基于微服务架构的路径控制和流量切换的软件解决方案
2021-12-29杨帆
杨 帆
(欧特克(中国)软件研发有限公司,上海 200127)
0 引言
随着互联网时代的到来,云计算技术和物联网技术快速发展,互联网应用提供商的硬件资源与软件资源越来越多地以服务的形式提供给用户[1]。2014年学者Martin Fowler正式提出微服务架构的概念[2]:微服务架构以一套微小的服务的方式来开发和部署一个单独的应用,这些微小的服务根据业务功能来划分,通过自动化部署机制独立部署运行在自己的进程中,微服务之间使用轻量级通信机制来进行通信。一个典型的微服务架构应该包括客户端、微服务网关、服务发现、微服务原子层、数据库、部署平台等模块,根据不同应用类型及服务规模,可以增加负载均衡 、权限认证、服务熔断、日志监控等模块,来满足服务的非功能性需求。企业纷纷迈向微服务架构的典型原因是业务的复杂性、可扩展性[3]。而 Spring Cloud是目前微服务架构领域的翘楚,也是一个全家桶式的技术栈,包含了很多组件,例如Eureka、Ribbon、Feign、Hystrix、Zuul这几个组件。首先Spring Cloud是基于Spring Boot实现的云应用开发工具,它为基于JVM的云应用开发中涉及的配置管理、服务发现、断路器、智能路由、微代理、控制总线、全局锁、决策竞选、分布式会话和集群状态管理等操作提供了一种简单的开发框架。
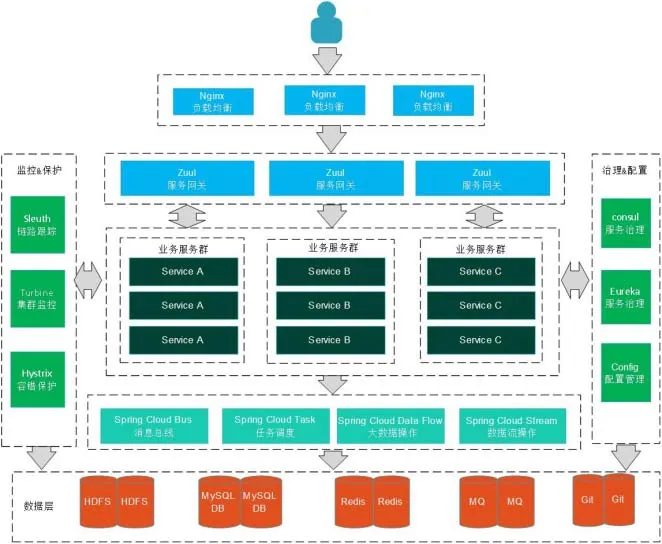
图1 微服务系统架构Fig.1 micr oservices system architecture
而在互联网企业快速迭代的开放和发布活动中伴随业务的增加,微服务的子系统会变得越来越多,并伴随着子系统间的业务调用路径也会越来越复杂。随之而来我们面临着多版本子系统的访问路径控制、黑白名单和流量切换,微服务本身的多系统间的全路径检测、问题定位和 log收集,以及各个子系统的平滑的上下线发布和切换等问题。而我们通过开发出泳道系统来进行各系统间实时流量控制、多版本访问路径选择等来解决各微服务间的问题。
1 微服务架构所面临的问题
微服务系统中每个服务代表着一个小的业务能力[4],而每个服务之间通过 API调用[5]。所以由于本身就存在多服务互相调用的特性,这就使得它存在着跨进程之间的事务、大量的异步处理、多个微服务之间相互发现选择以及网络延迟、容错、消息序列化等问题。而随着公司的成长和业务的拓展,各个系统会进行快速的多次迭代。这就会造成子系统的增加以及子系统的多版本共存等问题的出现。
而通过构建Spring Cloud系统构架,通过对Eureka、Ribbon、Feign、Hystrix、Zuul这几个系统和组件的使用,可以解决一些如子系统发现[6],各子系统间访问路由、负载等问题。但是这些还远远不够,还面临着如下问题的挑战:
(1)对多版本的子系统支持
(2)多版本的访问路径控制
(3)多版本的黑白名单和流量切换
(4)多系统间的全路径检测,问题定位和log收集各个子系统的平滑的上下线发布和切换。
2 解决方案和具体要求
为了解决微服务系统中的多版本子系统一系列问题,目前有两种可行的解决方案:
(1)物理隔绝独立部署。就是根据需要的支持的各个版本子系统独立部署一整套微服务系统,但是可以根据并发量减少部署的子系统个数。在最外层网关根据需求发出的版本号选择对应的独立系统[7]。
优点:不会对系统的开发有任何影响,系统独立流量切换和控制也相对容易,系统的集成测试相对友好,也便于开发人员发现问题,修改错误,对访问控制也相对容易。
缺点:实施成本高昂,如果根据一个子系统版本一套独立部署,需要把所有的其他子系统全部单独部署一遍,会把一些访问量较少的服务也单独再部署一个,而且如某些版本本身访问数量较少也需要一整套系统的支持,这就造成资源浪费和分配不均,会挤占高访问率版本系统的所占资源。
(2)通过软件自动选择可以访问的子系统。所有的子系统都配置自身的版本信息并且能够自己识别和选择需要访问的下一个系统的版本[8]。
优点:系统上下线灵活,不会挤占高访问率版本系统的所占资源。实施成本相对较低,对运维占用也相对较少。
缺点:可能会对开发和测试产生较大的影响,可能会对已有系统造成代码侵入问题,对于系统查错提告了难度。
对大多数处于创业期的互联网企业来说系统资源都是有限的,如何提升系统资源的最大利用率都是核心的问题。所以选择第二种方案是大多数创业期的互联网企业最佳选择。而如何规避第二种方案所带来的缺点则是对系统架构师的考验了。
为了对于已有系统的影响最小化也列出了如下的要求:
(1)能够对全路径进行追踪
(2)对已有系统的各个子系统没有硬性的代码侵入
(3)可以自由发布
(4)方便收集所有子系统的log记录
(5)不需要对已有系统进行重构和改造
3 泳道架构的设计和实施细节
为了应对以上问题,我们主要通过开发泳道架构系统来解决。而泳道架构系统的设计思路是通过软件让各个子系统能够自己选择可以访问的其他子系统。而在这当中需要对各个子系统最小化的代码侵入,对全链路能够有效的进行跟踪和查找。而且能够适用于消息队列(MQ)和job调用甚至数据库的存储。为了满足以上要求,泳道架构系统通过为了让各个子系统引入 jar包来让各个子系统能根据版本信息和设置的阈值自动选择它可以访问的其他子系统,并能够在所有的访问请求中带上唯一的trace Id,而且让这个Id一直保存在所有的需要调用的子系统中。并且泳道架构系统还通过新开发的新服务来为所有子系统配置版本信息,控制各个子系统流量,设置用户访问控制名单和系统访问控制名单。
实现细节:
首先Spring Cloud的Eureka已经提供了微服务的注册和发现服务,可以通过对子系统的配置修改将各个子系统版本信息通过注册服务发送给Eureka,而其他子系统则可以通过Eureka来获得需要访问的子系统的版本信息[9-10]。
统计得2001—2016年春季暴雨雨日共11 d,通过影响系统的分析发现(表1),在11次过程中,有8次暴雨都伴随有低空切变和地面倒槽的存在;高空槽,低空急流,地面冷空气也是重要的影响系统;春季是冷空气较为活跃的季节,有4次过程是高空有槽东移或急流存在,中层配合切变或低空急流,而地面先为倒槽控制,之后冷空气南下影响,冷暖空气交汇导致暴雨的发生。另外东北冷涡也是非常重要的影响系统,有4次暴雨与之有关。
其次在类似Spring Boot风格的基于简易配置的微服务[9]中开发一个被所有子系统引用的jar包来完成trace Id的访问透传,和从Eureka获取所有子系统的版本配置信息从而来进行访问路径选择和计算。
持续改进方案
泳道系统第一版:
所有版本信息通过Eureka来进行存储,而版本信息都是各个子系统存储于自己的配置文件内。这样可以对访问进行版本访问选择控制,但是也无法进行主动的流量控制。

图2 基于API的微服务调用Fig.2 API-Based microservices calling process
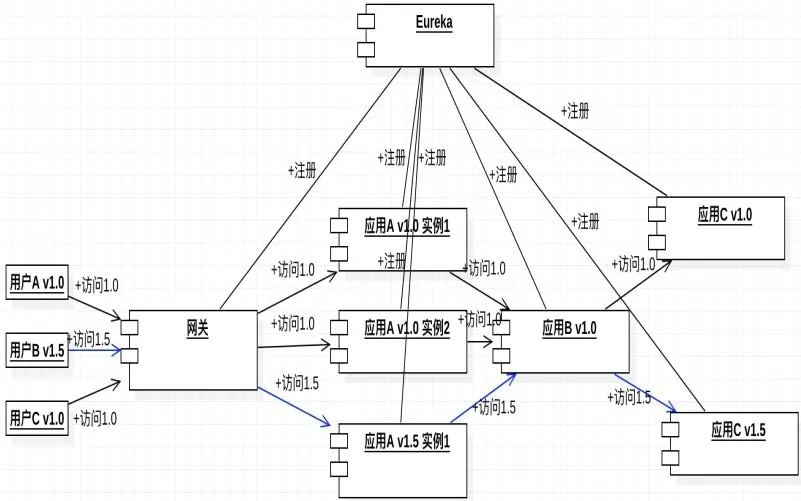
图3 利用Erueka的微服务的注册和访问实现的1.0的服务调用Fig.3 version 1.0 microservices calling process base on Erueka’s registration and access
用户的访问进入网关并带有用户的信息如用户APP的版本信息和用户ID等。网关根据此用户的信息生成该用户此次访问的Trace Id,并从注册的Eureka获取可以访问的应用A的所有实例信息。再根据访问的要求去选择相对应的应用A的具体实例。例如:用户A是要访问1.0版本的应用,网关从Eureka处获取到3个可以访问的应用A实例,然后根据1.0的版本号选出其中2个可以使用的具体实例,最后选择其中一个发出访问并带上生成的此次的Trace Id。应用A v1.0的其中一个实例收到这个访问发现它需要调用应用B。应用A从Eureka处获取到应用B没有版本的具体要求,所以不需选择就可以发生请求给应用B,但是该请求还是会带上网关生成的Trace Id和应用的版本需求。而在应用B收到访问请求在发现需要调用应用C时,它也会从Eureka处请求应用C的具体信息,然后根据访问所需求的版本要求选择应用C支持v1.0的具体实例,返送访问请求。
泳道系统第二版:
引入 Zookeeper服务把各个子系统版本配置信息在上线时同步注册到 Zookeeper上,再开发一个独立系统对Zookeeper信息进行管理。
由于添加了两个新的服务 Zookeeper和泳道控制应用,所以所有的服务在Eureka注册时同时会把自己的版本信息也注册到 Zookeeper上。而泳道控制应用就能实时观察和控制其中每一个应用实例的访问。其中的访问流程跟第一版大体一致,但是在选择该服务可以访问的下一个服务的实例时,则不是光通过Eureka来获取全部信息。而是先通过Eureka拿到全部可以访问的下一个应用实例,然后再从 Zookeeper上去获取具体的访问规则,如可以访问的版本信息,访问的黑白名单,然后过滤从Eureka获取的应用实例,选取符合以上规则的具体几个实例,最后还能再根据实例的流量访问规则来选取其中一个实例来访问。例如还是用户A发出的访问v1.0的请求,再网关处跟上一版一样生产对应的 Trace Id,从 Eureka获取应用A的v1.0和v1.5的全部3个实例,然后再读取 Zookeeper上的访问版本规则和黑白名单,筛选出应用A的v1.0的2个实例,然后再根据2个实例的流量控制的百分比选出最后访问的那一个实例。
计算流量的方式如下:
应用A的v1.0实例1的流量为40%,
应用A的v1.0实例2的流量为60%。
获取一个100以内的随机数,如果随机数小于等于40,选择应用A的v1.0实例1,反之则选择应用A的v1.0实例2.
泳道系统第三版:
去掉Zookeeper,把版本控制信息和流量调节信息控制系统前移。把信息存储于进入网关,根据访问控制把需要的子系统的访问版本控制信息跟 trace Id一起封装于访问信息内来进行全系统透传。

图5 以网关注入信息3.0的服务调用Fig.5 version 3.0 microservices calling process of gateway information injection
第三个版本跟第一版很像,只是在网关上添加了一个泳道控制应用。它的所有功能跟第二版比一点也没有减少,只是减少了系统的复杂度,去掉了Zookeeper,避免了可能会由于Zookeeper产生的问题(如非必要勿增实体)。全部的访问规则跟第二版基本一致,但是不再从 Zookeeper获取访问规则,黑白名单和流量控制信息了。而是这些信息直接存储在网关上,而网关则是把所有这些信息和Trace Id一样存储在每个分发出去的访问需求上,而具体的应用实例在做访问选择时,不再从别的服务上获取访问信息和规则,直接从访问信息中获取,这样减少了网路负担和服务直接的访问频次。
4 结论
通过泳道架构系统我们不需要对所有子系统进行代码侵入的情况下,只通过引入jar就能实现子系统间的访问选择,黑白名单控制和访问流量调节。以此为基础可以实现A/B测试和蓝绿部署、金丝雀发布,以及灰度发布、流量切分。
