OpenCL计算软件栈评估*
2021-12-23周博洋卢雪山杜溢墨
朱 浩,周博洋,卢雪山,杜溢墨
(1.军事科学院国防科技创新研究院,北京 100000;2.国防科技大学计算机学院,湖南 长沙 410073;3.空军后勤部,北京100000;4.31008部队,北京100091)
1 引言
人工智能及其支撑技术将成为决定未来社会发展的重要因素之一,人工智能技术在感知与信息处理、指挥决策、网络空间安全和无人系统等领域正发挥着越来越重要的作用。以使用GPU为代表的异构计算进行人工智能应用处理的效能更高,因此研究人员提出了CPU+GPU的异构模式,由CPU进行逻辑控制和数据转发,而GPU则负责大规模运算,这样的各取所长的工作方式更有利于GPU性能的发挥。
计算软件栈是发挥GPU硬件性能的关键。NVIDIA公司专门针对自己生产的系列GPU设计了CUDA计算软件栈。CUDA提供了简单的开发工具可用于设计GPU应用程序,降低了开发难度,并与计算库、驱动等相配合实现了程序在GPU上高效的在线编译、提交和运行。与CUDA相比,开放运算语言OpenCL(Open Computing Language)[1]是一个面向异构系统的完全免费的通用标准,并且适用于多种架构的处理器。OpenCL仅仅是一个通用的API,只提供函数接口,在此基础上衍生出了很多开源的计算软件栈,比如AMD维护的ROCm[2]、Freedesktop维护的Mesa[3]等,便于人们应用和研究。
虽然CUDA拥有比较好的性能和市场表现,但是由于目前CUDA源码闭源并且主要支持NVIDIA的GPU和Intel商用平台,没有广泛的移植性。考虑到未来在飞腾CPU和麒麟操作系统等国产软硬件平台上会有大量GPU计算移植和适配的需求[4,5],本文重点研究开源的OpenCL计算软件栈包括Mesa、ROCm(Radeon Open Computing)等,研究评估不同计算软件栈在程序各个执行阶段的性能差异、在Intel平台和国产平台上的性能差异等,为OpenCL软件栈的选型和优化提供决策依据。
2 OpenCL计算软件栈
2.1 OpenCL
OpenCL是第一个面向CPUGPUFPGA等异构系统并行编程的开放式、免费标准,也是一个统一的编程环境,当前最新协议为OpenCL 3.0。OpenCL协议有多种系统实现,目前主流计算软件栈有Mesa和ROCm。
OpenCL应用的流程包含编译、数据交换和执行等多个过程,如图1所示,具体到源码通常包含clGetPlatformIDs(获取平台)、clGetDeviceIDs(获取设备)、clCreateContext(创建Context环境)、clCreateCommandQueue(创建命令队列)、clCreateBuffer(创建缓冲对象)、clEnqueueWriteBuffer(Host写数据到GPU)、clCreateProgramWithSource(创建程序,为Context环境创建程序对象,并将Kernel源码加载到该对象中)、clBuildProgram(编译程序)、clCreateKernel(创建Kernel)、clSetKernelArg(设置Kernel参数)、clEnqueueNDRangeKernel(提交并执行Kernel)和clEnqueueReadBuffer(数据拷贝回Host)等函数,OpenCL提供了这些函数接口的定义。而Mesa和ROCm等软件栈的主要区别就在于以不同的方式实现了这些函数,所以性能会有差异。

Figure 1 Running process of OpenCL applications图1 OpenCL应用的运行流程
OpenCL应用程序包含C程序代码和Kernel程序代码。C程序代码负责除内核计算以外的设备初始化、数据输入输出、Kernel程序提交和执行等部分;Kernel程序代码是在GPU上执行的计算部分。OpenCL应用程序的内核部分是通过LLVM(Low Level Virtual Machine)编译器[6]运行时编译(Just In Time Compile),LLVM编译器前端负责对程序进行语法分析、词法分析以及优化后转成LLVM IR格式的中间语言;LLVM后端根据当前使用何种GPU设备来完成中间语言到GPU可执行语言的编译。
2.2 Mesa
Mesa(全称Mesa 3D)是一个完全开源的设备驱动程序,支持多种GPU,于1993年8月由布莱恩·保罗提出,设计之初仅仅是为了实现OpenGL的功能。在随后的发展中,其内容不断丰富并加入了GLX(OpenGL extension to X)、EGL、OpenCL等功能的实现。其中实现OpenCL语言的项目叫做Clover。
Mesa Clover能够支持OpenCL 2.2协议,对AMD 显卡有良好的支持。Mesa Clover结构简单,在处理数据量不大的OpenCL应用时,相比其它软件栈有一定的性能优势。
2.3 ROCm
ROCm是AMD维护的成熟的完全开源的OpenCL实现,支持OpenCL 2.2。ROCm有比较完整的生态,不仅支持OpenCL计算,还可以通过HIP(Heterogenous-compute Interface for Portability)支持CUDA计算,还包含丰富的调试、性能分析和开发环境等工具,是GPU计算方向比较活跃的项目。
ROCm主要包括3个部分:ROCm 库、ROCm平台和ROCm内核驱动,如图2所示。
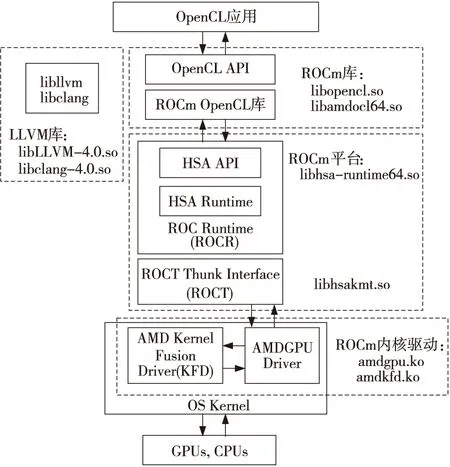
Figure 2 Architecture of ROCm图2 ROCm的软件栈结构
ROCm库包含OpenCL API和OpenCL库,其中OpenCL API是规范中定义的标准接口,ROCm OpenCL库就是OpenCL API的实现。ROCm平台主要实现了异构系统的功能,从系统层面整合CPU和GPU资源,也支持AMD的独立GPU计算。最大特点是对异构资源统一定义了虚拟地址空间,通过共享指针来共享数据,减少数据在不同资源间的拷贝次数。ROCm内核驱动用来支持异构系统的内核驱动,其主要功能包括支持任务队列,简化计算任务在CPU和GPU上的分布,支持异构存储管理以及驱动间的交互。其中,AMDKFD主要负责异构计算任务的处理,AMDGPU Dirver除了支持显示和计算以外,还提供GPU设备的初始化,为AMDKFD提供设备信息等功能。
3 国产平台和商用平台对比评估
本节对国产飞腾平台和Intel商用平台上的软件栈性能进行对比分析,了解CPU性能对GPU应用计算的影响程度。进行平台对比测试的环境如表1所示,本节采用了飞腾1500A 4核处理器(后文称FT 1500A)和Intel i7 4核处理器,选择了当前飞腾台式机上主流、适配成熟的显卡执行计算,OpenCL软件栈为Mesa 17.0。

Table 1 Test environment of Pytium and Intel platforms表1 国产飞腾平台和商用Intel平台软件栈性能测试环境
OpenCL测试程序采用Black-Scholes基准程序(简称B-S),该程序用于计算期权定价,数据输入是期权数集合(为了对比更加直观,本文将存储浮点型期权占用的存储空间转化成数据量的大小),直接反映的是数据并行处理能力。对Black-Scholes基准程序的编译、数据读写、运行和完成等过程进行采样,测试这些OpenCL接口的执行时间以及GPU加速比(CPU计算时间/GPU计算时间)。后面各图中X轴是将期权数转化成数据量大小后的值,Y轴是执行时间。
如图3所示,Intel i7处理器的应用程序内核编译性能是FT 1500A处理器的5倍左右,由于是采用多线程编译,这个数据可以反映出不修改LLVM编译器默认条件下Intel i7处理器的多核并行计算能力大概是FT 1500A的5倍。
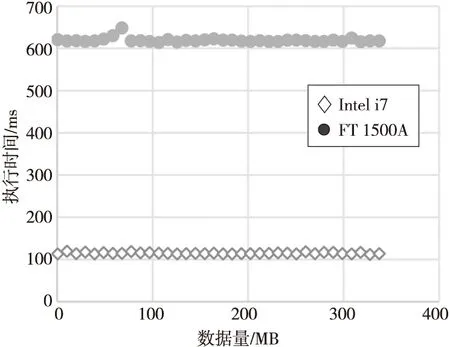
Figure 3 Build kernel time of B-S application on Phytium and Intel platforms图3 B-S应用在飞腾和Intel平台上的编译内核时间
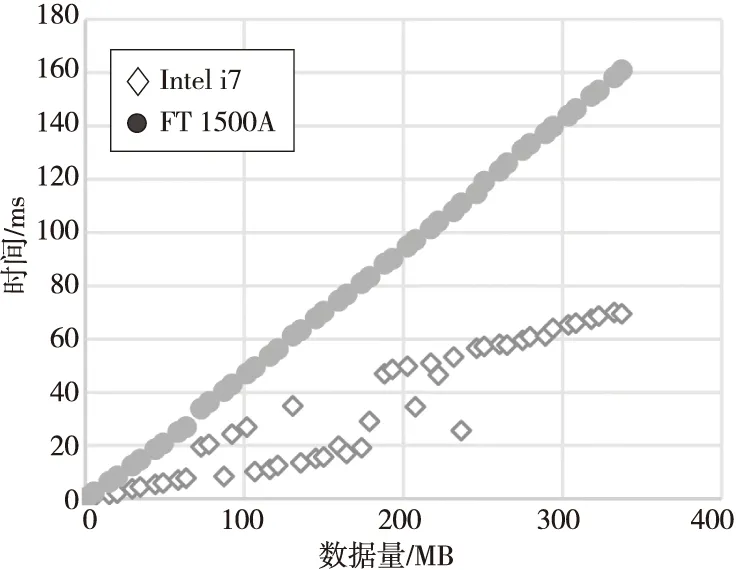
Figure 4 Read buffer time of B-S application on Phytium and Intel platforms图4 B-S应用在飞腾和Intel平台上的Read buffer时间
Read buffer时间反映的是CPU从GPU读取处理后数据的能力。如图4所示,当数据量小于175 MB时,FT 1500A执行时间大约是Intel i7的3.5倍;当数据量大于175 MB时,FT 1500A执行时间大约是Intel i7的2倍。
评估内核函数在GPU上的实际执行时间,记录为GPU计算时间。如图5所示,开始FT 1500A上GPU计算时间几乎与Intel i7的相等,数据量在240 MB附近时,FT 1500A的GPU计算时间出现跳跃式大幅度增加,接近4倍,而数据量在240 MB附近时,Intel i7的GPU计算时间有小幅度增加。考虑到这部分时间主要运行在GPU端,导致时间的差异应该是与CPU性能无关的,经过分析发现主要是由于CPU体系结构的不同,导致编译后的内核代码不同。在对内核代码进行编译时,LLVM编译器会根据CPU体系结构的不同,编译生成字的节码有所区别。在Intel商用平台上使用其他处理器运行B-S应用来测试GPU计算时间,确实没有区别,这证实了主要跟体系结构有关。
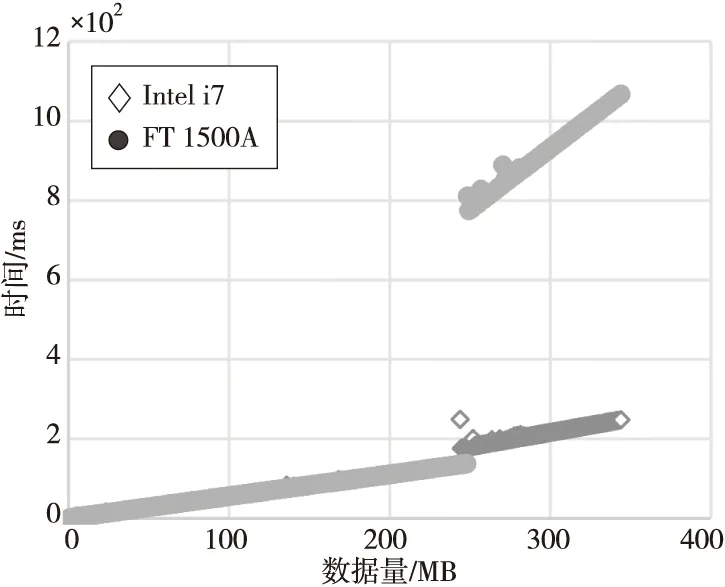
Figure 5 GPU running time of B-S application on Phytium and Intel platforms图5 B-S应用在飞腾和Intel平台上GPU计算时间
为了了解是国产飞腾平台还是商用Intel平台上加速效果更明显,获得GPU执行计算的加速比,首先将B-S应用内核函数的算法重写并使用CPU进行计算,得到2个平台上各自的CPU计算时间。如图6a所示,Intel i7的性能优势随着数据量的增大越来越明显,FT 1500A的执行时间最大时大概是Intel i7的2.8倍。用CPU计算时间除以GPU计算时间和可以得到应用程序的加速比。当数据量低于240 MB左右时,FT 1500A上的加速比高于Intel i7上的,超过20倍。当数据量超过240 MB时,Intel i7上的加速比高于FT 1500A上的,这是因为在FT 1500A上,内核的GPU执行时间在数据量超过240 MB时出现跳跃点,性能突然变差(如图6b所示)。整体来说,Intel i7上的加速比大概在5~10倍波动,FT 1500A上的加速比大概在4~20倍波动,最后两者分别稳定在5倍左右。
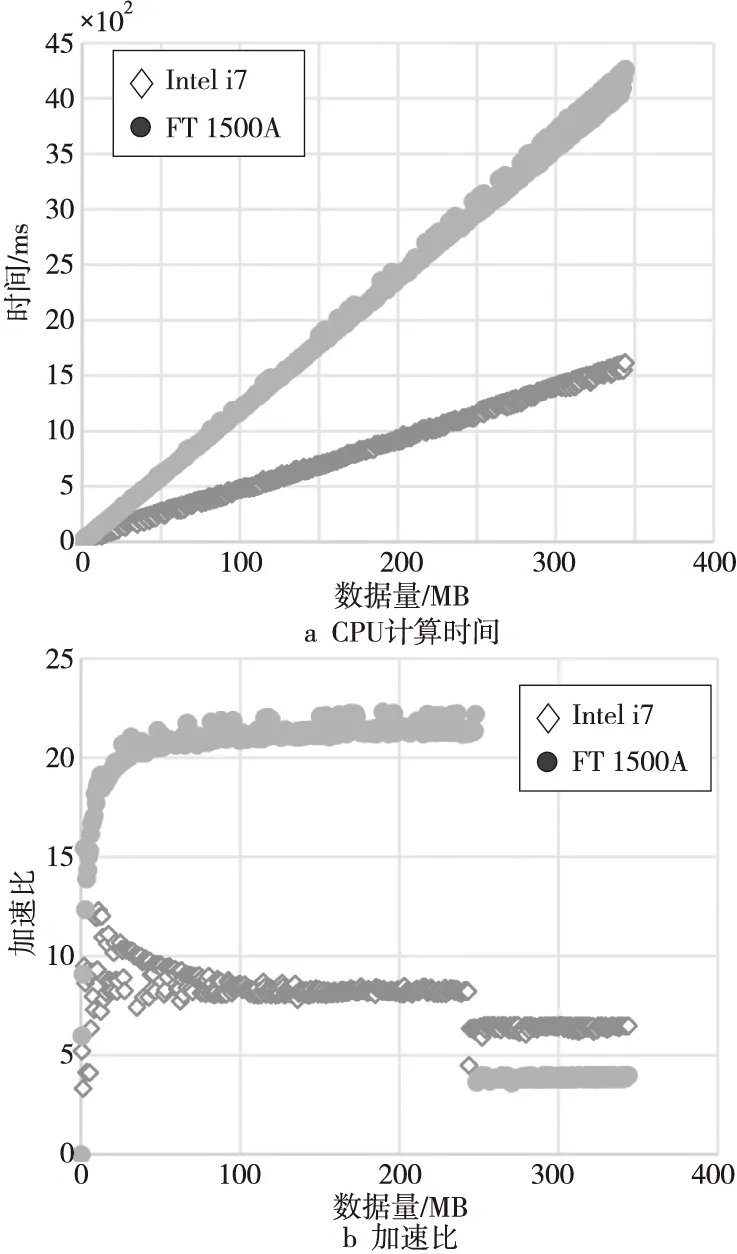
Figure 6 CPU running time of B-S application on Phytium and Intel platforms图6 B-S应用在飞腾和Intel平台上的CPU计算时间

Figure 7 Overall running time of B-S application on Phytium and Intel platforms图7 B-S应用在飞腾和Intel平台上的运行时间
如图7a所示,考虑测试初始化、编译、数据准备和GPU计算等过程的运行总时间,FT 1500A上的执行时间是Intel i7上的3.3~5.2倍。如果不考虑初次运行的编译时间,如图7b所示,FT 1500A上的执行时间是Intel i7上的2~4.1倍。
结合以上测试数据,对在国产平台和商用平台上进行GPU计算的性能评估总结如下:
(1)OpenCL应用的编译时间、数据拷贝时间、GPU计算时间等,也就是GPU应用的整体性能都和CPU平台的性能、体系结构有关。国产平台和商用平台2种不同CPU体系结构上的GPU计算时间(即内核函数在GPU上的执行时间)会有区别,主要是因为内核程序编译生成的可执行代码受体系结构的影响有差异。
(2)在计算数据量较小时,FT 1500A上使用GPU计算获得的加速比更大;数据量越大尤其是超过某个值时,GPU计算时间会有不同程度的跳涨,Intel平台上的GPU加速性能更优。这个跳涨的时机和原因有待进一步分析。当要处理的数据量较大时,国产平台上受制于CPU性能和体系结构编译优化方式等瓶颈因素,GPU计算获取的加速收益不如Intel商用平台。
(3)虽然大数据量计算时国产平台上计算加速收益不如Intel商用平台,但如果不考虑编译时间,FT 1500A上OpenCL应用执行时间比Intel i7 CPU上长2~4.1倍,小于FT 1500A与Intel i7 CPU本身的性能差距(这个差距大概是5倍)。在有的程序既可以使用CPU计算也可以使用GPU计算时,在国产平台上应更多地使用GPU进行计算,减少CPU性能差异带来的负面影响。
(4)在国产平台上优化OpenCL计算,应该是整个软硬件系统的优化,而不能仅仅优化GPU硬件体系结构。
4 软件栈对比评估
Mesa和ROCm是当下2个比较热门的OpenCL开源计算软件栈,本节对比了OpenCL应用在2个软件栈上的性能表现,作为对照还增加了AMD-APPSDK软件栈的测试,APPSDK是AMD公司维护的一个闭源的OpenCL计算软件栈。考虑不同平台上的驱动和内核有差异,可能会对应用执行产生影响,最后对驱动、内核造成的运行时间影响进行评估。
4.1 OpenCL软件栈测试
OpenCL软件栈测试环境如表2所示,采用了Intel i7处理器平台,装配有AMD中端档次的RX460显卡,内核版本是4.15,驱动分别是开源的amdgpu和闭源的amdgpu pro,执行B-S应用。测试时对比的OpenCL软件栈分别为ROCm、APPSDK、Mesa-open(Mesa,采用开源驱动)和Mesa-close(Mesa,采用闭源驱动)。
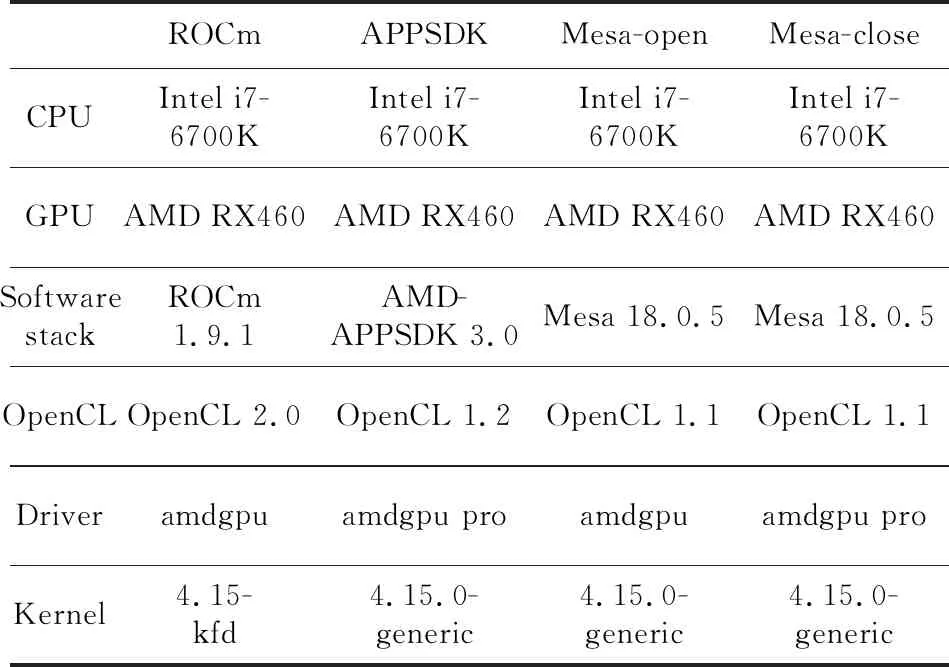
Table 2 Test environment of software stack 表2 软件栈测试环境
如图8所示,进行Create Buffer缓存的分配时,ROCm的执行时间随着数据量的增长而快速上升,其他3种软件栈几乎没有变化,多次测试均是这个结果。通过对代码分析发现,ROCm在缓存分配时会进行实际的物理分配,而其他的软件栈只是创建一个mem结构体,在读写时才进行实际的物理空间分配。

Figure 8 Create buffer running time of B-S application on various software stacks图8 B-S应用在不同软件栈上的Create Buffer执行时间
如图9所示,对比内核程序编译的时间,Mesa上编译时间最长,其次是ROCm,最短的是APPSDK。经过分析发现,编译性能的差异主要是由于LLVM编译器在对内核源码进行编译生成ISA代码过程中,编译后端的目标组合(Target Triple)差异性导致的,比如Mesa的目标组合是(amdgcn,Mesa3d,Mesa3d),ROCm的目标组合是(amdgcn,amd,amdhsa)。这个编译目标组合是在LLVM编译器里定义的,整个三元组含义是:(AMD GPU体系结构,厂商,操作系统环境)。根据目标组合的不同,不同的软件栈编译成的ISA代码就会有差异,从而导致编译内核执行时间有所差距,最终导致在GPU运行内核程序的效率有差别。

Figure 9 Build kernel running time of B-S application on various software stacks图9 B-S应用在不同软件栈上的编译内核执行时间
如图10所示,内核程序在GPU上计算时,在数据量低于240 MB时,APPSDK和ROCm的执行时间都略高于Mesa的。对Mesa来说,GPU上的计算时间仍存在一个跳跃点,当数据量高于240 MB时,Mesa开闭源的性能都会突然变差,执行时间达到APPSDK和ROCm的2倍。
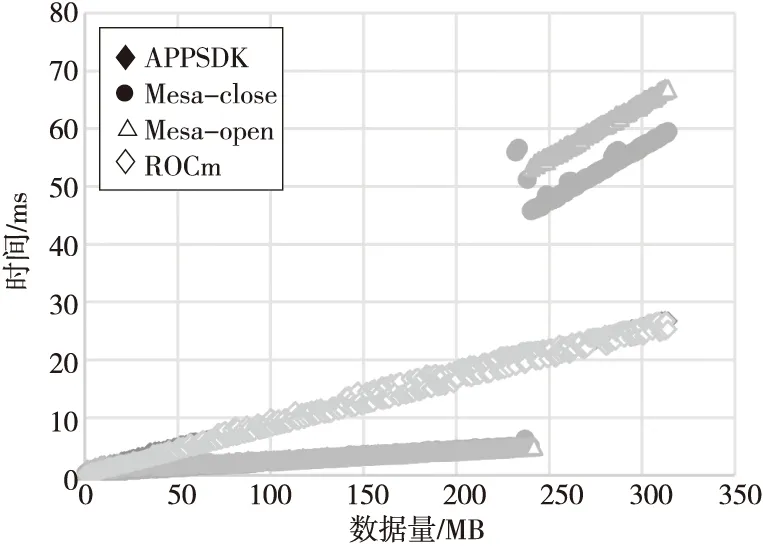
Figure 10 GPU running time of B-S application on various software stacks图10 B-S应用在不同软件栈上的GPU计算时间
如图11a所示,将主机内存数据写入GPU存储时,Mesa软件栈无论开闭源驱动,它们的执行性能都相近,都低于ROCm和APPSDK上的性能。但是,当数据量高于240 MB时,存在一个跳跃点,Mesa开源驱动上的执行时间长于Mesa闭源驱动的。
如图11b所示,将GPU计算产生的数据读回主机内存上是Read buffer,与Write buffer的表现类似,Mesa的性能差于APPSDK和ROCm的。在数据量为240 MB左右时,Mesa的执行时间有个快速增长的区间。
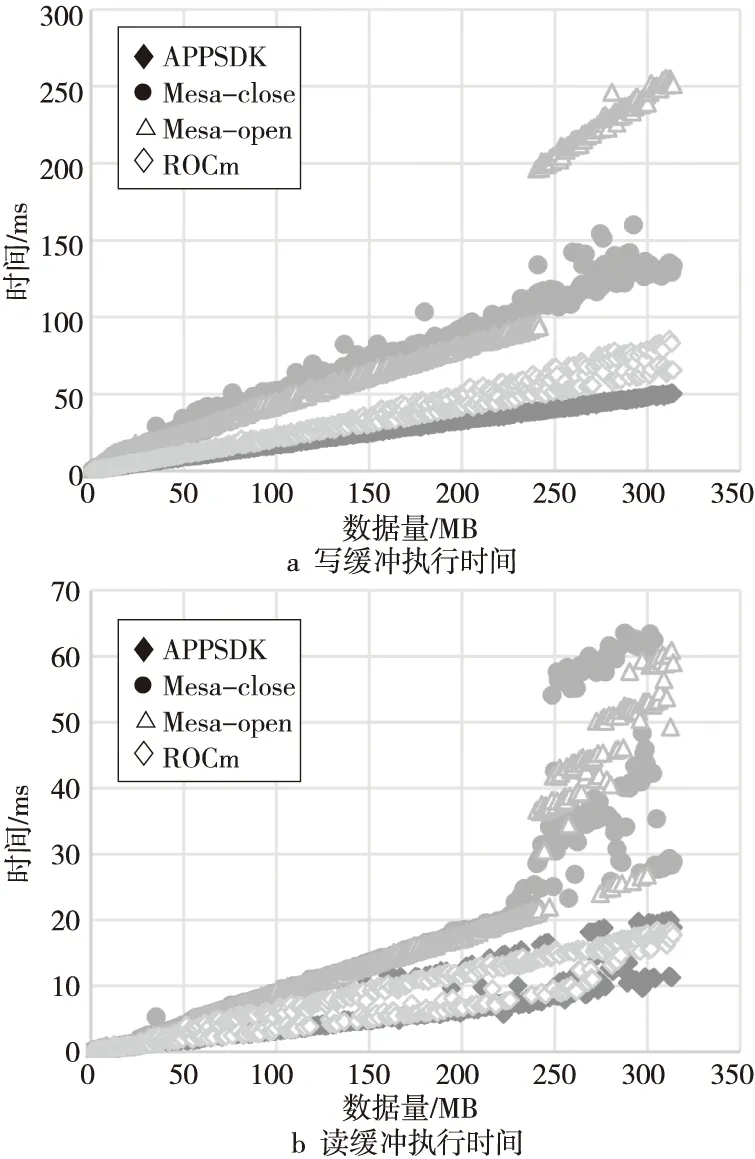
Figure 11 Read/Write buffer time of B-S application on various software stacks图11 B-S应用在不同软件栈上的读写缓冲执行时间
如图12所示,对比B-S应用从提交到执行结束的总执行时间,APPSDK有最好的性能表现,当数据量较小时(100 MB左右),ROCm上的执行时间长于Mesa上的。但是,当数据量在240 MB附近时,Mesa上的执行时间会快速增加。

Figure 12 Overall running time of B-S application on various software stacks图12 B-S应用在不同软件栈上的总时间
对OpenCL软件栈测试总结如下:
(1)应用总的执行时间,最优的是APPSDK,ROCm次之,然后是Mesa加闭源驱动的组合,最后是Mesa加开源驱动的组合。
(2)对GPU计算时间来说,尤其是大数据量时,APPSDK、ROCm平台的GPU性能优于Mesa的。APPSDK和ROCm的性能曲线是基本相同的,Mesa平台开闭源性能曲线基本相同。这说明了LLVM编译器针对APPSDK和ROCm的优化更好,相同内核函数在这两者上的执行效率更高。
从图10可以看出GPU计算时间,Mesa性能明显差于APPSDK和ROCm的,并且在数据量为240 MB时会有一个跳跃点,执行时间会明显增长。为了证明普遍性,本文又对比了另外几个应用的GPU计算性能。
如图13所示,进行2D图像卷积(Convolution-2D)测试,在Mesa上的GPU计算时间上升幅度明显高于ROCm上的,当数据量达到240 MB附近时,也出现跳跃式增加。而ROCm上的GPU计算时间一直平稳上升,在数据量达到280 MB时,增速仅仅有小幅度增加。这说明对于Mesa,数据量达到一定阈值时,应用的性能会有较大衰减,原因初步分析与Mesa中固定内存的创建方式有关,更深入的研究是下一步的工作。
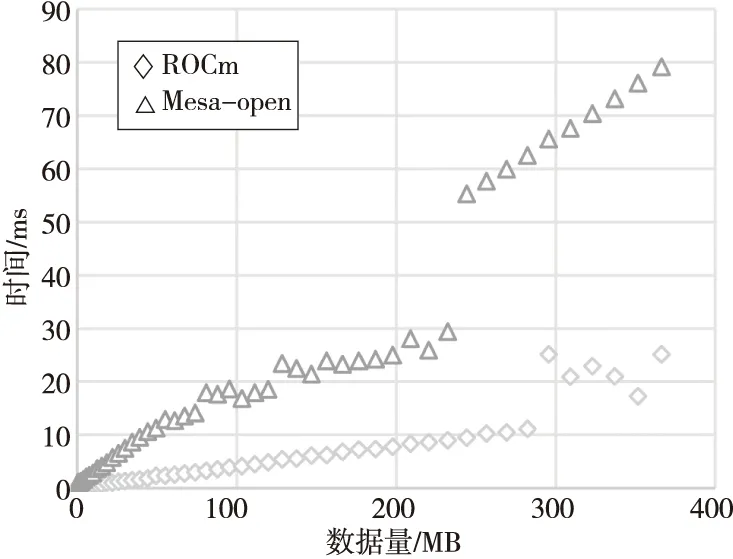
Figure 13 GPU running time of 2D convolution application on various ROCm and Mesa-open图13 ROCm和Mesa-open上2D图像卷积测试的GPU计算时间
Rodinia srad是超声波和雷达成像应用,用于消除局部相关噪声,而不会破坏重要的图像特征。Rodinia hotspot用于根据建筑平面布置图和模拟功率测量来估算处理器温度。如图14所示,Mesa上的Rodinia srad GPU计算时间为ROCm上的1.97倍。对于Rodinia hotspot应用,Mesa的GPU计算时间为ROCm的3倍。进一步证实了Mesa平台上的GPU计算性能确实不如ROCm上的。

Figure 14 GPU running time of Rodinia applications on ROCm and Mesa-open图14 Rodina应用在ROCm和Mesa-open栈上的GPU计算时间
下面2小节对驱动、内核差异造成的运行时间影响进行评估。OpenCL应用运行依赖的OpenCL软件栈还包括系统软件栈,比如底层的驱动和内核,它们构成了一个完整的软件栈来实现应用与硬件的交互。
4.2 开闭源驱动测试
从图12可以看出,应用在Mesa加开源驱动上运行与Mesa加闭源驱动的相比,性能要差一些,并且随着数据量的增大,性能差距越来越大。为了说明这种现象的普遍性,本节选择使用另一种OpenCL应用Adi进行确认测试。Adi是针对多核CPU和GPU的基准测试套件PolyBench-ACC中的测试用例。
如图15所示,与B-S应用的Write buffer和Read buffer类似,Adi应用在Mesa开源驱动上运行与Mesa闭源驱动上相比,开源驱动的性能要差,当数据量小时差距比较小,开源驱动上的运行时间波动大。
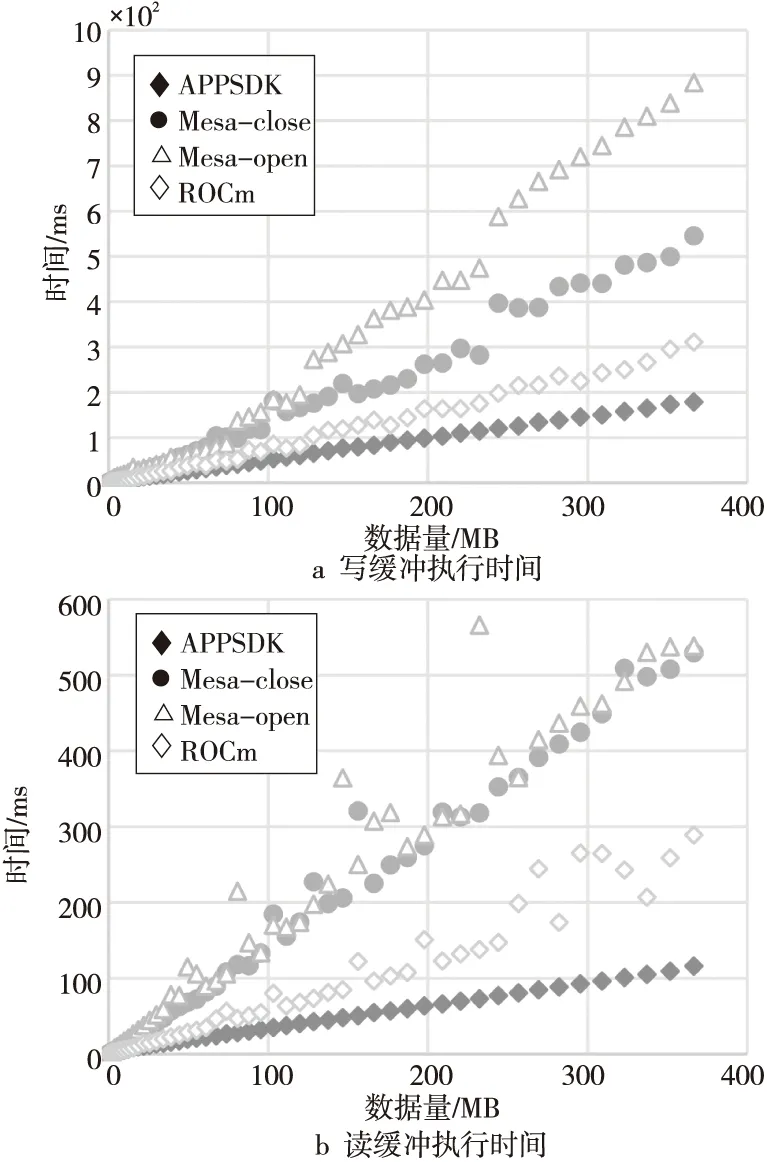
Figure 15 Read/Write buffer time of Adi application on various software stacks图15 Adi应用在不同软件栈上的读写缓冲执行时间
如图16所示,与B-S应用类似,Mesa上的Adi应用GPU计算性能比较差,并且开闭源驱动均会在240 MB数据量时出现较大波动。

Figure 16 GPU running time of Adi application图16 Adi应用在GPU上的计算时间
根据B-S应用和Adi应用等的性能表现,总结开闭源软件栈测试结果如下:
(1)开闭源驱动会对读写缓冲和GPU计算时间等过程产生影响。
(2)在数据量未超过跳跃点时,开闭源驱动执行的总时间几乎相等,开闭源驱动的GPU性能没有差异,当数据量超过跳跃点后,闭源驱动的GPU性能略高于开源驱动。经过对同一时间点开发下载的开闭源驱动对比分析发现,无论是OpenCL软件栈还是驱动闭源软件栈的版本,相对于开源版本都比较新,厂商会优先将一些新的特性优化集成在闭源版本中,这是GPU厂商的市场策略,这也是闭源性能有优势的主要原因。
4.3 内核版本测试
这一节评估内核版本对B-S应用进行GPU加速计算的影响。内核V4.15是Ubuntu1804版本默认采用的内核,与之前的长期支持LTS内核版本有较大的改动,本节测试选择了在4.15前后的2个内核进行对比,即Ubuntu1604.2默认的4.8内核版本与Ubuntu1804.1默认的 4.18版本。
如图17所示,在数据量小于100 MB时,高低版本总执行时间接近,随着数据量增大,4.8版本的总执行时间相比4.18版本的总执行时间越来越长,超过300 MB时,4.8版本的总执行时间接近4.18版本的2倍。
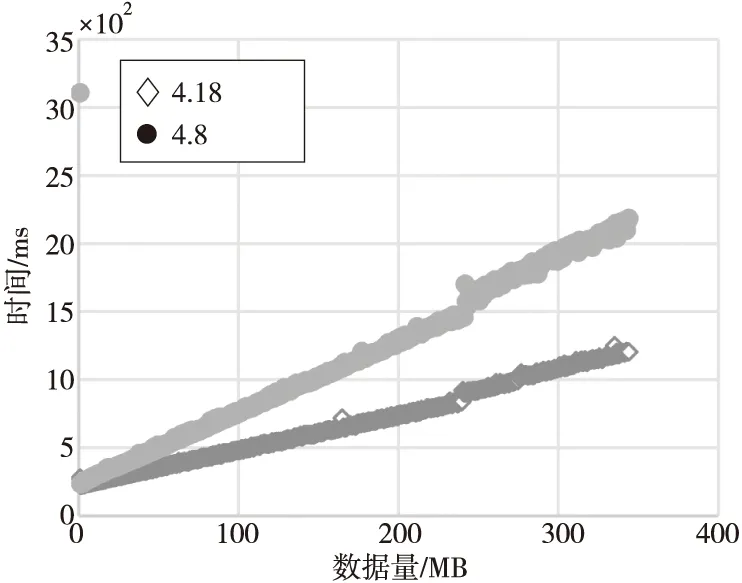
Figure 17 Overall running time of B-S application on various kernels图17 B-S应用在不同内核条件下的总运行时间
总结对内核版本差异的测试,可以看出:内核版本变化对GPU计算时间影响比较微小,主要是在数据量达到一定阈值后,2个版本上的时间才有差别,新版本上的性能较优。
4.4 总结
对第4节的测试结果总结如下:
(1)Mesa平台上的GPU应用有一个跳跃点(数据量240 MB左右),超过这个点,应用执行时间会跳跃式增长;但是ROCm不存在这种明显的跳跃点,执行时间增长比较平稳。Mesa与ROCm的GPU计算性能差异与算法和数据量有关,ROCm的GPU计算性能为Mesa的2.5~15倍左右(算法越复杂,数据量越大,ROCm优势越大)。
(2)ROCm开源平台相对于APPSDK闭源平台,应用总的执行时间在数据量小时存在劣势,存在很大的优化空间。相比Mesa,ROCm是以后在国产平台上进行移植和适配优化比较理想的GPU计算软件栈。
(3)在闭源驱动、新版本的驱动和内核上运行GPU应用运行性能有一定的优势,在国产平台上进行GPU计算时尽可能选择新版本的操作系统。
5 相关工作
Karimi等人[7-9]评估了NVIDIA GPU上的OpenCL和CUDA性能,对比了数据迁移性能、内核执行时间和总的执行时间,CUDA在某些场景下相对OpenCL有比较好的性能,但OpenCL的高可移植性决定了它是CUDA的一个很好替代。Komatsu等人[10,11]评估了OpenCL应用的性能和可移植性,OpenCL应用可以通过调优达到理想的性能。Mukherjee等人[12]对比了2种软件栈OpenCL和异构系统体系结构HSA(Heterogeneous System Architecture),HSA是HSA基金会维护的一种异构计算软件栈,由于HSA提供了共享虚拟内存、动态并行化等新特性,在异构平台上相比OpenCL具有更好的性能。另外还有一些研究是关于OpenCL测试基准的设计和实现[13-15],用于分析异构系统的瓶颈和优化系统性能。本文主要是在国产和商用平台上对不同OpenCL软件栈的性能进行对比分析,从系统软件栈和系统优化角度进行更加全面深入的研究。
6 结束语
本文基于Black-Scholes、2D-Convolution、Rodinia等几种测试集评估OpenCL软件栈在不同条件下的性能表现,为GPU计算机软件栈选型和优化提供依据。通过对国产和商用平台上OpenCL性能测试发现,CPU对GPU计算有比较大的影响,对GPU计算的优化应该是从CPU到GPU、从软件到硬件成体系的优化。通过对比和测试不同软件栈发现,ROCm的性能和稳定性都优于Mesa等软件栈,比较适合以后在国产平台上进行移植和优化。闭源版本和新版本的软件栈相对于稳定的开源版本会有一定的性能优势,为版本选型提供了依据。
