基于深度学习的草图检索方法研究进展*
2021-12-23姬子恒
姬子恒,王 斌
(南京财经大学信息工程学院,江苏 南京210023)
1 引言
基于内容的图像检索技术CBIR(Content-Based Image Retrieval)[1 -3]是计算机视觉和图像处理领域一个重要的研究方向,其任务是在图像数据库中检索与用户所提交样本图像在内容上一致或相似的图像,主要是通过对图像底层特征的比较来实现。CBIR执行的前提是需要用户提供一幅自然图像,以表达用户的检索意图。但是,在实际应用中,找到一幅准确表达用户检索意图的自然图像并不容易,且在很多情况下,很难得到这样的自然图像,从而限制了用户的个性语义表达。一个替代的方法是,用户可以提供一幅自画的草图来表达其检索意图,因此基于草图的图像检索技术应运而生。基于草图的图像检索SBIR(Sketch Based Image Retrieval)是CBIR检索形式的扩展,相较于CBIR,手绘草图可更方便、更直接地表达用户的检索意图。图1a为使用百度CBIR识图检索系统,用鸭子的自然图像作为检索图像,返回的前4个图像的检索结果;图1b为Pang等人[4]实现的SBIR检索系统,用鸭子草图作为检索图像,返回的前4个图像的检索结果。从图1可以看出,SBIR的检索结果差强人意,对比两者输入图像可获取的信息,易看出SBIR更具有挑战性。

Figure 1 Retrieval examples of CBIR retrieval system and SBIR retrieval system图1 CBIR检索系统和SBIR检索系统的检索例图
草图可以简单分为专业素描与简易草图,在计算机中,专业素描往往以灰度图像的形式表示,而简易草图为二值图像[5],如图2所示。在现实生活中,素描图像通常由专业人员绘制而成,从应用的角度来看,专业素描不具有普遍性,所以研究者们将研究集中于简易草图。草图不同于图像,图像是由密集像素组成视觉对象的透视投影,而草图是主观和抽象的线条图,它们包含非常少的目标信息,但是却有令人惊讶的直观说明性。

Figure 2 Examples of professional sketches and simple sketches图2 专业素描与简易草图示例
1.1 草图检索的挑战性
尽管草图检索取得了很大的进展,但是目前的研究仍然面临着几大问题:
(1)草图-图像的跨域差距。草图与图像为非同源数据,处于不同的域空间,图像是对物体的像素完美描绘,而草图是高度抽象的线条集合。如何将两者更好地进行特征匹配或嵌入空间映射,缩小两者的跨域差距成为最关键的研究内容。
(2)草图多义性。由于绘画能力和艺术表达方式因人而异,且草图本身具有一定的模糊性,导致草图会因用户主观意识被理解为不同的语义信息,即草图存在大量的类间差异,如图3所示。
(3)草图检索成本问题。随着互联网2.0时代的到来,用户产生的内容越来越多,数据增加为检索系统带来巨大的压力。当遇到大规模检索情景时,系统输入一幅手绘草图需要与系统数据库中大量的自然图像进行特征相似性计算,如何以更高的效率获得理想的结果也成为草图检索的一大问题。
(4)草图数据集缺乏。与可以轻松访问到百万级数据集的照片(ImageNet、CIFAR等)相比,草图研究可使用的公共数据集(Sketchy、TU-Berlin等)仅为亚万级,数据缺乏成为研究进展缓慢的重要原因。
1.2 传统的草图检索方法与基于深度学习的草图检索方法
在传统的草图检索研究[6 -13]中,草图被看作是基于形状轮廓的表达,研究重点集中于如何利用几何关系表达草图特征。特征提取通常在针对草图特别设计的特征描述符上(例如方向边缘直方图[14]、关键形状学习[15]等二进制形状特征描述符和梯度场[16]、尺度不变特征[17]等自然图像特征描述符)进行边缘提取;之后,将草图与边缘图使用欧氏距离等方法进行相似度测量,通过相似度匹配对候选结果的输出进行排序与检索;最后完成图像检索,传统的草图检索方法流程图如图4所示。但是,由于草图本身具有的高度抽象性,生成的特征描述子对于草图的内容无法有效地拟合[18],因此不能满足现实场景的使用。除此之外,使用传统的草图检索方法无法实现端到端的检索系统,导致工作量大量提升。
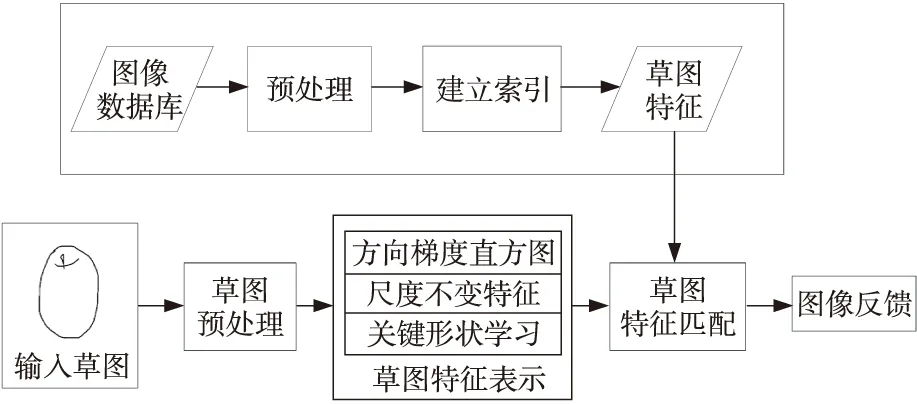
Figure 4 Flowchart of traditional sketch retrieval method图4 传统的草图检索方法流程图

Figure 5 Flowchart of sketch retrieval based on deep learning图5 基于深度学习的草图检索流程
2012年在ImageNet图像识别比赛中,Hinton课题组使用AlexNet网络获得冠军,掀起了深度学习新浪潮。草图检索作为计算机视觉领域中的重要研究方向之一,使用卷积神经网络CNN(Convolutional Neural Network)、循环神经网络RNN(Recurrent Neural Network)等深度学习技术已成为解决相关问题的主要方法。深度学习不同于传统手工特征提取需要层层设计,其可以学习手绘草图与自然图像包括低、中、高不同层次的深度特征,并学习理解图像中隐含的抽象语义信息,可以有效地捕捉人类感知。深度学习提取的深度特征更适合草图的研究,弥补了传统方法的不足,可实现端到端的检索系统,有效地提高了草图检索的性能。图5给出了基于深度学习的草图检索流程。
近年来,虽然已有大量的研究工作将深度学习应用于草图检索,但在国内外还没有发表过对该方面工作进行系统归纳和总结的综述性文献。本文聚焦于基于深度学习的草图检索方法,对现有的基于深度学习的草图检索方法进行综述和评论,并对未来的相关问题的研究进行总结和展望。本文结构安排如下:第2节介绍基于深度学习的SBIR常用模型;第3节介绍SBIR研究常用的公共数据集;第4节探讨SBIR中粗粒度与细粒度检索问题;第5节研究基于深度学习的SBIR的检索效率;第6节讨论用于SBIR的深度模型的泛化问题;第7节进行代表性方法的实验比较研究;最后一节为结束语。
2 SBIR深度学习特征提取模型
在图像处理领域中,常用的深度学习特征提取模型包括单层网络、孪生网络(Siamese Network)、三重网络(Triplet Network)和多层深度融合卷积神经网络等。SBIR研究不同于自然图像相关研究,其数据包含自然图像与手绘草图2个部分,它们是处于2个不同领域的异质数据,致使研究重点不仅需要关注于图像的语义、特征等内容,还需解决跨域问题。
SBIR研究初期,孪生网络为研究者们常用的网络模型,其可以实现异质数据在不同网络同步输入并完成数据在嵌入空间的映射。之后,Bui等人[19]通过实验发现,三重网络可以更好地捕获实例间的细微差异,适用于SBIR的研究,由此三重网络模型成为SBIR研究中最常使用的结构。本节选取具有代表性的孪生网络与三重网络进行介绍。

Figure 6 Siamese network structure 图6 孪生网络结构图
2.1 孪生网络(Siamese Network)
孪生网络是由Hadsell等人[20]提出的。在SBIR研究中,孪生网络作为模型框架,如图6所示,将手绘草图与自然图像作为模型的输入,通过深度网络学习,拉近标记为相似的草图-图像对在特征向量空间中的距离,而加大标记为不相似的草图-图像对在特征向量空间中的距离。使用类别标签Y={0,1}建立三元组(S,I,Y),其中S和I分别为输入草图与图像,当Y=1时,表示输入草图-图像对类别相同;相反,当Y=0时,表示类别不同。对比损失函数公式(Contrastive Loss)[20]如式(1)所示:

(1)

一般情况下,孪生网络中2个分支使用相同的CNN模型,例如AlexNet、Sketch-A-Nett和VGGNet等。近来,也有工作将不同的CNN网络相结合,实现描述草图特征的不变嵌入[19,21,22]。
2.2 三重网络(Triplet Network)
三重网络模型曾应用于人脸识别以及跨域问题,包括3D姿势估计(图像与姿势空间的映射)和场景描述(图像和自然语言空间的映射)。Bui等人[19]在草图检索问题中首次尝试使用三重网络,检索精度取得了显著的提升。在之后的研究中,三重网络成为最常用的模型框架。三重网络通常使用3个相同深度网络模型的分支,每个分支输入的数据不同,第1分支又被称为锚分支,输入数据为手绘草图;第2分支输入与输入草图类别相同的自然图像,称为正图像;第3分支则输入与输入草图类别不同的自然图像,称为负图像。三重损失函数负责指导训练阶段。实验表明,与孪生网络相比,三重网络可以更好地捕获实例间的细微差异。图7展示了三重网络模型框架。
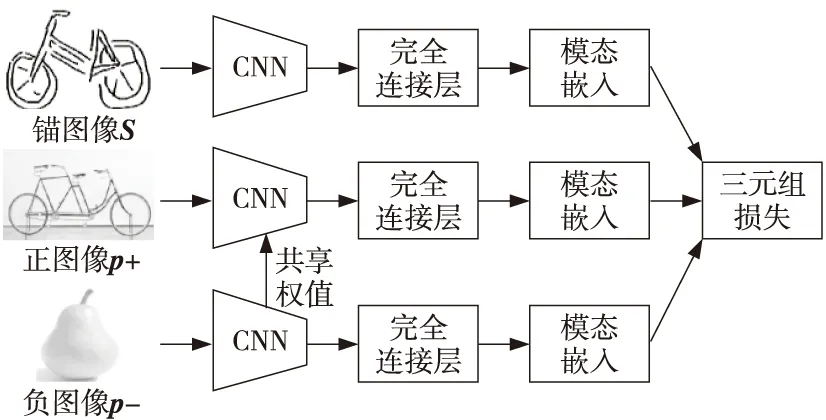
Figure 7 Triplet network structure 图7 三重网络模型
三重网络的目的是将同一类别的草图与正图像之间的距离最小化,并将草图与负图像之间的距离最大化,通过这样的方法增大类间距离,使输入检索草图时可以在空间中获得更好的映射。三重网络给定一个三元组t(S,p+,p-),S、p+和p-分别为输入草图、正图像和负图像,其对应的三元组损失函数[23]如式(2)所示:
Lθ(t(S,p+,p-))=
max(0,m+Fθ(S,p+)-Fθ(S,p-))
(2)
其中,m为正查询距离和负查询距离之间的边距,如果草图与正图像之间的距离和草图与负图像之间的距离小于间距m,则该三元组不会受到处罚。Fθ为测量特征向量距离的方法(实值计算时常用欧氏距离,二进制编码时常用汉明距离)。
3 草图检索常用公共数据集
手绘草图公共数据集在SBIR研究中起着重要的作用。手绘草图数据的收集不同于自然图像,不仅有数量要求,还需要在数据集中保留草图的抽象性、模糊性和多样性,所以同一个实例物体需要不同的人进行绘制。本节主要介绍现有的常用手绘草图公共数据集。
3.1 TU-Berlin Extended
TU-Berlin数据集是由Eitz等人[24]建立的,覆盖250个物体类别,每个类别80幅,一共包含20 000幅草图。图8为TU-Berlin数据集部分示例图。该数据集拥有“时序”属性,因此除了用于粗粒度检索之外,还可用于人类使用草图来描述物体的过程研究。使用TU-Berlin需要配合与草图类别相对应的自然图像,所以往往与Liu等人[25]提供的扩展自然图像数据集TU-Berlin Extended相结合使用。该扩展数据集与TU-Berlin中草图类别相对应,其中包含204 489幅自然图像。数据集来源:http:∥cybertron.cg.tuberlin.de/-eitz/projects/classifysketch/。

Figure 8 Part images in the TU-Berlin dataset图8 TU-Berlin数据集图像部分示例
3.2 Sketchy Extended
Sketchy数据集是由Sangkloy等人[26]建立的,该数据集中所有手绘草图通过众包方式收集,并要求参与者通过直观回忆参考图像的方式进行绘画,这样保证了草图本身的直观性与抽象性。除此之外,该数据集在每一幅手绘草图中添加Sketchablity属性,以此完成人工标注工作,表明该手绘草图在绘制时的难易程度[18],为用户提供了特定照片和草图之间的细粒度关联。Sketchy包含12 500件物品的自然图像,对应75 471幅手绘草图,每幅图像大约对应6幅草图,种类也多达125种。图9为 Sketchy Extended数据集部分示例图。Liu等人[25]用来自ImageNet的60 502幅图像扩充了Sketchy数据集。对于深度学习草图检索研究,Sketchy Extended也是验证模型有效性的数据集。数据集来源:http:∥sketchy.eye-gatech.edu/。

Figure 9 Part images in the Sketchy Extended dataset图9 Sketchy Extended数据集图像部分示例
3.3 QMUL Chair-V2和QMUL Shoe-V2
QMUL数据集的建立是为了进行细粒度检索的研究,其包含2个对象种类(椅子和鞋子),分为QMUL Chair-V2和QMUL Shoe-V2[27]。为了凸显出椅子和鞋子的类内区别,他们将2大类物品进行细致的小类别划分,数据集中数据皆以草图-图像对的形式存在,其中自然图像是从购物网络平台上获得的。QMUL Shoe-V2数据集是最大的单类细粒度草图检索FG-SBIR(Fine-Grained Sketch-Based Image Retrieval)数据集含有1 800个训练草图-图像对和200个测试草图-图像对。QMUL Chair-V2含有200个训练草图-图像对和97个测试草图-图像对。图10为QMUL Chair-V2和QMUL Shoe-V2数据集部分示例图。数据集来源:http:∥sketchx.eecs.qmul.ac.uk/downloads/。

Figure 10 Part images in QMUL Chair-V2 and QMUL Shoe-V2 datasets图10 QMUL Chair-V2和QMUL Shoe-V2数据集图像部分示例
3.4 QuickDraw Extended
QuickDraw Extended是由Dey等人[28]建立的,他们通过从QuickDraw中筛选出合适的草图,并根据其草图类型与自然图像进行了匹配,主要为了解决草图数据集数量不足的问题。该数据集横跨110种类别,每个类别包含3 000幅草图,总计330 000幅草图和204 000幅自然图像。图11为QuickDraw Extended数据集部分示例图。数据集来源:https:∥githu-b.com/googlecreativelab/quickdraw-dataset。

Figure 11 Part images in the QuickDraw Extended dataset图11 QuickDraw Extended数据集图像部分示例
3.5 常用数据集的对比分析
深度学习技术需要大量数据作为输入,至今为止,手绘草图数据集仍然缺乏,在一定程度上阻碍了SBIR技术的进一步发展。以上介绍的数据集为草图检索研究过程中最常用的手绘草图数据集,根据每个数据集的特性,不同的数据集可用于不同方向的草图检索研究。草图检索技术大致可分为粗粒度检索与细粒度检索,需要进行细粒度检索相关研究时,研究人员需要大量的不同类别草图与其对应的自然图像,所以常常使用TU-Berlin和Sketchy这2个数据集;而在进行细粒度检索时更加关注的是一个较大类别中的不同分类,QMUL Chair-V2、QMUL Shoe-V2和Sketchy更加合适。从深度网络模型的角度来看,粗粒度数据集可以更好地反映出模型针对空间分布的高维特征映射能力,而细粒度偏向于学习数据中细节特征与语义特征,更有利于类内目标的检索。表1对以上公共数据集进行了对比与总结。
4 粗粒度检索与细粒度检索
粗粒度检索与细粒度检索是草图检索领域的2类问题。粗粒度检索侧重于类间差异,旨在检索与查询草图共享相同类别标签的自然图像。为了充分表达草图的类间差异特征描述,CNN学习过程应专注于草图的全局特征和高级语义特征。细粒度检索FG-SBIR又称为实例级(instance-level)检索,而细粒度检索除了保留类别级的一致性外,还旨在保留类内实例级别的一致性,即只有检索结果为与输入草图唯一对应的实例图像才可判定为一次成功的检索。深度学习应用于粗粒度草图检索已有大量的研究工作,算法的检索性能提升很快,而近来,有研究将深度学习应用于更具挑战性的细粒度草图检索问题,取得了一些进展。本节对这2类研究工作进行综述和总结。
4.1 粗粒度检索
粗粒度检索研究中使用的深度网络模型,大多以孪生网络或三重网络为基础,根据研究重点的不同(例如域对齐、语义保留等问题),提出合适的变形结构(例如孪生同构网络、三重异构网络等)。Qi等人[29 -32]首次将孪生网络应用于粗粒度SBIR问题中,提出了针对草图特性的CNN网络结构,如图6所示。实验中使用以类Sketch-A-Net[30]为基础网络的同构孪生网络。与传统的手工提取特征方法相比,Qi等人[29]从全新的视角解决域移位问题,通过CNN学习对比损失函数引导模型训练。虽然实验结果与传统方法相比平均精度均值mAP(mean Average Precision)仅提升了1%,但是深度学习的引入突破了传统方法的束缚。
Bui等人[19]将三重网络应用于粗粒度草图检索,提出并比较了几种三重异构CNN网络。在锚分支与另外2个分支之间,通过使用不同的权重分享策略(权重无分享、权重半分享和权重全分享)进行对比实验,结果表明使用权重半分享策略的网络有更好的类别概括能力,其mAP值比Qi等人提出的孪生网络mAP值提升超过18%。

Table 1 Commonly used SBIR public datasets表1 常用SBIR公共数据集
Lei等人[31]在ImageNet数据集上使用VGG-19网络训练得到的预训练模型,解决了深度网络需要大量数据训练的问题,并使用Candy算子提取自然图像边缘轮廓,相比于其他边缘提取算法可以保留更多的纹理细节,使网络在学习过程中获得更多的语义信息。
Yu等人[33]将多步骤草图绘画概念引入SBIR问题,文中结合手绘草图的时序信息,将手绘草图与图像边缘图按绘画顺序分解为3部分视觉表示层,这些视觉表示层在同一层中彼此对应。根据多层视觉表示层相应地提出了多层深度融合卷积网络,基于多层视觉表示,将草图和二进制边缘图馈入多通道多尺度的深层CNN中,以提取不同层中的唯一特征表达,然后将3层特征融合为最终的精确特征以代表草图或图像,多层融合网络结构如图12所示。虽然将特征表达扩展到多层可以将草图的更多抽象和语义信息以及图像的二进制边缘图用于相似度计算,但使用多步骤训练存在新增笔划信息是否有效的问题,如果所增加笔划为无效信息,则会成为噪声,导致最终得到的融合特征并非最佳特征表示。

Figure 12 Multi-layer converged network structure图12 多层融合网络结构
Song等人[21]为了更好地解决草图域和图像域映射到公共空间域的问题,提出一种具有形状回归的边缘引导跨域学习方法,使用边缘引导模块融合经过级联操作的自然图像和相应的边缘图,有效引导自然图像特征提取域对齐过程,并使用形状回归模块探索草图与图像之间的形状相似性,从而缩小不同域的特征表示差异。
Bui等人[19]的研究表明,对于具有挑战性的草图数据集(如Sketchy、Flickr15k等),用边缘图代替图像将对检测准确性产生负面影响。虽然利用边缘检测算子提取出图像边缘图,完成图像域向草图域的近似转化,以减少域差,但是边缘图中存在不可避免的噪声,而且使自然图像只保留边缘轮廓与空间分布信息,而丢失了大量的高维语义信息,导致CNN网络未能发挥出其学习图像高维特征的优势。使用自然图像作为CNN输入源更有利于语义特征的提取和域差的减少,为之后的研究提供了指导。表2列出了5种代表性的深度草图粗粒度检索方法,给出了它们所用的基础网络、模型结构、使用方法、损失函数、测试数据集和检索精度,以资对比。
从表2可以看出,使用三重网络模型[19,33,21]比使用孪生网络模型[29,31]的检索精度更高。从使用的损失函数角度来看,仅使用对比损失或三元组损失引导模型训练的实验结果不理想,这归因于通过损失函数引导的训练结果在特征空间中不同类别所对应的特征向量分布较为分散,共享同类标签的特征向量未能得到较好的内聚性。
4.2 细粒度检索
相较于粗粒度检索,细粒度检索是一项更富有挑战性的任务:(1)视觉特征不仅需要细粒度,而且还需要跨域执行;(2)手绘草图高度抽象,使得细粒度匹配更加困难;(3)更为重要的是,训练所需带注释的跨域草图-图像对数据集稀少,使得许多深度学习方法面临巨大挑战。因此,相关研究者将研究重点集中于如何利用高维特征与更有效的局部信息实现跨模态匹配。本节将对细粒度检索研究中具有代表性的工作进行归纳总结。

Table 2 Five representative coarse-grained retrieval methods for sketches with deep learning表2 5种代表性的深度草图粗粒度检索方法
Yu等人[27]首次将深度学习引入细粒度检索问题中,他们在类别级检索模型基础上构建具有三元组排名损失的迁移模型,该模型通过分阶段预训练策略缓解细粒度数据不足的问题。在数据处理方面,文中将边缘图和草图组合成映射对,提高CNN网络在特征提取过程中空间映射的有效性,但使用的网络模型过于依赖数据集的信息标注,这样的工作将花费大量的劳动成本。Sangkloy等人[26]提供了Sketchy数据集,并在CNN网络中加入嵌入损失与分类损失,新数据集的提出为细粒度检索研究开辟了新的发展空间。
Zhang等人[22]使用异构网络(网络分支的网络结构或网络参数不同)的变体实现端到端的图像检索,以减少边缘图提取在高维特征提取过程中造成的图像信息丢失,结合对比损失与三元组排名损失进行逐步训练。在他们的研究中,将Tu-Berlin、ImageNet subset、Sketchy和QMUL Chair-V2分别用于训练或微调,这样的做法不利于语义信息在特征空间中的保存。
Song等人[34]引入对视觉细节的空间位置敏感的注意力模块来实现空间感知,并添加连接融合块将粗粒度语义信息与细粒度语义信息进行融合。Song等人[34]提出的深层空间注意力FG-SBIR模型在CNN的每个分支中添加注意力模块,用于表示学习的计算集中于特定的可辨别局部区域,而不是均匀分布在整体视图表示上。虽然CNN特征输出中包含细粒度信息,可以基于细微的细节进行区分,但是2个分支之间的特征未对齐,以及每个细粒度特征的语义感知信息较少而导致特征噪声更大。常用的对比损失或三元组排名损失通常使用基于欧氏距离的能量函数,该函数依赖于逐元素距离的计算,导致对错位十分敏感。因此,使用这2种损失函数建立于特征向量完全按元素对齐的假设之上,这与现实情况不符。为了解决这些问题,文献[34]提出了一种基于高阶可学习能量函数HOLEF(Higher-Order Learnable Energy Function)的损耗,其基于一对输入向量,通过向量之间加权外部减法形成的三重态损失的二阶距离函数。使用此能量函数,在比较草图和图像时,将计算2个特征向量之间的外部减法,从而详尽地测量2个域之间的逐元素特征差。虽然该实验检索精度有所提升,但是检索时间增加了一倍,效率大大降低。
Pang等人[4]认为在训练数据有限且仅关注区分性损失的情况下,仅学习2个域嵌入共同空间模型难以捕获所有域不变信息,无法有效地推广到与训练数据不同的测试域,导致训练域与测试域之间的差异和失准。为此,作者引入跨域图像合成的生成任务,提出了一种新的判别-生成混合模型,该模型将强制被学习的嵌入空间保留对跨域重构有用的域不变信息,从而显著减小异域间隙。Xu等人[35]探索了SBIR中的跨模式检索方法的有效性,使用概率方法对联合多模态数据分布进行建模,学习多模态相关性,利用子空间学习构造公共子空间并将多模态数据映射到其中,以进行跨模态匹配。实验表明子空间学习可以有效地对草图-图像域间隙进行建模。表3列出了7种代表性的深度草图细粒度检索方法,给出了它们所用的基础网络、模型结构、使用方法、损失函数、测试数据集和检索精度,以资对比。
5 深度哈希技术
草图检索研究除了需要解决减少草图与图像之间的域差,提高检索精度之外,还需解决大规模检索的效率问题[38-41]。随着数据规模的不断增大,使用距离算法计算相似度排名会花费巨大的存储空间和检索时间成本。哈希技术[42 -46]将图像的高维特征映射到二值空间,用低维哈希序列来表征图像,降低了检索算法对计算机内存空间的要求,提高了检索速度。传统的哈希编码方法主要是利用手工提取的特征作为图像表示,并通过不同的投影与量化方法(例如矢量迭代量化方法ITQ(ITerative Quantization)[39]、谱哈希方法SH(Spectral Hashing)[40]、核哈希[47]等)学习哈希码。近年来,深度哈希技术引起了计算机视觉研究者们的关注,其通过网络模型学习草图特征向量,之后将特征向量通过完全连接层且使用Sigmoid函数作为激活函数,并设定神经元的数量,即最终想获得的哈希码长度。与传统方法相比,跨域深度哈希(Cross Domain Deep Hashing)[48,49]编码能够更好地保留语义信息,同时以低计算量映射大规模异构数据,实现更优质的检索性能。与此同时,深度哈希检索也带了更大的挑战:(1)需要更紧凑的二进制编码实现有效的大规模检索;(2)需要使特征更具区分度来缓解由于数据高度抽象带来的剧烈变化。
Table 3 Seven representative fine-grained retrieval methods for sketches with deep learning表3 7种代表性的深度草图细粒度检索方法
采用深度哈希技术的模型的目标函数主要由3部分组成:(1)跨域交叉熵损失:为了将同一类别的草图与自然图像的二进制编码拉近;(2)语义分解损失:为了保持类别之间的二进制编码语义关系;(3)量化损失。总的损失函数[25]定义如式(3)所示:
s.t.BI∈{-1,1}m×n1,BS∈{-1,1}m×n2
(3)
其中,λ、γ为超参数,BI、BS分别为自然图像与草图的二进制编码,W为跨域相似性矩阵,φ(TI)、φ(TS)分别为图像与草图的类别词向量嵌入,D为共享的语义嵌入,ωI、ωS分别为自然图像与草图的特征矩阵,FI(ωI)、FS(ωS)分别为用于图像与草图的CNN网络。
Liu等人[25]首次将深度哈希方法用于草图检索问题中,提出了新的二进制编码方法——深度草图哈希DSH(Deep Sketch Hashing),使用一种半异构深度网络并将其结合到端到端二进制编码框架中。在DSH学习过程中对草图辅助信息进行编码,有效地减轻草图-图像之间的几何失真,并捕获到交叉视图的相似性以及不同类别之间固有的语义相似性,但二值化过程引入的量化误差会破坏域不变信息和跨域的语义一致性。Zhang等人[50]提出生成域迁移哈希方法,该方法使用对抗生成网络GANs(Generative Adversarial Nets)[51]将草图迁移到自然图像中增强泛化能力。在提出的学习框架中使用对抗损失与循环一致性损失共同优化了循环一致性迁移和哈希编码,还在其中加入了注意力模块,指导模型学习最具代表性的区域。表4列出了2种代表性的草图检索深度哈希方法,给出了它们所用的基础网络、模型结构、使用方法、损失函数、测试数据集和检索精度,以资对比。

Table 4 Two representative sketch retrieval deep hashing methods表4 2种代表性的草图检索深度哈希方法
6 类别泛化
所谓类别泛化,即通过特征提取模型,将训练过程中的可见数据与语义标签等辅助信息(例如词向量、属性向量)相结合,利用特征映射空间的语义信息“推理”出未见数据类别,从而完成图像检索任务。现在的大多数草图研究方法无法将已训练的类别高维特征映射到未训练类别的特征空间中,完成未训练类别的草图检索,由此衍生出SBIR研究的新课题——SBIR类别泛化。在现实生活中,检索系统训练数据无法涵盖数据库中潜在检索查询和候选对象的所有概念,所以草图检索的类别泛化成为亟需解决的新问题。
Bui等人[52]利用三元组损失网络提出了一种SBIR的有效表示,利用孪生卷积神经网络SCNN(Siamese Convolutional Neural Network)实现了描述不变嵌入来提高检索可见数据以外的能力,并且提出一种紧凑图像描述符实现在资源有限的移动设备上完成对数据集的有效检索。之后Bui等人[36]又提出一种同时具有对比损失与三元组损失的混合多级训练网络,使用该网络进行多阶段回归对数百个对象类别进行泛化。阶段1将训练网络每个分支设定为共享权重层,学习对应域中独有的特征;阶段2通过比较2个域中的低维特征来学习2个域中的共同特征;阶段3使用三元组损失对整个网络进行调整与完善,也进一步提高准确性。但是,他们仅对未训练类别泛化分析进行研究,并未进行具体实验。之后一段时间内,草图检索泛化问题没有取得大的突破。
2018年由Yelamarthi等人[53]首次将零次学习ZSL(Zero-Shot Learning)[54 -62]引入草图检索问题中,在此之前,大多数零次学习方法应用于自然图像处理领域,该类方法建立于一个假设之上:测试数据集分为可见数据与不可见数据,其共享语义空间且在语义嵌入空间中进行域对齐操作[56]。通过将可见数据与跨域迁移的语义知识映射到共享的语义空间中,根据可见数据训练学习到的嵌入属性完成对不可见数据的检索。零次学习的挑战性在于如何通过共享空间中的语义信息完成域对齐,从而实现不可见数据分类。随着新事物的不断增加,使用零次学习提高泛化能力成为必然趋势。图13所示为零次学习示意图。

Figure 13 Schematic diagram of zero-shot learning图13 零次学习示意图
Yelamarthi等人[53]提出了ZS-SBIR的新基准,以VGGNet为基础网络,为草图检索问题设计了条件变体自动编码器框架CVAE(Conditional Variational AutoEncode)和对抗自动编码器框架CAAE(Conditional Adversarial AutoEncode),如图14所示。本质上,文中模型将草图特征向量作为输入,使用生成模型随机填充缺失的信息,从而生成更多可能的图像向量,利用这些生成的图像特征向量从数据库中检索图像。在Yelamarthi等人的实验中,将草图与图像数据全部作为输入,而在泛化问题中,图像和草图并非所有的区域都可为跨模态映射提供关键的有效信息。
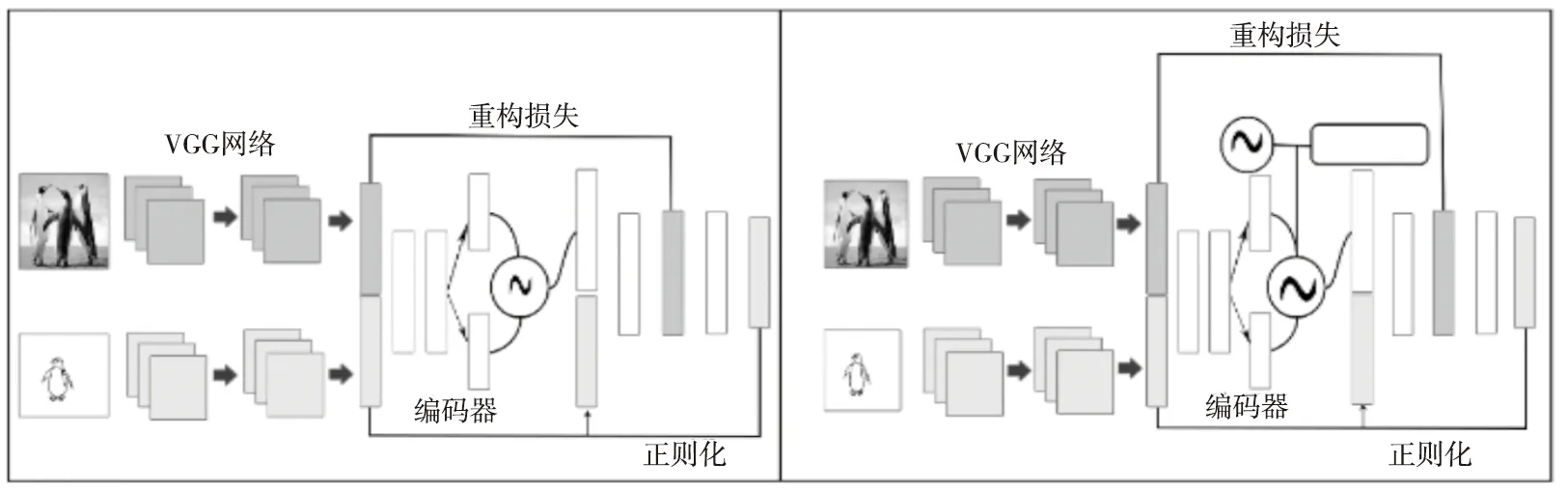
Figure 14 Architecture of CVAE and CAAE 图14 CVAE和CAAE体系结构图
深度哈希有效地解决了大规模的草图检索问题,但是如果检索草图为训练过程中未见过的类别,使用深度哈希往往会失败。Shen等人[63]针对这个问题提出了零次草图图像哈希ZSIH(Zero-Shot Image Hashing)模型。模型结构由端到端的三重网络组成,其中2个分支为二进制编码器,第3个分支分别利用Kronecker融合层和图卷积来减轻草图-图像的异质性并增强数据之间的语义关系。由于使用哈希算法的二值化过程引入的量化误差会破坏域不变信息和跨域的语义一致性,因此文中还提出一种生成哈希算法,使零次学习知识表示得以重构。但是,Kronecker融合层效率低下,将花费大量的检索成本。ZSIH是第一次将ZSL和跨域哈希相结合应用到SBIR任务中,对ZS-SBIR的研究具有重要意义。为使草图域与图像域能够更好地在公共映射空间中语义对齐,往往需要使用高阶的草图-图像对,例如Sketchy数据集。
Dutta等人[64]提出了语义对齐的配对周期一致生成SEM PCYC(SEMantically tied Paired CYcle Consistency)模型,其中每个分支通过对抗训练将视觉信息映射到公共语义空间。在对抗学习中将分类损失、循环一致损失和对抗损失相结合,保持每个分支的循环一致性。该模型只需要在类别级监督下进行学习,从而避免使用高阶的草图-图像对或内存融合层。
Dey等人[28]提出了一个新的ZS-SBIR模型,在模型中嵌入外部语义信息并使用2个新的损失函数来帮助实现可见类与不可见类之间的语义转换。一种为域分离损失,通过迫使网络学习与域无关的嵌入来弥合域之间的差距,其中梯度反转层GRL(Gradient Reversal Layer)鼓励编码器从草图和图像中提取互信息。另一种为语义损失,可以确保在已获取的嵌入中保留语义信息。在理想情况下,草图域和图像域可以在公共语义空间完全对齐。假设理想情况成立,为使草图检索得到更好的效果,则需要考虑如何在学习过程中保留更多的有效语义,从而完成拥有细节语义的检索。
Liu等人[65]从域适应的角度来解决以上问题,提出一种语义感知的知识保存SAKE(Semantic-Aware Knowledge prEservation)方法,通过使用师生优化模型进行近似计算,其中ImageNet的预训练模型作为教师信号,结合外部语义信息指导语义感知知识在嵌入空间中得到更好的保存与映射,从而进一步减少两域域差。表5列出了6种代表性的深度草图检索类别泛化方法,给出了它们所用的基础网络、模型结构、使用方法、损失函数、测试数据集和检索精度,以资对比。
从表5可以看出,SBIR类别泛化不仅关注域差减少问题,其对模型的推断未知类别能力、域对齐、语义保留等方面也有较高的要求。从Bui等人[52,53,63]的研究重点与实验结果中可以看出,他们提出的模型未能较好地保留语义与捕捉类内差异性,导致实验结果并不理想。而从Liu等人[65]的消融实验可知,注意力机制、语义对齐模块和语义知识保存模块均可有效提升模型性能。如何更好地实现保存语义知识、提升域对齐性能将成为解决类别泛化的关键。
7 实验比较研究
针对基于深度学习的草图检索,本文还进行了实验比较研究,其主要目的有2个:(1)评估选用测试集的特点与适用场景;(2)评估测试模型性能优劣。数据集选取方面,本文选取了TU-Berlin和Sketchy公共数据集,这2个数据集已被多篇文献[23,25,50,53,63-65]作为研究标准。本文还将较新的QuickDraw数据集[28]作为新基准纳入对比实验,此数据集虽然还未得到广泛的使用,但相比于其他2个数据集,该数据集有效地缓解了手绘草图研究中缺少大规模草图数据集问题,根据其特有特性可以从实验中获得更加丰富的模型评估信息。模型选取方面,本文选取CVPR、ECCV、ICCV等计算机视觉顶级会议提出的3个最新SBIR模型进行验证,分别为GRLZS模型[28]、SEM PCYC模型[64]和SAKE模型[65]。

Table 5 Six representative generalization methods for sketch retrieval categories with deep learning表5 6种代表性的深度草图检索类别泛化方法

Table 6 Results comparison of GRLZS,SEM-PCYC and SAKE on TU-Berlin,Sketchy,and Quickdraw datasets表6 GRLZS、SEMPCYC和SAKE在TU-Berlin、Sketchy、QuickDraw数据集上的结果对比
7.1 实验环境
实验平台为一台个人计算机,CPU为Intel(R)Core(TM)i9-9900K,操作系统为Windows 10,内存为32 GB,GPU为NVIDIA RTX 2080。实现算法的编程语言为PyThon,编程工具为Pychram,深度学习框架为PyTorch。为了实现有效的结果比较,本文将各模型参数尽可能统一。起始学习率lr=1e-4,最低衰减为lr=1e-7;参数优化器权值β1=0.9,β2=0.999,λ=5e-4。
7.2 评估准则
在对比实验中,本文采用2个标准的信息检索性能评估准则——平均精度均值和查准率。
(1)平均精度均值。
在SBIR研究中,平均精度均值mAP为常用检索性能评估准则,其定义如式(4)所示:
(4)
其中,Pr(q)表示查询草图q的检索精度,S表示测试集中查询草图的数量,Avg(·)表示平均函数。
(2)查准率。
查准率(Precision)是指在一次查询过程中,检索系统预测为正样本图像数量占所有返回图像数量的比例。
(5)
其中,tp(true positives)表示被系统检索到的正样本图像数量,fp(false positives)表示被系统检索到的负样本图像数量。
7.3 实验结果对比与分析
在实验中,本文将TU-Berlin、Sketchy和QuickDraw 3个数据集作为基准,在GRLZS、SEMPCYC和SAKE 3个训练模型上进行测试。通过实验结果对比,有利于从不同角度分析模型的优劣,表6所示为实验测试结果。
从表6的实验结果可以看出,3个模型在QuickDraw数据集上的测试结果均低于另外2个数据集上的测试结果。通过观察数据集得知,虽然QuickDraw数据集相比于另外2个数据集,在手绘草图数量上有绝对性的优势,但是QuickDraw图像质量不高、表达语义模糊等原因导致最终的测试结果不理想。实验结果表明,在SBIR问题中,不仅需要草图数量大,还需要较高质量的草图才能更好地进行语义提取与泛化。观察另外2个数据集上的实验结果,在相同的模型中,使用Sketchy数据集往往比使用TU-Berlin数据集的实验结果更胜一筹,根据测试结果验证出,无论是从数量上还是从Sketchy数据集中包含实例对标签的属性来看,Sketchy是比TU-Berlin更优质的数据集。
从模型角度看,在TU-Berlin和Sketchy 2个数据集上,SAKE模型与其它2个模型相比,结果有显著的提高。与GRLZS和SEM-PCYC不同,SAKE模型着重解决域适应问题,该模型为微调数据中的训练样本生成了伪标签并保留在预训练模型中,具有丰富视觉特征的原始域知识,使合适的候选图像与干扰信息得到了更好的区分。网络在进行前向训练时,将二进制编码附加到第1层的输出中,用来指示输入的数据是图像域还是草图域,用1个带条件的自动编码器代替2个独立的网络,帮助网络学习来自不同模态输入数据的不同特征。由于基准数据集中没有对应标签,SAKE使用ImageNet预训练网络初始化模型,作为教师信号,通过外部语义知识的约束来监督网络的学习。与SAKE模型相比,虽然SEM PCYC模型使用循环一致损失函数与外部语义信息的结合,将草图域和图像域在嵌入空间中更好地对齐,但是未能对预训练模型中的有效知识进行保存,导致在训练过程中丢失大部分知识。但是,从表6中可以清楚观察到,SAKE模型在QuickDraw数据集上表现并不理想,从其使用的教师指导模块可以分析其原因,QuickDraw中手绘草图与其他2个数据集中手绘草图相比,存在无法表达完整语义的草图,这导致在教师指导模块中为训练的模型提供较大噪声,产生存在误差的指导信号,被训练出的模型无法从源数据中学习有用的感知知识进行有效存储,最终的检索效果也随之降低。
8 结束语
虽然草图检索研究已经取得了很大的进展,但是还远远无法满足实际应用的需求,该领域仍然面临很多具有挑战性的问题,未来可主要着眼于如下研究工作:
(1)到目前为止,SBIR研究可使用的公共数据集在数量上仍然不足,一定程度上阻碍了研究的进一步发展。可用于细粒度检索的数据集(与Sketchy数据集相似)更是成为SBIR研究的亟需资源。虽然迁移学习和无监督机器学习可能有助于解决标签不足的草图训练数据问题,但是为推动SBIR研究与发展,仍然需要收集高质量的手绘草图数据,只有在拥有充足实验数据的基础上,模型才能广泛地从手绘草图中获取抽象数据模式和高度复杂的时序逻辑信息。
(2)如何将草图与图像之间的公共特征进行更好的映射,减少两域之间的差距将是一个长久的课题。本文建议参考图像检索领域中最新技术(例如动态路由、Few-Shot、MatchNet、Meta learning等),它们应用于其它问题中取得了很好的结果,可以为SBIR相关问题的研究提供新的思路。
(3)现有的基于深度学习的草图检索方法所使用的网络模型(如AlexNet、VGG16等),其网络结构大多是基于自然图像的特性所设计的,然而自然图像与手绘草图之间存在较大差异,未能有针对草图本身所具有的抽象性、时序性等特征设计的有效的深度学习网络,因此在之后的研究工作中,可以从草图的固有特点有针对性地压缩模型结构,减少网络中不必要的参数等,设计专用神经网络,提高检索性能。
