采用改进CNN对生猪异常状态声音识别
2021-12-29耿艳利宋朋首林彦伯季燕凯杨淑才
耿艳利,宋朋首,林彦伯,季燕凯,杨淑才
采用改进CNN对生猪异常状态声音识别
耿艳利1,2,宋朋首1,林彦伯1,季燕凯1,杨淑才3
(1. 河北工业大学人工智能与数据科学学院,天津 300130;2. 智能康复装置与检测技术教育部工程研究中心,天津 300130;3. 天津魔界客智能科技有限公司,天津 300130)
猪只声音能够体现出其生长状态,该研究针对人工监测猪只声音造成的猪只疾病误判以及耗时耗力等问题,研究基于卷积神经网络CNN(Convolutional Neural Network)的生猪异常状态声音识别方法。该研究首先设计猪只声音实时采集系统,并利用4G通讯技术将声音信息上传至云服务器,基于专业人员指导制作猪只异常声音(生病、打架、饥饿等)数据集,提取猪只异常声音的梅尔谱图特征信息;其次引入多种注意力机制对CNN进行改进,并对CBAM(Convolutional Block Attention Module)注意力机制进行优化,提出_CBAM-CNN网络模型;最后将_CBAM-CNN网络模型分别与引入SE_NET(Squeeze and Excitation Network)、ECA_NET(Efficient Channel Attention Networks)和CBAM注意力机制的CNN神经网络进行对比,试验结果表明该文提出的_CBAM-CNN网络模型在最优参数为128维梅尔频率、2 048点FFT(Fast Fourier Transform)点数、512点窗移下的梅尔谱图特征下相较于其他模型对猪只异常声音识别效果最佳,识别率达到94.46%,验证了算法的有效性。该研究有助于生猪养殖过程中对猪只异常行为的监测,并对智能化、现代化猪场的建设具有重要意义。
声音信号处理;动物;异常声音;卷积神经网络;SE_NET;CBAM;ECA_NET
0 引 言
传统的生猪养殖对猪只的健康状态和异常状态判断通常需要人为蹲点监测、近距离观察[1-2],容易造成猪只的应激反应和疾病的扩散[3-5]。随着科学技术的发展,养猪技术越来越趋于智能化。
国外将声音识别技术应用于生猪养殖业早于国内。2007年,意大利学者Guarino等[6]以猪咳嗽声的梅尔频率倒谱系数为特征,利用动态时间规整算法实现了猪咳嗽声的识别,咳嗽声识别准确率为85.5%。Exadaktylos等[7]基于声音信号的频域特征对化学诱导的猪咳嗽声、病猪咳嗽声、其他环境音进行分析与分类,整体识别准确率达到85%,病猪咳嗽声识别准确率达到82%。Chung等[8]以患病猪咳嗽声和其他声(不患病猪咳嗽声、猪尖叫声、猪呼噜声)的梅尔频率倒谱系数为特征,利用支持向量数据描述算法和稀疏表示分类法组成两级分类器对其进行识别,数据集包括300个患病猪只的咳嗽声和200个其他声音,所提模型平均识别准确率达到91.0%。Hong等[9]使用NVIDIA TX-2嵌入式设备采集猪只声音,搭建MnasNet网络并实现猪只异常声音的实时识别,消除噪声对识别准确率的影响。Cordeiro等[10]通过决策树对猪只声音进行识别,证明猪只声音可以反应猪只的年龄、性别和患病情况。
国内在此方面研究尚处于起步阶段。南京农业大学团队[11-12]对母猪是否患有呼吸道疾病判断容易出现偏差等问题,提出一种基于改进模糊均值的咳嗽声识别算法,有效帮助饲养员判断猪是否有呼吸道疾病。华中农业大学团队[13-14]将猪只咳嗽声的梅尔频率倒谱系数及其一阶、二阶差分系数组合为复合特征,使用深度信念网络等方法对猪咳嗽声进行识别,猪咳嗽声识别准确率达到94.29%。涂鼎[15]以猪咳嗽声的语谱图为特征,使用微调的AlexNet模型实现了猪咳嗽声的识别,模型识别准确率达到94.76%。苍岩等[16]同样以猪只声音的语谱图为特征,利用MobileNetV2模型对猪的哼叫、惊吓、喂食等声音进行识别,模型识别准确率达到97.3%。
综上所述,国内外学者分别从猪只声音采集设备、去噪与模式分类方面进行大量研究,其中如何对猪只异常声音进行实时采集并准确识别是目前研究的重点。因此本研究搭建了基于4G通讯技术的猪只声音远程实时采集平台,实现猪只声音信息的远程实时采集;选取猪只异常声音的梅尔谱图为特征参数,研究基于CNN的猪只异常声音识别方法。
1 猪只声音信息采集
1.1 猪只声音信息采集平台
猪只声音信息采集设备由单片机、数据采集模块、4 G通讯模块和电源管理模块组成。其中单片机采用STM32F103RCT6芯片;数据采集模块由1个麦克风咪头和音频放大电路组成;4G通讯模块采用的是ME909s-821 LTE Mini PCIe 模块。猪只声音信息采集设备硬件连接和实物如图1所示。
1.2 试验数据采集
本研究试验数据采集于河北省沧州市某猪场,猪场养殖的猪品种为长白猪,采集时间为2020年11月份,将采集设备置于料槽上方,整个采集过程持续7d。猪只声音信息采集现场如图2所示。
图2中圆圈处为猪只声音采集设备放置地点,其中采样率设置为32 kHz,采样位数为16 bit,通道数为单通道。编码之后的数据通过2个直接存储器访问控制器将数据实时传输给4 G通讯模块。
1.3 试验数据传输与存储
本研究通过4G通讯模块把采集到的声音数据传输到云服务器上。通讯协议采用TCP/IP协议,采集端当做TCP的客户端,进行不间断的向服务端发送数据。云服务器作为TCP的服务端,对指定端口进行阻塞式监听,客户端连接成功后开始传输数据,服务端先向客户端发送重启命令保证传输的数据对齐。经过专业人员指导,最终筛选得到猪咳嗽声样本700个,猪尖叫声样本1 146个,猪哼哼声样本1 040个。
2 声音信号预处理及特征提取
2.1 预处理
声音信号是非平稳信号且信号低频段能量大,高频段能量小,所以需要对声音信号进行预处理,预处理过程包括:预加重、分帧、加窗。其中预加重的作用是对声音的高频部分进行加重,去除口唇辐射的影响,增加猪只声音的高频分辨率;声音信号是非平稳的信号,但一般认为在短时间(30~50 ms)内,声音信号是平稳的,即声音信号具有短时平稳性,所以利用分帧加窗的方式对声音信号进行分析。本文猪只声音分帧长度为50 ms,帧移为12.5 ms。
2.2 去噪
采集的原始数据中猪只声音和环境噪声相互叠加,环境噪声影响模型的识别效果,本文选取去除加性噪声效果较好的谱减去噪法对猪只声音进行去噪。借鉴文献[12]的去噪方法,设第帧纯净声音信号序列为x(),第帧带噪声音信号序列为y(),估计的1帧噪声信号序列为d(),为采样点序号,则谱减公式为

由X()进行逆傅里叶变换可得到第帧纯净声音信号序列x(),将每帧纯净声音信号序列进行重叠相加可得到去噪后的纯净声音信号。对各类声音进行降噪后效果如图3所示,谱减降噪后各类声音均没有失真,且较好地去除了背景噪音。
2.3 端点检测
猪只声音经过去噪后声音信号仍然存在无声段,为了防止无声段对识别效果产生干扰,需要对猪只声音信号进行端点检测,确定猪只有效声音的起点和终点。本文选用基于短时能量的单参数双门限端点检测方法[17]对猪声音进行检测,其中短时能量计算公式为

式中为帧长,声音分帧后每帧的长度,为猪声音的采样点序号,为帧序号。
3类声音经过端点检测后的时域曲线和短时能量曲线如图4所示。
2.4 提取梅尔谱图特征
经过分析,发现猪只各类声音样本都在3 s以内,截取猪只声音长度选择为3 s,保证每段声音都包含其异常声音发音的一个周期,设计梅尔滤波器对经过预处理的猪只声音滤波,最后得到声音信号的梅尔谱图[18-19]。其中128维梅尔频率、2 048点快速傅里叶变换FFT(Fast Fourier Transform)点数、512点窗移下猪只各类异常声音的梅尔谱图如图5所示。
3 分类模型选取与优化
本文以猪只声音信号的梅尔谱图为特征,利用卷积神经网络搭建本文的分类模型。卷积神经网络具有局部连接和权值共享的特点,但是卷积神经网络在获取到梅尔谱图的各个位置的局部信息时,不可避免的会产生各种冗余的信息,而这种冗余的特征对提升模型的性能效果不佳[20-21],因此本文通过引入SE_NET、ECA_NET、CBAM等注意力机制对卷积神经网络进行优化。
3.1 局部特征学习单元
本文基于卷积操作构建局部特征学习块[22]。局部特征学习块由卷积层、批归一化层[23]、指数线性单元激活函数和最大池化层组成,卷积层学习输入梅尔谱图的特征;批归一化层对每批卷积层的输出进行归一化处理,提高深度网络的性能和稳定性;指数线性单元激活函数定义批归一层的输出。指数线性单元具有负值,使激活的平均值更接近于零,因此可以加快网络的收敛速度,从而获得更高的识别精度。指数线性单元激活函数的计算公式为
3.2 SE_NET
SE_NET对CNN在通道方向添加注意力机制,该模型复杂度低,新增参数和计算量小,主要包括“压缩”和“激励”2个关键操作[24]。
“压缩”部分是顺着空间维度对特征图进行“压缩”,将原来特征图维度ÍÍ(、、分别为特征图的高度,宽度和通道数)压缩为1Í1Í,该特征图感受野更广;“激励”部分是在“压缩”的基础上对特征各个通道间相关性进行建模,得到不同通道的重要性大小后在“激励”到原始特征图中对应的通道中。实际使用中“压缩”采用全局平均池化操作,“激励”采用两层全连接层,且为了增强泛化能力,神经元个数按一定的衰减比例减少。
3.3 ECA_NET
ECA_NET是对SE_NET的改进模型,是一种极轻量的通道注意力模块,该模块增加的模型复杂度小,提升效果显著[25]。ECA_NET使用1D卷积代替SE_NET中的全连接层,其中1D卷积涉及到超参,即卷积核尺寸,它代表了局部跨通道交互的覆盖率。的计算公式为
ECA_NET通过式4自适应选择卷积核大小,以确定局部跨信道交互的覆盖率。SE_NET和ECA_NET模块示意图如图6所示。
3.4 CBAM
CBAM结合了通道注意力机制和空间注意力机制[26],将猪只异常声音的梅尔谱图经过卷积层生成特征图,对此特征图依次进行通道注意力加权和空间注意力加权得到最终经注意力加权后的特征图,具体步骤如公式(5)、(6)所示
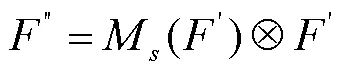


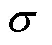
通道注意力部分和SE_NET原理类似。空间注意力部分具体含义为将特征图分别进行平均池化和最大池化操作并将两个结果连接组成ÍÍ2的特征图,通过通道数为1的卷积层学习得到ÍÍ1的特征图,将此特征图通过Sigmoid激活函数得到该特征图各部分的权重,最后将权重特征图与原始特征图相乘得到空间注意力加权的特征图。
CBAM总体结构和各部分示意图如图7所示:
3.5 _CBAM
本文借鉴ECA_NET对SE_NET的改进方式,将CBAM的通道注意力部分使用ECA_NET中提出的权重共享的1D卷积来代替全连接层,同时也引入ECA_NET中提出自适应1D卷积核。改进后通道注意力部分计算公式如下
式中f Ík为卷积核大小为Í的卷积操作,的计算公式如式(4)所示。
改进后通道注意力部分如图8所示:
4 试验结果分析
本试验网络模型结构为4层局部学习单元-注意力层-全连接层,前4层局部特征学习单元卷积核个数分别为64-64-128-128,全连接层神经元个数为3。将数据集以8∶1∶1的比例划分为训练集、验证集、测试集,学习率设置为0.006。因为不同类型的谱图对模型性能有一定影响,因此本文在128维梅尔频率下针对不同FFT(Fast Fourier Transform)点数、不同窗移下的梅尔谱图进行了多次试验,各类模型在不同类型梅尔谱图下的识别效果如表1所示。
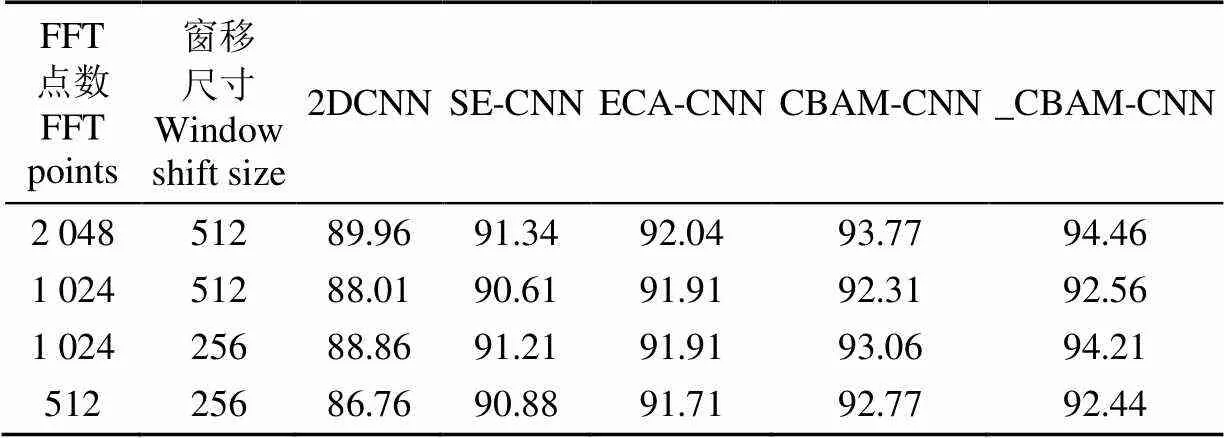
表1 不同FFT点数和窗移下准确率统计
试验结果表明128维梅尔频率、2 048点FFT点数、1/4窗移下的梅尔谱图模型下识别效果最佳。本文基于提升模型识别效果和降低模型复杂度两方面来对注意力机制进行改进,为了对改进效果进行分析,将模型大小和识别效果以表格形式展现。
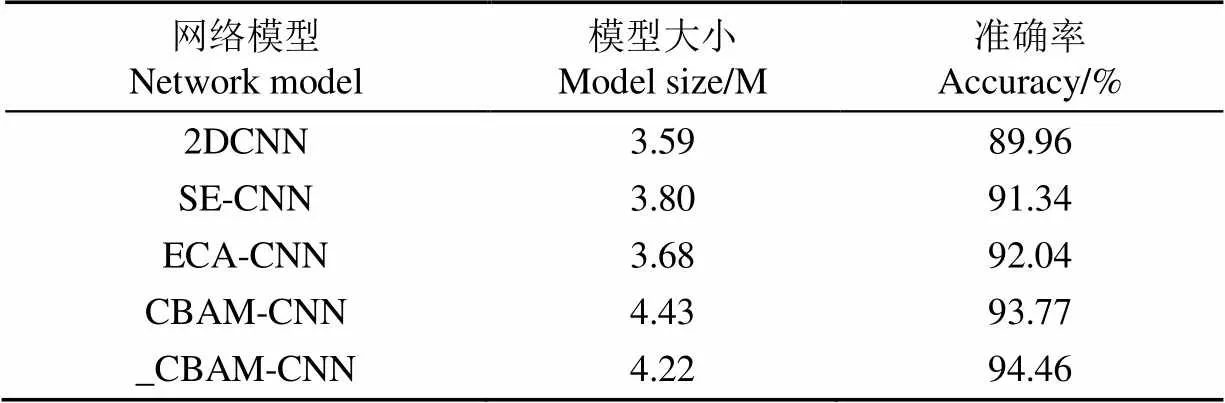
表2 各网络模型大小和识别准确率
通过对表2中模型大小和识别准确率的分析,可以看出,本文改进CNN网络模型_CBAM_CNN在耗费少量的存储空间的同时对模型的识别效果有很大的提升。本文所提出的_CBAM-CNN在模型大小上和识别效果两方面均优于CBAM-CNN,相对于2D-CNN、SE-CNN、ECA-CNN这3种网络模型,_CBAM-CNN虽然牺牲了少量存储空间,但是在模型识别效果上有显著提升,识别准确率达到94.46%。
模型在最佳类型谱图下对各类异常声音具体识别效果以多分类混淆矩阵的形式表示:

表3 不同网络模型下试验结果混淆矩阵统计
由表3可以看出 _CBAM-CNN模型相较与其他模型,对各类异常声音识别最好,其中猪尖叫声识别精确率最高,达到了100%,猪哼叫声和猪咳嗽声识别精确率略低,分别为92.4%和88.6%。相较于前人所做研究,本文对猪尖叫声识别精确率高于其他所有文献,但哼叫声和咳嗽声识别精确率略有不足。
5 结 论
1)搭建了一种基于4G通讯技术的远程无接触式采集猪只声音的设备,利用卷积神经网络对猪只声音进行识别,引入多种注意力机制对CNN进行改进,并对CBAM注意力机制做出优化,提出_CBAM-CNN网络模型。
2)试验证明,猪只声音识别最优参数组合为128维梅尔频率、2 048点FFT、1/4窗移,最优网络模型为_CBAM-CNN,最优识别准确率达到94.46%,其中猪只尖叫声识别精确率达到100%,优于前人所做研究。
3)该研究采用单麦克风采集猪只声音,未对猪舍异常声音的猪只进行定位研究,后续将会引入麦克风阵列并结合视频技术研究猪只养殖过程中异常行为的精准定位和精准行为监测。
[1] Mitchell S, Vasileios E, Sara F, et al. The influence of respiratory disease on the energy envelope dynamics of pig cough sounds[J]. Computers and Electronics in Agriculture, 2009, 69(1): 80-85.
[2] Sara F, Mitchell S, Marcella G, et al. Cough sound analysis to identify respiratory infection in pigs[J]. Computers and Electronics in Agriculture, 2009, 64(2): 318-325.
[3] 王瑞年,张佳,黄守婷. 数字化养猪管理体系建设实践[J]. 今日养猪业,2021(1):9-13.
Wang Ruinian, Zhang Jia, Huang Shouting. Digital pig management system construction practice[J]. Pigs Today, 2021(1): 9-13.
[4] Mucherino A, Papajorghi P, Pardalos P. Data Mining in Agriculture[M]. New York: Springer, 2009.
[5] Moi M, Nääs I A, Caldara F R, et al. Vocalization as a welfare indicative for pigs subjected to stress situations[J]. Arquivo Brasileiro de Medicina Veterinária e Zootecnia, 2015, 67(3): 837-845.
[6] Guarino M, Jans P, Costa A, et al. Field test of algorithm for automatic cough detection in pig houses[J]. Computers and Electronics in Agriculture, 2007, 62(1): 22-28.
[7] Exadaktylos V, Silva M, Aerts J M, et al. Real-time recognition of sick pig cough sounds[J]. Computers and Electronics in Agriculture, 2008, 63(2): 207-214.
[8] Chung Y, Oh S, Lee J, et al. Automatic detection and recognition of pig wasting diseases using sound data in audio surveillance systems[J]. Sensors, 2013, 13(10): 12929-12942.
[9] Hong M, Ahn H, Atif O, et al. Field-applicable pig anomaly detection system using vocalization for embedded board implementations[J]. Applied Sciences, 2020, 10(19): 6991-6991.
[10] Cordeiro A F S, Nääs I A, da Silva Leitão F, et al. Use of vocalisation to identify sex, age, and distress in pig production[J]. Biosystems Engineering, 2018, 173: 57-63.
[11] 徐亚妮,沈明霞,闫丽,等. 待产梅山母猪咳嗽声识别算法的研究[J]. 南京农业大学学报,2016,39(4):681-687.
Xu Yani, Shen Mingxia, Yan Li, et al. Research of predelivery Meishan sow cough recognition algorithm[J]. Journal of Nanjing Agricultural University, 2016, 39(4): 681-687. (in Chinese with English abstract)
[12] 闫丽,沈明霞,刘龙申,等. 基于二次对数能量熵小波包的母猪哺乳声去噪方法研究[J]. 农业机械学报,2015,46(11):330-336.
Yan Li, Shen Mingxia, Liu Longshen, et al. Denoising method of log energy entropy quadratic wavelet packet in sows’lactating vocalization[J]. Transactions of the Chinese Society for Agricultural Machinery, 2015, 46(11): 330-336. (in Chinese with English abstract)
[13] 龚永杰,黎煊,高云,等. 基于矢量量化的猪咳嗽声识别[J]. 华中农业大学学报,2017,36(3),119-124.
Gong Yongjie, Li Xuan, Gao Yun, et al. Recognition of pig cough sound based on vector quantization[J]. Journal of Huazhong Agricultural University, 2017, 36(3): 119-124. (in Chinese with English abstract)
[14] 黎煊,赵建,高云,等. 基于深度信念网络的猪咳嗽声识别[J]. 农业机械学报,2018,49(3):179-186.
Li Xuan, Zhao Jian, Gao Yun, et al. Recognition of pig cough sound based on deep belief nets[J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(3): 179-186. (in Chinese with English abstract)
[15] 涂鼎. 基于音频技术的生猪咳嗽声音识别方法研究[D]. 哈尔滨:东北农业大学,2020. Tu Ding. Research on Pig Cough Sound Recognition Methods Based on Audio Technology[D]. Harbin: Northeast Forestry University, 2020. (in Chinese with English abstract)
[16] 苍岩,罗顺元,乔玉龙. 基于深层神经网络的猪声音分类[J]. 农业工程学报,2020,36(9):195-204.
Cang Yan, Luo Shunyuan, Qiao Yulong. Classification of pig sounds based on deep neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(9): 195-204. (in Chinese with English abstract)
[17] 马辉栋,刘振宇. 语音端点检测算法在猪咳嗽检测中的应用研究[J]. 山西农业大学学报:自然科学版,2016,36(6):445-449.
Ma Huidong, Liu Zhenyu. Application of end point detection in pig cough signal detection[J]. Journal of Shanxi Agricultural University: Nature Science Edition, 2016, 36(6): 445-449. (in Chinese with English abstract)
[18] 李志忠,腾光辉. 基于改进 MFCC 的家禽发声特征提取方法[J]. 农业工程学报,2008,24(11):202-205.
Li Zhizhong, Teng Guanghui. Feature extraction for poultry vocalization recognition based on improved MFCC[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2008, 24(11): 202-205. (in Chinese with English abstract)
[19] Chia A O, Hariharan M, Yaacob S, et al. Classification of speech dysfluencies with MFCC and LPCC features[J]. Expert Systems with Applications, 2012, 39(2): 2157-2165.
[20] He K, Zhang X, Ren S, et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification[C]//IEEE International Conference on Computer Vision. IEEE Computer Society, 2015: 1026-1034.
[21] Jia Y, Shelhamer E, Donahue J, et al. Caffe: Convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM international conference on Multimedia. 2014: 675-678.
[22] Zhao J F, Xia M, Chen L J. Speech emotion recognition using deep 1D & 2D CNN LSTM networks[J]. Biomed Signal Process Control. 2019, 47: 312-323.
[23] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//International Conference on Machine Learning, 2015: 448-456.
[24] Hu J, Shen L, Albanie S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2020, 42: 2011-2023.
[25] Wang Q L, Wu B G, Zhu P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020: 11531-11539.
[26] Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3-19.
Voice recognition of abnormal state of pigs based on improved CNN
Geng Yanli1,2, Song Pengshou1, Lin Yanbo1, Ji Yankai1, Yang Shucai3
(1.,,300130,; 2.,,300130,; 3..,.,300130,)
Sound has been widely used to monitor the health and body conditions of pigs. But the manual monitoring cannot meet the high demand in modern agriculture at present, including zoonotic diseases, misjudgments of pig diseases, and time- and labor-consuming. In this study, a real-time collection module of pig sound was designed to rapidly recognize the abnormal state using an improved convolutional neural network (CNN). A 4G communication was used to upload the collected pig sound into the cloud server. A TCP/IP communication protocol was also selected, where the acquisition end was set as a TCP client and the uninterrupted data to the server. Specifically, the TCP cloud server was utilized to block the specified port, and then start the transfer data after the client was connected successfully. The server also sent a restart command to the client, to ensure data alignment. The sound acquisition was realized via a single channel, where the sampling frequency was 32 kHz, while the quantization digit was 16 bits. Correspondingly, the raw data of various abnormal sounds of pigs (sickness, fighting, and Hunger) were collected, according to the experts of pig breeding. Some operations were used to preprocess the data, including framing, windowing, de-nosing, and endpoint detection. As such, a voice data set of abnormal status was built. Subsequently, the Mel spectrogram of various sounds was extracted under the parameters of 128-dimensional mel frequency, 2048 points of Fast Fourier Transform (FFT) points, and 512 points of window shift. A classification model of the signal acquisition was then constructed using the feature of Mel spectrogram for pig sound signals. Therefore, a local feature learning unit was designed using an improved CNN, indicating fewer weights and lower network complexity than fully connected networks. Four layers of local feature units were constructed, where the number of convolution kernels in each layer was 64-64-128-128. Nevertheless, the local location and various redundant information were inevitably generated, when CNN had acquired each image. Three types of attention mechanisms were used to improve CNN, including Squeeze and Excitation Network (SE_NET), Efficient Channel Attention Networks, (ECA_NET), and Convolutional Block Attention Module (CBAM). A fully connected network with three neurons and an activation function of Softmax was also used to recognize abnormal sounds of pigs. The CBAM was then optimized to propose the CBAM-CNN using the ECA_NET improved SE_NET. The experimental results show that the optimal combination of parameters in pig voice recognition was 128 dimensional Mel frequency, 2048 point FFT, 1/4 window shift, and the optimal network model was _CBAM-CNN. The optimal recognition accuracy reached 94.46%, and the accuracy of pig squeal recognition reached 100%, better than before. The attention mechanism was also improved the model recognition, while reducing model complexity. A better recognition was achieved using the smaller size of _CBAM-CNN model, compared with CBAM-CNN. The accuracy of _CBAM-CNN model was 94.46% for the sound recognition of abnormal pigs. This finding can provide the accurate monitoring of abnormal behaviors of pigs in the process of breeding, thereby constructing intelligent and modern pig farms.
acoustic signal processing; animals; abnormal noise; convolutional neural network; SE_NET; CBAM; ECA_NET
耿艳利,宋朋首,林彦伯,等. 采用改进CNN对生猪异常状态声音识别[J]. 农业工程学报,2021,37(20):187-193.doi:10.11975/j.issn.1002-6819.2021.20.021 http://www.tcsae.org
Geng Yanli, Song Pengshou, Lin Yanbo, et al. Voice recognition of abnormal state of pigs based on improved CNN[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(20): 187-193. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2021.20.021 http://www.tcsae.org
2021-07-20
2021-08-31
河北省重点研发计划项目(19226613d)
耿艳利,博士,副教授,研究方向为智能畜牧。Email:gengyl@hebut.edu.cn
10.11975/j.issn.1002-6819.2021.20.021
TP391.4
A
1002-6819(2021)-20-0187-07
