基于自动编码器的锂离子电池状态评估方法
2021-12-29韩云飞段善旭程时杰
韩云飞,谢 佳,蔡 涛,段善旭,程时杰
(强电磁工程与新技术国家重点实验室(华中科技大学),湖北省武汉市 430074)
0 引言
近年来,在国家和地方政府的推动下,电池储能系统建设规模不断扩大[1]。锂离子电池因为具有循环稳定、比能量/比功率高等优点,在电池储能系统上得到广泛应用[2]。在线评估电池的状态对于确保电池的安全性和可靠性至关重要。其中健康状态(SOH)是评估电池老化状态的指标之一,一般认为SOH 为电池当前最大可用容量与初始额定容量的比值[3]。准确的SOH 估计对于指导电池储能系统的安全可靠运行具有重要意义。
锂离子电池的状态估计方法主要分为基于模型的方法和数据驱动方法[4]。基于模型的方法从老化机理出发对电池进行建模,例如P2D 模型[5-6]。基于模型的方法具有较高的精度[7],然而建立模型需要求解复杂的偏微分方程,使其难以在电池管理系统(BMS)中实时应用。
目前,机器学习技术的发展使得数据驱动方法在电力系统及综合能源系统受到广泛关注[8],其中的一个应用层面即为对电网设备进行状态评估和故障诊断[9]。为了准确地评估及预测电池的老化状态,模型的输入需要能够充分反映电池的状态特征。文献[10-11]分别选择阻抗谱和增量容量分析(ICA)曲线作为输入特征,阻抗谱和ICA 能从机理上解释电池的老化,但均需要特殊的测试条件,难以在线应用。文献[12-14]采用深度学习技术,从电池的电压、电流、温度等原始参数中提取电池的老化信息。虽然深层神经网络具有从原始数据中提取深层特征的能力,但多维的原始数据需要更大的网络去拟合。由统计学习算法实现的人工智能可以从人类的监督中获益[15],即根据人类领域知识的初步特征选择可以提升机器学习算法的性能。因此,本文结合特征选择与机器学习模型进行电池的状态评估。
上述电池的SOH 估计方法均为监督式模型,即训练数据需要有对应的真实值标签。而在实际应用中电池的可用容量受到充放电倍率、温度等影响[16],电池理论上的当前最大可用容量需要在实验室进行测试,这给建立监督机器学习模型造成了阻碍。文献[17]对基于深度学习的异常检测方法进行了综述,一些机器学习技术已被用来检测工业系统中的损伤,其中自动编码器是无监督异常检测方法的核心。在异常检测中使用自动编码器的常见方法是在健康的数据样本上训练模型,自动编码器可以很好地重构健康的数据,而对于异常样本会产生较大的重构误差。基于电池状态评估与异常检测的相似性,本文将自动编码器应用在电池的状态评估上,提出一种结合特征选择与无监督机器学习的方法。首先,分析电池的老化数据,从电压-容量曲线中选择具有电化学意义的输入特征,并验证卷积神经网络(CNN)从输入提取深层次特征的能力。然后,建立基于CNN 的自动编码器模型,计算自动编码器模型输入、输出的重构误差,并采用逻辑回归根据重构误差对电池进行状态分类。最后,在MIT-Stanford数据集上进行实验,验证了该方法的有效性。
1 特征选择
机器学习模型的性能受到输入数据的表现形式影响。从原始的电池数据中选择有意义的特征属性能有效提升模型的性能,因此有必要对模型的输入特征进行选择。
实验使用的数据集[18]的详细测试内容见附录A。附录A 图A1 展示了6 个电池的放电容量曲线。电池的充电模式各不相同,但都采用相同的放电方法。随着充放电循环电池的容量逐渐衰减,定义电池的循环寿命为容量衰减至80%的额定容量时的循环次数。可以发现,电池的老化特性存在差异,充电策略对循环寿命有着深远的影响。
文献[19]提出了一种机器学习方法,利用电池的前100 圈循环的放电电压曲线预测电池的循环寿命。该数据驱动方法选择电压-容量曲线的统计量作为模型输入特征。具体而言,以Q(V)表示放电容量为电压的函数,如附录A 图A2 所示,随着电池的老化,电池的放电容量随着电压演变。结果表明,在使用第10 圈和100 圈循环的Q(V)差值的方差作为唯一模型输入时,寿命预测模型在测试集上可以达到11%的平均百分误差。这一结果突出了电压-容量特征在电池诊断和预测上的强大能力。该特征以电压作为自变量,因为电池的工作电压区间比较固定。而以电压为因变量,该特征描述了电化学过电位的概念。过电位为电极的电位差值,是一个电极反应偏离平衡时的电极电位与这个电极反应的平衡电位的差值。在等效电路中,过电位为欧姆内阻和极化内阻上的电压之和。随着电池的老化,极化加剧,过电位发生变化,在电压-容量关系上体现为曲线的偏移,因此电池的电压-容量特征与老化状态存在对应关系。
从附录A 图A1 和图A2 可以发现,在早期循环中电池老化不会导致明显的容量衰减,但在电压-容量曲线中会有所体现。以电池“b3c7”为例,电池在第100 圈和200 圈的放电容量分别为1.069 Ah 和1.068 Ah,而在附录A 图A2 的电压-容量曲线中,第100 圈和200 圈的Q(V)曲线存在明显偏移。这可能是由于去锂化负极活性物质的损失导致Q(V)在容量不变的情况下发生变化。当负极相对正极过量时会出现这种现象,而这在商用锂离子电池中是比较普遍的[20]。因此,去锂化负极的损失改变了锂离子储存的电位,而没有改变总容量[21]。从电化学的角度来看,随着电池老化,Q(V)的变化表现为曲线下面积的变化,循环圈数N和M之间的面积差为:
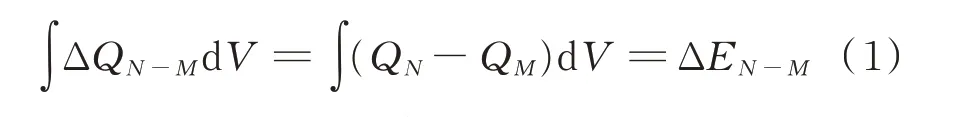
式中:QN和QM分别为第N圈和M圈电池的容量值;ΔEN-M为第N和M圈释放能量的差值;ΔQN-M为在给定无穷小电压区间dV上第N和M圈循环的累计容量的差值。随着电池的老化,电池所能存储和释放的能量有所降低。
基于上述分析,本文从电压-放电容量曲线中提取输入特征。具体地说,给定采样时的电压和电流可以计算放电容量。为了使不同电池和循环的电压容量数据标准化,采用样条函数对原始数据插值获得连续的电压-容量曲线。3.5 V 至2.0 V 的电压间隔被量化为W个电压区间,区间的右端点Vi为:

电压点对应的容量[Q1,Q2,…,QW]为模型输入特征,其中Qi为Vi处电池的累计放电容量。为了便于计算,W取1 000。由于电池实际运行不会进行完整的充放电循环,为了模拟实际工况从[Q1,Q2,…,Q1000]中选择部分片段数据作为模型的输入,例如[Q250,Q251,…,Q749]表示电池从3.125 V放电至2.375 V 的数据,在实际应用中只需要记录在该电压区间循环的电流数据,而不需要对电池进行完整的充放电。由附录A 图A2 可知,随着电池的循环老化,过电位发生变化,电压-容量曲线产生偏移。不同的老化状态对应了不同的电压-容量片段数据,因此该数据能作为评估电池状态的输入特征。
2 基于数据驱动的状态评估模型
基于上述的输入特征,选择自动编码器建立电池状态评估模型。自动编码器是一种可以用于异常检测的神经网络模型,采用健康的数据训练自动编码器,自动编码器可以学习健康数据的内部表示(internal representation),训练完成的模型能较好地重构健康数据的输入,而对于没有遇见过的异常数据的分布,编码器模型难以较好地重构输入,因此重构误差能衡量样本的数据分布与训练的健康数据的差异。应用在电池的状态评估上时,采用健康的电池数据训练模型,使其学习健康电池的特征。随着电池的老化,电池状态偏离训练数据的状态,相应的模型重构误差也会增大,因此采用重构误差作为评估电池状态的指标。状态评估框架如图1 所示,依据电池的老化机制将数据划分为健康和异常,其中健康和异常的定义在2.1 节介绍,使用健康数据训练自动编码器模型,将模型的重构误差作为逻辑回归的输入,对电池的状态进行分类。

图1 锂离子电池状态评估方法框架Fig.1 Framework of state evaluation method for lithium-ion battery
2.1 数据划分
为了使用健康状态的数据训练自动编码器模型,需要将电池数据划分为健康和异常两类。根据电池的老化机理,在早期循环中电池的容量衰减主要是由不稳定电解质导致的固体电解质界面(SEI)层增长引起的,SEI 层的生长与循环次数或时间有近似的平方根关系[22]。在某个时间点之后容量开始迅速下降,文献[16]认为机械性能下降是造成这种现象的主要原因。在这一快速老化阶段,电极颗粒之间以及颗粒与集流体之间的电接触损失变得更加严重,因此其对电池容量损失的影响将远远超过SEI 层稳定生长的影响。在这一阶段,电池会快速循环到其寿命结束,即意味着电池的容量降低到标称容量的80%。这一描述与附录A 图A1 中电池的容量先缓慢下降、在某一节点后迅速衰减的现象相符。本文将容量快速衰减阶段的电池数据标记为异常。文献[22]通过检测容量衰减曲线中的曲率变化来检测异常老化行为。曲率k的计算公式如下。
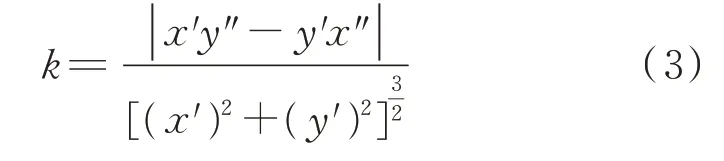
式中:x为循环圈数的平方根;y为电池容量。
附录B 图B1 显示了电池的曲率和容量随循环变化的曲线。为了提升该方法的鲁棒性,采用95%分位数来确定分割数据的阈值,即定义曲率数值中由小到大95%位置的状态为健康和异常的分界点。
健康数据被随机分为3 个部分,80%用于训练模型,10%用于训练期间的验证,10%用于测试模型在健康数据上的性能。
2.2 卷积神经网络
CNN 能较好地提取输入数据的空间相关性特征,在电力负荷预测、电力设备的故障诊断等领域有所应用[23]。CNN 的典型结构如附录C 图C1 所示,其中包括卷积层、池化层和全连接层[24]。由于输入特征为1 维向量,因此采用1 维CNN 建立基本模型。1 维CNN 的卷积核在一个方向上扫描,进行互相关运算。随着电池性能的下降,固定电压间隔下的放电容量发生变化,CNN 可以识别Q(V)的演化规律,即不同的Q(V)对应不同的劣化程度,CNN 可以将从Q(V)中提取的特征直接映射到电池的关键状态。
用于建立自动编码器模型的基本CNN 结构由卷积层和池化层组成。卷积层的激活函数为线性整流函数(ReLU)。池化层用于降低卷积层输出的维数。为了降低过拟合,采用10%的dropout 率。
2.3 自动编码器
自动编码器是一种编码器-解码器架构的神经网络,自动编码器的结构如附录C 图C2 所示,其中编码器网络可以将输入特征映射到低维空间,解码器网络可以重构低维数据,使得输出尽可能等于输入。
使用电池的健康数据训练自动编码器模型,训练数据记作x=[x1,x2,…,xm],其中m为特征向量的长度,编码过程如式(4)所示。
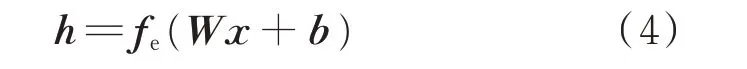
解码过程如式(5)所示。
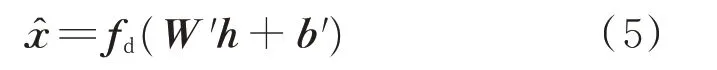
式中:fe(·) 为编码函数;fd(·) 为解码函数;W、b和W′、b′分别为编码层和解码层的函数权重和偏置。网络的训练使得输出数据x^ 和x尽可能相等,即在训练过程中将电池的健康状态的特征编码为网络的权重。
本文中编码器和解码器的基本模块由CNN 组成。附录C 图C3 显示了模型的网络超参数,自动编码器中编码和解码模块的基本结构由经验模型决定[25],模块的具体参数如卷积核的数量、大小等由训练集和验证集的数据进行多次实验优化。
2.4 基于重构误差的状态评估
当自动编码器模型训练完成后,可以学习Q(V)曲线的高级特征。由于该模型在训练过程中没有看过异常数据,而异常数据与健康数据的分布存在差异,因此无法很好地重建异常数据的输入特征。给定输入向量[,,…,],模型输出为[,,…,], 对 应 重 构 误 差 为[e1,e2,…,ei,…,em],i= 1,2,…,m,其中ei=|-|表示特征向量的输入和输出第k位的绝对误差。随着电池的老化,电池的状态偏离训练数据的状态,误差向量[e1,e2,…,em]也相应发生变化,因此将误差向量作为评估电池状态的指标。
2.5 逻辑回归
逻辑回归根据误差向量[e1,e2,…,em]将电池分类为健康或是异常状态。逻辑回归计算输入的线性和并通过sigmoid 函数将其映射为0 到1 之间的实数,如式(6)所示。输出值为描述电池是否异常的概率。

式中:w为模型的权重矩阵。
2.6 评估指标
为了比较电池容量和重构误差作为状态评估指标的相似度,计算两者的皮尔逊相关系数ρX,Y。
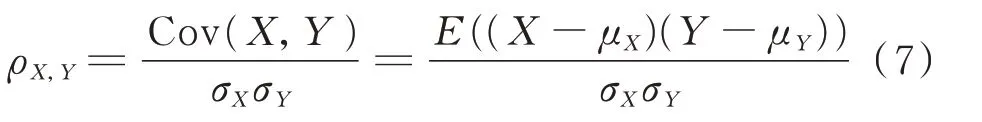
式中:X为随机变量;Y为重构误差;Cov(X,Y)为容量和重构误差的协方差;σX、σY和μX、μY分别为X、Y的方差和均值;E(·)为协方差Cov(X,Y)的具体计算公式。皮尔逊相关系数是衡量向量相似度的一种方法,其绝对值|ρX,Y|为0 至1 的实数,值越接近1 说明向量越相似。
选择混淆矩阵、受试者工作特性(ROC)曲线[26]等指标评估基于重构误差的分类器的分类性能。
自动编码器模型初始学习率设置为0.001,采用Adam 优化算法更新网络参数,训练迭代次数为20。用于优化的损失函数为均方误差(mean squared error,MSE),其计算公式如下。

式中:qi为实际容量值,通过实验获得;为模型的输出值。
采用平均百分误差(mean absolute percentage error,MAPE)评估模型的性能,其计算公式如式(9)所示。
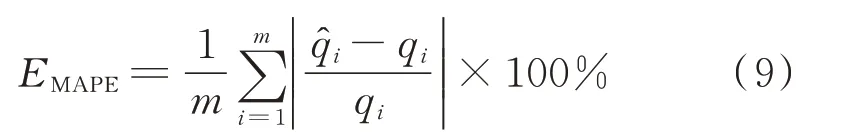
模型的实现基于Tensorflow2.0 中的高级深度学习框架Keras。
3 实验结果与分析
3.1 基于CNN 的电池容量估计模型
为了验证CNN 提取电池Q(V)特征的性能,搭建了CNN 模型用于电池的容量估计。CNN 模型包括3 个卷积层和1 个全连接层。卷积层用于提取Q(V)的深层次特征,全连接层合并卷积层提取的深层次特征信息并输出对应的电池容量。80%的数据用于训练CNN 模型,剩下的20% 用于测试CNN 模型的性能。
为了研究CNN 模型对输入的鲁棒性,对不同长度的输入向量进行了测试。考虑到电池实际应用中会在某一荷电状态(SOC)区间循环,而不是进行完整的充放电循环,选择原始特征中连续的长度为300、500 和700 的向量进行测试。图2 显示了输入向量长度为300、500、700 时的容量估计结果,模型的MAPE 分别为0.57%、0.28%、0.43%。结果表明,这3 种输入都能获得满意的容量估计结果。长度为300 的特征向量对应的电压范围为2.75~3.20 V,长度为500 的特征向量对应的电压范围为2.375~3.125 V,长度为700 的特征向量对应的电压范围为2.075~3.125 V。输入长度为300 的模型性能略差,这可能是因为输入较短的片段数据难以充分表征电池的老化状态信息,并且不同循环在该电压区间的Q(V)曲线比较接近,这给CNN 识别电池的老化状态造成了困难。从附录A 图A2 可以看出,随着电池性能的下降,Q(V)曲线的变化主要发生在2.0~3.0 V 的电压区间。这表明CNN 模型可以捕获到Q(V)从2.0~3.0 V 的不同循环的演变模式。

图2 容量估计结果Fig.2 Capacity estimation results
3.2 基于自动编码器的电池状态评估模型
本文采用基于CNN 的自动编码器对输入特征进行重构,将重构误差输入到逻辑回归分类器中以判断电池是否正常。为了模拟实际的工况,选择长度为500 的向量[Q250,Q251,…,Q749]作为输入特征,图3 显示了在健康的训练和测试数据上模型的输入和输出,真实值为输入,预测值为输出。训练数据的MSE 为1.54×10-4,测试数据的MSE 为7.11×10-5。可见,健康的数据模型能较好地重建其输入。
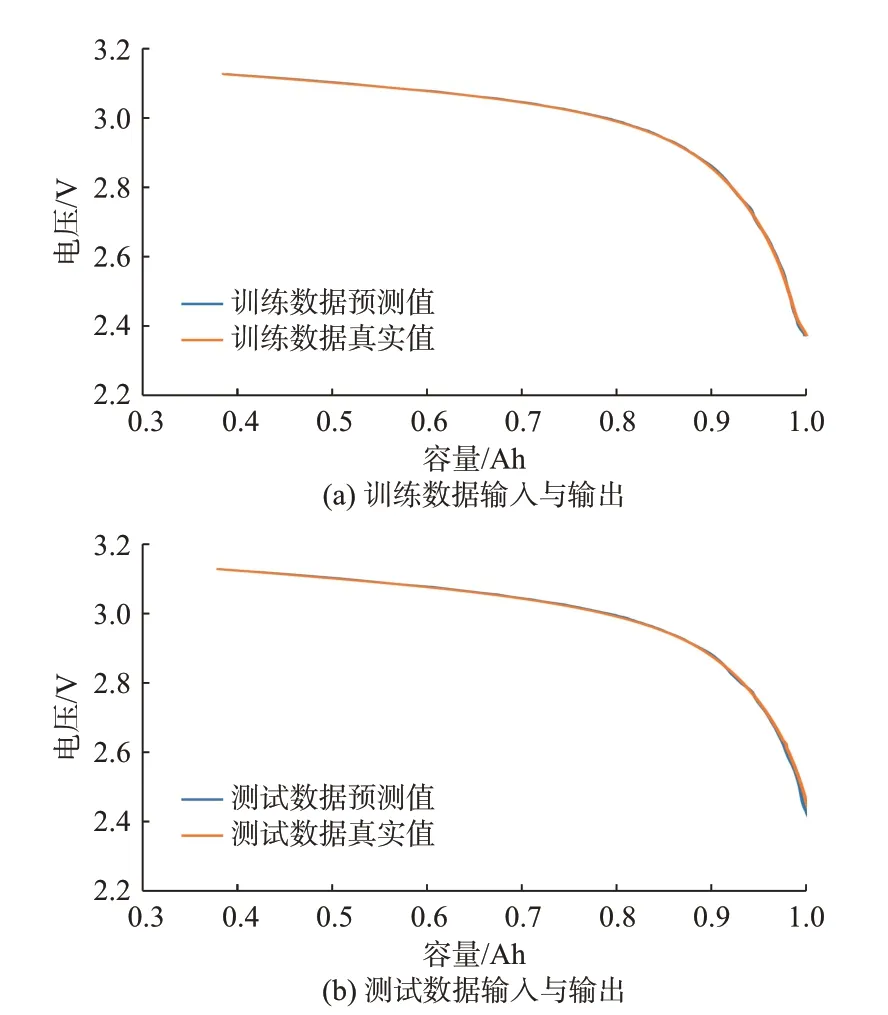
图3 自动编码器在健康数据下的输入和输出Fig.3 Input and output of autoencoder with healthy data
当异常数据输入模型中时,相应的输出如图4所示。当电池老化时,Q(V)曲线逐渐变化,由于自动编码器模型在训练过程中没有学习过异常数据的Q(V)演变模式,因此无法很好地重建输入数据。

图4 自动编码器在异常数据下的输入和输出Fig.4 Input and output of autoencoder with abnormal data
为了分析误差分布,平均绝对误差的对数直方图如图5 所示。MAE 的对数表示如式(10)所示。

为了将健康数据和异常数据之间的误差显著区分,MAE 的对数累计计算5 个循环的数据,即使用当前循环的最近5 次循环数据进行评估。由图5 可知,健康数据误差近似服从正态分布,如图中蓝色曲线所示,而异常数据的误差分布不同于健康数据,如图中红色曲线所示。结果表明基于CNN 的自动编码器模型能通过计算重构误差对电池的状态进行判定。
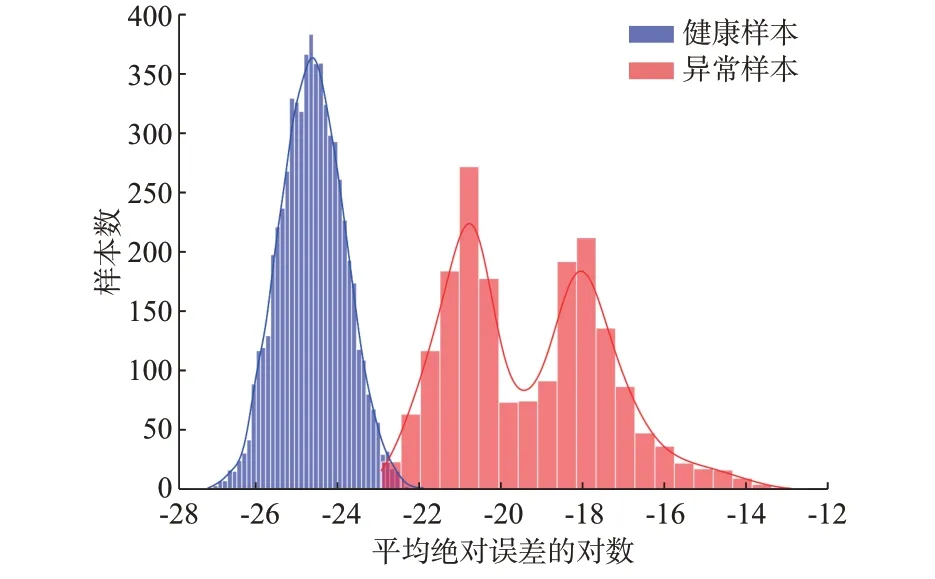
图5 健康和异常数据的误差分布Fig.5 Error distribution of healthy and abnormal data
附录D 图D1 和图D2 显示了当输入长度为1 000 的原始特征时的模型输入与输出。虽然实际在线应用难以获得100%放电深度的数据,但图D1和图D2 表明重构误差较大的区域集中在2.0~3.0 V 的区间,这与附录A 图A2 中Q(V)曲线的演变规律是一致的。
附录D 图D3 显示了一个电池样本的重构误差随着循环的变化。在健康状态数据中,电池的容量衰减主要是由于SEI 层的增长,重构误差有轻微的增长。在特定的时间点后,由于其他机械性能的退化,电池的容量急剧下降,重构误差迅速增大。为了与容量数据对比,附录D 图D4 显示了该电池的循环放电容量,可见重构误差与容量具有相似的变化趋势。多个电池样本的容量和重构误差的皮尔逊相关系数分别为-0.78、-0.91、-0.86,平均值为-0.85。重构误差与电池的容量具有较强的相关性,能一定程度地反映电池的老化状态。
在计算出重构误差后,将其作为逻辑回归的输入,得到电池是否异常的概率。采用分层抽样获得逻辑回归模型的训练数据和测试数据。训练数据占80%,测试数据占20%,其中训练和测试数据中健康与异常样本的比例相同。采用L1 和L2 正则化抑制模型过拟合。附录D 图D5 显示了不同正则化程度的精度性能,准确度表示正确预测的样本占总预测样本的比例。由图D5 可以发现,L1 正则化的性能略好于L2 正则化。由于L1 正则化倾向于将权重矩阵w稀疏化,表明误差向量[e1,e2,…,em]中的分量对于判别电池的状态可能不是同等重要的。在误差向量为500 维时采用L1 正则化的权重矩阵中非零项只有52 个。从附录D 图D2 也可以发现误差集中在2.0~3.0 V,说明Q(V)曲线的特定区间对于电池的状态评估是比较关键的。
附录D 图D6 为用于状态评估的逻辑回归模型的ROC 曲线。假阳率(false positive rate)是指健康样本中预测为异常样本的数量与实际健康样本数的比值。真阳率(true positive rate)表示异常样本中预测为异常的样本数与实际异常样本数之比。ROC曲线下面积(AUC)为0.988 4。对于分类问题,AUC 越接近1 说明分类器的性能越好[26]。这一结果说明基于自动编码器重构误差的逻辑回归模型在电池的状态评估上具有较好的分类性能。
由于将异常状态判定为健康相较将健康状态判定为异常的危害性更大,即该分类是代价敏感的。因此为了尽可能多地检测出异常状态的电池,对逻辑回归的损失函数进行修改,原损失函数为:
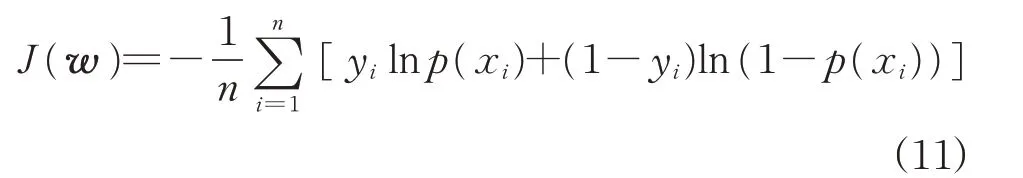
式中:n为样本数;yi为样本的分类标签,取值为1 表示异常,为0 表示健康;p(xi)表示分类为异常的概率。
由于2 种误分类的代价不同,对2 种情况设置不同的权重系数,修改后的损失函数如式(12)所示。

式中:w0和w1为权重系数,通过网格搜索进行优化。
优化后模型的混淆矩阵如表1 所示,其中检测出的异常样本占总异常样本的98.73%,正确分类的样本占所有样本的92.95%。

表1 混淆矩阵Table 1 Confusion matrix
综上所述,本章首先建立CNN 模型估计电池的容量,验证了CNN 具备从电池的Q(V)曲线中提取深层特征的能力。接着,建立基于CNN 的自动编码器模型,使用健康数据训练自动编码器,计算编码器对不同输入的重构误差,将重构误差作为逻辑回归分类器的输入,对电池的状态进行判定。最后,ROC 曲线、混淆矩阵等性能评估结果证明了本文方法的有效性。
4 结语
本文提出了一种基于CNN 的自动编码器模型用于锂离子电池的状态评估。该工作的主要贡献如下。
1)将电池的Q(V)特征与深度学习模型结合,采用CNN 模型估计电池容量。结果表明电池的Q(V)特征是电池状态预测与预诊断的丰富的数据源。
2)提出一种基于CNN 的自动编码器模型用于判定电池是否异常,在健康数据上进行训练后,自动编码器模型学习了Q(V)的演化模式。利用模型输入、输出的重构误差可以估计电池的状态。误差分布证明自动编码器模型能够近似地区分电池的异常和健康状态。
3)根据重构误差,采用逻辑回归对电池状态进行分类。当采用L1 正则化时获得最好性能,L1 正则化倾向于生成稀疏的权值矩阵,这意味着Q(V)中的电压区间对于电池劣化评估并不同等重要。在退化诊断中某些特定的电压范围更值得引起关注。
这项工作突出了电压-放电容量曲线结合深度学习诊断电池劣化的能力。该方法的缺点是需要在线采集足够的健康数据来训练模型。同时,由于测试数据的限制,没有在实际动态运行工况的电池数据上进行测试。后续的工作将考虑将Q(V)特征与迁移学习相结合,以减少模型在线训练所需的数据量,加快训练过程。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
