可以从多种类型的网页中抽取正文信息.缺点是对于细粒度结构化Web信息抽取的精度效果仍达不到最理想的程度.文献[9]通过三个启发式规则的加权平均获得组成块分数,得分最高的就是信息块.缺点是只使用紧密度中心性显得太片面,不足以表示块的中心性.
1 所提出的方法
1.1 网页预处理
1.1.1 视觉特征去噪
通过查看网页发现,大量的网页都是由Head、Foot、Left、Right、Center五部分[10]或者其中某几部分组成,其中大多数的网页均含有Head、Foot区域.
所提出的方法,先将网页转化成DOM结构,并得到页面的大小;根据页面大小获得上下左右四部分阈值,记为W1,W2,W3,W4;再通过对网页内元素的绝对坐标以及实际大小与获得的阈值进行比较,通过此方法划分区域.若任意元素E,所占区域上的左上角原点绝对坐标为(a,b),元素所占区域大小为(width,height).如果E.b + E.height <=W1,则E属于Head区域;如果E.b>=W2,则E属于Foot区域;如果E.a + E.width <=W3,则E属于Left区域;如果E.a >= W4,则E属于Right区域,所有不属于Head,Foot,Left,Right的区域作为结果返回.设计的算法如下所示:
算法1 Visual Denoising
输入:页面大小阈值W1,W2,W3,W4,元素E,元素绝对坐标(a,b);
输出:网页中心区域t.
Begin
1 if b+height<=W1then //(width,height)为元素所占区域大小
2E∈Head; //Head、Foot、Left、Right为网页区域
3 else ifb>=W2then
4E∈Foot;
5 else ifa+E.width<=W3then
6E∈Left;
7 else ifa>=W4then
8E∈Right;
9 else
10E∈t;//元素E属于Center部分
11 return t; End
1.1.2 正则表达式去噪
在经过视觉特征去噪后,仍可能包含未去除干净的噪声信息,需要通过正则表达式过滤噪声标签的方式再次去除.噪声信息如表1所示.

表1 噪声信息
1.2 网页分割和信息块提取
本文以一个简单的方式分割网页,首先将网页沿垂直方向拆分成列,对拆分后的每部分进行判断,是否可以进行沿垂直方向拆分为列或者沿水平方向拆分为行;然后再对于拆分后的每行或者每列,再继续进行沿垂直方向拆分或者沿水平方向拆分.在此基础上,重复进行上述操作,如图1所示.

图1 网页拆分图
本文将网页转换成DOM树结构,在此基础上,自下向上遍历中生成一个新的网页视觉树.在遍历的过程中,为了提高网页信息处理的效率,进行两次去除噪声操作:利用视觉特征和正则表达式去除那些噪声节点,对通常不含正文文本内容的标签做剪枝处理,得到一个简洁的DOM树.并为新的视觉树中每个提取的节点分配一个判断符:即为每个节点标记两个变量,代表其子树中是否存在沿垂直方向拆分.
构建网页视觉树之后,需要识别组成块.本文从视觉树对应的根节点展开新的可视化树.首先需要判断是否进行了沿垂直方向拆分,如果当前节点的子节点有子节点,即进行了沿垂直方向拆分,则增加一个粒度,继续扩展当前节点的子节点;如果当前子树只有沿水平方向拆分,则不进行扩展.如此重复进行上述操作,当整个树不再进行扩展时,所有的叶节点都是预期的组成块.通过上述过程,就可以获得网页的所有组成块.接下来就是从这些组成块当中提取出信息块.信息块通常是最靠近网页中心的块,通过上述过程后标记数最多的块是所有块中面积最大的块.本文在视觉去噪时已经输出的就是Center部分,只需要使用两个启发式规则:信息块是通过上述网页分割过程后标记数最多的块,是所有组成块中面积最大的块.通过加权平均来获得信息块的分数,就能进行信息的提取,分数最大的组成块即信息块.
如图2所示,图中①代表视觉去噪结果,②代表组成块,③代表信息块.计算公式如下:

图2 信息块提取图
Score(bi)=α×Areai+(1-α)|bi|
(1)
式中:|bi|为块bi中标记数目,Area为块bi的面积,得分最高的块是信息块.
2 实验评估
在本节中,对本文方法进行了评估,将其与文献[1]中PPL、PPR、CEPR算法和文献[9]算法进行了比较.
2.1 数据集和评估指标
2.1.1 数据集
利用三个数据集来验证本文提出方法的性能.在表2中显示数据集的详细信息.

表2 三个数据集统计
2.1.2 评估指标
使用准确率,召回率和F1量度[11]来评估本文信息提取方法的性能,计算公式如下所示:
(2)
(3)
(4)
其中S1表示抽取结果的集合,而S2表示手工标记结果的集合.
2.2 实验评估
2.2.1 实验结果
本文实验结果如下表3所示

表3 本文实验结果(%)
观察表4到表6发现,在人民网数据集、搜狐网数据集、新浪网数据集上,本文的方法都能取得较高的准确率,但召回率相对较低,这是因为人民网、搜狐网包含大量的导航或者评论内容,导致错误地将其当成正文信息并提取.相对于文献[1]中PPL、PPR、CEPR算法和文献[9]算法,本文方法在准确率上高于另外几种算法,在召回率上,本文方法高于文献[1]中的PPL、PPR、CEPR方法,但是在部分数据集上低于文献[9]中算法.对于F1值,本文的方法也优于其他几种网页信息提取方法.
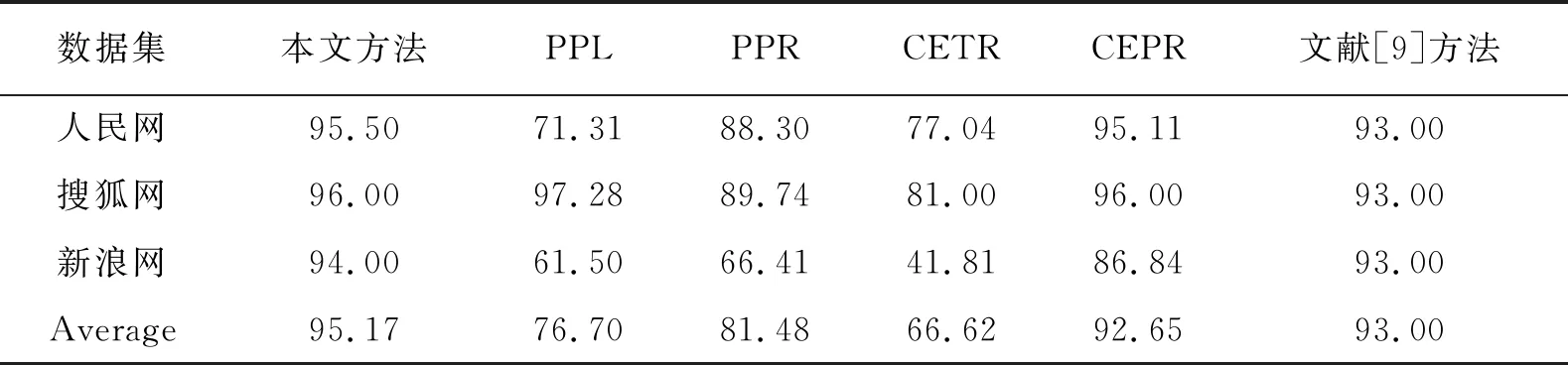
表4 准确率(P)对比结果(%)

表5 召回率(R)对比结果(%)
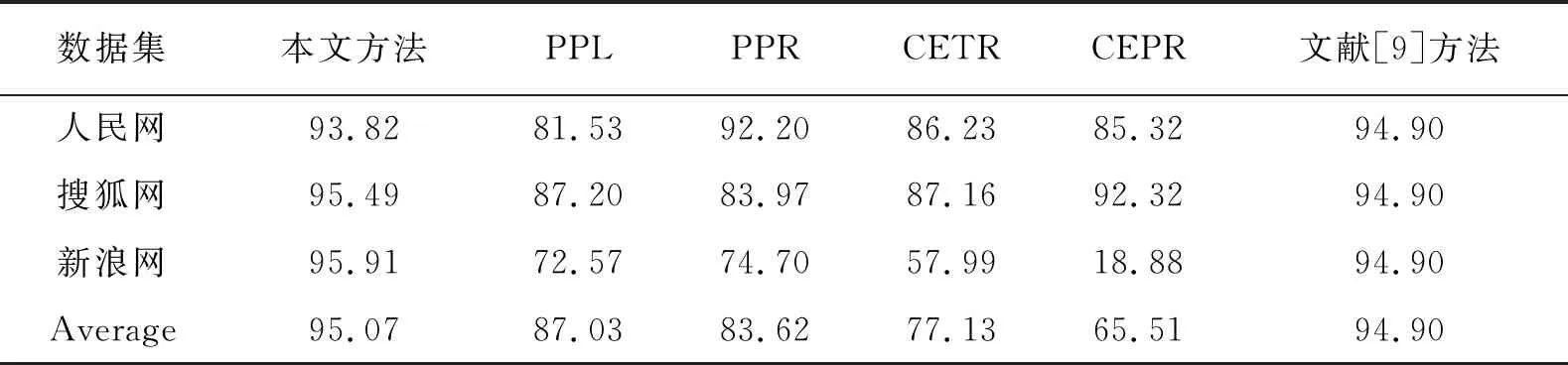
表6 F1值对比结果(%)
2.2.2 参数分析
参数α是用于平衡两个启发式规则之间的重要权值,若α值太高,则组成块面积会占据更多的权值,同时可能会导致获得错误的结果.通过一些先前的观察,决定将α权值设置在0.4以内,实验结果如图3到图5所示.
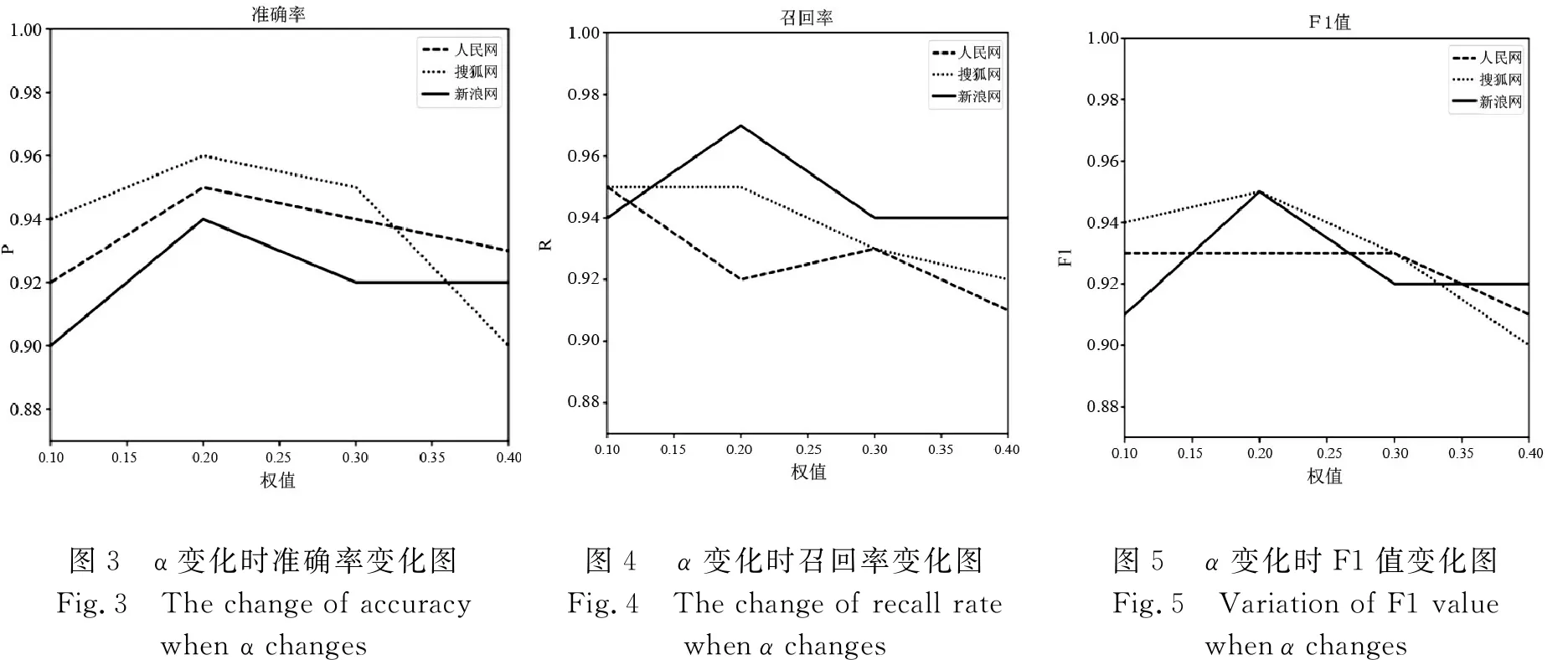
通过观察图3到图5可以发现,当参数α大于或者小于0.2时,准确率、召回率、F1值都没有达到最好的效果,因此本文方法实验参数设置为0.2.
3 结语
本研究提出了一种基于视觉特征去噪和DOM树的网页信息提取方法.与其他几种方法相比,准确率有所提高.同时,本方法也适合许多网站,但是在个别网页当中也会存在不准确的信息块提取.比如正文文本较短,可能会导致提取错误;同时由于本算法主要依赖元素的位置信息,错误的位置将导致错误的划分,它将进一步影响信息块提取的准确性,这将是今后方法改进的方向.
