基于多粒度语义分析的二进制漏洞搜索方法*
2021-12-23马慧芳闫彩瑞
刘 豪,马慧芳,龚 楠,闫彩瑞
(西北师范大学计算机科学与工程学院,甘肃 兰州 730070)
1 引言
软件开发项目组通常进行代码复用以提高生产力和效率,目前最常用的方式是直接复制开源代码以及引用第三方代码库。然而,在此过程中如果监管不善,就可能会导致没有经过补丁修正的漏洞程序传播至不同软件程序,进而传播至不同操作系统乃至平台架构;其次,不同编译器在编译过程中可能会产生交叉优化二进制文件,而且源代码可能会随着时间推进发生演变(例如经过补丁优化),产生交叉版本二进制文件,这些潜在因素都可能导致二进制漏洞的产生。一旦这些漏洞被别有用心之人利用,将对公司资产和运营产生不利影响。例如,若信息管理系统因漏洞未及时修补而受到黑客攻击或控制,将导致用户私人信息泄露,并且受攻击系统也可以作为黑客攻击其他系统的跳板。
相关研究人员已经开展了很多基于代码克隆的二进制文件相似度检测和二进制漏洞搜索工作,这些工作主要基于二进制函数的控制流图CFG(Control Flow Graph)来进行漏洞检测。这些方法的性能在合理配置下均表现良好,但是可能会导致大规模二进制文件损失以及漏洞搜索的低准确率。例如,Genius[1]利用谱聚类算法生成代码本,并基于二部图匹配算法计算特定属性控制流图ACFG(Attribute Control Flow Graph)与代码本中每个有代表性的属性控制流图(ACFG)之间的相似度,但此方法相当耗费时间,且准确率低;Gemini[2]提取出与Genius[1]相同的轻量级特征,并只依赖属性控制流图(ACFG)通过深度神经网络DNN(Deep Neural Network)来生成二进制函数嵌入向量,但由于特征提取不够合理,其搜索效率仍然较低;VulSeeker[3]优化了特征提取方式,以提取控制流图(CFG)和数据流图DFG(Data Flow Graph),组成标记语义流图LSFG(Labeled Semantic Flow Graph),并通过深度神经网络来获取二进制函数的嵌入表示;CACompare[4]通过模拟函数执行过程来提取函数中的语义签名,基于提取出的语义签名进行相似度检测,但是其模拟函数执行过程相当耗时,导致整体搜索效率低下;BinSeeker[5]则首先提取出函数的控制流图(CFG)和数据流图(DFG)组成标记语义流图,并通过深度神经网络(DNN)先筛选出一批漏洞函数,再进一步进行函数模拟来筛选出漏洞函数;Bingo[6]则利用选择性代码嵌入和长度可变部分追踪来计算函数语义,这些语义用于构建函数模型,以进行相似度的比较以及漏洞搜索,但Bingo不支持跨平台的漏洞搜索。α Diff[7]旨在应对交叉版本二进制文件相似度检测挑战,将二进制文件分为函数级和模块级进行相似度检测;赵鹏磊等[8]实现了基于标准化的无监督特征提取方法,并通过引入注意力机制来自动学习属性控制流图中不同节点的权重。这些方法在合理的实验配置下有着不错的搜索性能,然而,其分析二进制文件和漏洞文件的语义过于单一,进一步限制了其搜索性能及效率的提升。
本文提出了一种基于多粒度语义特征进行相似度比较的跨平台二进制漏洞搜索方法Taurus,解决了跨平台以及交叉优化所带来的二进制文件代码差异问题。给定待检测二进制文件和数据库中的二进制漏洞,Taurus分别对基本块、函数和模块3种不同粒度下的语义进行提取及分析,并计算3种粒度下的语义特征相似度。在获取到3种粒度下语义特征的特征相似度后,Taurus将计算其总体相似度,然后对相似度得分进行降序排序,最终判定目标二进制文件中是否含有疑似漏洞。
目前本文已实现Taurus原型程序,并将其与各种配置下的最新漏洞搜索方法进行了比较,结果表明Taurus具有更好的搜索性能。本文贡献如下所示:
(1)首次提出基于多粒度语义特征分析的二进制漏洞搜索方法,以提高漏洞搜索的准确性和效率。
(2)优化了原始的语义特征学习方法,通过标记语义流图(LSFG),深度神经网络(DNN)学习出的嵌入表示信息更加丰富。
2 Taurus方法
本节主要介绍Taurus方法及其实现原理。Taurus的任务是确定目标二进制文件中是否包含与已知漏洞相似的函数,其输入是来自待检测二进制文件和数据库中的二进制漏洞。如图1所示,Taurus共包含3个部分:多粒度语义特征提取、语义生成和相似度计算。给定待检测二进制文件以及数据库中的某个二进制漏洞,Taurus首先通过交汇式反汇编工具IDA Pro[8]提供的插件IDA Python提取2个文件中每个函数的控制流图(CFG),同时通过LLVM RR[9]插件推断2个基本块之间是否具有数据指向边缘,从而生成数据流图(DFG),最后将控制流图(CFG)和数据流图(DFG)整合为标记语义流图(LSFG),并通过特定的语义提取规则将其转换为初始数值向量,通过深度神经网络(DNN)计算出其在基本块粒度下的相似度值;然后,Taurus提取出2个文件的函数调用图,并获取函数调用图的入度和出度,通过欧氏距离计算出其在函数粒度下的相似度值;最后,Taurus提取出2个文件的导入函数集,通过集合交并关系获得其数值向量,亦通过欧氏距离计算出其模块粒度下的相似度值。在获取到3种粒度下的相似度后,Taurus将整合这3种相似度并计算2个文件中函数的总体相似度得分。在计算出待检测二进制文件与数据库中每一个二进制漏洞的相似度后,Taurus将所有的相似度得分进行降序排序,输出该二进制文件的漏洞检测报告。

Figure 1 Framework of binary vulnerability search method based on multi-granularity semantic analysis图1 基于多粒度语义分析的二进制漏洞搜索方法框架
2.1 基本块间语义特征
2.1.1 标记语义流图
标记语义流图(LSFG)包含控制流图(CFG)和数据流图(DFG),它们的边缘分别标记为0和1,其中0代表控制关系,1代表数据关系。使用标记语义流图(LSFG),目的是提高模块间语义生成的准确性,其同时考虑了函数中基本块的控制关系和数据关系,这将有效地缓解不同平台之间不同控制流图(CFG)引入的结构干扰。本文使用IDA Pro提供的IDAPython为每个二进制函数的基本块创建控制流图(CFG),并利用IDA Pro的LLVM RR插件推断2个基本块之间是否有数据指向边缘。对于来自2个不同的基本块中满足控制流图(CFG)拓扑的2条指令i和j,如果指令i为一个写存储器操作,而指令j读取相同的存储器地址,则为这2个基本块创建一条数据相关的边。另外,仅保留不同块之间的数据相关性,并且2个基本块之间至多存在有一条数据相关性边。Taurus将每个函数的控制边和数据边存储在2个文件中。
2.1.2 基本块间特征提取
通过参考已有工作[3]中使用的特征,并针对不同的特征集执行一系列代码克隆实验,本文最终确定使用表1所示的8种类型特征作为每个基本块的初始语义表示。这些选定特征可以在各种体系结构和编译优化配置下轻松提取和更改。利用IDA Python为每个基本块提取特征,然后根据表1将基本块中的8种特征指令按照特征数量编码为数值向量,如图2所示。对于每个二进制函数,函数中所有基本块的数值向量都存储在单独的文件中。

Table 1 Basic-block level features used by Taurus表1 Taurus使用的8种基本块特征

Figure 2 An example of the block feature extraction图2 特征提取的一个例子
对于基本块间的特征提取,本文通过语义感知深度神经网络(DNN)模型来完成。在该模型中,输入为函数中所有基本块的d维初始特征向量,输出则是表示函数语义的p维嵌入向量。为了精确捕捉函数语义,还要考虑到控制流图中基本块之间的数据以及控制关系。受VulSeeker[3]的启发,并参照Structure2vec[10]神经网络和Siamese[11]网络结构,本文提出如图3所示的语义感知深度神经网络(DNN)模型。

第t层嵌入的处理过程通过式(1)获得:
(1)

Figure 3 DNN model of Taurus图3 Taurus的深度神经网络模型
其中,w1是每层更新过程中的d×p维的待训练参数矩阵,C和D为待表示节点的控制流邻居节点集合和数据流邻居节点集合,σc和σd是以ReLU作为激活函数的n层全连接神经网络,如式(2)所示:
(2)
其中,n代表每个向量的嵌入深度,即全连接神经网络的层数;Ti和Oi(1≤i≤n)为每层用到的p×p维的参数矩阵;lc和ld分别为式(1)中待表示节点v的控制流邻居节点和数据流邻居节点的向量和。
基本块间语义特征提取过程如算法1所示。
算法1标记语义流图嵌入生成
输入:标记语义流图G=〈V,Ec,Ed〉。
输出:嵌入向量u。

步骤2 fort=1toTdo
步骤3forv∈Vdo

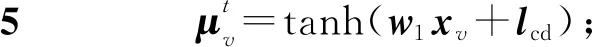
步骤6endfor
步骤7 endfor{将所有更新后的向量累加}
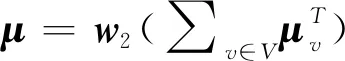
在得到待检测二进制文件的嵌入Ea和待检测二进制漏洞的嵌入Ev之后,通过式(3)计算其基本块间语义特征距离:
(3)
2.2 函数间特征提取
首先要明确的是函数不能单独运行,其需要在同一个二进制文件中调用其他函数或者被其他函数调用运行,这种特征称为函数间语义特征,可以用函数间的调用图来表示。值得注意的是,相似函数有相同调用图,理想状态下,需要考虑所有函数的调用图。
本文只从函数调用图中提取出1个节点的入度和出度来作为函数间语义特征,记为g(Ia)。具体来说,以目标函数Ia为例,令in(Ia)和out(Ia)表示函数Ia的函数调用图的入度和出度,如式(4)所示:
g(Ia)=(in(Ia),out(Ia))
(4)
然后通过欧氏距离来获取函数间语义特征距离,如式(5)所示:
D2(Ia,Iv)=‖g(Ia)-g(Iv)‖
(5)
2.3 模块间语义特征提取
对于目标二进制函数,它需要调用一组导入函数,记为S(Ia)。值得注意的是,即使在版本更新过程中这些函数发生了变化,相似函数也会调用相似的导入函数,因为在模块开发过程中未替换导入函数集,因此也可将导入函数集视为第3种语义,称为模块间语义。对于模块间语义特征的提取,通过处理2个文件导入函数集的集合交并关系,将其转换为数值向量,并通过计算欧氏距离来获取二者在模块粒度下的相似度。对于集合关系的获取,通过式(6)将导入的函数集嵌入到超集的空间中:
h(A,B)=〈x1,x2,…,xs,…,xt〉
(6)
其中,集合B为集合A的超集,t为超集B的势。若超集B中的第s个元素xs存在于集合A中,则记xs为1,否则为0。
对于目标函数Ia和漏洞函数Iv,记其二进制文件分别是Ba和Bv,则其导入函数集分别为imp(Ia)和imp(Iv),其二进制文件的导入函数集分别imp(Ba)和imp(Bv)。接下来,将超集定义为imp(Ba)∩imp(Bv),并利用式(6)分别将二进制文件和二进制漏洞在模块粒度下的语义特征转换为数值向量,然后利用式(7)计算其模块粒度下的语义特征相似度:
D3(Ia,Iv)=‖h(imp(Ia),imp(Ba)∩imp(Bv))-
h(imp(Iv),imp(Ba)∩imp(Bv))‖2
(7)
2.4 总体相似度计算及漏洞相似度排名
给定2个函数Ia和Iv,根据前文所述,可以计算出它们的基本块间特征距离(D1)、函数间特征距离(D2)和模块间特征距离(D3)。
由于函数的导入函数集通常比较稳定,因此通常模块粒度下的语义特征相似度D3数值位于0~1;其次,基本块粒度下的语义特征相似度D1同样也是位于0~1。由于交叉版本的二进制文件中的相似函数可以有不同的调用图,特别是不同的入度和出度,因此函数粒度下可能会有相对较大的距离D2。为了解决这个问题,本文预定义了一个(0,1)内的超参数λ,以抑制D2数值过大的影响。因此,2个函数的总体相似度计算方法如式(8)所示:
D(Ia,Iv)=D1(Ia,Iv)+1-λD2(Ia,Iv)+D3(Ia,Iv)
(8)
对于任意待检测二进制文件,可以计算出其与数据库中每一个二进制漏洞总体相似度得分,然后依照相似度得分进行降序,从而获取该二进制文件的漏洞检测报告。
3 实验
Taurus程序主要由3个模块构成:函数内语义特征提取组件、函数间语义特征提取组件和基本块间语义特征提取组件。Taurus使用的工具以及插件均基于IDA Pro 7.0。本节评估并测试Taurus在不同平台以及版本优化下的漏洞搜索性能,旨在回答以下3个问题:
(1)在跨平台二进制函数搜索中,Taurus是否比其他二进制漏洞搜索方法更准确?
(2)Taurus完成漏洞搜索任务所耗费的时间如何?
(3)Taurus是否可以在实际应用中进行漏洞搜索?
3.1 实验配置
本文实验平台配置为:Intel i7-8750H CPU,6核12线程,3.90 GHz ,6 GB显存 NVIDIA GTX 1060 GPU、内存为16 GB,且操作系统版本为64位Windows 10,版本号为2004。
3.1.1 数据集配置
为了公平地验证Taurus的漏洞搜索性能,本文沿用了Genius[1]和Gemini[2]中构造的2个人工数据集来评估不同的搜索任务。其中,数据集I用来训练Taurus,同时将Taurus与Genius、Gemini以及Taurus的2个变种Taurus-1和Taurus-2进行比较,Taurus-1是Taurus删除了函数间语义特征提取模块的版本,而Taurus-2是Taurus删除了模块间语义特征提取模块的版本;数据集II用于测试Taurus的漏洞搜索效率,由于其他工具涉及跨平台漏洞搜索,因此需要在不同平台上进行漏洞搜索。
数据集I沿用Gemini中的人工数据集,从5个不同的开源程序中编译了一组二进制文件:libjepg,Wget,OpenSSL,Coreutils和curl。通过具有4个优化配置(O0~O3)的2个编译器(GCC和Clang)将这些开源程序分别编译至3种体系结构(Windows X86/X64,MIPS32/MIPS64,ARM34/ARM64)。这个数据集中包含735 540个具有9 345×103个基本块的二进制函数,具体信息如表2所示。

Table 2 Open-source programs表2 开源程序列表
数据集II由从各种不同的平台选择的4 649个物联网固件镜像组成,并且这些固件镜像来自Genius[1]。
3.1.2 基线设置
Taurus需要一个带有大量标记的相似和不相似二元函数对的数据集进行训练,可以通过以下方法在数据集I中自动标记样本:将代码中的函数f编译为一组二进制函数,记为set(f)={f1,f2,…,fn}。对于set(f)中的每一个函数fi,随机选择一个不同的函数fj(i≠j)组成一个相似的样本对,记为Sam(fi,fj,+1)。同时随机选择set(f)中不存在的另一个二进制函数gk来模拟一个包含fi的不相似样本,记为Dis(fi,gk,-1)。最后,总共构造了大约3 677×103个样本对,且没有完全相同的样本对,只有相似和不相似的样本对。
3.1.3 训练方法
为了获得更准确的实验结果,本文通过10折交叉验证对Taurus进行训练和评估,即将样本对分为10个子集,9个子集用来训练模型,1个子集用来测试模型,重复此操作10次,每次选择一个不同的子集进行测试。每次完成训练后将随机调整训练集。训练的目的是获得模型Taurus中的参数:w1,T1,…,O1,…,On和w2,以优化式(9)所示的目标函数:
(9)
其中yi为待预测二进制文件的真实标签。
为了获得基本块间特征提取模型的最合适参数,本文通过随机梯度下降优化(即式(9)),直到模型可以达到最佳分类性能,终止训练。经过上述训练过程,Taurus中的基本块粒度语义特征提取模型将有效地将标记语义流图(LSFG)转换为嵌入。
3.2 漏洞搜索准确性评估
本节主要探讨问题(1),即本文方法是否可以更准确地进行跨平台漏洞搜索。
Taurus的任务是准确识别存在漏洞函数的二进制文件,通过数据集I对Taurus,Taurus-1,Taurus-2和Gemini的漏洞搜索效率进行评估。分别从数据集I中随机抽取2 100对二进制文件来比较Taurus与Gemini的漏洞搜索效率,其中3个不同平台各700对,最终结果如图4所示。
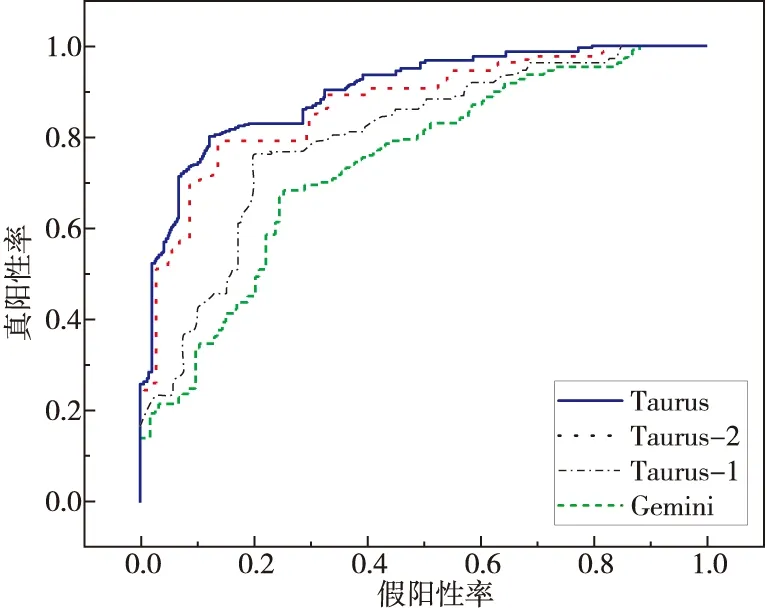
Figure 4 ROC curves of Taurus,Taurus-1,Taurus-2,and Gemini图4 Taurus,Taurus-1,Taurus-2和Gemini的ROC曲线
从图4可以观察到,Taurus及其2个变种的ROC曲线都位于Gemini[2]之上,可以推断出Taurus有较大的可能性先对漏洞函数进行分类。Taurus的AUC值为86.49%,比Gemini[2]的高13.19%,由此可以看出在漏洞搜索效率方面Taurus要优于Gemini[2],因为其可以获取到更多的语义信息,有助于高效地识别漏洞函数。
另外,值得注意的是,当分别删除函数间语义特征提取模块和模块间语义特征提取模块时,Taurus-1和Taurus-2的漏洞搜索性能依然呈上升态,进一步表明了本文方法的有效性。控制语义粒度的目的是分别探究函数间语义特征和模块间语义特征对漏洞的搜索效率的影响,实验结果表明,在分别去除函数间语义特征提取模块(Taurus-1)和模块间语义特征提取模块(Taurus-2)后,Taurus-1的AUC值比Taurus-2的小13.76%,这表明对于二进制文件相似性检测而言,函数级语义要比模块级语义重要得多。
3.3 漏洞搜索效率验证
本节主要回答有关Taurus完成漏洞搜索任务的时间成本的问题(2)和有关现实生活中搜索性能的问题(3),在此分别讨论了对数据集II进行漏洞搜索的时间和对数据集I进行训练的时间。表3列出了Genius、Gemini和Taurus的程序搜索时间,第2列可以观察到每个程序包含的函数数量,而第3~5列是每种方法执行漏洞搜索所耗费的时间。

Table 3 Searching time of three methods表3 3种方法所耗费的搜索时间
表3中,所有程序平均包含1 895个函数。在搜索效率方面,Gemini和Taurus所需的时间较短,平均只需284 s和502 s即可完成漏洞搜索,这意味着Gemini和Taurus平均只需要0.15 s和0.26 s来计算目标函数和漏洞函数之间的相似度。但是,Genius需要2 976 s才能完成1 895个函数中的漏洞搜索。与Gemini和Taurus相比,Genius的时间成本要高得多,比前二者分别高10.48倍和5.93倍。结合图4综合来看,尽管Taurus比Gemini花费了更多的时间,但它却以少量的时间为代价实现了更高的搜索准确性,因此Taurus更适用于大规模代码的漏洞搜索任务。
对于本文配置的100 000对函数样本,Genius通过谱聚类算法生成模型大约需要50天。而Gemini和Taurus受机器配置的限制,模型训练的时间成本分别约为17天和23天。但是,训练过程为一次性,之后几乎不会影响漏洞搜索效率。这意味着一旦完成模型参数训练,就可在任何情况下重用它,而无需再花费时间训练。
3.4 参数研究
本节主要讨论如何设置参数可以使得Taurus达到最佳性能,同时还评估了不同参数对漏洞搜索性能的影响。Taurus语义学习模块的参数主要包括:嵌入尺寸、嵌入深度和迭代次数。
3.4.1 嵌入尺寸
嵌入尺寸是指用于表示函数语义的嵌入向量的维数p。与前文相同,本节还是通过ROC曲线来评估嵌入尺寸对漏洞搜索性能的影响。图5是Taurus在不同嵌入尺寸下的ROC曲线,可以推断,当嵌入尺寸为64时,Taurus的AUC值相当可观。同时考虑到训练和预测时间的成本,本文最终选择64作为默认嵌入尺寸。

Figure 5 ROC curves of different embedding sizes图5 不同嵌入尺寸下的ROC曲线
3.4.2 嵌入深度
嵌入深度是指Taurus中基本块间语义特征提取模块中全连接神经网络的层数n。图6为改变嵌入深度的效果。当嵌入深度为2时,可以获得相对最佳的AUC值。结果表明,通过添加2层全连接神经网络,生成的嵌入向量将具有更高的表示性能和更好的函数语义捕获。但是,当嵌入深度大于2时,只会徒增时间成本和人工成本。

Figure 6 ROC curves of different embedding depths图6 不同嵌入深度下的ROC曲线
3.4.3 迭代次数
如前文所述,迭代次数是指Taurus中基本块间语义特征提取模块的隐藏层层数T。图7为Taurus在不同迭代次数下的ROC曲线。从图7中可以推断当迭代次数为6时,本文方法将获得漏洞搜索的最佳性能,且在条件允许的情况下,迭代次数越多,结果越好。
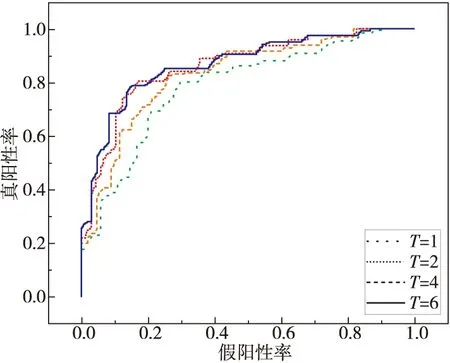
Figure 7 ROC curves of different iterations图7 不同迭代次数下的ROC曲线
4 结束语
本文提出了一种基于3种语义特征的跨平台二进制漏洞搜索方法Taurus,通过集合基本块间语义特征、函数间语义特征和模块间语义特征进一步提高了漏洞搜索的效率及准确性。实验表明,Taurus在漏洞搜索准确性上比其他相关工作高,且在不同平台上都略有提高,适用于现实生活中的跨平台二进制漏洞搜索。
