城市轨道交通精细化客流预测系统设计与实现
2022-01-04高彦宇许心越陈丽丹
孙 琦,高彦宇,许心越,陈丽丹
(1. 北京轨道交通路网管理有限公司,北京 100101;2. 北京交通大学 轨道交通控制与安全国家重点实验室,北京 100044)
近年来,北京城市轨道交通规模发展十分迅猛。截至2019年底,北京轨道交通路网运营里程达到699.3 km,运营线路23条,运营车站共计405座,最高年度日均客流达1 086万人次。轨道交通网络规模的不断扩大和客流量的不断增加,导致轨道交通拥挤、服务质量下降,铁路网客流结构、波动规律异常复杂[1],铁路网形式变化比较快,列车粗犷式配置很容易导致大规模拥挤或者晚点,如何精细化城市轨道交通客流预测,快速响应路网波动,实时配置运力资源已成为运营管理者迫切需要解决的问题。
目前,国内很多主要城市的轨道交通运营企业建设相应的客流预测系统。这些客流预测系统大多依据不同的客流预测方法或客流预测模型,王莹等人[2]提出季节时间序列模型(SARIMAM,seasonal ARIMA model)对北京地铁进站客流量进行预测,Sun等人[3]提出了小波-SVM混合方法对北京地铁系统的换乘客流进行预测。Roos等人[4]提出了利用不完整历史观测数据预测短期客流的动态贝叶斯网络方法。Li等人[5]提出用径向基函数(RBF,Radial Basis Function)神经网络预测单站客流。Jiao等人[6]提出基于贝叶斯组合和非参数回归的改进卡尔曼滤波模型来预测北京地铁13号线高峰时段的客流。梁强升等人[7]提出一种融合循环门控单元和图卷积神经网络的城市轨道交通客流预测模型(GCGRU,Graph Convolutional Networks and Gate Recurrent Unit)。
当前大部分的客流预测系统采用的预测模型单一、提供的预测客流指标不全,时空粒度较粗,多场景的适用性不足。因此,亟须开发一套能够适用于多场景的全指标的精细化精准客流预测系统,实现支持基于OD的多种精细化客流预测模型和方法,为多场景下调度指挥和客运管理提供高准确度、精细化时空粒度的客流预测数据支持。
1 轨道交通客流预测现状及需求分析
1.1 现状分析
当前,我国的城市轨道交通已经进入快速发展时期,超大型城市线网规模快速扩大,导致城市轨道交通客流激增、客流增长规律复杂和运营场景多样化。现场客流预测系统存在以下不足:
(1)既有预测系统存在系统功能不全,适用的场景具有局限性;
(2)既有预测系统存在预测粒度不够精细,不能完全刻画客流演变过程,无法支撑日常运营的全部业务。
1.2 需求分析
通过对地铁运营公司现场业务进行分析,发现不同场景下路网客流量和客流规律等不同,需要在不同场景下为各调度指挥和客运管理部门持续提供精细化客流预测数据支持,总体需求主要包括以下3个方面。
(1)在常规场景下,通过用户的设定或选择机器学习模型实现未来预测日期的客流预测功能,输出客流进出站、OD等精细化客流预测结果。
(2)在节假日场景下,通过用户的设定或选择针对特殊日期单独的预测方法,对路网结构进行调整、对模型参数进行设定,实现在节假日场景未来预测日期的客流预测功能,输出客流进出站、OD等精细化客流预测结果。
(3)在新线场景下,通过用户的设定或选择加权平均法模型,对路网结构进行调整、对模型参数进行设定,实现新线开通后未来预测日期的客流预测功能,输出客流进出站、OD等精细化客流预测结果。
2 系统方案
2.1 总体设计
该系统主要由数据准备、客流预测及分析、数据提供3个部分组成,系统总体结构,如图1所示。
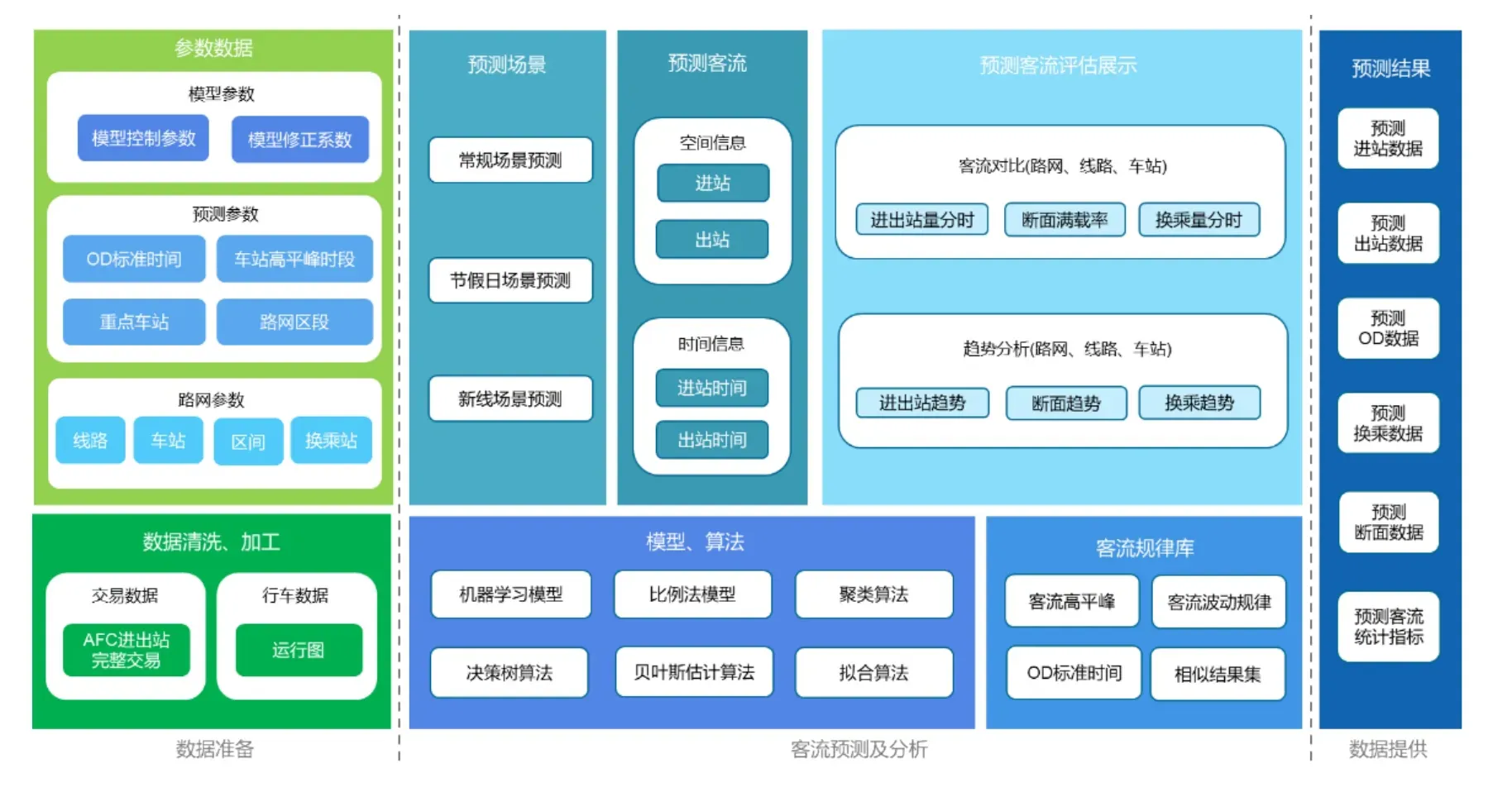
图1 系统总体结构
(1)数据准备部分主要是准备数据,以及对业务数据进行处理,包括参数数据和业务数据。a. 业务数据有交易数据和行车数据;b. 参数数据有模型参数、预测参数和路网参数。
(2)客流预测及分析部分主要包括预测场景、预测客流、预测客流评估展示、预测算法和客流规律库。a. 预测场景包括常规场景预测、节假日场景预测和新线场景预测,对应的预测模型是机器学习模型和加权平均法模型;b. 预测客流模块支持根据用户的设定或选择不同的模型或算法实现未来预测日的客流预测功能,输出客流进出站、OD等精细化客流预测结果;c. 预测结果评估模块实现预测数据和实际数据的对比分析,通过对比分析发现预测模型或算法的问题,进行优化调整;d. 预测算法有机器学习模型、比例法模型和聚类算法等;e. 客流规律库包括客流高平峰、客流波动规律、OD标准时间及相似结果集。
(3)数据提供部分主要是预测数据对外支撑,包括预测进站量、预测出站量、预测断面满载率、预测客流来源去向等。
2.2 技术架构设计
本系统采用的技术构架包括展示层、访问层、大数据存储计算与微服务层和基础数据交换层,如图2所示。

图2 系统技术架构
(1)展示层采用Html5进行用户界面展示,采用LayUI和Finereport完成页面UI交互控制,部分矢量图像采用基于Html5的js和canvas技术实现。
(2)访问层采用Ngnix作为系统统一入口,并通过API Gateway对外提供服务访问接口。
(3)大数据存储计算与微服务层基于Hadoop各类数据计算与存储服务,主要有HDFS分布式文件存储、Spark内存计算、Hive/SparkSQL离线分析、Flink流数据处理、HBase海量数据查询、Kafka分布式消息、ElasticSearch分布式搜索引擎等,其中SparkMlib和TensorFlow提供的AI基础框架为各种预测场景提供底层算法库支持,Spring cloud的微服务器框架为应用提供基础运行环境。RocketMQ为系统提供消息处理引擎,Redis和Oracle为系统的各类预测和清分数据实时处理提供内存计算环境。
(4)基础数据交换层采用MQ队列或FTP方式实现外部数据接入,并为外部系统提供客流预测数据服务。
2.3 接口
接口主要是为了接收系统所需要的数据和提供系统生成的结果数据。接收数据主要包括历史城市轨道交通自动售检票系统(AFC,Automatic Fare Collection)交易数据、每日AFC交易数据、运行图数据和其他参数类数据。接口方式主要通过FTP、MQ队列、HTTP请求等方式实现。
2.4 数据处理
源数据来自于各个业务系统,指标口径对不上,会出现不一致、重复、不完整、存在错误或异常(偏离期望值)的数据,所以需要数据清洗,其主要步骤如下。
(1)缺失值清洗:主要包含确定缺失值范围、去除不需要的字段、填充缺失内容、重新取数。
(2)格式内容清洗:a. 格式内容问题有时间、日期、数值和全半角等显示格式不一致,需将其处理成一致的某种格式;b. 内容中有不该存在的字符,最典型的就是头、尾、中间的空格,也可能出现姓名中存在数字符号、身份证号中出现汉字等问题,这种情况下,需要以半自动校验、半人工方式来找出可能存在的问题,并去除不需要的字符;c. 内容与该字段应有内容不符,需要详细识别问题类型。
(3)逻辑错误清洗:主要包含去重、去除不合理值和修正矛盾内容,其中,不合理数据主要有日期、消费情况、出行里程等信息。
(4)非需求数据清洗:a. 该步骤主要是把不需要的字段删除,历史AFC交易数据、每日AFC交易数据和运行图数据的主要对数据格式、重复数据、异常字段数据修正等信息进行清洗;b. 清洗完成后将不同方式接入的数据进行集成存储,保存至一个一致的数据存储中;c. 对海量的数据的数据格式进行设计定义,对原有格式进行转换,转换成适合客流预测系统的数据形式。
3 关键技术
3.1 聚类算法
根据路网拓扑结构,将路网划分为不同区段,得到区段集合S=[trans1,sta1-sta2,trans2,sta3-sta4-sta5,···], 其中,transn表 示换乘站,staa-···-stab表示同一条线路上的连续非换乘站;利用AFC系统中的乘客刷卡记录数据,统计路网n个车站中第i个车站在日期j的第k个时段(高峰时段与平峰时段)去往路网中其他车站的OD;利用前面得到的各车站、各日期、各时段的OD,计算各车站、各时段的重点去向车站集合I。具体计算流程如下。
(1)计算各车站各时段的进站客流总量中去向其他各车站的客流量的占比,作为各去向车站的贡献度,计算公式如下:

其中,odij表示从c站到d站的OD;Rij表示d 站作为c站的去向车站的客流贡献度。
(2)车站总体客流去向服从幂律分布,将不同去向贡献度下的累积车站数,取对数后进行线性回归,计算样本中车站数的对数的下四分位数,将所得数值带入回归函数,计算得到去向贡献度临界值r。
(3)统计去向贡献度大于步骤(2)中所得的去向贡献度临界值r的去向车站,作为车站的重点去向车站集合I。
(4)利用步骤(2)和步骤(3)得到的重点去向车站集合I及区段集合S,构成车站去向集合D,每个车站在工作日(双休日)的不同时段有不同的去向集合。将车站i在日期j的第k时段,以重点去向车站l为去向的客流量Niijkl,以及以除重点去向车站之外的区段m为去向的客流量Nsijkm,构建得到聚类样本为: [Niijk1,Niijk2,···,Niijkl,Nsijk1,Nsijk2,···,Nsijkm]。
(5)车站i在日期T的聚类样本形式如下:

其中,Si(T)为车站i在日期T的聚类样本;pij(k)为车站i在时段k内去往重点车站j的客流量;rij(k)为车站i在时段k内去往区段j的客流量(若区段j内包含重点车站,则扣除去往重点车站客流量);u为重点车站个数;v为区段个数。
(6)采用z-score标准化法将聚类样本标准化为均值为0,方差为1的数据。
利用AP聚类算法对各车站各特征日各时段下所有日期的标准化聚类样本进行聚类,得到各车站各日期各时段的聚类结果。
3.2 决策树算法
为了实现自动化预测,模型需要实现根据预测日期特征自动选择采用相似规律的历史客流作为预测依据。因此,采用聚类形成的类别样本数据构建决策树模型,并将构建后的决策树模型用于输出预测日期所属的历史规律类别。决策树采用ID3算法,算法输入形式为历史数据每日各时段的特征及该时段车站的进站客流的聚类类别。
算法核心是在决策树各个节点上应用信息增益准则选择特征,递归构建预测各车站各时段进站客流的决策树。2018年1、2季度苹果园站的进站客流 聚类结果构建的决策树,如图3所示。

图3 2018年1、2季度苹果园站的进站客流决策树
将预测日的日期特征输入构建好的决策树,得到预测日所属的日期类别。假设要预测苹果园站2018-06-29高峰时段(PEAK1)的进站客流,该预测日的输入特征为[第2季度,工作日,星期五],决策树结构的第1个特征为季度,将2018-06-29划分到第2季度的分支;决策树结构的第2个特征为星期几,继续将2018-06-29划分到星期五的分支;决策树的最后一个特征为日期类型,按照2018-06-29的日期类型(为工作日)最终确定所属类别为类别6。
为了提高决策树的泛化能力,需要对树进行剪枝,把过于细分的叶节点去掉而回退到其父节点或更高的节点,使其父节点或更高的节点变为叶节点。将数据集划分成训练集和验证集2个部分,用训练集决定树生成过程中每个节点划分所选择的属性,验证集在剪枝中用于判断该节点是否需要进行剪枝。
4 系统设计及应用效果
4.1 常规场景客流预测设计
4.1.1 预测方案
在常规场景下,基于历史客流数据和路网拓扑数据,运用聚类方法[8]和机器学习方法构建机器学习预测模型,对目标日期分时段OD进行预测。机器学习预测模型是一个全自动、自学习式的预测模型,是通过对历史客流分布和路网拓扑数据进行聚类,总结出不同特征日下的客流分布模式类别,使用预测日的日期特征寻找历史日期中与之同类别的日期集合,利用日期特征相似程度对同类别日期进行加权,并利用客流月份变化趋势修正系数[9]对同类别日期进行修正,从而拟合得到预测日分时OD。常规场景客流预测流程,如图4所示。

图4 常规场景客流预测流程
4.1.2 效果分析
图5和图6分别是在常规场景下路网分时进、出站客流预测情况对比,可以看出预测趋势和实际情况相符,进站量平均相对误差为0,出站量平均相对误差为5.13%,这说明该算法取得了良好的预测效果。

图5 常规场景下进站量对比折线
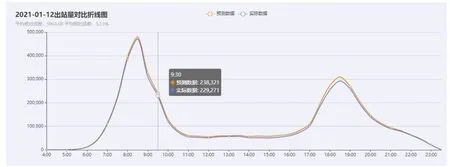
图6 常规场景下出站量对比折线
4.2 节假日场景客流预测设计
4.2.1 预测方案
由于每年节假日天数少,客流结构特殊,且每年路网结构都会发生变化,难以积累足够多的样本数据进行聚类预测。所以需要设计单独的预测方法针对特殊日期进行预测,具体预测流程,如图7所示。
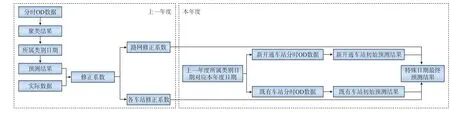
图7 节假日场景客流预测流程
(1)使用上一年度对应节假日期之前的历史分时OD客流进行聚类,获得聚类结果。然后,利用上一年度节假日期分时OD,通过与聚类中心距离判断节假日所属类别,获得相同类别日期集合。
(2)使用同类别日期客流加权拟合预测上一年度节假日期分时OD,并与实际值进行对比,获得各车站的修正系数,以及路网修正系数。
(3)将上一年度节假日相对位置的同类别日期客流数据映射到本年度中,获得本年度节假日日期同类别日期组合。
(4)利用本年度节假日期同类别的日期客流,加权拟合获得各车站初始预测客流,利用前面得到的修正系数,对各车站的初始预测客流进行修正。对于新线开通的车站,使用路网修正系数进行修正,得到最终的预测客流。
4.2.2 效果分析
图8和图9是分别在节假日场景下路网分时进、出站客流预测情况对比,可以看出预测趋势和实际情况相符,进站量平均相对误差为0,出站量平均相对误差为2.56%,这说明该算法取得了良好的预测效果。

图8 节假日场景下进站量对比折线

图9 节假日场景下出站量对比折线
4.3 新线场景预测设计
4.3.1 预测方案
新线开通后,由于路网结构发生变化,第1个特征日没有对应的历史规律可以用来预测,同时在开通初期相同路网拓扑下的历史客流数据样本规模小,决策树不能对所有车站都输出预测结果,因此对于新线客流的预测需要制定专门的预测方法。
(1)第1阶段
第1阶段为新路网拓扑运营第1个星期,对于第1个特征日,既有站使用上一年度数据进行聚类预测,辅以人工修正。新开通车站使用专家预测值。对后续日期,使用既有相同特征日数据进行拟合。第1阶段预测流程,如图10所示。
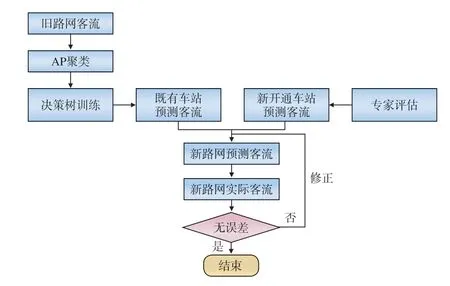
图10 第1阶段预测流程
(2)第2阶段第2阶段为新路网拓扑运营第2~4个星期,由 于样本量规模限制,决策树不能完整预测所有车站,对于决策树能够预测的车站及时段,采用常规预测方法进行预测;对于不能输出聚类类别的车站,使用设定规则筛选相似日期类别。第2阶段预测流程,如图11所示。

图11 第2阶段预测流程
(3)第3阶段
第3阶段为新路网拓扑运营第5个星期及以后,正常使用决策树进行类别预测并拟合预测客流,具体预测流程,如图12所示。

图12 第3阶段预测流程
4.3.2 效果分析
图13和图14分别是新线接入场景下路网分时进、出站客流预测情况对比,可以看出预测趋势和实际情况相符,进站量平均相对误差为0,出站量平均相对误差为0,这说明该算法取得了良好的预测效果。

图13 新线场景下进站量对比折线

图14 新线场景下出站量对比折线
5 结束语
本文开发的路网精细化客流预测系统已经在北京轨道交通指挥中心投入实际使用,为生产服务平台(TCC系统)等多个业务系统持续提供精细化路网客流预测数据支撑,取得了良好的效果,为北京市轨道交通有预见性地进行网络化调度指挥和客运管理发挥了重要作用。
未来需要对北京轨道交通路网客流规律,尤其是特殊场景的客流规律进行更为深入的分析,不断增加和优化客流预测模型和算法,提高节假日、新线接入、大型活动等多种特殊场景的客流预测准确度。
